.png)

"Beware of the Turing tar-pit in which everything is possibile, but nothing of interest is easy." - Alan Perlis 1982
What is of interest to you? Many things, I am certain. One such topic that I am constantly intrigued by is program optimization. Whether you are looking to compute the largest fibonacci number in one second, or creating the fastest financial transaction database ever written, or even just rewriting something in rust, you likely know how rewarding optimization can be.
Optimization separates the weak from the fast. Optimization isn't a thing of the past. Advances in technology shape the form of our programs, but don't negate the need to optimize. Well optimized programs save money, enable higher-tier scaling opportunities, and preserve system simplicity. Would you rather spend thousands to run shoddy code on autoscaling cloud infrastructure, or write better code, letting you use a handful of mid-tier servers at reduced latency and cost?
In this article I aim to explain the concept of low-level optimization, and why Zig is particularly well suited for it. If you enjoy what you read, please consider supporting me :)

Trust the compiler?
Some people would say "trust the compiler, it knows best." It sure does, for most low-level situations! Optimizing compilers have come a long ways. Increased system resources and advances in IR transformations have enabled compiler backends like LLVM to deliver impressive results.
Compilers are complicated beasts. The best optimizing backends will still generate sub-par code in some cases. In fact, even state-of-art compilers will break language specifications (Clang assumes that all loops without side effects will terminate). It is up to us to give our compilers as much information as possible, and verify that the compiler is functioning correctly. In the case of most low-level languages, you can generally massage your code until the compiler realizes it can apply a certain transform. In other situations, it's not so easy.
Why are low-level languages generally more performant? You might think the reason is that high level languages are doing a lot of extra work, such as garbage collection, string interning, interpreting code, etc. While you are right, this isn't *entirely* complete. High level languages lack something that low level languages have in great adundance - intent.
The verbosity of low level programming languages enable us to produce code that the compiler can reason about very well. As an example, consider the following JavaScript code:
function maxArray(x, y) { for (let i = 0; i < 65536; i++) { x[i] = y[i] > x[i] ? y[i] : x[i]; } }As humans, we can interpret this code as setting the values in x as the maximum of x and y. The generated bytecode for this JavaScript (under V8) is pretty bloated. As a comparison, here is what the function might look like if it were written in Zig:
fn maxArray( noalias x: *align(64) [65536]f64, y: *align(64) const [65536]f64, ) void { for (x, y, 0..) |a, b, i| { x[i] = if (b > a) b else a; } }In this more verbose language, we can tell the compiler additional information about our code. For example, the optimizer now knows about alignment, aliasing requirements, array sizes, and array element types - all at compile-time. Using this information, the compiler generates far superior, even vectorized code. If you were wondering, equivalent Rust code generates near identical assembly.
So can we *really* trust our compilers? It depends. Are you looking to uncover transformations to triple the throughput of your program's performance bottleneck? You should probably look at what the compiler is doing, and figure out if there are better ways to express *your intent* to the compiler. You may need to tweak the code to get the transforms you want. In the worst cases, you may discover that the compiler isn't applying optimal transforms to your code. In these cases, you may need to write inline assembly to squeeze out that last drop.
But what about high level code? Except for niche cases, the most we can do is reason about loops. In other words, compilers cannot change our algorithms and optimize our paradigms. Their scope is relatively narrow.
So where does Zig fall?
I love Zig for it's verbosity. Due to this verbosity, it's easier to write more performant programs than with most other languages. With Zig's builtin functions, non-optional pointers, unreachable keyword, well chosen illegal behavior, Zig's excellent comptime... LLVM is practically spoon-fed information about our code.
It isn't all rainbows though, there are tradeoffs. For example, Rust's memory model allows the compiler to always assume that function arguments never alias. You must manually specify this in Zig. If the compiler can't tell that your Zig function is always called with non-aliasing arguments, Rust functions will outperform the non-annotated Zig functions.
If we take in well-annotated LLVM IR as the *only* metric of a language's optimization capability, then Zig does well. This is not all that Zig has up it's sleeves. Zig's true optimization superpower lies in compile-time execution.

What is comptime?
Zig's comptime is all about code generation. Do you want to use a constant in your code? You can generate it at compile-time and the value will be embedded in the produced binary. Do you want to avoid writing the same hashmap structure for each type of data it can store? comptime has your back. Do you have data which is known at compile-time, and want the optimizer to elide code using this data? Yes, you can do this with comptime. Zig's comptime is an example of metaprogramming.
So how is this different from macros? It's pretty nuanced. The purpose of comptime is essentially the same as macros. Some macros will modify the raw text of your code, and others can modify your program's AST directly. This allows macros to inline code specific to the types and values of data in your program. In Zig, comptime code is just regular code running at compile-time. This code cannot have side-effects - such as network IO - and the emulated machine will match the compilation target.
The reason that Zig's comptime can match up so well to macros is twofold. Firstly, almost all Zig code can be run at compile-time, using comptime. Secondly, at compile-time, all types can be inspected, reflected, and generated. This is how generics are implemented in Zig.
The flexibility of Zig's comptime has resulted in some rather nice improvements in other programming languages. For example, Rust has the "crabtime" crate, which provides more flexibility and power than standard Rust macros. I believe a benefit of comptime over current alternatives lies in how seamlessly comptime fits into the Zig language. Unlike C++'s constexpr, you can use comptime without needing to learn a new "language" of sorts. C++ is improving, but it has a long ways to go if it hopes to compete with Zig in this domain.
So can Zig's comptime do *everything* macros can? Nope. Token-pasting macros don't have a mirror in Zig's comptime. Zig is designed to be easy to read, and macros which modify or create variables in a unrelated scopes just don't cut it. Macros can define other macros, macros can alter the AST, and macros can implement mini-languages, or DSLs. Zig's comptime can't directly alter the AST. If you really want to, you can implement a DSL in Zig. For example, Zig's print function relies on comptime to parse the format string. The print function's format string is a DSL of sorts. Based on the format string, Zig's comptime will construct a graph of functions to serialize your data. Here are some other examples of comptime DSLs in the wild: the TigerBeetle account testing DSL, comath: comptime math, and zilliam, a Geometric Algebra library.
Here are more resources for learning about Zig's comptime:
String Comparison with comptime:
How do you compare two strings? Here's an approach that works in any language:
function stringsAreEqual(a, b) { if (a.length !== b.length) return false; for (let i = 0; i < a.length; i++) if (a[i] !== b[i]) return false; return true; }We know that two strings aren't equal if their lengths aren't equal. We also know that if one byte isn't equal, then the strings as a whole aren't equal. Pretty simple, right? Yes, and the generated assembly for this function reflects that. There's a slight issue though. We need to load individual bytes from both strings, comparing them individually. It would be nice if there was some way to optimize this. We could use SIMD here, chunking the input strings and comparing them block by block, but we would still be loading from two separate strings. In most cases, we already know one of the strings at compile-time. Can we do better? Yes:
fn staticEql(comptime a: []const u8, b: []const u8) bool { if (a.len != b.len) return false; for (0..a.len) |idx| { if (a[idx] != b[idx]) return false; } return true; }The difference here is that one of the strings is required to be known at compile-time. The compiler can use this new information to produce improved assembly code:
isHello: cmp rsi, 7 jne .LBB0_8 cmp byte ptr [rdi], 72 jne .LBB0_8 cmp byte ptr [rdi + 1], 101 jne .LBB0_8 cmp byte ptr [rdi + 2], 108 jne .LBB0_8 cmp byte ptr [rdi + 3], 108 jne .LBB0_8 cmp byte ptr [rdi + 4], 111 jne .LBB0_8 cmp byte ptr [rdi + 5], 33 jne .LBB0_8 cmp byte ptr [rdi + 6], 10 sete al ret .LBB0_8: xor eax, eax retIs this not amazing? We just used comptime to make a function which compares a string against "Hello!\n", and the assembly will run much faster than the naive comparison function. It's unfortunately still not perfect. Because we know the length of the expected string at compile-time, we can compare much larger sections of text at a time, instead of just byte-by-byte:
const std = @import("std"); fn staticEql(comptime a: []const u8, b: []const u8) bool { const block_len = std.simd.suggestVectorLength(u8) orelse @sizeOf(usize); // Exit early if the string lengths don't match up if (a.len != b.len) return false; // Find out how many large "blocks" we can compare at a time const block_count = a.len / block_len; // Find out how many extra bytes we need to compare const rem_count = a.len % block_len; // Compare "block_len" bytes of text at a time for (0..block_count) |idx| { const Chunk = std.meta.Int(.unsigned, block_len * 8); const a_chunk: Chunk = @bitCast(a[idx * block_len ..][0..block_len].*); const b_chunk: Chunk = @bitCast(b[idx * block_len ..][0..block_len].*); if (a_chunk != b_chunk) return false; } // Compare the remainder of bytes in both strings const Rem = std.meta.Int(.unsigned, rem_count * 8); const a_rem: Rem = @bitCast(a[block_count * block_len ..][0..rem_count].*); const b_rem: Rem = @bitCast(b[block_count * block_len ..][0..rem_count].*); return a_rem == b_rem; }Ok, so it's a bit more complex than the first example. Is it worth it though? Yep. The generated assembly is much more optimal. Comparing larger chunks utilizes larger registers, and reduces the number of conditional branches in our code:
isHelloWorld: cmp rsi, 14 ; The length of "Hello, World!\n" jne .LBB0_1 movzx ecx, word ptr [rdi + 12] mov eax, dword ptr [rdi + 8] movabs rdx, 11138535027311 shl rcx, 32 ; Don't compare out-of-bounds data or rcx, rax movabs rax, 6278066737626506568 xor rax, qword ptr [rdi] xor rdx, rcx or rdx, rax ; Both chunks must match sete al ret .LBB0_1: xor eax, eax retIf you try to compare much larger strings, you'll notice that this more advanced function will generate assembly which uses the larger SIMD registers. Just testing against "Hello, World!\n" though, you can tell that we significantly improved the runtime performance of this function. (a was the runtime-only function, b was the same function where one argument was known at compile-time, and c was the more advanced function).
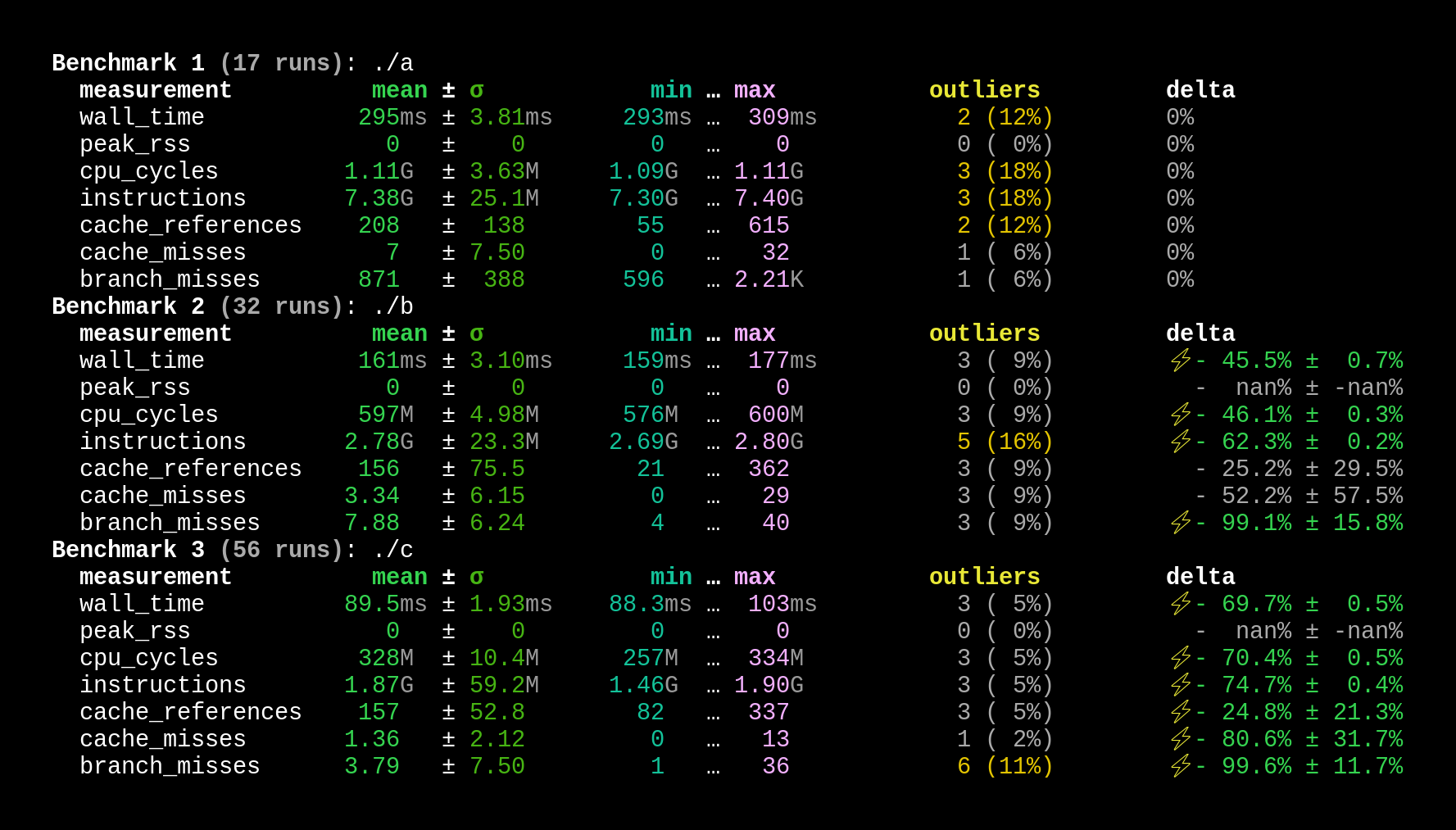
Runtime-known data at comptime:
Zig's comptime powers aren't limited to compile-time. You can generate some number of procedures at compile-time for simple cases, and dynamically dispatch to the right procedure, falling-back to a fully runtime implementation if you don't want to bloat your binary:
fn dispatchFn(runtime_val: u32) void { switch (runtime_val) { inline 0...100 => |comptime_val| { staticFn(comptime_val); }, else => runtimeFn(runtime_val), } } fn staticFn(comptime val: u32) void { _ = val; // ... } fn runtimeFn(runtime_val: u32) void { _ = runtime_val; // ... }Conclusion:
Is comptime useful? I would say so. I use it every time I write Zig code. It fits into the language really well, and removes the need for templates, macros, generics, and manual code generation. Yes, you can do all of this with other languages, but it isn't nearly as clean. Whenever I use Zig, I feel it's easier to write performant code for *actually useful* scenarios. In other words, Zig is not the "Turing tar-pit".
The possibilities are only limited to your imagination. If you are required to use a language without good generics, code generation, templates, macros, or comptime at your workplace, I feel sorry for you.
Hopefully you enjoyed this article. If you did, please consider supporting me. On a final note, I think it's time for the language wars to end. Turing completeness is all that we need, and the details fade away when we look for the bigger picture. Does this mean we can't have favorite languages? No, it does not. People will still mistakenly say "C is faster than Python", when the language isn't what they are benchmarking. On that note, enjoy this Zig propaganda: