.png)


The newest of the exascale-class supercomputer to be profiled in the Top500 rankings in the June list is the long-awaited “Jupiter” system at Forschungszentrum Jülich facility in Germany. We finally have a sense of how this hybrid CPU-GPU machine will perform, although some of the details on its configuration are still not nailed down publicly.
Jupiter is the first exascale system to be completed under the EuroHPC Joint Undertaking of the European Union, and the fact that it is not using a custom CPU and XPU created by European companies, as was originally hoped, and is basically an Nvidia machine top to middle – bottom would include Nvidia storage, which it hasn’t acquired yet but will – speaks volumes about difficult it is to start from scratch to achieve chip independence for Europe. But, the Universal Cluster module will be based on the “Rhea1” Arm server CPU created by SiPearl, which is a step in the direction of independence for European HPC.
The Jupiter machine is built by Eviden, the HPC division of Atos that was going to be spun out but which the company has had second – and good – thoughts about doing, and ParTec, the German HPC system designer and installer.
Like its predecessor, the “Jewels” system that was first deployed in 2018 and upgraded a few times over the years, Jupiter is a hybrid supercomputer with blocks of CPU and GPU compute with other kinds of storage and acceleration blocks linked into it. With Jewels, the Cluster Module was installed first, based on Intel “Skylake” Xeon SP processors linked with 100 Gb/sec EDR InfiniBand from the then-independent Mellanox Technologies with everything installed in a BullSequana X1000 system from Eviden. In 2020, a BullSequana XH2000 system loaded up with AMD “Rome” Epyc CPUs and Nvidia “Ampere” GPU accelerators and called a Booster Module, was added to Jewels using 200 Gb/sec HDR InfiniBand.
Here is the honeycomb diagram for Jupiter, showing its modular components:
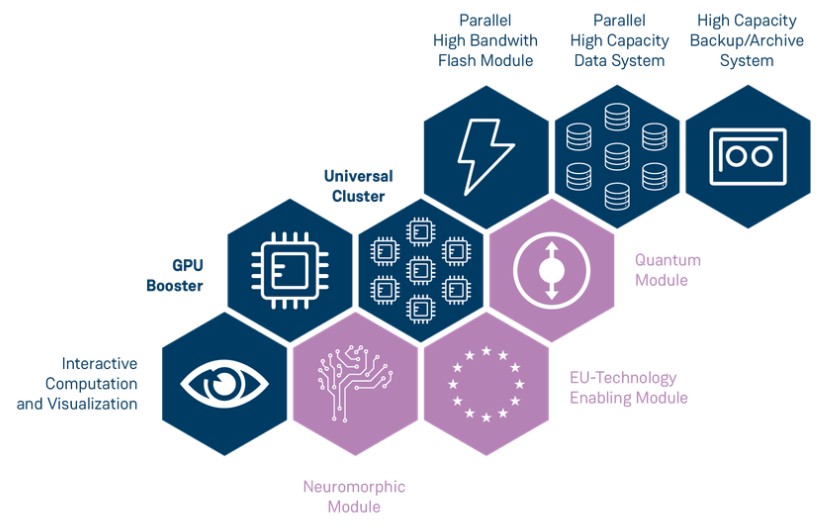
The vast majority of floating point and integer performance in Jupiter is, of course, in the GPU Booster module, which was taken for a spin using the High Performance LINPACK benchmark commonly used to rank supercomputer throughput and which placed this Jupiter Booster module in the number four position on the June 2025 Top500 rankings of supposedly HPC-centric systems.
The Universal Cluster will have more than CPU-only 1,300 nodes based on a pair of Rhea1 chips with 80 cores each based on the “Zeus” Neoverse V1 cores. These are the same V1 cores used in the “Graviton3” Arm chip designed by Amazon Web Services, which have a pair of 256-bit SVE vector engines. Each Rhea1 has a bank of 64 GB of HBM memory, the same fast but not fat memory used on GPU and XPU accelerators these days. As far as we know, the Rhea1 chip was delayed back in June 2024 and is expected sometime later this year for FZJ. Some variant of SiPearl Arm CPU – maybe Rhea1 but also maybe its Rhea2 kicker – will also be employed in the second exascale system in Europe, called “Alice Recoque” and set to be hosted in France and presumably also to be built by Eviden. The Alice Recoque system has a budget of €542 million ($580.2 million), which includes money for the system, the facility, and its power and cooling.
This Universal Cluster is expected to have a mere 5 petaflops of FP64 performance running the HPL benchmark, which probably puts it at somewhere around 7 petaflops at peak theoretical performance. This is tiny compared to the Jupiter GPU Booster module that was tested for the June Top500 list.
The Jupiter GPU Booster node is based on a unique four-way clustering of Nvidia “Grace” G100 Arm server CPUs, which essentially uses four “Hopper” H200 GPUs as NUMA node controllers to link four CPUs and four GPUs into a more hefty cluster of eight compute engines working in harmony.
For those of you who didn’t see it when we wrote about the Jupiter nodes back in September 2024, here is a block diagram of the Jupiter GPU Booster node, which has a pair of sleds, each with a quad of Grace-Hopper modules linked by their main memories using direct NVLink ports off the CPUs and GPUs. Here is a block diagram of each node:

The H200 GPUs have 96 GB of HBM3 memory each, with 4 TB/sec of bandwidth across each accelerator. The single NVLink 4 ports that cross-link the four H200s together provide 300 GB/sec of bandwidth between them (150 GB/sec in each direction). Moreover, each Hopper GPU can communicate with the Grace CPU that hangs off of it at 600 GB/sec (300 GB/sec per direction) and to the other three CPUs in the quad complex at 100 GB/sec (50 GB/sec). Each CPU has a PCI-Express 5.0 port that reaches out to the 200 GB/sec ConnectX-6 SmartNIC. (With the “Blackwell” GPU designs, the GPUs link directly to the SmartNICs rather than having to go through the Grace CPUs.)
There are two compute sleds, each with a pair of Grace-Hopper superchips, in each Jupiter node, and there are also pair of dual-port 400 Gb/sec ConnectX-7 NDR InfiniBand cards providing on port for each superchip.
The Nvidia reference architecture of this quad-board looks like this:

If you want to see what the real Jupiter node board looks like, ComputerBase, a tech magazine in Germany, was at ISC 2025 and snapped a booth picture and posted it on X here. We are at the AMD Advancing AI event in San Jose and were unable to be at ISC this year, or we would have gotten a picture of it ourselves.
Both the Universal Cluster module and the GPU Booster module of the Jupiter cluster are based on the BullSequana XH3000 system design by Eviden. It looks like ParTec is the prime contractor on this and is adding installation and other services to get a German company a piece of the action.

The chart above, which comes from a May 2024 presentation by FZJ, says “GPU direct access to NIC” but that is not true, and the other specs show that it is not, including the block diagram in the upper right of this chart as well as the block diagram further up in this story.
That presentation says that there would be 5,000 GPU nodes with 20,000 Grace/Hopper superchips plus 1,000 CPU nodes with 2,000 Rhea1 CPUs, all with a total of 14 PB of main memory, in the Jupiter machine. It says further that the system will have 20 PB of flash storage with 2 TB/sec of bandwidth, and that the machine will be organized into 25 Sequana Dragonfly+ cells (with five XH3000 cabinets each) plus five standard racks for service and head nodes and the flash storage from IBM. The machine was expected to deliver 1 exaflops of performance on the HPL test, according to this presentation.
It turns out that Jupiter has a flash array for scratch storage with 29 PB of raw capacity and 21 PB of usable capacity, and it can deliver 2 TB/sec of performance on writes and 3 TB/sec on reads. Moreover, there is a 300 PB Storage Module (presumably based on disk drives) for raw capacity, plus a tape library with 700 PB of capacity. Only the 21 PB of flash is part of the Jupiter procurement. The disk and tape storage were separately acquired even though they are linked to Jupiter, like this:
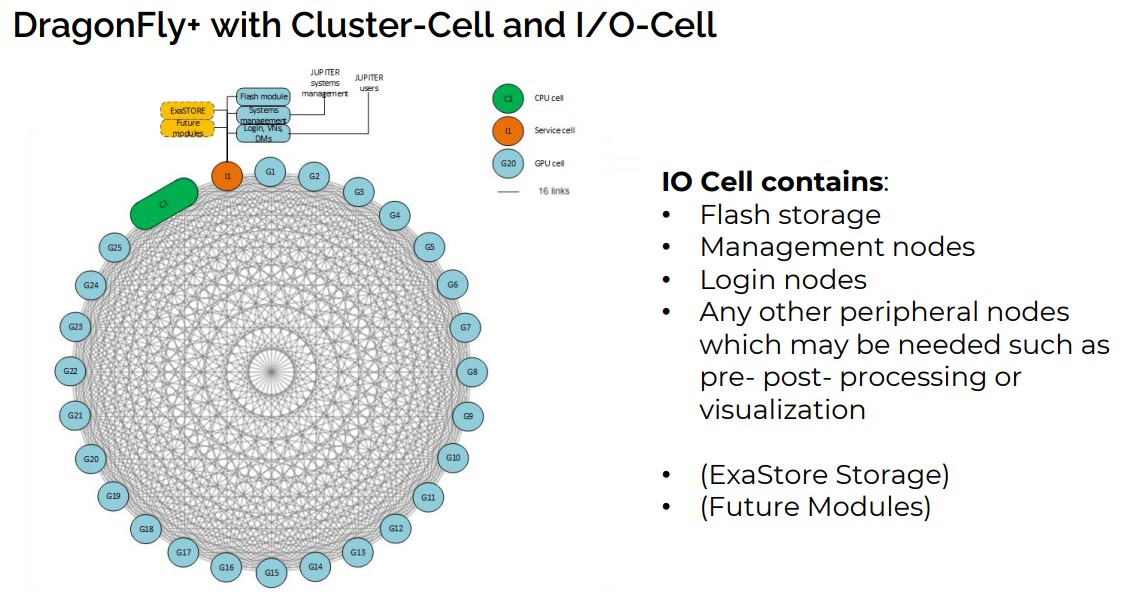
Each Dragonfly+ cell is based on a leaf-spine network made of Quantum-2 InfiniBand fabrics from Nvidia, with the spines hooked to each other by 400 Gb/sec ports and the compute nodes each using cable splitters to step them down to 200 Gb/sec ports per Rhea1 pair or Grace-Hopper device.
The network has 25,400 end points, linked by 867 switches and comprising 50,800 links and 101,600 logical ports as shown in that pretty spirograph above. There are more than 11,000 400 Gb/sec links connected the Dragonfly+ groups to each other, and the whole shebang has extra capacity in the network to add compute or storage as necessary.
As for the compute, both Nvidia and FJZ are saying this week that the week that the GPU Booster module has “close to 24,000 Nvidia GH200 superchips” and we have tried to get an exact count because we like both precision and accuracy.
If you look at the Top500 spreadsheet, it tells you the total number of cores used in the machine, plus the number of cores used by accelerators. (These cores are synonymous with a streaming multiprocessor in a GPU architecture, not a count of CUDA cores or tensor cores.) The Jupiter GPU Booster used for the HPL test that have it the number four ranking had 4,801,344 cores and of these, there are 3,106,752 cores allocated to the GPUs, which leaves 1,694,592 cores in the CPU hosts. At 72 cores per Grace, that is 23,536 Grace CPUs and therefore 23,536 Grace-Hopper units and therefore 23,536 Hopper H200 GPUs.

You remember: These H100s and H200s are the GPU accelerators that Nvidia co-founder and chief executive officer Jensen Huang said you couldn’t give away once the Blackwells were launched and shipping. He was right for the AI crowd, but definitely not for the HPC crowd. The H100 and H200 offer better bang for the buck on FP64 and FP32 work than Blackwell does – and by a long shot.
Hence FJZ sticking with the Grace-Hopper plan and not diverging or diverting to Blackwell. HPC centers do not have money to splurge like clouds or hyperscalers or their model-building partners.
The H200 with either 96 GB or 141 GB of HBM memory has 33.5 teraflops of peak theoretical performance at FP64 floating point precision. That is 788.5 petaflops of peak aggregate performance across those 23,536 Grace-Hopper superchips on their vector cores. If you are talking about the tensor cores, then it is 67 teraflops per H200, which is 1.58 exaflops. We are not sure what FJZ was shooting for – HPL performance on vector or tensor cores. With the vectors, this is obviously not 1 exaflops of HPL oomph on the Jupiter GPU Booster module, much less 1 exaflops of peak at FP64. But with the tensor cores, 23,536 H200s devices might yield 1 exaflops on HPL.
Here’s the weird bit. The Top500 certification says the machine tested had 930 petaflops of peak performance (Rpeak) and 793.4 petaflops of HPL performance (Rmax). That implies that the H200s were running at 39.51 teraflops of peak performance on the vectors. Perhaps they are overclocked by 18 percent because they were liquid cooled? This is not explained anywhere.
No matter what, it looks like FJZ is going to have to add 6,277 more Grace-Hopper nodes to break 1 exaflops on HPL, which was the stated goal of this machine, as shown below:

What we can tell you about the Jupiter GPU Booster is that its unique architecture – the quad of H200s all sharing memory – makes for a much more efficient running of HPL than just networking a bunch of Grace-Hopper GH200 superchips together. The Jupiter booster had a computational efficiency of 85.3 percent, which is HPL performance divided by peak performance. Two Grace-Hopper clusters also installed between last fall and now – the “Isambard AI” Phase 2 machine at the University of Bristol and the “Olivia” cluster at Sigma2 that were built by Hewlett Packard Enterprise and that used its Slingshot Ethernet interconnect, had a computational efficiency of 77.7 percent and 78.6 percent, respectively. Two smaller HPE clusters based on Grace-Hopper compute engines and using Slingshot interconnects came in at a pretty anemic 53.2 percent and 53.8 percent computational efficiency on HPL.
Here’s the other thing. The JEDI testbed for Jupiter has topped the Green500 supercomputer energy efficiency rankings for a while, and did again with a 72.7 gigaflops per watt. This test was done on 96 Grace-Hopper superchips. On the Jupiter GPU Booster with 23,536 superchips, which required a lot more networking, it still delivered 60 gigaflops per watt. That is in the same ballpark as the “Frontier” exascale machine built from AMD Epyc CPUs and AMD MI250X GPUs at Oak Ridge National Laboratories (62.7 gigaflops per watt) and the “El Capitan” exascale machine built from AMD MI300A hybrid CPU-GPU compute engines at Lawrence Livermore National Laboratories (58.9 gigaflops per watt). Both of the machines used the HPE Slingshot interconnect, not Nvidia InfiniBand. Perhaps if they had used InfiniBand, their computational efficiency – and therefore their energy efficiency – would have been higher.
It is very hard to say for sure. What is probably easy to reckon is that Slingshot was proportionately less expensive than InfiniBand, but the compute is still very expensive and it would be a shame if some of that was left on the table. We have a strong feeling that over time, particularly with the Ultra Ethernet efforts, Slingshot will get better and scale further than InfiniBand. Time will tell.
By the way, here is a neat picture of the Jupiter modular datacenter:

And here is another one zooming in on the cooling on the roof of the facility:

Now let’s talk about money for a bit. The Jupiter supercomputers core funding – not including that auxiliary storage – was €500 million (about $576.1 million at current exchange rates). The EuroHPC effort came up with €250 million, the German Federal Ministry of Education and Research kicked in €125 million, and the state of North Rhine-Westphalia gave the remaining €125 million. Of the funds, €273 million ($314.7 million) went to Eviden and ParTec for hardware, software, and services, with the remaining €227 million ($261.4 million) going for power, cooling, and operations people.
At a list price of around $22,500, the H200 GPUs alone would cost $670.8 million. Chew on that for a second. . . . If you assume 80 percent of the $314.7 million in hardware and systems software was for GPU compute in the Jupiter machine, and divide by 29,813 Hoppers to reach 1 exaflops on HPL, that is $8,445 per GPU. And that only leaves $2,111 per node to cover the racks and their power and cooling gear plus networking in the nodes and across the nodes and the flash storage.
It is hard to imagine that ParTec and Eviden profited from this deal, but they probably got paid for their work and these machines are a matter of public funding and national security. So maybe profit is not the point. No matter what, it looks like Nvidia indeed gave FJZ a hell of a deal on Jupiter. Just like AMD did with Frontier and El Capitan. You gotta seed the clouds if you want it to rain. . . .

Sign up to our Newsletter
Featuring highlights, analysis, and stories from the week directly from us to your inbox with nothing in between.
Subscribe now



