.png)

Jürgen Schmidhuber often wears his heart on his sleeve and does so rather publicly via his much read personal website. Every now and then, his look-I-did-it-in-the-90s blog posts make it to the front page of Hackernews and well, in this case, Sabine Hossenfelder’s youtube channel too (See “Plagiarism Charges Against Nobel Prize for Artificial Intelligence”).
This particular episode on “Who invented Backpropagation (BP) ” (See original blog here) led me to one of the papers I had long bookmarked but never actually perused: H. J. Kelley’s “Gradient Theory of Optimal Flight Paths ”. ARS Journal, Vol. 30, No. 10, pp. 947-954, 1960.
Backpropagation (BP) is oft quipped as the backbone of modern AI. As so eloquently put in this auto-diff survey paper, BP converts the heady challenge of learning into a gradient descent adventure in the neural network’s weight space eventually reaching a decentish minima of the objective function being targeted. The terminology emerges rather organically as the process literally entails backward propagation of the sensitivity of the objective value at the output (See figure below).
There’s been somewhat of a mild consensus in the by lanes of history of AI that Kelley’s paper was the canonical work that brought BP into mainstream academic discourse and first presented the reasonably-recognizable precursor of modern backpropagation. (There’s an accompanying chapter on “Method of Gradients” published two years later as well)

Fascinatingly, when I got to the end of the paper, the acknowledgement section caught my attention (See image above). It read:
”Acknowledgments: The writer is pleased to acknowledge the contributions of Messrs. William P. O’Dwyer and H. Gardner Moyer of Grumman’s Computation Facility in handling the computational phase of this study on the IBM 704, and of Mrs. Agnes Zevens of the Systems Research Section in checking and preparing the numerical results for publication.”
This hit me like a ton of bricks for a very specific reason. I had recently learnt of a sinister arrangement of “sub-authorship” targeting women in science (and especially computing) where their contributions were systematically relegated to the marginalia (typically the “acknowledgments section”) rather than being awarded co-authorship. This was textbook rank-and-file Matilda Effect in front of me which triggered the urge to reach out and learn more about this paper’s back story. I must mention that I was emboldened by my previous success in this regard. Back in 2021, I reached out to Prof. Gertraud Fenk-Oczlon about “Konstanz im Kurzzeitgedächtnis - Konstanz im sprachlichen Informationsfluß?” published in 1980 which introduced the “Uniform Information Density” hypothesis to NLP literature. As it turns out, she was never credited for this work and none of the NLP-adjacent courses I took as a PhD student at CMU mentioned her work.

As it turns out, one the professors who had appropriated her work had reached out in 2020 and personally apologized whilst acknowledging that her work ought to have been cited!

So, as I began to search for Mrs. Agnes’ contact details, I chanced upon this page that read: “ZEVENS, AGNES STARIN, also known as AGNES MICHALOWSKI, AGNES ZEVENS MICHALOWSKI and AGNES STARIN, was born 3 February 1920, is listed with the following 3 birthplaces: NEW YORK MAN, New York; N Y C, New York; NEW YORK CIT, New York, daughter of RICHARD STARIN (father) and HELEN THYM, was assigned Social Security number 104-03-9459 (indicating New York), and died 24 May 1999, while residing in Zip Code 11714-5910 (Bethpage, New York, within Nassau County).”
The dates did line up. The project that Mrs. Zevens was allocated to began roughly in 1958 funded by Organization of Aerospace research, USAF (See image below) and it was typical for senior women in their late thirties to be allocated to such important numerical jousts.

The locations too lined up. Grumman’s research facilities were located exactly in the hometown where she had resided: Bethpage, NY.
So, yeah, the code-reviewer-PM of the pioneering back-prop paper project had passed away in 1999 during the AI winter of the ‘90s without so much as a blimp. Am sure there are many such Mrs.Agneses out there buried in the Acknowledgement sections. If someone from Google scholar team ever reads this, here’s an utterly doable reasonable fix: Scrape the acknowledgement sections of all the papers you have archived in this era, extract the authors, run them through your SOTA name disambiguation pipelines and posthumously cite them. It is the least we can do! (Citation-puritans can go bleep themselves).
A few trivia-hued concluding thoughts: The original MCP - Mars Colonization Project (MCP) in AI , Markup aesthetics of parenthesized citations and miniscule computing magic of IBM 704
One of the most famous stories in AI tech-lore is one that unfolded in 2012 when Elon Musk gave Demis Hassabis a tour of SpaceX headquarters and described Mars as a “backup planet” in case something went wrong with humanity on Earth. Apparently, Hassabis responded by asking, “What if AI was the thing that went wrong?” and stated how easy it would be for the rogue-AI to follow humanity to Mars through our communication systems and destroy the colony there.
This apocryphal tale is also oft used to ground the metaphysical nexus between X.ai and SpaceX as also as a real-world Proof-of-Polymathism of the visionary behind these ambitious projects.
To me it’s both uncanny and yet weirdly reasonable that the pioneering work on the workhorse-algorithm of modern AI quite literally targeted finding the minimum time planar flight paths from Earth’s orbit to the orbit of Mars as the marquee numerical application to sell its efficacy.
One of the unexpected quirky challenges of reading Kelly’s paper was the formatting and the ensuing notational dissonance. As it turns out, certain journals in those days mandated usage of parentheses for citations and square brackets to denote equations. It is but reasonable to assume that familiar notation is processed more easily; deviations require extra cognitive effort and feel “wrong” or uncomfortable and it did!

Given the recent pixel-fetish-brouhaha about modeling text using pictures of text, I wonder how such idiosyncrasies in the pre-training datasets will usher in corner cases that are currently not seen with textual data modeling with, err, text. (See this fascinating video from the recent tokenization workshop below).
For now, likes of Gemini seem to be navigating this ambiguity just fine!
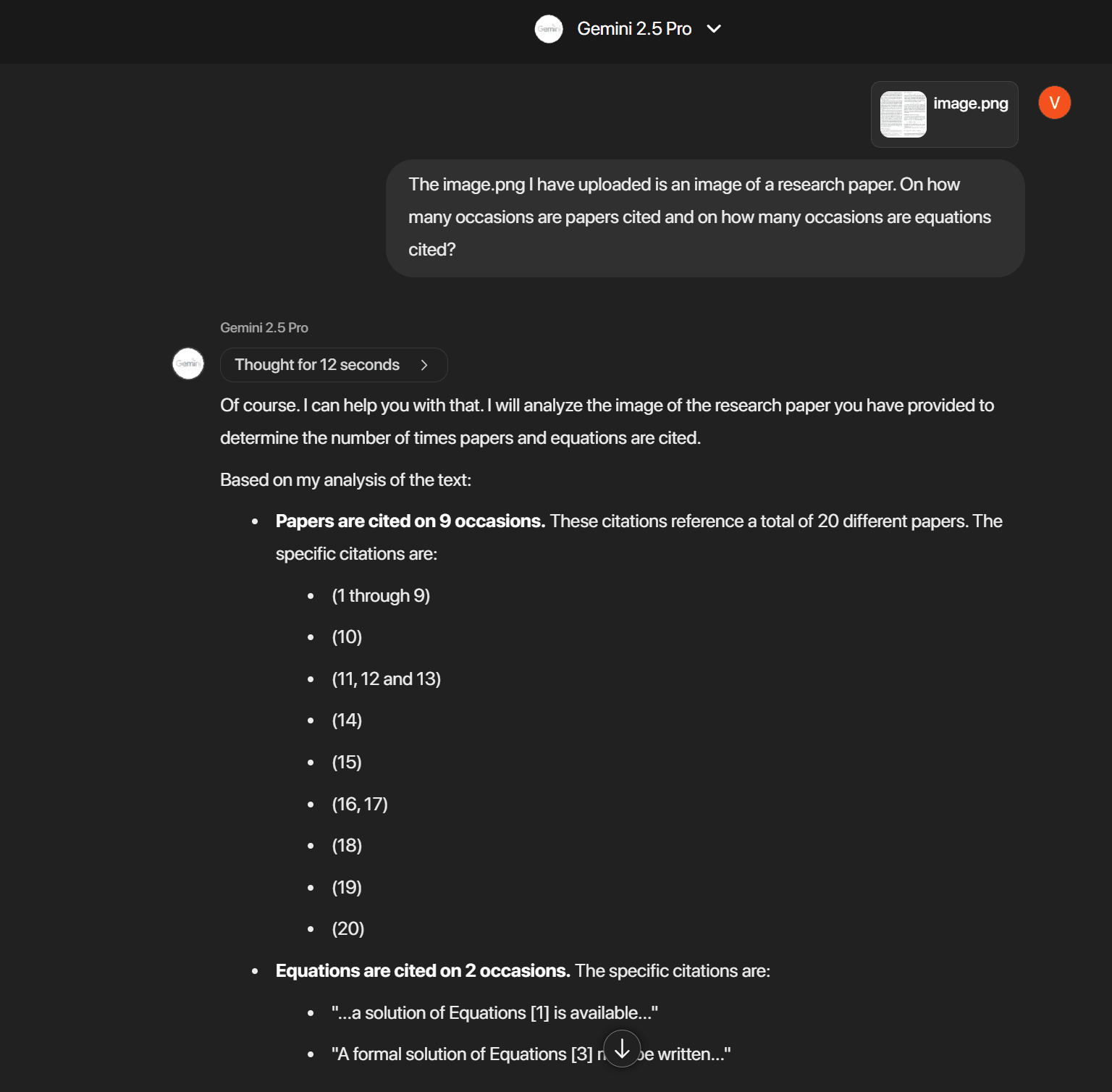
These days, it is a norm to flaunt the vulgarity of GPU silicon real estate you were able to throw at the model slop being peddled in the AI/LLLM papers. The flaunt in Kelly’s paper was the IBM 704 whose stats just blew my mind. I am going to write down my CliffsNotes in a pointwise manner and will probably visit and revisit them every now and then just to relive the early days of the conquest of the comp-core monoculture that conquered humanity (and to also remind myself to never label myself GPU-poor)
Introduced in 1954, 704 was the first mass-produced computer with hardware for floating-point arithmetic and regarded as “pretty much the only computer that could handle complex math”.
Was a vacuum-tube machine and failed around every 8 hours
Peaked out at 12000 floating-point additions per second
Ran FORTRAN and LISP
One 38-bit accumulator, one 36-bit multiplier/quotient register, and three 15-bit index registers. That’s it!


