.png)

As large language models increasingly take on reasoning-intensive tasks in areas like math and science, their output lengths are getting significantly longer—sometimes spanning tens of thousands of tokens. This shift makes efficient throughput a critical bottleneck, especially when deploying models in real-world, latency-sensitive environments.
To address these challenges and enable the research community to advance the science behind reasoning models, NVIDIA developed Nemotron-H-47B-Reasoning-128K and Nemotron-H-8B-Reasoning-128k. Both models also are available in FP8 quantized variants. All were developed from the Nemotron-H-47B-Base-8K and Nemotron-H-8B-Base-8K foundation models.
The most capable model in this family, Nemotron-H-47B-Reasoning, delivers significant inference-time speedups compared to similarly sized transformer models. Notably, it offers close to 4x greater throughput than Llama-Nemotron Super 49B V1.0, supports 128K token contexts, and matches or exceeds the accuracy for reasoning-heavy tasks. The Nemotron-H-8B-Reasoning-128k model also shows similar trends when compared to the Llama-Nemotron Nano 8B V1.0 model.
These results demonstrate that hybrid architectures like Nemotron-H can be post-trained just as effectively as pure Transformer models—while also providing significant advantages in throughput and context length.
A key feature of the new Nemotron-H Reasoning model family is its ability to operate in both reasoning and non-reasoning modes. Users can opt in to receive outputs with detailed intermediate steps or instruct the model to respond concisely—depending on the task. When no preference is specified, the model intelligently selects the best strategy on its own. This kind of flexible control makes it easy to adapt the model to a variety of use cases.
NVIDIA is releasing the four Nemotron-H Reasoning models under an open research license, and we invite the community to build, test, and innovate with them. Model cards and model weights are available here:
- Nemotron-H-47B-Reasoning-128k
- Nemotron-H-47B-Reasoning-128k-FP8
- Nemotron-H-8B-Reasoning-128k
- Nemotron-H-8B-Reasoning-128k-FP8
Training stages
The training pipeline began with supervised fine-tuning (SFT), using curated examples that include explicit reasoning traces—enclosed in <think> tags—to guide the model through step-by-step problem-solving before reaching a final answer. These traces often represent multiple possible solution paths and encourage the model to explore alternatives and iterate, improving accuracy. However, the added verbosity also increases inference cost, especially for longer traces.
To balance this, we introduced paired examples with the reasoning stripped out, allowing the model to learn when and how to respond directly. This dual-format training helps the model adapt fluidly to different reasoning requirements.
Stage 1: Mastering math, code and science reasoning
The first phase of fine-tuning focused on math, science, and coding—domains where explicit reasoning is especially valuable. The training data here used a 5:1 ratio of reasoning to non-reasoning samples, and some of these examples are available publicly in the Llama-Nemotron-Post-Training-Dataset. Over 30,000 steps with a batch size of 256, the model showed consistent improvements on internal STEM benchmarks.
Stage 2: Expanding instructional coverage, dialogue and safety
The second phase shifted toward instruction following, safety alignment, and multi-turn dialogue—while continuing to sample from Stage 1 to retain strong STEM performance. This dataset was more compact—about 10x smaller—and offered a balanced mix of reasoning and non-reasoning samples. This helped the model generalize across a broader range of tasks while improving control over reasoning mode switching.
Training for long contexts
To support 128K-token contexts, we trained the model on synthetic sequences reaching up to 256K tokens. These were built by stitching together shorter conversations (from the Stage 2 training data) and augmenting them with tasks designed to stress long-range memory. For example, we included:
- Follow-up questions referencing earlier turns
- Long document-based QA requiring deep passage understanding
- Cross-referenced multi-turn chat
- Keyword aggregation tasks with distractors
These examples encouraged the model to develop robust long-context attention patterns. We evaluated this capability using the RULER benchmark in non-reasoning mode. The model achieved an 84% RULER score, compared to just 46% for Llama-Nemotron under the same 128K-token conditions—an indication of substantial gains in long-context handling.
Reinforcement learning with GRPO
After SFT, we applied Group Relative Policy Optimization (GRPO) in multiple phases. Each phase targeted specific skills—like instruction following or tool use—by creating task-specific datasets with automatic verifiers, followed by broader fine-tuning with a general reward model.
Instruction-following tuning
To strengthen instruction adherence, we sampled 16,000 prompts from the LMSYS Chat dataset and paired them with IFEval-style instructions. A rule-based verifier scored outputs based on how well they satisfied each instruction, creating a reward signal that prioritized following directions with precision.
Function calling with abstention
We next trained on approximately 40,000 valid tool-use examples from Glaive V2 and Xlam. To build robustness, we added 10,000 negative samples where the correct function call was impossible—rewarding the model for recognizing when to abstain. This balanced, 50K-sample dataset enabled the model to become more discerning in tool use.
General helpfulness via reward model
In the final RL phase, we use a Qwen-32B-based reward model (scoring 92.8 on RewardBench) to improve overall response helpfulness. Using prompts from HelpSteer2, we ran about 200 steps of GRPO. While short, this final stage led to noticeable gains in output quality, particularly in tool use and instruction adherence.
Controlled reasoning at inference
Inference-time behavior can be customized using simple control tags in the system prompt:
- {'reasoning': True} triggers reasoning mode
- {'reasoning': False} triggers direct-answer mode
- Omitting the tag lets the model choose
Our Jinja chat template detects these control strings and modifies the assistant’s response accordingly. When {'reasoning': True} is present, the response is prefixed with Assistant:<think>\n, indicating the start of a reasoning trace. When {'reasoning': False} is found, the response is prefixed with Assistant:<think></think>, signaling a non-reasoning response. This mechanism resulted in near 100% control of reasoning or non-reasoning modes.
Final results
Across benchmarks in math, coding, science, tool use, and dialogue, Nemotron-H-47B-Reasoning-128K delivers accuracy on par with or better than Llama-Nemotron Super 49B V1.0 and outperforms Qwen3 32B on all non-coding benchmarks. The model also supports post-training quantization applied to all linear layers, achieving efficient deployment with minimal accuracy loss. Lastly, we provide checkpoint and results from this quantized version to demonstrate its effectiveness in practice.
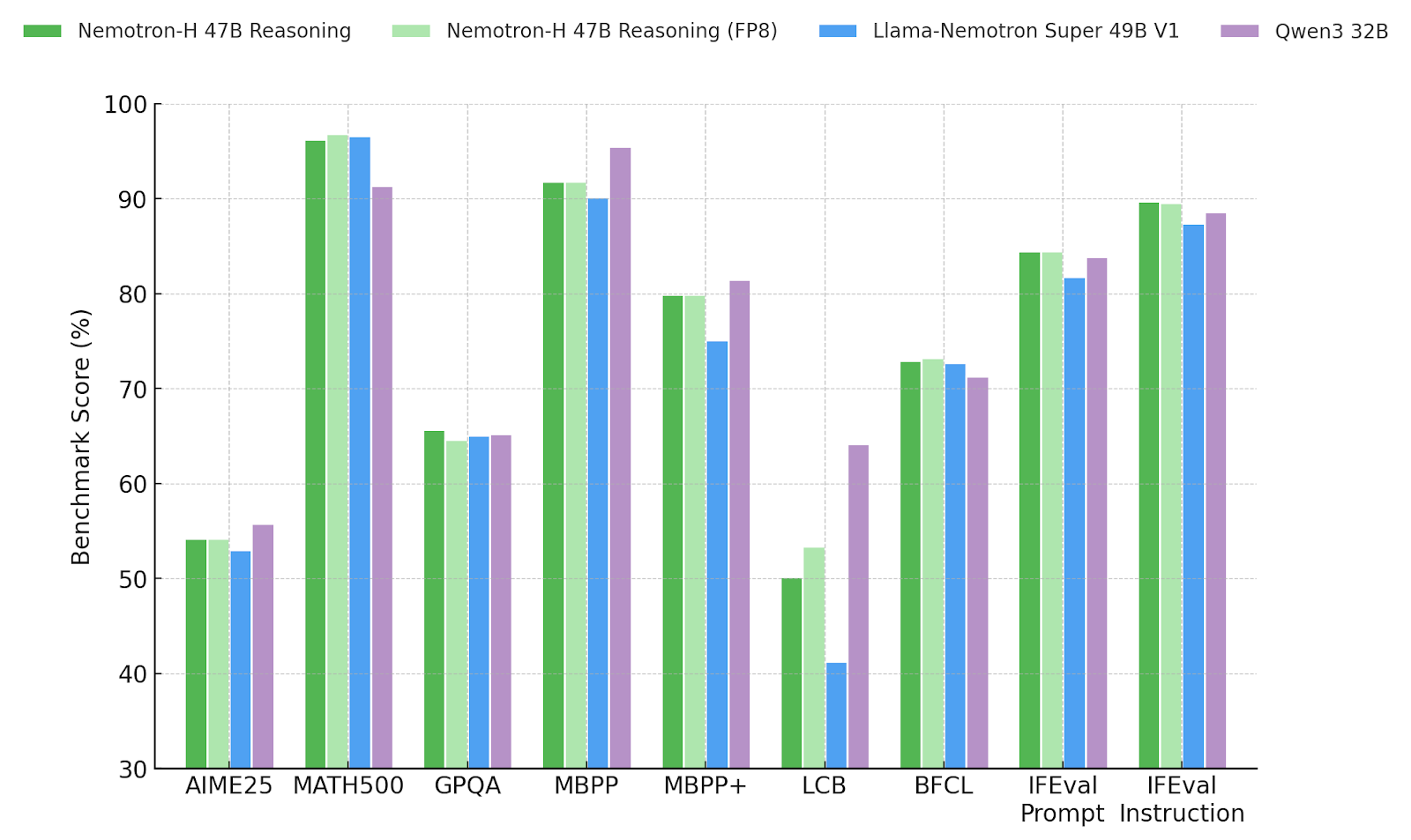 Figure 1. Benchmark scores for Nemotron-H 47B Reasoning, Llama-Nemotron Super V1, and Qwen3 32B. All models were evaluated using our internal evaluation pipeline to ensure consistency.
Figure 1. Benchmark scores for Nemotron-H 47B Reasoning, Llama-Nemotron Super V1, and Qwen3 32B. All models were evaluated using our internal evaluation pipeline to ensure consistency.Whether your application demands transparency, precision, or speed, Nemotron-H-47B-Reasoning offers a versatile and high-performing foundation.
Throughput comparisons
Thanks to its hybrid Mamba-Transformer architecture, Nemotron-H-47B-Reasoning delivers significant inference-time speedups compared to similarly sized Transformer-only models. The figure below presents average benchmark accuracy versus inference throughput for a reasoning-style workload. We use Megatron-LM to benchmark the maximum achievable throughput on two NVIDIA H100 GPUs in BF16, where each model processes short input sequences (128 tokens) and generates extended reasoning traces (32K output tokens). To maximize per-GPU throughput, we select the largest batch size that fits for each model.
 Figure 2. Benchmark scores compared to throughput for Nemotron-H 47B Reasoning and competing models.
Figure 2. Benchmark scores compared to throughput for Nemotron-H 47B Reasoning and competing models.Our internal evaluation pipeline—used to ensure consistent, apples-to-apples comparisons—shows that Qwen3 achieves the highest average benchmark score, followed closely by Nemotron-H-47B-Reasoning. Notably, Nemotron-H delivers approximately 4x higher throughput than the Transformer-based baselines.
Contributors
Yian Zhang, David Mosallanezhad, Bilal Kartal, Dima Rekesh, Luis Vega, Haifeng Qian, Felipe Soares, Julien Veron Vialard, Gerald Shen, Fei Jia, Ameya Mahabaleshwarkar, Samuel Kriman, Sahil Jain, Parth Chadha, Zhiyu Li, Terry Kong, Hoo Chang Shin, Anna Shors, Roger Waleffe, Duncan Riach, Cyril, Meurillon Matvei, Novikov, Daria Gitman, Evelina Bakhturina, Igor Gitman, Shubham Toshniwal, Ivan Moshkov, Wei Du, Prasoon Varshney, Makesh Narsimhan Sreedhar, Somshubra Majumdar, Wasi Uddin Ahmad, Sean Narenthiran, Mehrzad Samadi, Jocelyn Huang, Siddhartha Jain, Vahid Noroozi, Krysztof Pawelec, Twinkle Vashishth, Oleksii Kuchaiev, Boris Ginsburg, Mostofa Patwary, and Adithya Renduchintala



