LightlyStudio – an open-source multimodal data curation and labeling tool
2 weeks ago
2
Curate, Annotate, and Manage Your Data in LightlyStudio.
We at Lightly created LightlyStudio, an open-source tool designed to unify your data workflows from curation, annotation and management in a single tool. Since we're big fans of Rust we used it to speed things up. You can work with COCO and ImageNet on a Macbook Pro with M1 and 16GB of memory!
Curate, Annotate, and Manage Your Data in LightlyStudio.
Runs on Python 3.8 or higher on Windows, Linux and MacOS.
pip install lightly-studio
Download example datasets by cloning the example repository or directly use your own YOLO/COCO dataset:
To run an example using an image-only dataset, create a file named example_image.py with the following contents in the same directory that contains the dataset_examples/ folder:
importlightly_studioasls# Indexes the dataset, creates embeddings and stores everything in the database. Here we only load images.dataset=ls.Dataset.create()
dataset.add_samples_from_path(path="dataset_examples/coco_subset_128_images/images")
# Start the UI server on localhost:8001.# Use env variables LIGHTLY_STUDIO_HOST and LIGHTLY_STUDIO_PORT to customize it.ls.start_gui()
Run the script with python example_image.py. Now you can inspect samples in the app.
To run an object detection example using a YOLO dataset, create a file named example_yolo.py with the following contents in the same directory that contains the dataset_examples/ folder:
Run the script with python example_yolo.py. Now you can inspect samples with their assigned annotations in the app.
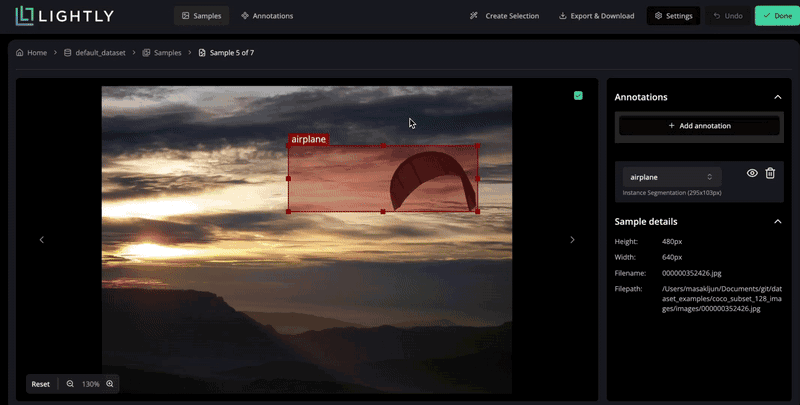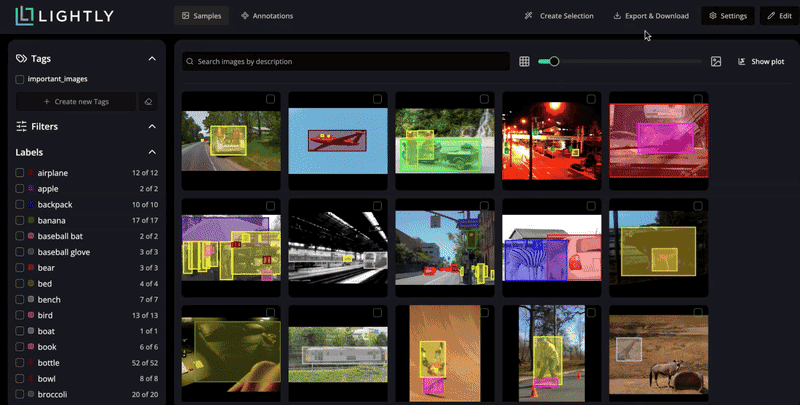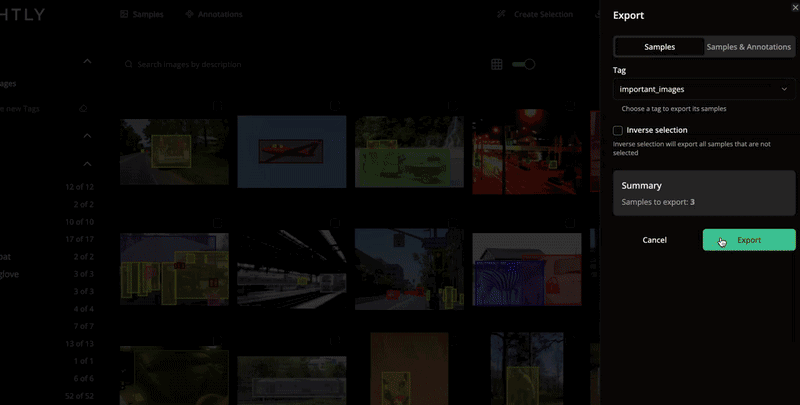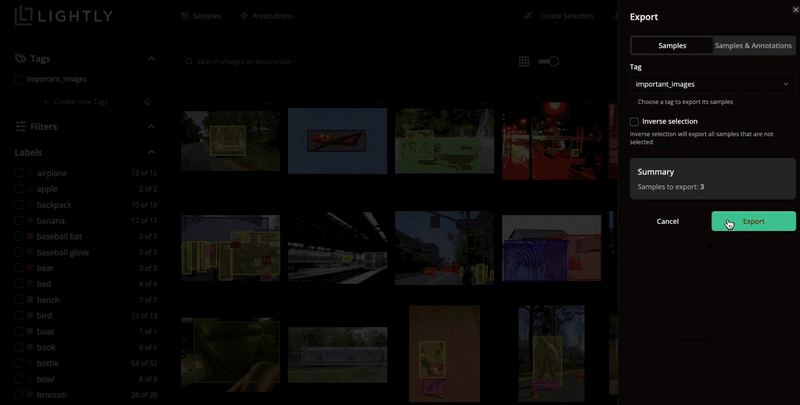
COCO Instance Segmentation
To run an instance segmentation example using a COCO dataset, create a file named
example_coco.py with the following contents in the same directory that contains
the dataset_examples/ folder:
Run the script via python example_coco.py. Now you can inspect samples with their assigned annotations in the app.
To run a caption example using a COCO dataset, create a file named example_coco_captions.py with the following contents in the same directory that contains the dataset_examples/ folder:
Run the script with python example_coco_captions.py. Now you can inspect samples with their assigned captions in the app.
LightlyStudio has a powerful Python interface. You can not only index datasets but also query and manipulate them using code.
The dataset is the main entity of the python interface. It is used to setup the dataset,
start the GUI, run queries and perform selections. It holds the connection to the
database file.
importlightly_studioasls# Different loading options:dataset=ls.Dataset.create()
# You can load data also from cloud storagedataset.add_samples_from_path(path="s3://my-bucket/path/to/images/")
# And at any given time you can append more data (even across sources)dataset.add_samples_from_path(path="gcs://my-bucket-2/path/to/more-images/")
dataset.add_samples_from_path(path="local-folder/some-data-not-in-the-cloud-yet")
# Load existing .db filedataset=ls.Dataset.load()
A sample is a single data instance, a dataset holds the reference to all samples. One can access samples individually and read or write on a samples attributes.
# Iterating over the data in the datasetforsampleindataset:
# Access the sample: see next section# Get all samples as listsamples=list(dataset)
# Access sample attributess=samples[0]
s.sample_id# Sample ID (UUID)s.file_name# Image file name (str), e.g. "img1.png"s.file_path_abs# Full image file path (str), e.g. "full/path/img1.png"s.tags# The list of sample tags (list[str]), e.g. ["tag1", "tag2"]s.metadata["key"] # dict-like access for metadata (any)# Set sample attributess.tags= {"tag1", "tag2"}
s.metadata["key"] =123# Adding/removing tagss.add_tag("some_tag")
s.remove_tag("some_tag")
...
Dataset queries are a combination of filtering, sorting and slicing operations. For this the Expressions are used.
fromlightly_studio.core.dataset_queryimportAND, OR, NOT, OrderByField, SampleField# QUERY: Define a lazy query, composed by: match, order_by, slice# match: Find all samples that need labeling plus small samples (< 500px) that haven't been reviewed. query=dataset.match(
OR(
AND(
SampleField.width<500,
NOT(SampleField.tags.contains("reviewed"))
),
SampleField.tags.contains("needs-labeling")
)
)
# order_by: Sort the samples by their width descending.query.order_by(
OrderByField(SampleField.width).desc()
)
# slice: Extract a slice of samples.query[10:20]
# chaining: The query can also be constructed in chained wayquery=dataset.match(...).order_by(...)[...]
# Ways to consume the query# Tag this subset for easy filtering in the UI.query.add_tag("needs-review")
# Iterate over resulting samplesforsampleinquery:
# Access the sample: see previous section# Collect all resulting samples as listsamples=query.to_list()
# Export all resulting samples in coco formatquery.export().to_coco_object_detections()
LightlyStudio offers a premium feature to perform automatized data selection. Selecting the right subset of your data can save labeling cost and training time while improving model quality. Selection in LightlyStudio automatically picks the most useful samples - those that are both representative (typical) and diverse (novel).
You can balance these two aspects to fit your goal: stable core data, edge cases, or a mix of both.
fromlightly_studio.selection.selection_configimport (
MetadataWeightingStrategy,
EmbeddingDiversityStrategy,
)
...
# Compute typicality and store it as `typicality` metadatadataset.compute_typicality_metadata(metadata_name="typicality")
# Select 10 samples by combining typicality and diversity, diversitydataset.query().selection().multi_strategies(
n_samples_to_select=10,
selection_result_tag_name="multi_strategy_selection",
selection_strategies=[
MetadataWeightingStrategy(metadata_key="typicality", strength=1.0),
EmbeddingDiversityStrategy(embedding_model_name="my_model_name", strength=2.0),
],
)
[0.4.0] - 2025-10-21 LightlyStudio released as preview version
We welcome contributions! Please check our issues page for current tasks and improvements, or propose new issues yourself.
.png)