.png)

Ricardo Tavares
June 20, 2025
Some basic steps for making software are usually described as: make it work, make it right, make it fast. Large Language Models (LLMs) offer no guarantees about any of that, but at least they can write and review code. As a new tool, they unlock an abundance of code and documentation that can vary between pretty good to deceptively plausible. So if accumulating lines of code doesn't mean you have a working piece of software, how useful can LLMs be?
Answering this often triggers more questions that shouldn't surprise anyone. Do you have some workable requirements? Have you created meaningful tests aligned with those? Can you understand and fix your code when those tests fail? Are you seeing opportunities to delete code in a way that enhances its value by reducing its liability? In all of these questions, code is ingrained with purpose, hampered by ambiguity, and therefore very much human, even when it lies forgotten in some machine where it still happens to create value for stakeholders. But how can AI align with these tasks that we ourselves aren't so sure about? To map that territory, people are planting flags across different dimensions of AI coding. Imagine these as different spectrums that can plot to different points hovering between prototyping and production.
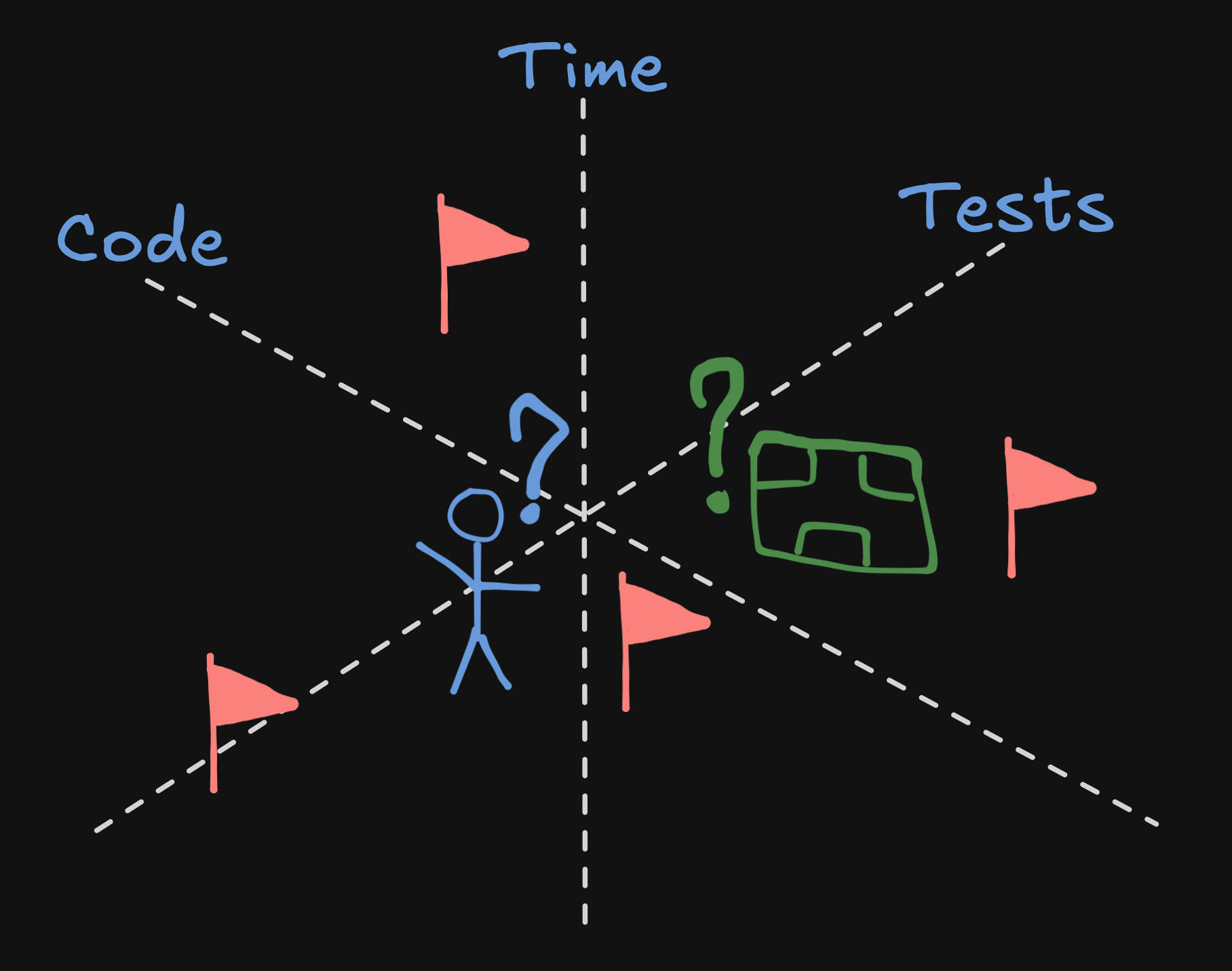
The need to oversee what the AI is doing depends on the importance of a project and the risks of shipping buggy code. Sometimes we just want to tag a bot in Slack and tell it to add a feature. Or maybe we can speech-to-text on our phone while doing something else. But other times we may want to conduct how an LLM codes inside our editor or through GitHub. If we have development experience, the original definition of vibe coding applies as we deliberately avoid looking at code in order to engage with other skills. We also can't help but let our experience still lead the LLM through our choice of prompts in order to avoid rabbit holes and find the simplest path. On the other hand, if we can't code, LLMs can still put our ideas into practice at least to a point where we can understand how they're ambiguous or incomplete. This is even better if it's a learning project where we're getting to know a new programming language or even how to code in general.
On one end of this axis, we have the drive to establish AI as an autonomous and comprehensive abstraction over any code that it deems necessary in order to solve and prevent problems. On the other hand, we value human interpretability and our intervention deep into any layer where ambiguity might require careful consideration, as we exercise ultimate responsibility. If a human is still in the loop, some balance will always have to be found between these two points. Like the pipes that sometimes clog under our sink, the state of the underlying code can never be completely ignored.
Through the iterative cycles of a project, AI can show up at very different times. In an initial architectural phase, chatting with an LLM may help us consider all the best options. A conversational approach may have at least some of the value of a productive meeting without actually having one. On the other hand, a large codebase can be decades old and an LLM can attempt to review code for it. The obliviousness of the AI over all the hidden context may find new issues in these incoming changes, especially from the perspective of LLMs that may come to work with this code. In between these two extremes, most projects are still not greenfield projects, making the modularity of a codebase and the meaningfulness of its tests very consequential for how far an AI agent can go on its own. As LLMs may have trouble maintaining coherence across time, even the quality of the development workflow can make a considerable difference.
But AI also allows us to greenfield much more by making prototypes, which is one of the best ways to understand what we really want and how we can go about it before starting any real project. Even before vibe coding, there has always been great potential in having prototype code, as in, not shipping it. Forcing it into production and letting your users find out what's wrong is a whole other thing. If I tell you not to do that, there's always someone who will take that calculated risk given that, when it blows up, some customers will still appreciate your ability to maybe save the day. But if there's room to make code you don't ship, the value of vibe coding can really shine through unlocking personal use, iterative learning, and experimentation.
Automating tests can involve a lot of tedious boilerplate that certainly LLMs can power through. But in the same way that automation can never completely replace manual testing, AI can't deliver meaningful guarantees if it just replicates generic tests. Before you pour that concrete, we need to consider what can really be tested and if those assertions can mean anything for the evolving success of this project. That meaning can surely be suggested by an LLM, but is it useful for us if the AI decides what tests the AI needs to pass? Can you discard useless tests with the same confidence that you ignore early prototypes or will that code become persistent noise in your workflow? If we just tell an LLM what we want and simply add that it should have tests on top of that, will those have any chance of convincing us that we don't need to manually test everything?
Even though it talks more and more like a human, technology is still as trustworthy as the businesses that built it and the humans who are using it. Benchmarks, evals, tests, these are all the secret software sauce of the current AI evolution at scale. We can be sure that LLMs optimize for passing tests within the potential narratives offered by their training and our prompts. Much like chefs always say "taste, taste, taste", careful testing of AI code is a foundational ground we have to pour our human energy into. We don't have to implement every automation ourselves, but it's on us to decide what gets tested and why should we care if these tests are passing.
To conclude this, I'd like to call your attention to a reverse-LLM skill: the ability to delete code. Not to predict the next token, but to erase previous tokens because they're no longer needed or because we can replace them with something smaller that is easier to maintain and understand. In all these dimensions, ask how easily can you reduce the size of your code when you can't see it, when it's very old or when you can't rely on your testing. If you think this is a very human skill, there is another that goes even deeper: the ability to prevent code. It surely takes a human at the helm to be able to say what should be done when, knowing that we become what we give our attention to. We can appear to be doing everything, and AI can certainly help with that, but knowing where you don't want to go is just as important as finding your desired destination.



