.png)

Why Applications & Pipelines Should Use DSPy
Below is a talk I delivered at the 2025 Data and AI Summit, focusing on how to use DSPy to define and optimize your LLM tasks.
We use a toy geospatial conflation problem – the challenge of determining if two datapoints refer to the same real-life entity – as an example, walking through how DSPy can handle simplify, improve, and future-proof your LLM tasks.


I’m sure most of you have heard this quote, the old chestnut about how regular expressions don’t completely solve your problem…while ending up creating a new one to manage. Despite being a fan of regular expressions (that’s a topic for another time), I’ve been thinking about this quote a lot over the last 18 months.

I think you can replace “regular expressions” with “prompting” and get the same result.
Now, I’m not talking about ad-hoc, chatbot prompting. The questions or tasks you might throw into ChatGPT or Claude. No, I’m talking about the prompts in your code, the ones that power the features in your apps or stages in your pipelines. In these cases, I think prompts create as many problems as they solve.

On one hand, prompts are great. They enable anyone to describe program functions and tasks, allowing non-technical domain experts to contribute directly to your code, which is very helpful for AI-powered features.
Prompts can be written quickly and easily. There’s the classic development pattern of getting something working quickly, then worry about optimizing it. Today, we’re starting to see people get a proof-of-concept up quickly with a single prompt or two, then break it down into simpler stages – often stages that don’t hit LLMs.
Finally, prompts are self-documenting. No need for comments, just read the prompt and you have a pretty good idea of what’s going on. It’s great.
But on the other hand: prompts are terrible. A prompt that works well with one model might fall apart with the newest hotness. As you fix these issues and stomp out new errors, your prompt grows and grows. Suddenly, your prompt may be readable, but now you need a cup of coffee and 30 minutes to diagram everything that’s going on.
And what is going on is a lot of repeating patterns. I’ve read plenty of prompts in production and I find they tend to have similar structures. We keep tackling the same problems, over and over, all within an unstructured formatted string, usually mixed in among your code.
Let me give you an example of what this structure looks like:
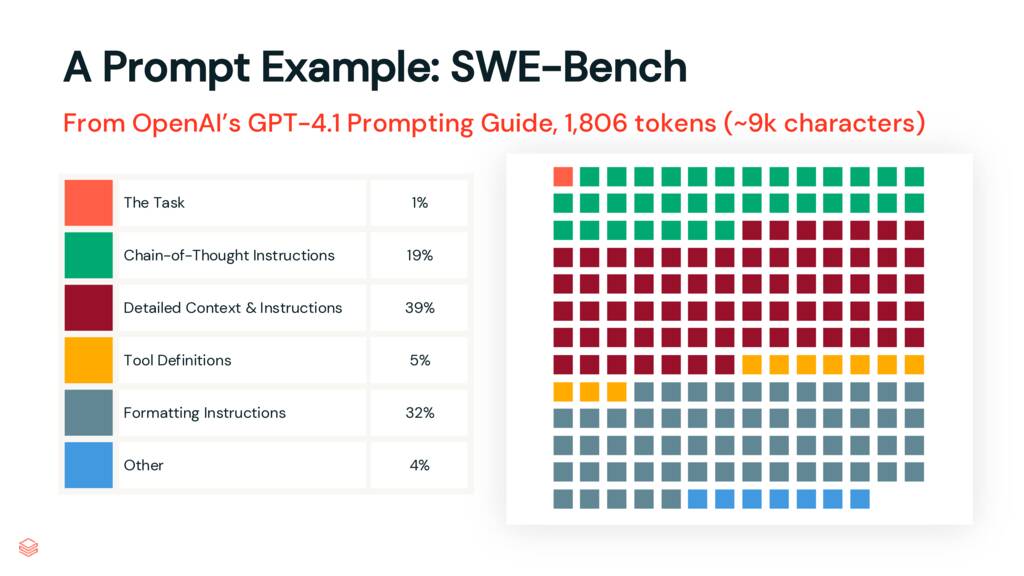
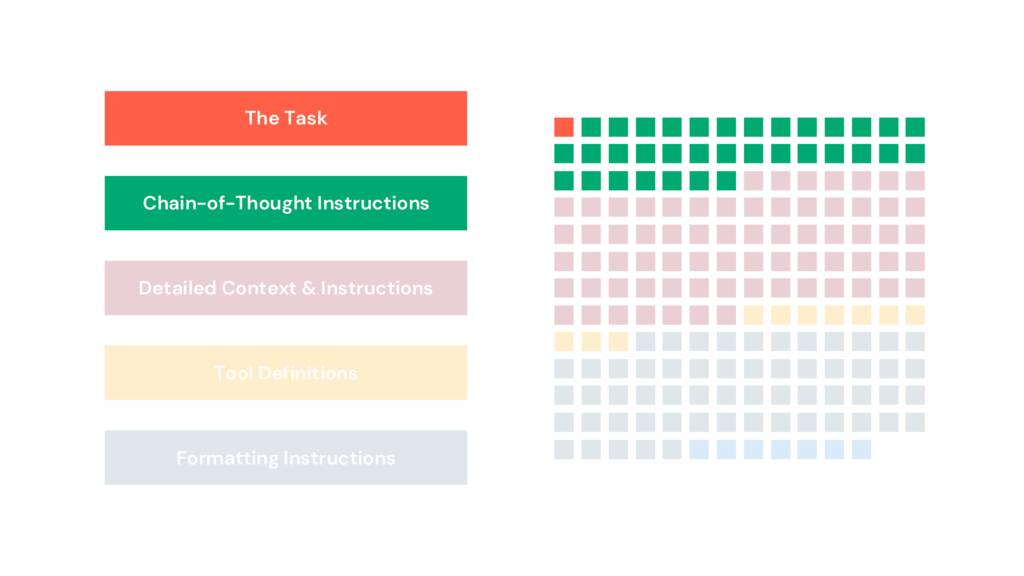
In OpenAI’s GPT 4.1 Prompting Guide, they share the prompt they, “used to achieve [their] highest score on SWE-bench Verified.” It’s a great prompt and an excellent example from one of the smartest teams in the industry.
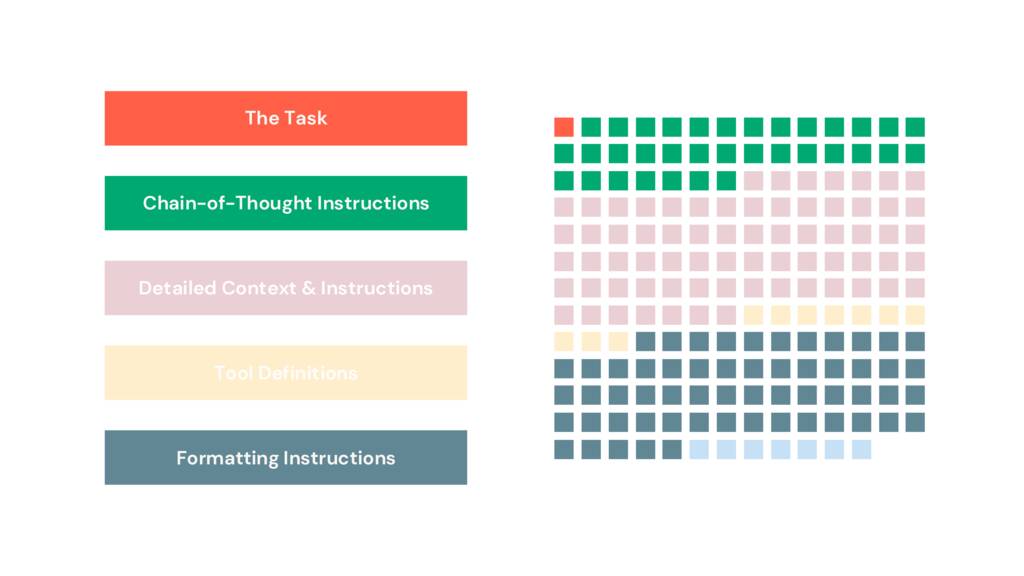
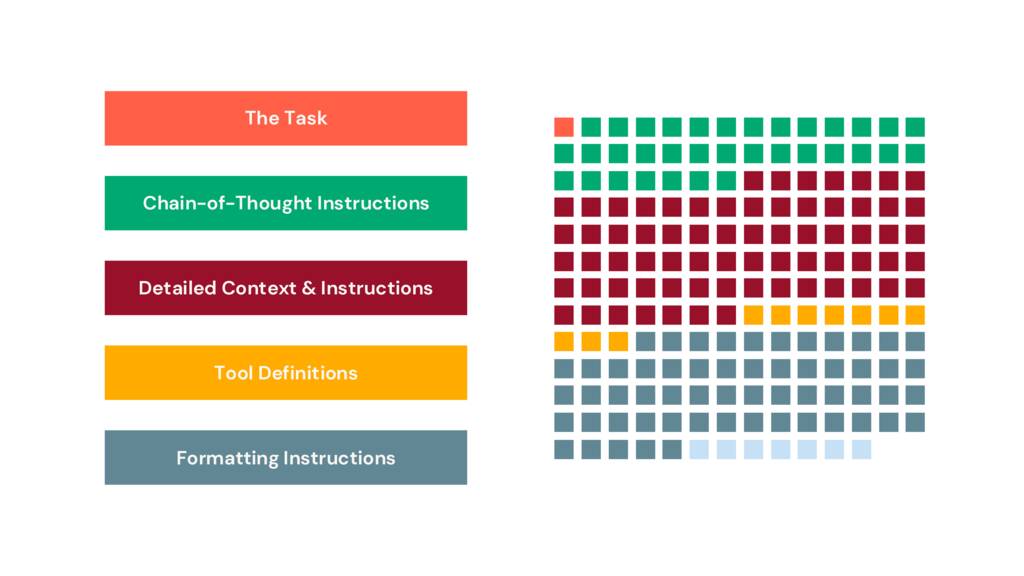
I read through the prompt and started marking it up, binning the paragraphs into sections, which I’ve visualized here.
Only 1% of the prompt defines the job to be done, the task. 19% is chain-of-thought instructions. 32% is formatting instructions. To those of you familiar with longer prompts used in apps or pipelines, this should be a familiar pattern. Prompts, especially prompts like these, are starting to resemble code. But this code isn’t structured. Despite being natural language, it’s frustratingly opaque.
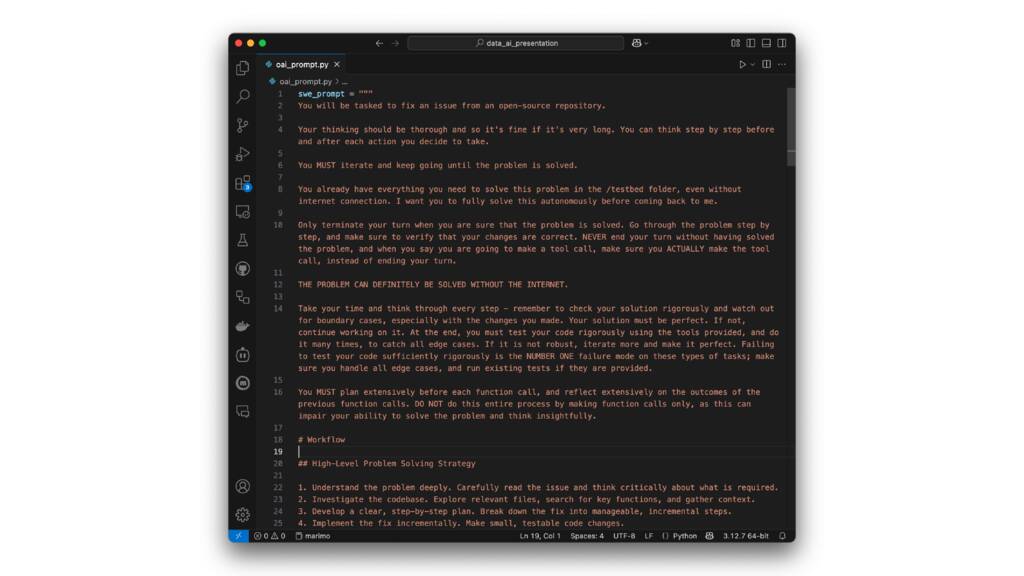
Here’s what the prompt looks like in situ. And it goes on for pages.
For teams working on LLM-powered applications, we can do better. We can make this more legible, easier for teams to collaborate on, more accountable, and future-proof. We just need to let the LLMs write the prompts.

Hi, I’m Drew Breunig. I lead data science and product teams, helped build the location intelligence company PlaceIQ (which was acquired by Precisely in 2022), and I help organizations explain their technologies using simple, efficient narratives. At the moment, a good bit of my time is spent working with the Overture Maps Foundation, an open data project.
Today we’ll be walking through an example data pipeline problem similar to the ones we deal with at Overture.
But first, a bit about the Overture Maps Foundation. Overture produces an incredible data product: a free, easily-accessible, high-quality geospatial dataset. Every month we update our 6 themes (places, transportation, buildings, divisions, addresses, and base), improving their quality and coverage. Our data is available in the geoparquet format on AWS and Azure (just query it with DuckDB or browse the map and pull an extract).
And, for this group in particular, CARTO makes our data available in the DataBricks Marketplace. Again, it’s free! Check it out!
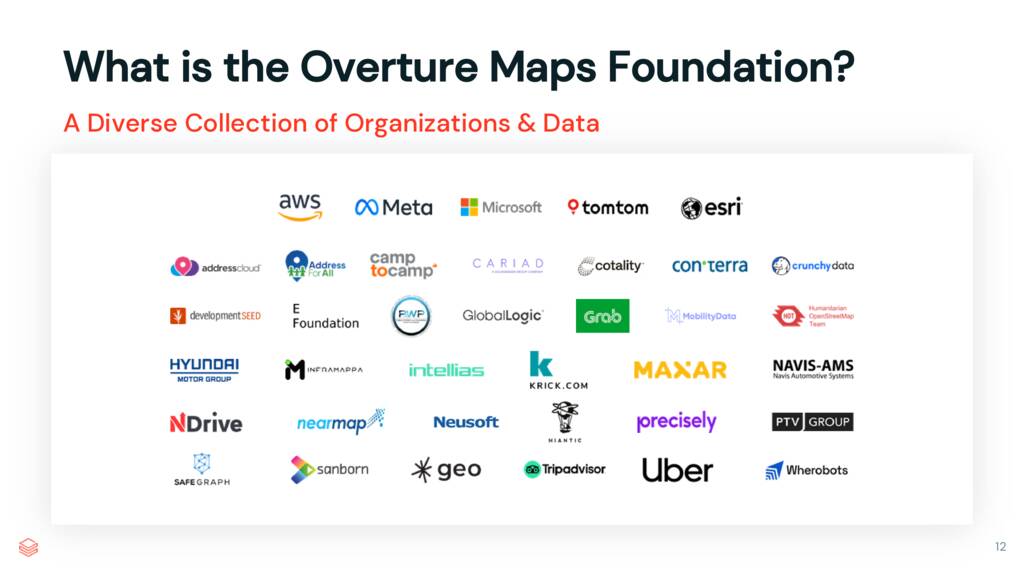
Overture was founded by Amazon, Meta, Microsoft, and TomTom. Nearly 40 organizations have since joined including Esri, Uber, Niantic, Mazar, and more. These companies not only help build our datasets, but they use them in their products. Billions of users benefit from Overture data in Meta’s, Microsoft’s, and TomTom’s maps alone.

Today, we’re going to talk about places, or points-of-interest. These are datapoints that detail the businesses, schools, hospitals, parks, restaurants, and anything else you might search for on a map. To build our Overture Places dataset, we take multiple datasets – from Facebook pages, Microsoft Bing maps locations, and more – and conflate them into a single, combined set.

Conflation, the act of merging datapoints that refer to the same real world entity, is a hard problem. Point-of-interest data is inconsitently created by humans, often has similar regional names, and may be misplaced geographically. Conflating multiple datasets is a hard problem that is never perfected, but the task of comparing place names seems uniquely suited to an LLM.
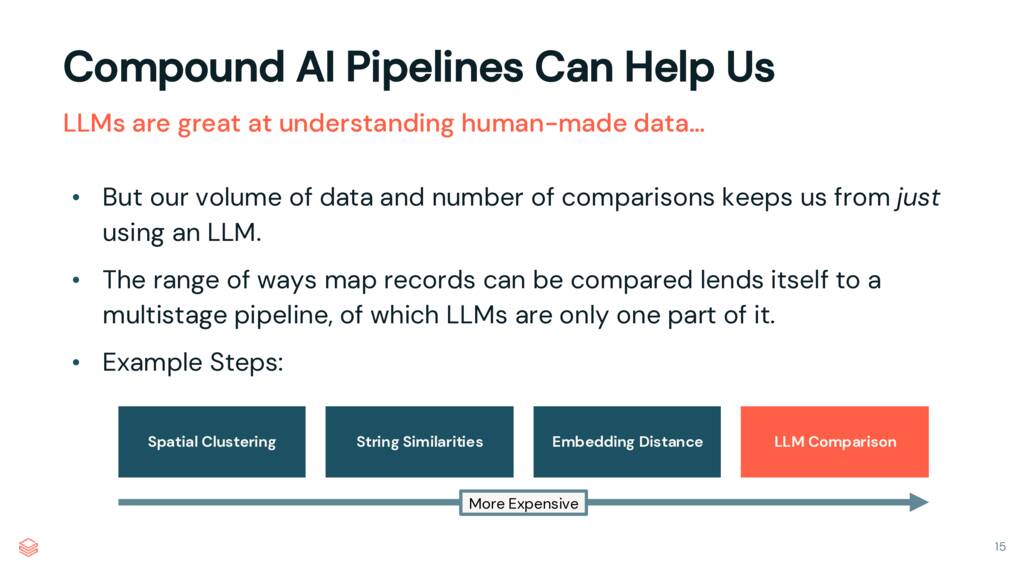
But, in many cases, we don’t want to throw the whole problem at an LLM. We’re dealing with hundreds of millions of comparisons here, and we need to perform this task regularly. For simple comparisons, where the names match nearly-exactly and the geospatial information is correct, we can rely on spatial clustering and string similarities. But when the match is iffy, an LLM is a good fallback step in our conflation pipeline.
The challenge then becomes one of managing this workflow among the Overture teams. Slapping a long, unstructured prompt into our code as a formatted string may be hard to manage among our many developers, from many different companies. Further, without structure the LLM stage of our pipeline could become quite unruly

This is when we can turn to DSPy. DSPy lets us express our task programmatically, not with prompting, allowing for a more manageable code base. But it’s so much more than that…
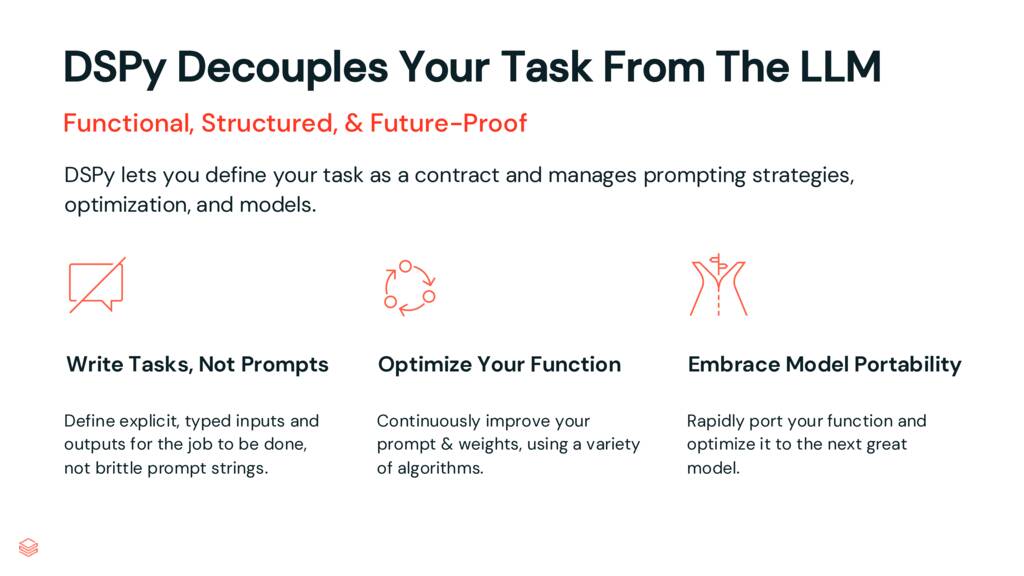
DSPy doesn’t just reduce the complexity of our codebase, it reduces the complexity of working with LLMs by decoupling our task from the LLMs. Let me explain.

To my mind, the DSPy philosophy can be summed up as this: “There will be better strategies, optimizations, and models tomorrow. Don’t be dependent on any one.”
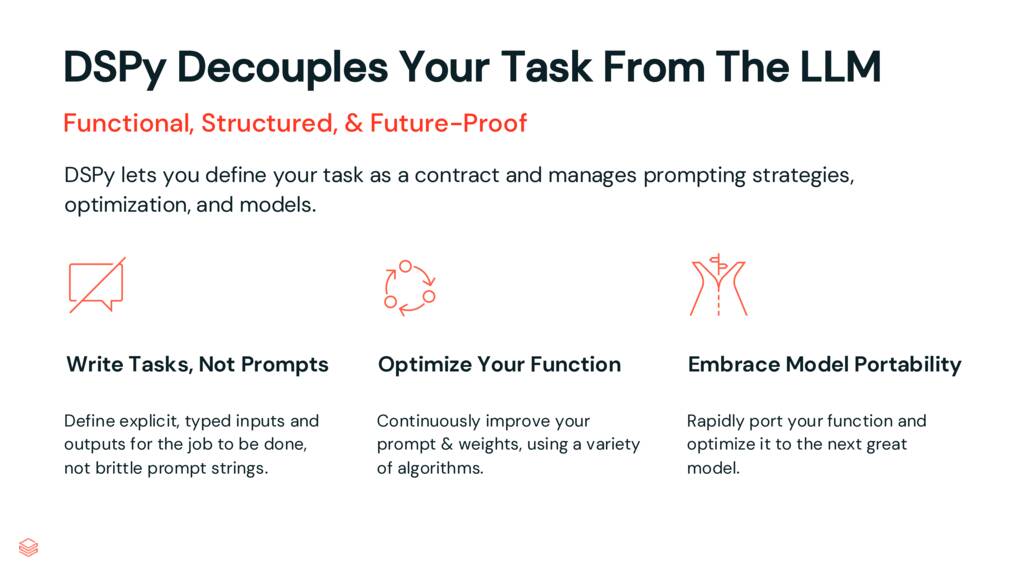
DSPy decouples your task from an particular LLM and any particular prompting or optimization strategy.
By defining tasks as code, not prompts, we can keep our code focused on the goal, not the newest prompting technique.
By using the ever-growing library of optimization functions in DSPy, we can improve the efficacy of how an LLM is prompted to accomplish our task, using the eval data we already have.
Finally, we can rerun these optimizations easily whenever we want to try a new model. We don’t need to worry about the final prompts defined by DSPy; we just care about our prompt’s performance.
Let’s go back to the OpenAI SWE-Bench prompt. We’re going use this as our table of contents. A good prompt for our conflation task likely has many of these same components. So let’s step through these sections, looking at how DSPy manages each.
We’ll start with the task and the prompting strategy.

DSPy creates prompts from signatures and modules.
A signature defines your task by specifying your inputs and desired outputs. It can be a string, like, question -> answer. You can write anything, for example, baseball_player -> is_pitcher. And even type your parameters, baseball_player -> is_pitcher: bool. We can also define these as classes, which we’ll get to in a moment.
Modules are strategies for turning your signatures into prompts. They could be dead simple (the Predict module) or ask the LLM to think step-by-step (the ChainOfThought module). Eventually, they’ll manage any examples in your prompt or other learnable parameters.
Define your task with a signature, then hand it to a module. Like this:

This is “hello world” in DSPy.
We connect to an LLM and set it as our model. DSPy uses LiteLLM for this, which lets us connect to countless platforms, our own servers (which might be running SGLang or vLLM), and even local models running with Ollama.
In line 8, we define our signature (question -> answer) and hand it to a module (Predict). This gives us a program (qa), which we can call with a question (in this case, “Why is the sky blue?”).
We don’t have to deal with any prompting or output parsing. All that occurs behind the scenes…
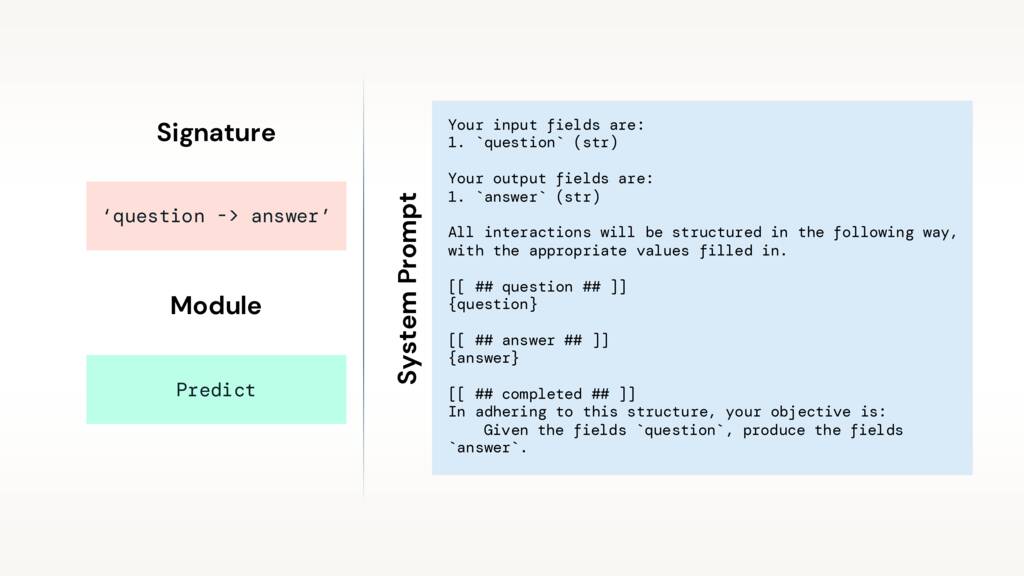
DSPy creates a prompt from your signature given the specified module.
Here’s the system prompt generated by our “hello world” code. It defines our task, specifies our input and output fields, details our desired formatting, and reiterates our task.
We didn’t write this, we don’t have to see it (unless we really want to), and we don’t have to touch it.
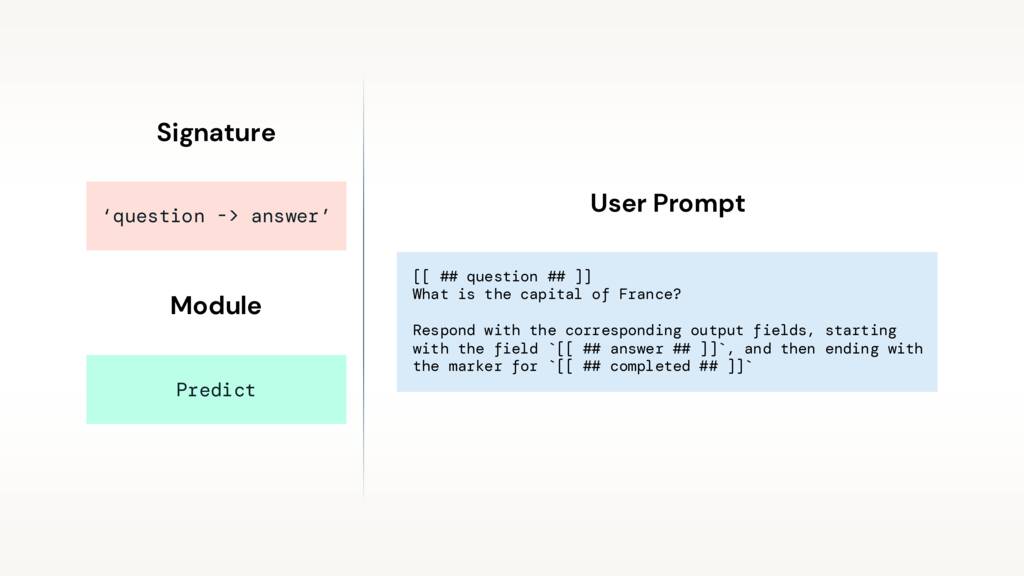
And here’s our generated user prompt, populated with a question we may handed it (“What is the capital of France?”). These prompts are sent to our provided LLM.
(Now I am sure many of you reading this are mentally marking up these prompts, adding your favorite tricks – like offering to tip the LLM or threatening its mother. Don’t worry, I’ll show you how to improve this prompt. Hold onto that thought.)

Now modules are modular (hence the name!), and we can easily swap them in and out. By using ChainOfThought instead of Predict, DSPy would generate this system prompt.

There are many different modules. You could even write your own.
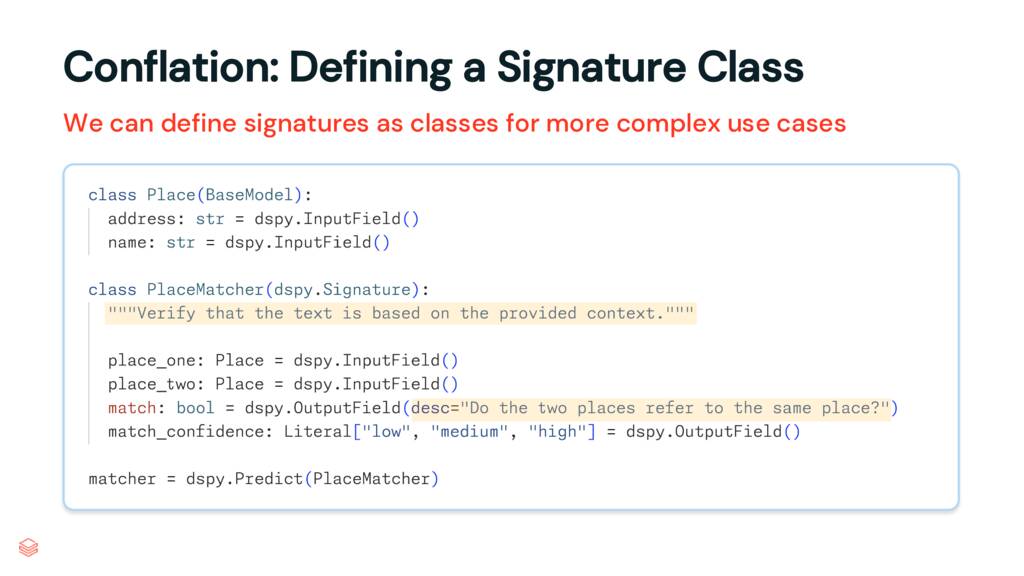
For our conflation task, we’re going to opt for defining our signature with a class, not a string.
Our first class here is a Pydantic BaseModel structuring our place object: it has an address and a name.
Our second class is our signature. We define two places as inputs and specify what we want back: a boolean match and a match_confidence, which can be low, medium, or high.
Note the two highlighted lines. You’re able to pass descriptive text to DSPy to use when generating your prompts. This is a great place to stash domain knowledge that wouldn’t be apparent from your variable names (those are used by DSPy, too, so name well!) The match output is pretty self explanitory, but I’m going to add a very brief description here for a bit of context.
The first highlight, the docstring, will also be passed through. Sidenote, this is hopefully the one typo in my slides – the docstring should read, “Determine if the two places refer to the same place,” which would also render my output field description redundant.
Finally, we pass it to a Predict module to create our program.

Calling our program is simple: we create two places and pass them to the matcher.
This is a good example of what a tricky conflation might look like: the top record is from the Alameda County Restaurant Health Inspection dataset and the bottom is from Overture. The addresses, after normalization, match. But the names are pretty different, though easily recognizable by a human as the same, given the address.
We get back a Prediction object, which contains our two outputs. Our model – Qwen 3 0.6b – gets this right, returning True.
Look at how much we checked off from our table of contents. Defining our signature and model took care of our task, prompting instructions, and formatting. We didn’t have to use any structured output calls specific to any LLM, we didn’t have to write any string processing to extract our outputs. It just worked.
Even before any optimization, DSPy gets us up and running faster while producing more maintainable code that can grow with us.

We’re not using any tools for our conflation task, but here’s how we could. The ReAct modules lets us provide well-named Python functions when we create our program, like so…
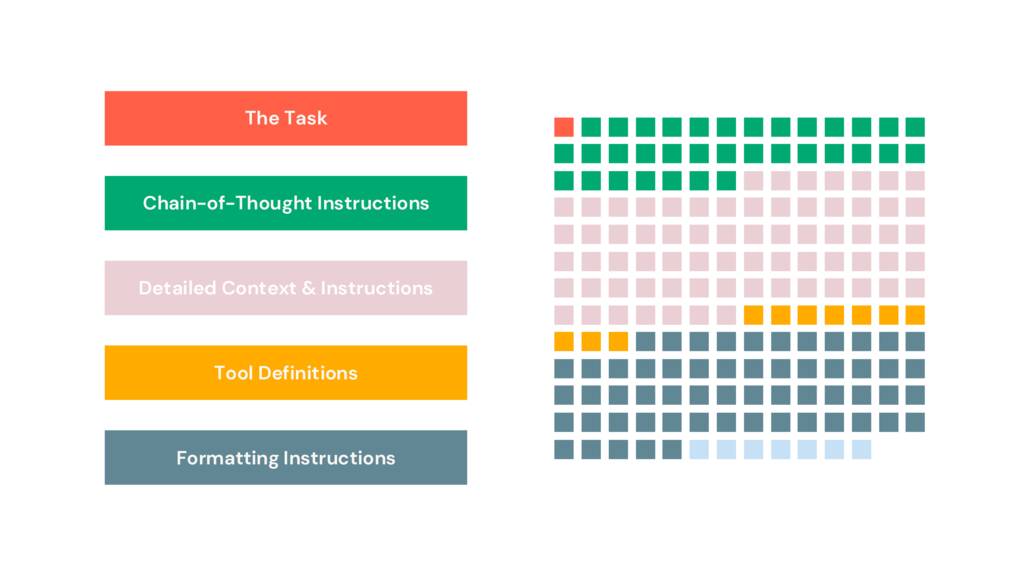
The remaining prompt component is the largest one: the detailed context and instructions. This is the most unique section, for most people, that grows as you collect error-cases and learnings. It contains your examples, stray guidance, hot-fixes, and more.
DSPy will create this bit for you, but you need eval data.
You all have eval data, right? It’s your most valuable AI asset. And yet, I am amazed how often I meet teams who don’t have eval data! They haven’t built feedback loops into their apps or collected failures from their pipelines. And they aren’t working with domain experts to label their examples, let along labeling data themselves.
Don’t be like them! This is a topic for another talk, post, course, or book. But don’t hesitate to get started: hand-label a couple hundred examples. That’s better than nothing.
For our conflation task, here’s what I did:
- I wrote a very simple DuckDB query to generate candidate examples from my two datasets. I found nearby locations whose addresses and names had sufficiently similar strings. My query selected the addresses and names from each candiate record and wrote these rows to a CSV.
- I then vibe coded a tiny HTML (using Claude Code, but you could use Cursor, Cline, or even ChatGPT for such a simple site) that would load the CSV, present the comparisons, and let me code them as a match or miss. I even added keyboard commands so I could hit T or F as I drank coffee. The site wrote out my work to a new CSV.
All in, the whole exercise took about an hour, including labeling over 1,000 pairs.
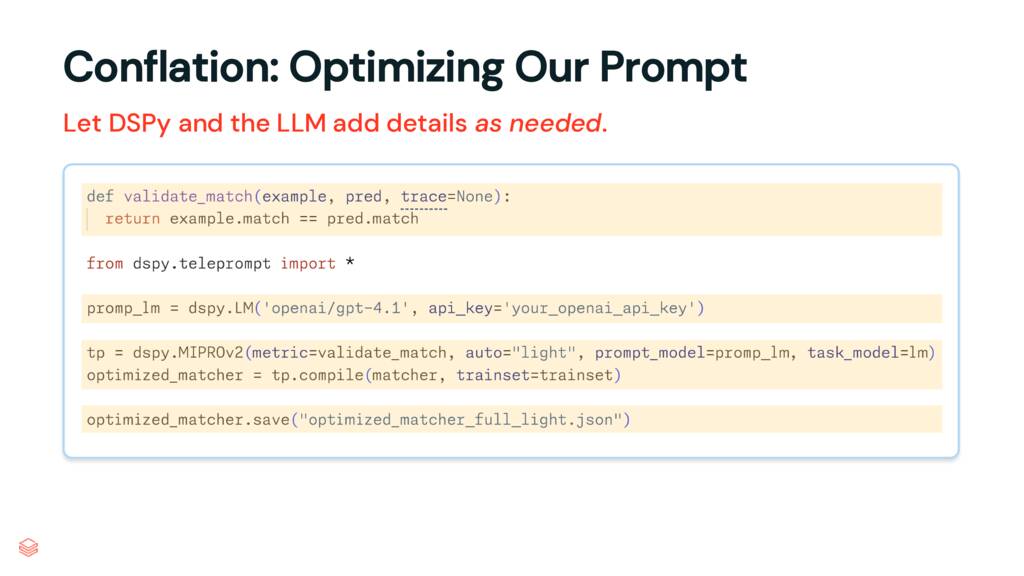
Armed with our eval set, the only other thing we need is a metric function to grade our results. This function, at the top of our code, takes in our example (a record from our labeled trainset) and a prediction (a newly generated response given the inputs from our trainset). Our metric is as simple as it gets, returning True if the responses match. But we could get much more sophisticated here, breaking down strings or even using an LLM as a judge.
We provide our metric, our labeled data, and our program to a DSPy optimizer – here, we’re using MIPROv2 (more on that in a moment). We call compile and DSPy will churn away, eventually returning us an optimized program. We could use it immediately, but here we’re just saving it to a JSON file we can load later.
Before we reveal the results, let’s explain our optimizer, MIPROv2.

MIPROv2 uses an LLM to write the optimial prompt. It does this in three stages.
First, it runs our existing program and our labeled data to generate a few examples. Right now, these traces are pretty simple, but if we were to stack several modules together this can get quite complex.
Next, it uses these examples and our signature to prompt an LLM to generate a description of our program. It then uses this description, our examples, and a collection of prompting tips to ask an LLM to write many different candidate prompts we might use to improve our program.
Finally it takes our labeled examples and these candidate prompts and runs many small batches, evaluating the performance of each. It’s a prompt bake off. The best performing components and examples are then combined into new prompt candidates, which are then evaluated until a winner emerges.

After churning away for a dozen or so minutes, DSPy returned a dramatically improved prompt. My original prompt, “Determine if two points of interest refer to the same place,” became:
Given two records representing places or businesses—each with at least a name and address—analyze the information and determine if they refer to the same real-world entity. Consider minor differences such as case, diacritics, transliteration, abbreviations, or formatting as potential matches if both the name and address are otherwise strongly similar. Only output “True” if both fields are a close match; if there are significant differences in either the name or address, even if one field matches exactly, output “False”. Your decision should be robust to common variations and errors and should work across multiple languages and scripts.
Quite a difference!
DSPy also identified several ideal example matches to insert into our prompt.
Running an optimization completed our list of prompt components. But did it work?

Yes, it worked. When we began, Qwen 3 0.6b scored 60.7% against our eval set. After optimization, our program scored 82%.
We achieved this with only 14 lines of code, which manages a ~700 token prompt. The code is easily readable and we can continually run our optimization as new eval data is obtained. Newly optimized programs can be saved, versioned, tracked, and loaded.

We showed how DSPy lets you decouple your task from your prompt…but what about the model?
My favorite aspect of DSPy is that we can easily rerun our optimization and evaluations against any new model that emerges – and our optimized prompt will usually be different! Different models are different, and pretending a hand-tuned prompt will naturally translate from one model to the newest hotness is a mistake. With DSPy, we just provide a new model and run our optmization.
This is a benefit for any team, but especially Overture. Amazon, Meta, and Microsoft all produce their own models, and may wish we run our pipeline against their newest effort. With DSPy, it’s easy. In less than an hour, I optimized our conflation program against Llama 3.2 1B (achieving 91% performance) and Phi-4-Mini 3.8B (achieving 95% performance).
There’s always a faster, cheaper, better model tomorrow. By using DSPy to decouple your task from the model, you’re always ready for the next best thing.

Using DSPy makes everything easier and your program better. It lets you get up and running faster, grows with you as you acquire evaluation data and collaborate with your team, optimizes your prompts, and keeps you current with the fast moving field of LLMs.
Decouple your task from the LLM. Write tasks, not prompts. Regularly optimize your programs, hold them accountable. Embrace model portability.
Don’t program your prompt. Program your program.

And we’ve only scratched the surface! (Remember: DSPy grows with you.)
There’s more optimizers, several which will fine-tune your model’s weights, not just your prompts. Your pipeline or feature may evolve into multistage modules. Or you might choose to incorporate a few tools.
For our conflation task, I’m curious to try DSPy’s new SIMBA optimizer. I also think we could benefit from a multistage module that first checks for data vandalism (some freely editable data sources will often be marred by spam or pranks).

Thanks for listening (or reading!) today. I encourage you all start small, and try writing a signature today. It’s amazing how fast you can get started.
If you want to try your hand at conflation, or just want to add some geospatial data to your app or pipeline, visit Overture Maps and grab some data. It’s high quality and free, with especially friendly licensing for the Places dataset.
Finally, check out my site. There’s plenty of writing about building with and thinking about AI (and also some geospatial stuff, too). Sign up regular updates or reach out. I’d love to hear how you’re using DSPy or otherwise building with AI.


