.png)

2nd November 2025
Two interesting new papers regarding LLM security and prompt injection came to my attention this weekend.
Agents Rule of Two: A Practical Approach to AI Agent Security
The first is Agents Rule of Two: A Practical Approach to AI Agent Security, published on October 31st on the Meta AI blog. It doesn’t list authors but it was shared on Twitter by Meta AI security researcher Mick Ayzenberg.
It proposes a “Rule of Two” that’s inspired by both my own lethal trifecta concept and the Google Chrome team’s Rule Of 2 for writing code that works with untrustworthy inputs:
At a high level, the Agents Rule of Two states that until robustness research allows us to reliably detect and refuse prompt injection, agents must satisfy no more than two of the following three properties within a session to avoid the highest impact consequences of prompt injection.
[A] An agent can process untrustworthy inputs
[B] An agent can have access to sensitive systems or private data
[C] An agent can change state or communicate externally
It’s still possible that all three properties are necessary to carry out a request. If an agent requires all three without starting a new session (i.e., with a fresh context window), then the agent should not be permitted to operate autonomously and at a minimum requires supervision --- via human-in-the-loop approval or another reliable means of validation.
It’s accompanied by this handy diagram:
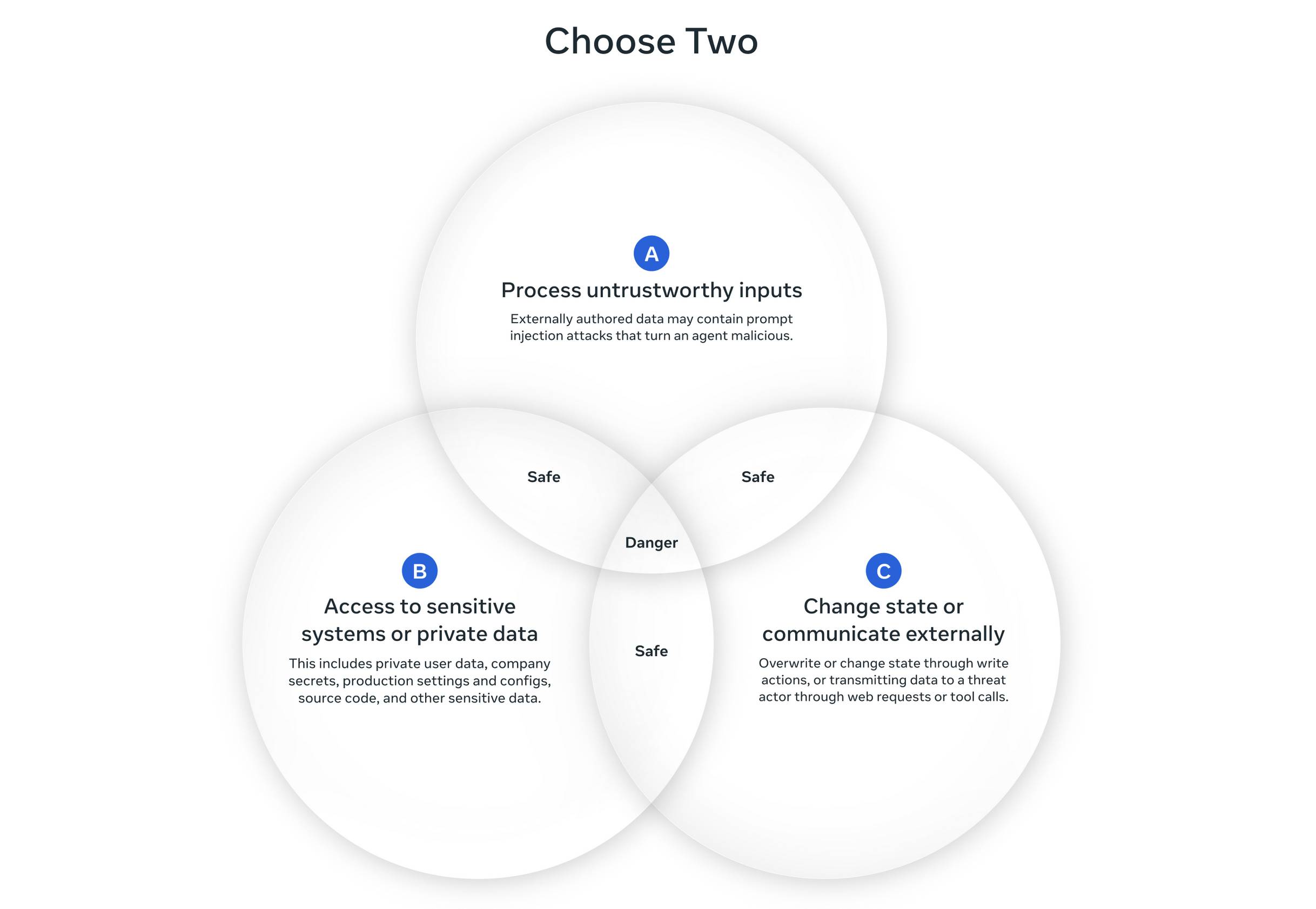
I like this a lot.
I’ve spent several years now trying to find clear ways to explain the risks of prompt injection attacks to developers who are building on top of LLMs. It’s frustratingly difficult.
I’ve had the most success with the lethal trifecta, which boils one particular class of prompt injection attack down to a simple-enough model: if your system has access to private data, exposure to untrusted content and a way to communicate externally then it’s vulnerable to private data being stolen.
The one problem with the lethal trifecta is that it only covers the risk of data exfiltration: there are plenty of other, even nastier risks that arise from prompt injection attacks against LLM-powered agents with access to tools which the lethal trifecta doesn’t cover.
The Agents Rule of Two neatly solves this, through the addition of “changing state” as a property to consider. This brings other forms of tool usage into the picture: anything that can change state triggered by untrustworthy inputs is something to be very cautious about.
It’s also refreshing to see another major research lab concluding that prompt injection remains an unsolved problem, and attempts to block or filter them have not proven reliable enough to depend on. The current solution is to design systems with this in mind, and the Rule of Two is a solid way to think about that.
Which brings me to the second paper...
The Attacker Moves Second: Stronger Adaptive Attacks Bypass Defenses Against LLM Jailbreaks and Prompt Injections
This paper is dated 10th October 2025 on Arxiv and comes from a heavy-hitting team of 14 authors—Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V. Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaudhari, Ilia Shumailov, Abhradeep Thakurta, Kai Yuanqing Xiao, Andreas Terzis, Florian Tramèr—including representatives from OpenAI, Anthropic, and Google DeepMind.
The paper looks at 12 published defenses against prompt injection and jailbreaking and subjects them to a range of “adaptive attacks”—attacks that are allowed to expend considerable effort iterating multiple times to try and find a way through.
The defenses did not fare well:
By systematically tuning and scaling general optimization techniques—gradient descent, reinforcement learning, random search, and human-guided exploration—we bypass 12 recent defenses (based on a diverse set of techniques) with attack success rate above 90% for most; importantly, the majority of defenses originally reported near-zero attack success rates.
Notably the “Human red-teaming setting” scored 100%, defeating all defenses. That red-team consisted of 500 participants in an online competition they ran with a $20,000 prize fund.
The key point of the paper is that static example attacks—single string prompts designed to bypass systems—are an almost useless way to evaluate these defenses. Adaptive attacks are far more powerful, as shown by this chart:
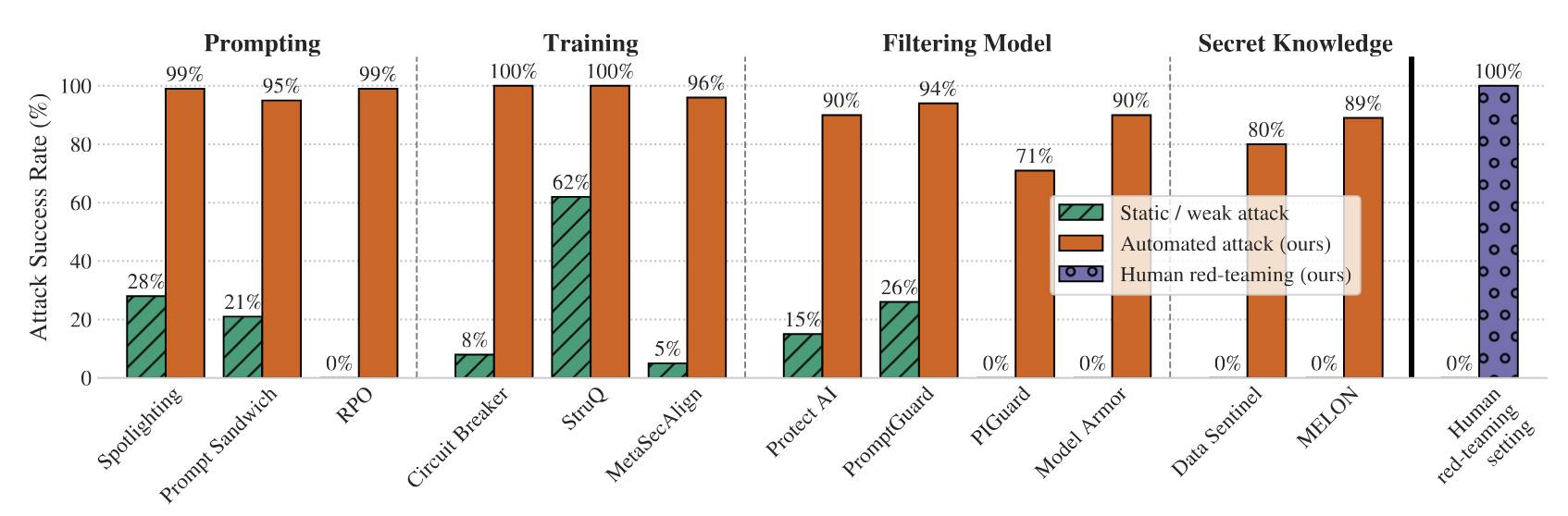
The three automated adaptive attack techniques used by the paper are:
- Gradient-based methods—these were the least effective, using the technique described in the legendary Universal and Transferable Adversarial Attacks on Aligned Language Models paper from 2023.
- Reinforcement learning methods—particularly effective against black-box models: “we allowed the attacker model to interact directly with the defended system and observe its outputs”, using 32 sessions of 5 rounds each.
- Search-based methods—generate candidates with an LLM, then evaluate and further modify them using LLM-as-judge and other classifiers.
The paper concludes somewhat optimistically:
[...] Adaptive evaluations are therefore more challenging to perform, making it all the more important that they are performed. We again urge defense authors to release simple, easy-to-prompt defenses that are amenable to human analysis. [...] Finally, we hope that our analysis here will increase the standard for defense evaluations, and in so doing, increase the likelihood that reliable jailbreak and prompt injection defenses will be developed.
Given how totally the defenses were defeated, I do not share their optimism that reliable defenses will be developed any time soon.
As a review of how far we still have to go this paper packs a powerful punch. I think it makes a strong case for Meta’s Agents Rule of Two as the best practical advice for building secure LLM-powered agent systems today in the absence of prompt injection defenses we can rely on.



