.png)

October 23, 2025#133 Programming Theory
PETSCII/ASCII Conversion
Let's talk about PETSCII and ASCII, what they are and how to convert between them properly and losslessly. There are some examples on the internet that are not right, and there are some nuances that make it more complicated than it seems at first glance.
ASCII was developed to standardize the codes used by different types of early computers and teletype (and teletype-like) machines. At this time, computers generated output by printing to paper. Although it is an "American" standard code of information interchange, several of the characters were designed for internationalization, by combinations that can only be done on paper.
For example, the "Back Space", which became ubiquitous on PCs for "delete," on paper truly is a back "space." It causes the print head to move back one space so that it's positioned above where the previous character was printed. Symbols like, caret (^), tilde (~), and backtick (`), which we use today to mean or perform certain technical functions, are actually meant as accents over letters in foreign words. Such as: aĉeti, España, or très.
Once computers started having text displays on screens, like virtual terminals, these tricks of combining multiple characters on paper became more complicated.
ASCII is a 7-bit code, therefore there are only 128 characters, code values from 0 to 127. And these are divided into blocks of 32 characters. The first block is for control sequences, usually used to control the teletype machine or regulate data flow between two machines. For example, XON and XOFF, known from software flow control, are 17 and 19, which are in the first block, and defined as device control characters. Block 2 is used for numbers and most punctuation. Block 3 is used for uppercase letters, plus some additional symbols, and block 4 is used for lowercase letters, and a few more symbols.
How is PETSCII different
There is general confusion over what PETSCII is. Is it that cool graphical character set that PETSCII graphics are famed to make use of? Well, kinda, sorta, but not really.
PETSCII is an equivalent code to ASCII, but designed for the Commodore PET and used by all Commodore 8-bit computers. Why did Commodore reinvent the wheel? Why not just use ASCII instead of creating a whole new and only partly compatible information code?
For one, the aforementioned 7-bit nature of ASCII. That may have been useful to save bandwidth. For example, an RS-232 transmission could be configured for one start bit, one stop bit, 7-bit words, plus one parity bit for a total of 10 bits per character transmitted. If the code required 8-bit words, that's 11 bits per character. Which, believe it or not is 10% (!) more overhead. It would be almost 10% slower, therefore, to transmit the same message. Commodore 8-bit computers are so categorized because their CPU processes data 8-bits at a time. It makes little sense to use a 7-bit code with an 8-bit CPU.
Commodore wanted to make use of other characteristics of the codes to make some things easier to program, and save space in the ROMs. For example, in the character set ROM, the upper half of the set is the reverse of the lower half. This means that if you have an "a" on the screen, and you want to show a blinking cursor, that can be done by toggling between the standard "a" and the reverse "a", and that can be done merely by XORing the byte with %10000000, thus toggling the high bit on and off. Super convenient.

Commodore PET 2001
However, that's just the character set, it's not the PETSCII information code itself. But PETSCII also uses this same correspondence technique between the upper and lower halves of the code. As an 8-bit code, it has 8 blocks of 32-bytes. Block 1 is for control characters, just like in ASCII. But the corresponding Block 5 is also for control characters. Why would they do that? Certain control characters that are at the same index in both blocks—therefore togglable by just flipping the high bit—are the inverse of one another. For example, $0E is the code to switch to text mode (lowercase/uppercase character set), and $8E is the code to switch to graphics mode (uppercase/graphics character set.) Another example, $12 turns reverse mode on, but $92 turns reverse mode off. These are the inverse of each other, and if you have one you can obtain the other by toggling bit 7 (the highest bit, since bits are numbered 0 to 7.)
Similarly, the alphabetic characters have a correspondence. The difference between the upper and lowercase letters is the flip of bit 7. Bit 7 is also special in the 6502/6510 machine language. If bit 7 is set, the number is negative. Therefore, you can load a character and branch on whether its in the upper or lower half of the code set without needing to do a comparison first. LDA somechar, and then you can branch right away using BMI or BPL based on the state of bit 7. Bit 7 can also be rolled onto or from the carry, very easily. And the special BIT instructions can test the state of bit 7, adjusting the status register but without modifying the accumulator, X or Y registers. These features are all quite convenient while doing tight, efficient, assembly programming in a computer with very little memory.

MOS 6502, 8-bit CPU.
Although the keyboard handling code in the KERNAL ROM is done with lookup tables, it is still conceptually (and usually actually) the case that SHIFT plus some key will produce the corresponding PETSCII value to the one without the SHIFT key held, where the shifted value just has the high bit set. A few more examples are in order. Cursor Down is $11 and Cursor Right is $1D. Both of these are in the Block 1 control characters. No SHIFT key is held to select these, you just press the two cursor keys. Likewise, Cursor Up is $91 and Cursor Left is $9D. Both are the inverse with just the high bit set, putting them in Block 5, but they are also entered on the keyboard by pressing the same keys but with the SHIFT key held. It is as though the lower half of PETSCII is unshifted and the upper half is obtained with SHIFT. The reality is slightly more complicated, but if it weren't for pesky (that's pesky not PETSCII) exceptions, they probably wanted it to work this way.
Position of alphabetic characters
Let's think about the position of the alphabetic characters.
When the Commodore 64 starts up, it is in uppercase/graphics mode. That is implemented by changing a register in the VIC-II so that it reads the character set from an adjacent 2KB block of memory. In the Character ROM are two 2KB character sets, side-by-side in the computer's addressing space. $D000-$D7FF (2048 bytes, or 2KB) and $D800-$DFFF (another 2048 bytes.)
Why did they choose uppercase characters plus graphics characters as the default? I don't know. Maybe because BASIC is primarily not a mixed-case language. Maybe because extra graphics characters were just more useful than mixed-case text, most of the time. I'm not sure of their reasoning.
But in any case, when you type on the keyboard without holding the SHIFT key, you are producing PETSCII lowercase characters. And these get rendered as uppercase while the uppercase/graphics character set is selected. When you press keys while holding SHIFT, naturally, you produce uppercase characters in the PETSCII encoding. With the default character set, these render as graphical symbols. When you swap character sets (either with SHIFT+COMMODORE or by printing the text PETSCII control code, $0E) then the character set matches the PETSCII code and, evidently, any letters typed without SHIFT are lowercase and any typed with SHIFT are uppercase.
Therefore, we may surmise that uppercase characters are in the upper half of PETSCII, and at a corresponding place as their lowercase equivalents. And that is true. Lowercase letters, i.e., those typed without holding SHIFT, are in Block 3, while uppercase letters are in Block 7. Thus "a" ($41) and "A" ($C1) correspond, and only bit 7 needs to be toggled to make the difference between them.
Comparison to ASCII
In ASCII, the uppercase letters are in Block 3 and the lowercase letters are in Block 4. Where as in PETSCII, the lowercase letters are in Block 3 and the uppercase letters are a toggle-of-bit-7 away, or Block 7.
Therefore, A HA! PETSCII has simply rearranged the blocks of ASCII, right? And thus to convert, we just shuffle the blocks around. PETSCII Block 3 becomes ASCII Block 4. PETSCII Block 7 becomes ASCII Block 3. Easy, right? Well, not so fast.
Remember that some of those ASCII characters were meant for combining on paper to form accents and other text ornaments. For example, underscore, although we use it for weird things on computers today, it's original purpose was to draw an underline. How did that work? You send a 5-letter word, then you send 5 backspace characters, then you send 5 underscore characters. Bingo, the word remains on the page, the backspaces reposition the print head, the underscores overlay an underline beneath the word. But on a Commodore computer's screen you cannot combine characters in that way, so what is the point in keeping the underscore around?
ASCII Table, from asciitable.com.
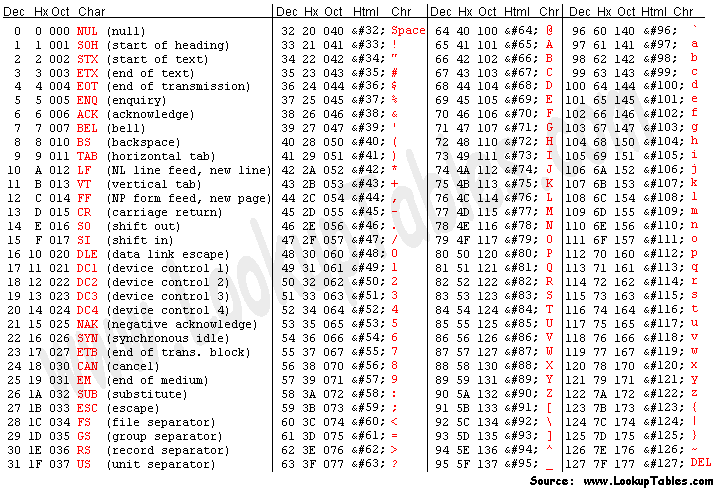
At the same spot in ASCII where the underscore appears ($5F), in PETSCII it's a left-pointing arrow. What exactly is a left pointing arrow supposed to mean and how did they intend it to be used? I have no idea. It's been interpreted in various ways through the years, to mean back or escape, etc., but one thing is for certain, it isn't used to draw an underline. Similarly, the caret ($5E), which was meant to appear above a letter, in PETSCII it's up-pointing arrow with a stem. In BASIC this is used to represent a mathematical power, like 3^3 = 9, but it renders as 3↑3 = 9. There is nonetheless an obvious correspondence, between the caret glyph and the up-arrow glyph, but why not include the stem since it can't be combined with other characters on the screen?
Other examples become a bit more arbitrary. For example, Block 2 (numbers and symbols) in both ASCII and PETSCII already has a slash, the forward slash ($2F), does PETSCII really need another slash, a backslash? As Commodore wanted to sell a lot of computers in Britain, it made more sense to include a British pound symbol. On the other hand, the @-symbol ($40), which had been around for centuries and is found even on antique typewriters, is retained in PETSCII with precisely the same code. Square brackets are a little more modern, most old typewriters didn't have them. Brackets (i.e., [ ] ) are more common than braces (i.e., { } ), they're visually simpler and have uses in editorial writing, such as to insert an editor's note. Therefore, while PETSCII has no braces, it does have brackets. The left and right brackets are codes $5B and $5D in both ASCII and PETSCII.
To sum up the above, the @-sign is the first character of block 3, immediately after the question mark, and the group of 5 symbols:
[ \ ] ^ _ in ASCII, or [ £ ] ↑ ← in PETSCIIcome together at the end of the same block as the @-sign, Block 3. That seems quite copacetic.
There is just one problem. These 6 symbols are found flanking the uppercase letters in ASCII, but they're surrounding the lowercase letters in PETSCII! Thus, the naive solution of just rearranging the blocks is no solution at all.
Reversable conversion
In many cases it is sufficient to have a conversion that is "good enough," and in some cases a conversion that's "on-the-fly." For example, if you have an ASCII text file, and it's got mostly just the common characters, you want it to be in PETSCII so that you can at least read it and make sense of it on your Commodore 64. A rough or approximate conversion is probably good enough.
Converting a file on disk in ASCII (like README.TXT made on a PC) to a second file that contains PETSCII would let you read it with the JiffyDOS @T command, or just a BASIC program that reads the bytes in and prints them to screen. Alternatively, TextView (and TextView+) for C64 OS can open an ASCII file and convert it to PETSCII "on-the-fly." Each character is converted at the moment it's being output to a display buffer. It's ASCII in memory, but as you scroll, whatever becomes visible goes through a conversion as it goes to the screen.
But our goal is a 100% reversable conversion. Why is this important? Because in the age of network connected services, we want the C64 to be able to compose in PETSCII and send to a server by converting to ASCII first. The server can then store it or display it and it's already in the more standard ASCII. But then, we want another C64 to be able to fetch that content, and convert from ASCII to PETSCII as it retrieves it. The goal is for the C64 that retrieves the data to get a 100%-identical copy of the data that was originally sent from a C64, even though it has passed through a conversion routine, twice.
Uppercase PETSCII alphabet
We focused earlier on Block 3, which holds the lowercase PETSCII alphabetic characters, because the non-alphabetic symbols in that block are at precisely the same locations in ASCII. (i.e., the @-sign is code $40, the first character of Block 3, in both PETSCII and ASCII.) But while the lowercase letters are here in PETSCII, in this same block in ASCII we find the uppercase alphabetic characters.
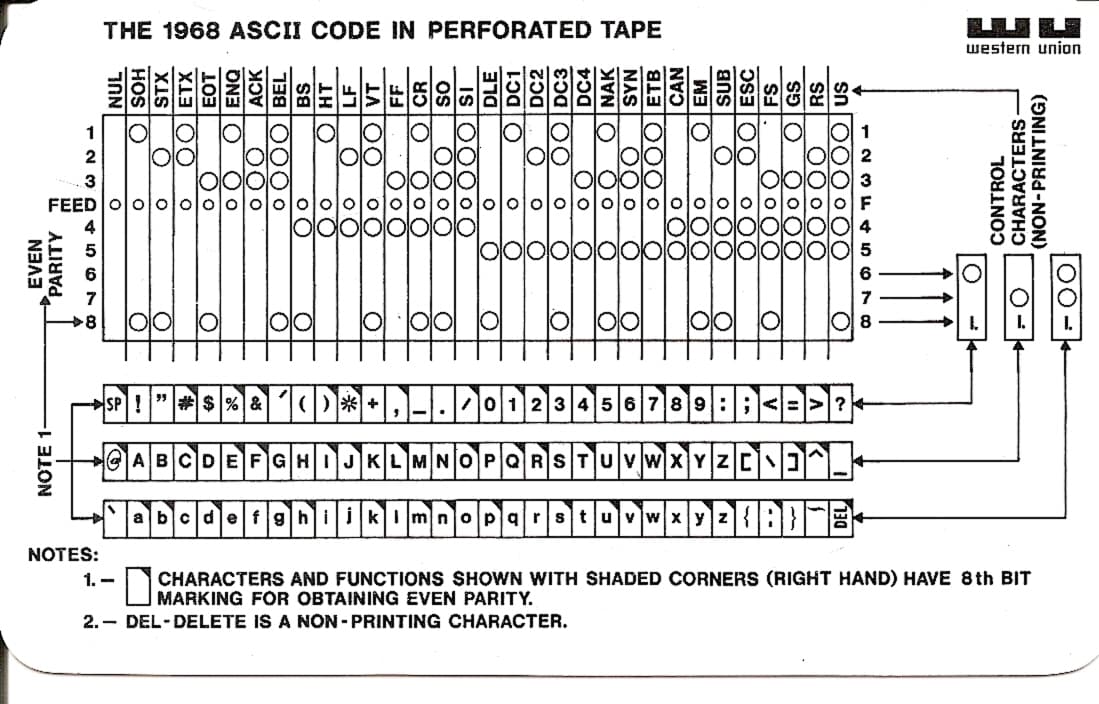
The lowercase alphabet in ASCII is found in Block 4. The other symbols in Block 4 consist, again, of one character before "a" and 5 characters after "z", (6 symbols + 26 letters = 32 characters.) The first is backtick (`), and the final five are left brace ({), pipe (|), right brace (}), tilde (~) and finally the last is actually a control code, DELETE. There is some crazy history behind the final character being used for "DELETE." It goes back to data being punched as holes in paper. Since the final character, 127, has all the bits set, all 7 holes would be punched in the card. This also has the effect of clearing any previously punched mistake. For example, if you meant to punch "a" (1 1 0 0 0 0 1), but you accidentally punched "s" (1 1 1 0 0 1 1), there is no way to unpunch those holes that are in the wrong place. But you could punch out all the holes, and that then takes on the meaning of, "ignore this character" as though it had been "deleted" from the data stream. Clever.
ASCII punched in paper cards, 1968.
PETSCII's block containing the uppercase letters is in Block 7, and none of its 6 additional symbols are the same as those in ASCII. Five of them have been given PETSCII graphical characters, and one of them ($DE, the equivalent of the tilde) is the PI symbol. I don't know if this was intentional, but the PI symbol looks not-far-off from a tilde with two little legs sticking out the bottom of it. When I was a kid, writing BASIC programs, I used to use the PI symbol as a horse. And also, the PI character has meaning in BASIC programs, naturally, as the mathematical constant, 3.14159265.
In Block 3, there was an obvious correspondence between the extra symbols; @ and square brackets line up perfectly, up arrow and left arrow actually look at lot like caret and underscore. Although in this case, Block 4 ASCII and Block 7 PETSCII, the extra symbols have no visual or semantic correspondence, it makes little sense to try to move them anywhere else. PETSCII doesn't have the braces, pipe, tilde or backtick somewhere else, it just doesn't have them at all, the same way that ASCII just doesn't have the PI symbol nor the other 5 graphical symbols.
Marked Text (MText) and undefined blocks
In ASCII, (true 7-bit ASCII,) Block 5 through 8 are undefined. As an aside, 7-bit ASCII is simultaneously validly encoded UTF-8. In UTF-8 encoded text there are never any single-byte code points with the most significant bit (bit 7) high. Whenever the most significant bit is high, i.e., a byte value from 128 to 255, it is always part of a multi-byte sequence. Therefore, UTF-8 is not ASCII-encoded, but true 7-bit ASCII-encoded text is also valid UTF-8-encoded.
In PETSCII, there are 8 blocks, but only 6 of them are defined. Blocks 1, 2 and 3, and Blocks 5, 6 and 7. The last block in each half of the code set, Block 4 and its shifted equivalent, Block 8, are undefined.
This means that in both PETSCII and ASCII, Block 8 is always unused. It is for this reason that I chose to use Block 8 to hold the MText formatting characters that are natively rendered by C64 OS's toolkit classes. Text files can be rendered by C64 OS—with MText formatting—regardless of whether the rest of the text is PETSCII or ASCII. For example, the help files that come bundled with C64 OS Applications, which are displayed by the Help Utility, these are all PETSCII + MText. However, when you use the Wikipedia App, the Wikipedia proxy does not convert to PETSCII. It embeds the MText codes into what is otherwise ASCII-encoded text. The Wikipedia app does ASCII to PETSCII conversion on-the-fly and MText codes in Block 8 are left unmodified.
Help Utility, rendering PETSCII with MText.
This is a requirement that is special to C64 OS. Technically, text that has byte values in Block 8 is not PETSCII or ASCII, since Block 8 is undefined in both. However, for our purposes, we have effectively defined two new standards: PETSCII+MText and ASCII+MText. In these, MText codes are found in Block 8 and should remain in Block 8 during conversion.
The crux of conversion
In a technical sense, perfect conversion is impossible. It's like converting between two languages that don't have the same vocabulary. For example, PI in PETSCII cannot be converted to mean PI in ASCII, not because we don't know where to map it, but because ASCII doesn't have any code that means PI. Same with the British pound. It is impossible to convert into ASCII and still have it mean "£" because ASCII just doesn't have a code with this meaning. And vice versa, ASCII has a tilde character but PETSCII has no code that means tilde.
There is another way in which perfect conversion is technically impossible. PETSCII defines 6 blocks, but ASCII defines only 4 blocks. That means there are more codes in PETSCII than in ASCII! For example, ASCII has only one block of control codes, but PETSCII has two such blocks. Not all of the 64 control codes in PETSCII have a definition, but nonetheless, 43 of them do and that's more than 32. So even if you attempted to cleverly map each to a different code in ASCII, they cannot all be fitted into ASCII's single control code block.
In both of these manners, therefore, we must make a decision based on what our goals are.
For example, if our goal were to produce 100% valid ASCII and to retain semantic meaning only, then nothing that cannot be semantically expressed in ASCII ought to be retained. For instance, PI in PETSCII? But there is no PI in ASCII, therefore, we could either remove it or encode it in some other way. Similarly, the color codes, the function keys, and the cursor keys in PETSCII have no semantic equivalents in ASCII. What would we do with these?
But, what are our goals?
Our goal is that conversion from PETSCII to ASCII and then back to PETSCII should restore the output to exactly the input. Why? Why is that our goal? Because we are both creating and consuming textual content with our PETSCII-native Commodore 64s, but, that content will pass through and probably be stored or logged, processed or analyzed, in computing environments that are fluent in ASCII (as well as more sophisticated encodings) and yet know nothing of PETSCII.
In other words, the truth is PETSCII. And the journey through ASCII is an imperfect and temporary or transient waypoint on its return back to PETSCII-land. This means that the ASCII may semantically miscode some things for which it has no equivalent. It also means that the ASCII may technically be invalid, as codes could appear in blocks that are undefined. What we're really focusing on in the conversion is remapping the codes that do have both presence and semantic equivalence. For example, a-z, A-Z, 0-9, ! " # $ % & ' ( ) * + , - etc. etc. And also such examples as ^ to ↑ and _ to ← are semantically equivalent if not visually identical. While retaining all other characters with as little disturbance as possible, such that they can be restored losslessly.
On the other hand, within the context of C64 OS specifically, semantically, we are meeting ASCII halfway. C64 OS is designed to be a citizen of the internet and it uses a custom character set and has swappable keyboard drivers. Several of the Block 3 and Block 7 PETSCII symbols have had their visual and semantic meaning, in C64 OS, changed to mimic their counterparts in ASCII.
Appendix D of the printed C64 OS User's Guide. Keyboard mapping for special characters.
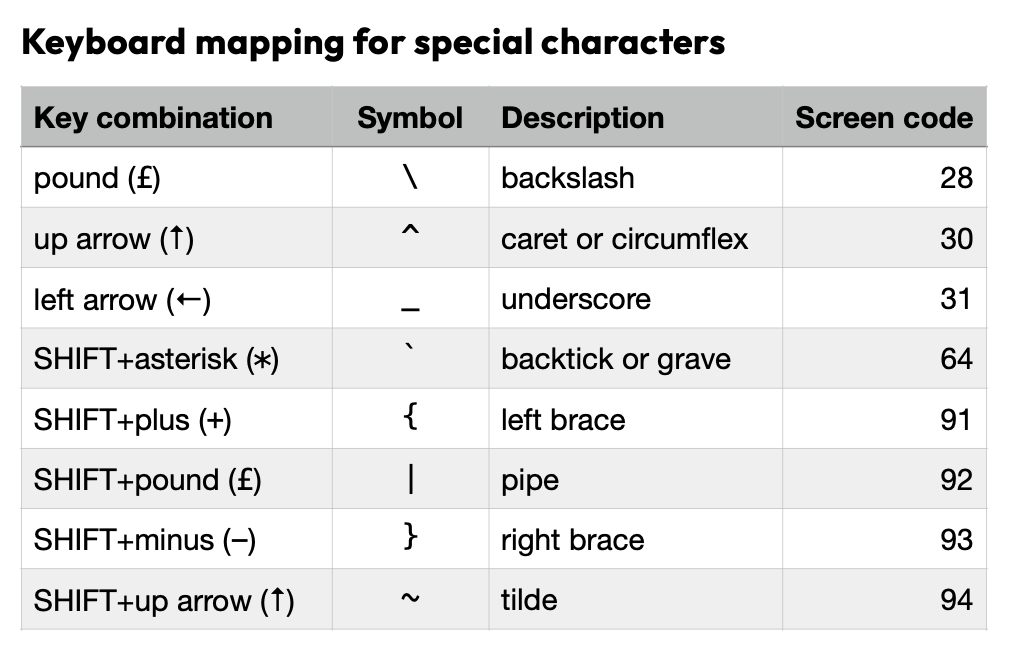
You can see from this table that C64 OS visually and semantically maps the British pound (£) to backslash (\) as it is in ASCII, the up arrow (↑) to caret (^), and the left arrow (←) to underscore (_). These are in Block 3. It also maps all 5 of the symbolic characters from Block 7 to their ASCII Block 4 equivalents. Backtick, left brace, pipe, right brace and tilde. The final ASCII character, DELETE, remains a PETSCII graphic symbol. The table in the appendix of the User's Guide also shows what keyboard combinations must be pressed, with the standard keyboard driver, to produce these characters, since they don't appear in the glyphs on the keys.
The first three, £ to \, ↑ to ^, and ← to _, are direct equivalents. SHIFT+£ to get a pipe is the common layout on Mac and PC keyboards. SHIFT+↑ is more-or-less a direct equivalent for PI being remapped to tilde, although it could arguably have been SHIFT+← to position the tilde in the common layout of Mac and PC keyboards. On Mac and PC keyboards plus and minus are in reverse order, minus then plus. This pair of keys is used with SHIFT for the braces. And lastly, SHIFT+* is used for the backtick, out of convenience that this key is not already overloaded.
Final Conversion Matrix
Below is the PETSCII table from the Complete Commodore Inner Space Anthology. This is taken from my physical copy, which I've marked up with pencil, and corrected in some places. I've added horizontal red lines to visually seperate the blocks more.
I've also highlighted with colored overlays the areas from the areas that have to get moved around.
PETSCII Table, with highlighted blocks and ranges.
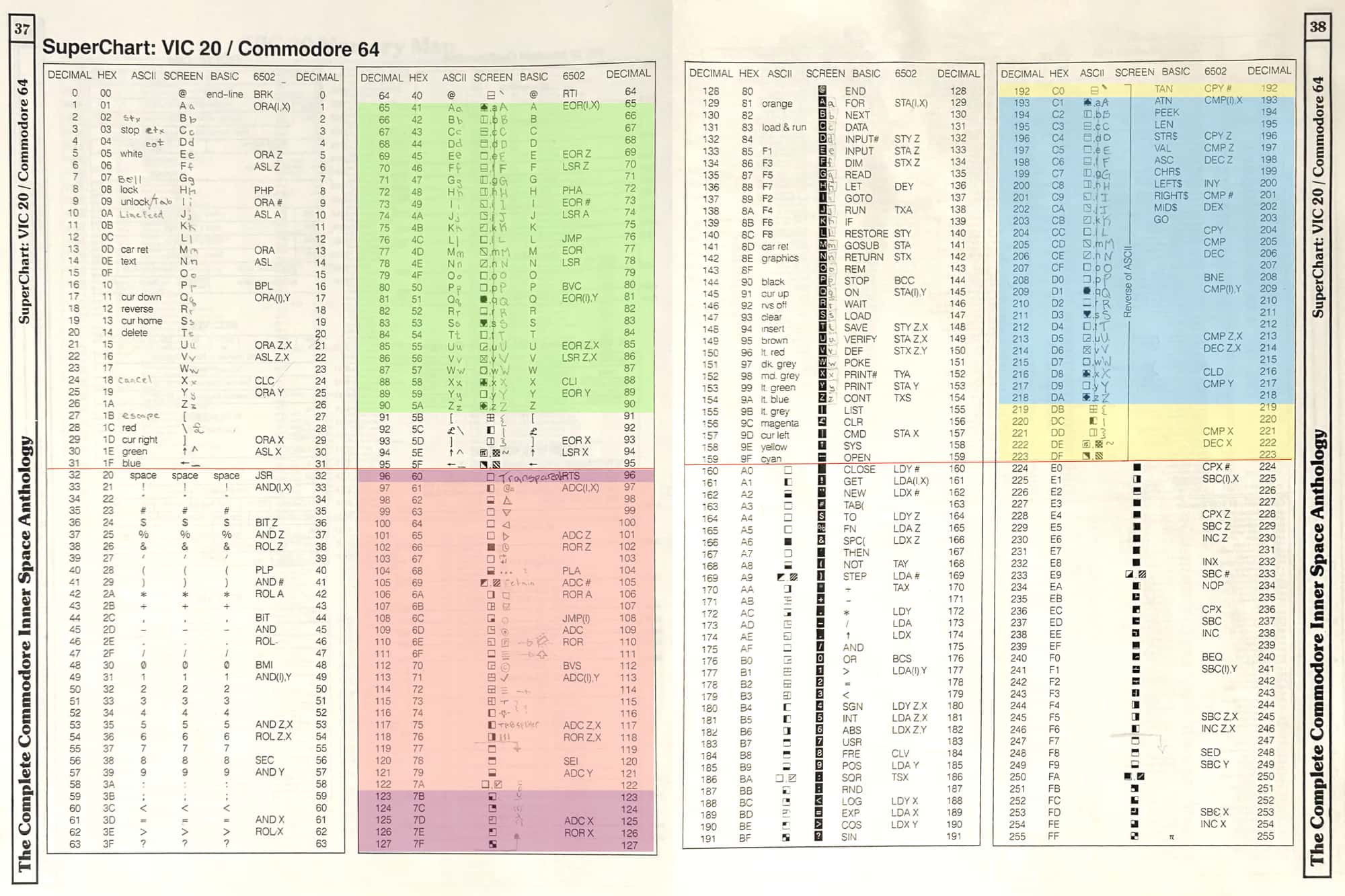
The red, green and blue parts rotate. The blue part goes where the green part is, the green part goes where the red part is, and the red part goes where the blue part is. Additionally, the purple and the yellow (each discontiguous) swap with each other.
Below is the same thing said a different way.
From PETSCII to ASCII
| Block 1 | Block 1 | Control Codes Low |
| Block 2 | Block 2 | Numbers and Symbols |
| Block 3 ($40,$5B-$5F) | Block 3 ($40-$5B-$5F) | @ [ ] Symbols |
| Block 3 ($41-$5A) | Block 4 ($61-$7A) | Lowercase Letters |
| Block 4 | Block 7 | Undefined |
| Block 5 | Block 5 | Control Codes High |
| Block 6 | Block 6 | Graphics Symbols |
| Block 7 ($C0,$DB-$DF) | Block 4 ($60-$7B-$7F) | ` { } Symbols |
| Block 7 ($C1-$DA) | Block 3 ($41-$5A) | Uppercase Letters |
| Block 8 | Block 8 | MText Codes |
You can also summarize the swaps as a two step process.
- Swap all contents of Block 7 with contents of Block 4
- Swap the "a" to "z" range from Block 3 with the "A" to "Z" range of Block 4
From ASCII to PETSCII
| Block 1 | Block 1 | Control Codes |
| Block 2 | Block 2 | Numbers and Symbols |
| Block 3 ($40,$5B-$5F) | Block 3 ($40-$5B-$5F) | @ [ ] Symbols |
| Block 3 ($41-$5A) | Block 7 ($C1-$DA) | Uppercase Letters |
| Block 4 ($60-$7B-$7F) | Block 7 ($C0,$DB-$DF) | ` { } Symbols |
| Block 4 ($61-$6A) | Block 3 ($41-$5A) | Lowercase Letters |
| Block 5 | Block 5 | Undefined (PETSCII Control Codes High) |
| Block 6 | Block 6 | Undefined (PETSCII Graphics Symbols) |
| Block 7 | Block 4 | Undefined |
| Block 8 | Block 8 | MText Codes |
You can also summarize the swaps as a two step process.
- Swap all contents of Block 4 with contents of Block 7
- Swap the "A" to "Z" range from Block 3 with the "a" to "z" range of Block 7



