.png)

Claude models are known for their good coding capabilities, but recent Claude models (Claude 3.7 Sonnet, Claude Sonnet 4) tend to output full code files for coding tasks, even when your prompt asks for just the changes.
In this post, we share our experiments on this behaviour, the findings, and how to solve this issue if you just want the changes.
Prompt and Model Behavior
To investigate this phenomenon, we experimented with Claude models and other leading LLMs on our sample Next.js TODO app modification task. By testing different variations of the prompt, we analyzed which combination of prompts and models would output only code changes versus the entire file.
The basic "TODO task prompt" (reproduced below) contains instructions "Only show the relevant code that needs to be modified. Use comments to represent the parts that are not modified". We expect models with good instruction following ability to follow the instruction and output only the changes.
TODO task prompt:
add created_at field to todos, update both backend and frontend. Instructions for the output format: - Output code without descriptions, unless it is important. - Minimize prose, comments and empty lines. - Only show the relevant code that needs to be modified. Use comments to represent the parts that are not modified. - Make it easy to copy and paste. - Consider other possibilities to achieve the result, do not be limited by the prompt.Our experiment results show that different models exhibit different levels of instruction adherence in terms of outputting only the changes.
Specifically, Claude 3.7 Sonnet and Claude Sonnet 4 gave the full output for the simple coding change. On the other hand, Claude 3.5 Sonnet and GPT-4.1 gave the concise output with only the changes.
Example Output from Claude Sonnet 4 and GPT-4.1 with basic "TODO task" prompt:
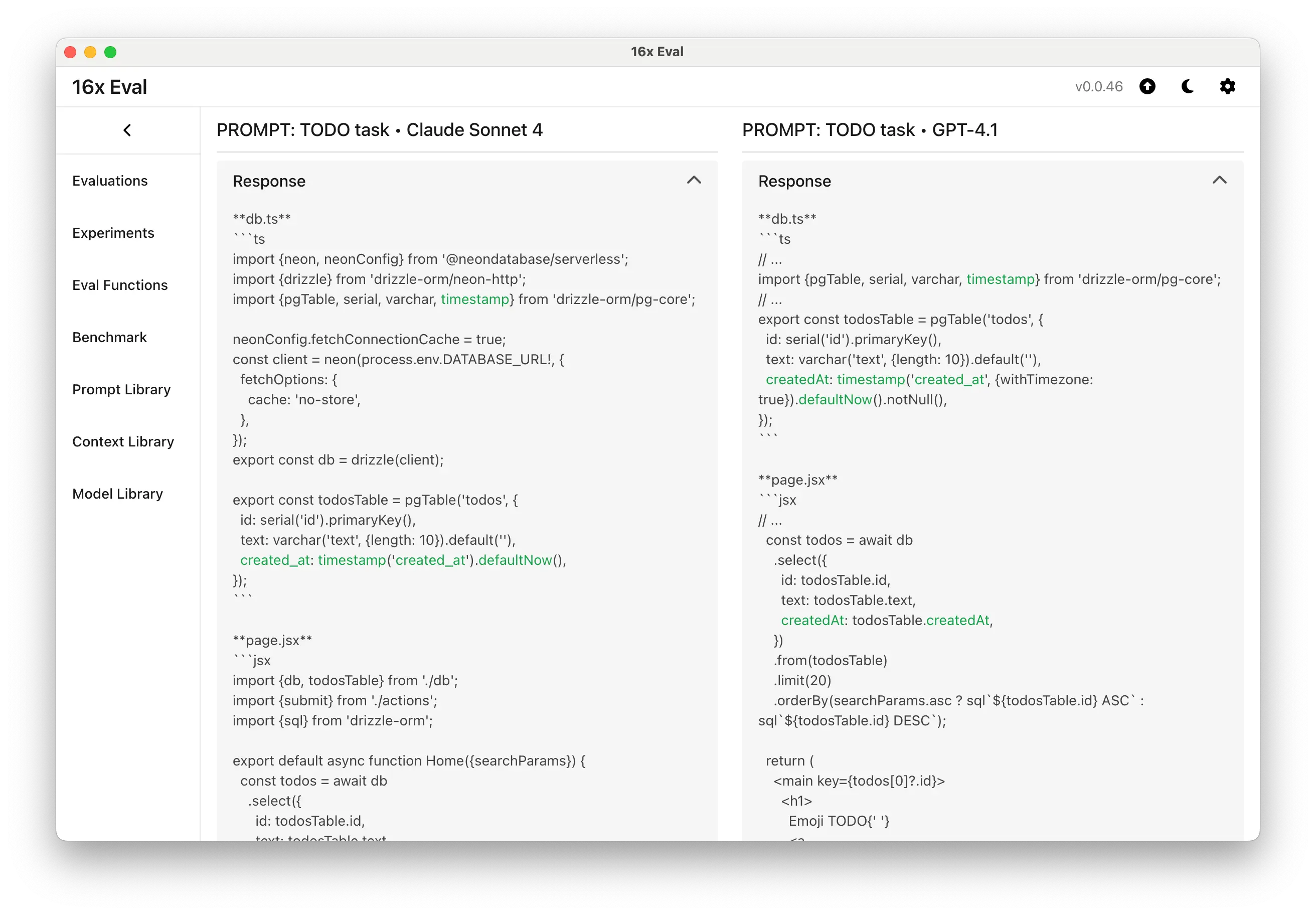 Claude Sonnet 4 gave the full output, whereas GPT-4.1 gave the concise output with only the changes.
Claude Sonnet 4 gave the full output, whereas GPT-4.1 gave the concise output with only the changes.Example Output from Claude 3.5 Sonnet and Claude 3.7 Sonnet with basic "TODO task" prompt:
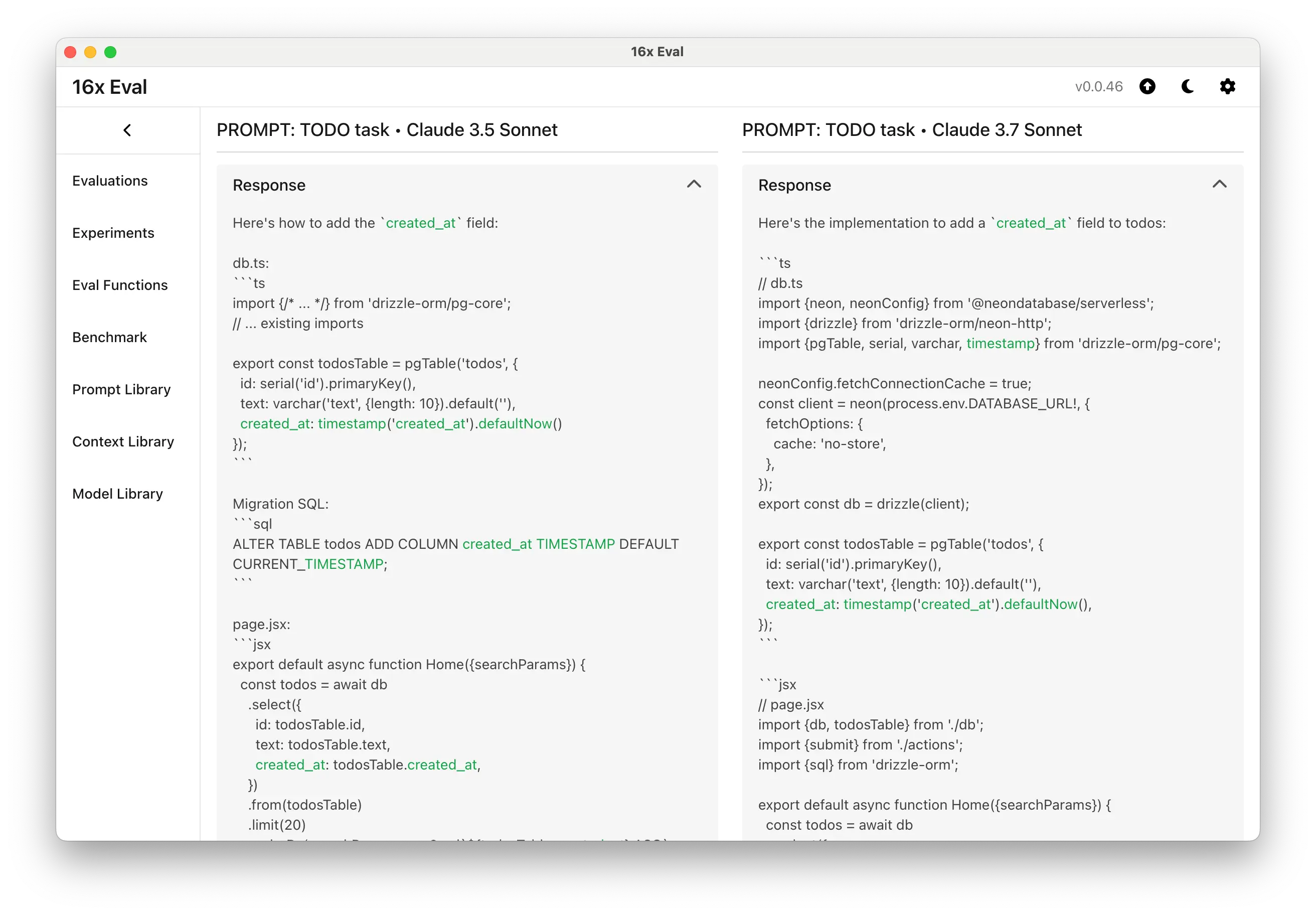 Claude 3.5 Sonnet gave only changes, whereas Claude 3.7 Sonnet gave the full output.
Claude 3.5 Sonnet gave only changes, whereas Claude 3.7 Sonnet gave the full output.We then created a variation of the prompt to apply stronger instructions for only outputting the changes, by adding the instructions "Do NOT output full code", and "Only output parts that need to be changed" to the prompt. We call this prompt "TODO task (Claude)".
TODO task (Claude) prompt:
add created_at field to todos, update both backend and frontend. Instructions for the output format: - Output code without explanation, unless it is important. - Minimize prose, comments and empty lines. - ONLY show the relevant code that needs to be modified. Use comments to represent the parts that are not modified. - Do NOT output full code. Only output parts that need to be changed. - Make it easy to copy and paste. - Consider other possibilities to achieve the result, do not be limited by the prompt.Using this prompt variant, we were able to make Claude Sonnet 4 output only the changes, instead of full code:
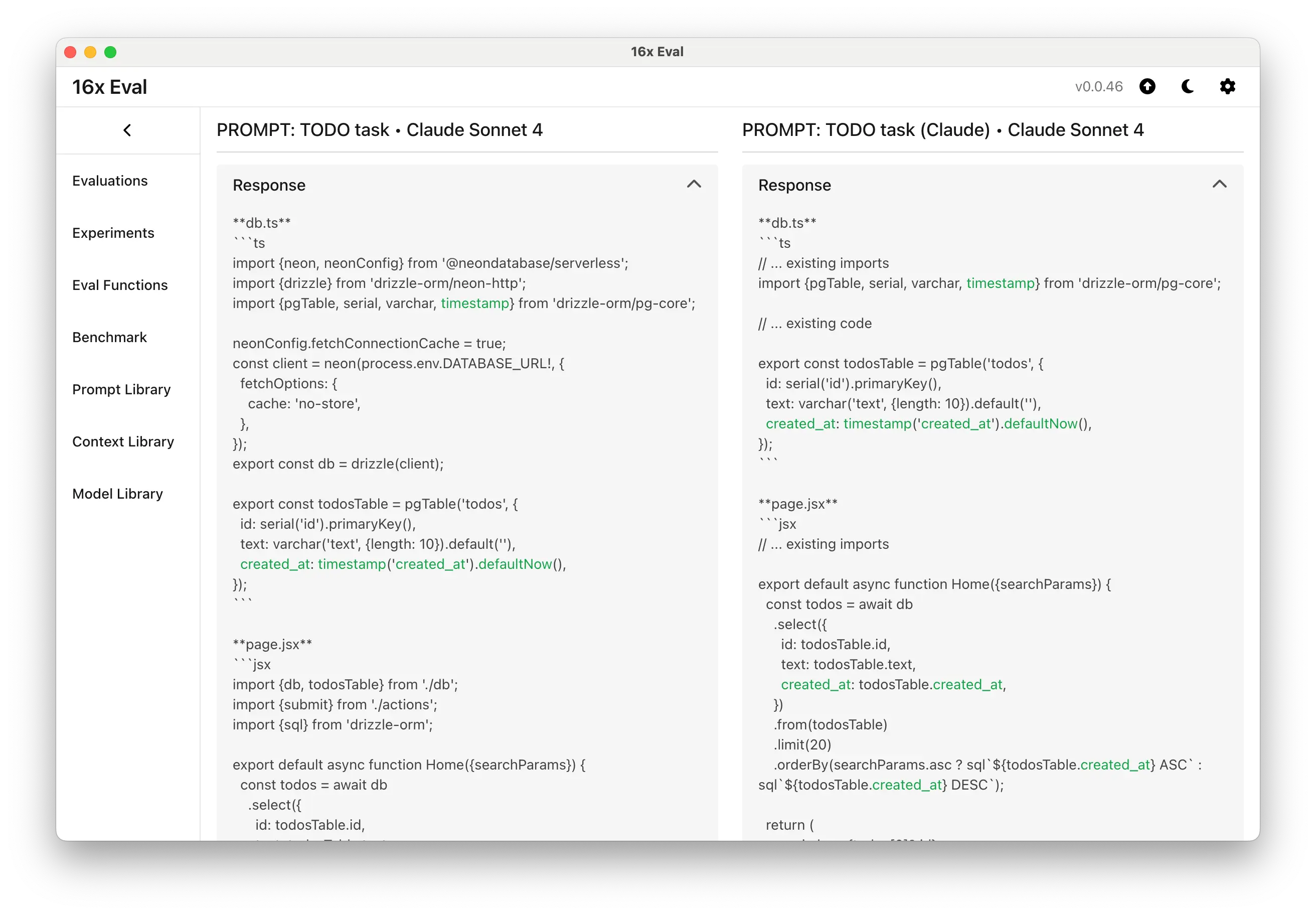 With the "TODO task (Claude)" prompt, Claude Sonnet 4 output only the changes, instead of the full code
With the "TODO task (Claude)" prompt, Claude Sonnet 4 output only the changes, instead of the full codeExperiment Results and Findings
We then tested various models with the basic "TODO task" prompt and "TODO task (Claude)" prompt. The results are shown below:
| Claude 3.5 Sonnet | TODO task | Moderate | Only code changes | Follows instruction |
| Claude 3.7 Sonnet | TODO task | Moderate | Full code output | Ignores instruction |
| Claude 3.7 Sonnet | TODO task (Claude) | Strong | Full code output | Ignores instruction |
| Claude Sonnet 4 | TODO task | Moderate | Full code output | Ignores instruction |
| Claude Sonnet 4 | TODO task (Claude) | Strong | Only code changes | Follows instruction |
| GPT-4.1 | TODO task | Moderate | Only code changes | Follows instruction |
| Gemini 2.5 Pro | TODO task | Moderate | Only code changes, verbose | Follows instruction |
| Gemini 2.5 Pro | TODO task v2 (concise) | Moderate | Only code changes | Follows instruction |
Key Findings:
- Claude 3.7 Sonnet always outputs full files, even with strong prompts.
- Claude Sonnet 4 respond to strong, repeated instructions ("Do NOT output full code. Only output parts that need to be changed."), but not the initial prompt.
- GPT-4.1 consistently outputs only the requested code changes with standard, concise prompts. No aggressive prompt engineering is required.
- Gemini 2.5 Pro defaults to verbose output but becomes concise with direct instruction like "Be concise."
Read more about Gemini 2.5 Pro's behavior in our post on dealing with Gemini 2.5 Pro verbosity
See the full evaluation details in our eval-data repo.
Possible Reasons for Full Code Outputs
While Anthropic has not provided any official explanation for this behavior, there are a few possible reasons why newer Claude models default to full-file outputs:
- Training Data Bias: They're likely trained on datasets where responses often include whole files, making verbosity a "safe default."
- Safety & Context: Presenting the full file helps avoid missing context or mistakes, and is clearer for those not used to code diffs.
- Model Design Choices: Emphasis on helpfulness and comprehensiveness means verbose outputs.
These tendencies have become stronger with new versions. The default now is verbosity unless you request otherwise.
Getting Concise Outputs
- For Claude Sonnet 4: Use direct, forceful instructions—for example, "Do NOT output full code. Only show the changes."
- For Claude 3.7 Sonnet: Our tests show even the strongest prompt won't suppress verbose output; concise outputs from prompts alone are not achievable. Use Claude Sonnet 4 instead.
- For Gemini 2.5 Pro: Add "Be concise." to the prompt. Instruct directly to limit prose and output only changed code.
- For GPT-4.1: Standard concise prompts ("only show code changes") work reliably.
Test and Compare Yourself
Our experiment shows that you can adapt your prompts to model quirks for better results. Tools like 16x Eval let you test different combinations of models and prompts and compare the results easily to find what works best for your use case.
 Screenshot of a sample evaluation from 16x Eval
Screenshot of a sample evaluation from 16x Eval
