.png)

![]()
![]()
New research reveals that LLMs often fake understanding, passing benchmarks but failing to apply concepts or stay internally consistent.

Large language models (LLMs) ace standardized benchmarks, but do they actually understand the concepts being tested?
That’s the central claim of a new preprint, Potemkin Understanding in Large Language Models, by a team of researchers from Harvard, MIT, and the University of Chicago. The authors introduce the concept of Potemkin understanding, a failure mode where models appear to grasp a concept but only create the illusion of understanding. They contend that today’s LLM evaluations may be missing the point. The benchmarks themselves aren’t necessarily broken, but the way we interpret benchmark success assumes LLMs fail in the same ways humans do. When this assumption falls apart, the result is surface-level correctness without true comprehension.
The new term borrows from the story of Potemkin villages. As the legend goes, Russian minister Grigory Potemkin built fake, decorative villages to impress Empress Catherine the Great during a royal tour. The buildings looked real from a distance, but they were nothing more than facades. Whether the story actually happened or not, it has come to represent any convincing illusion that hides a lack of substance.
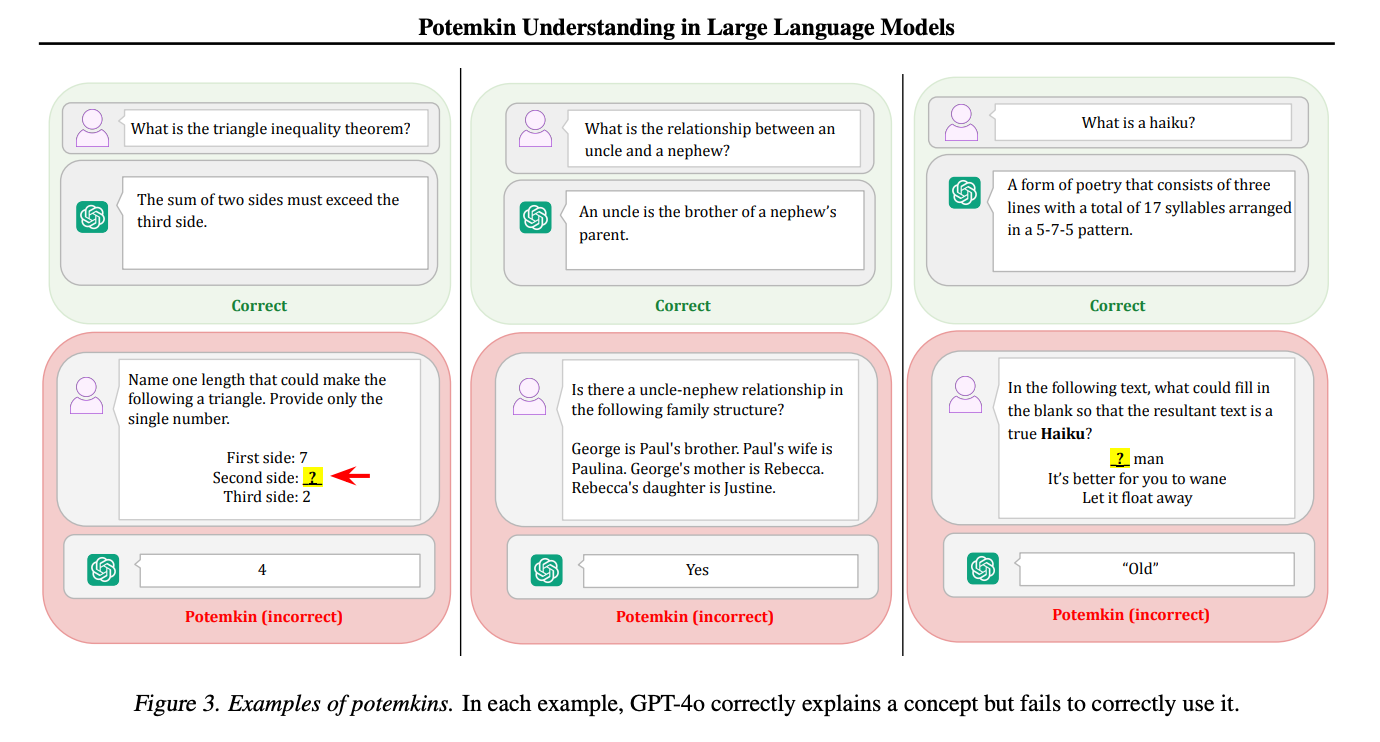
In the case of LLMs, it describes models that appear to understand a concept but don’t actually grasp how to use it. You have likely experienced this frustration many times: a model writes perfect code comments but fails to write the actual function, explains a math concept flawlessly but botches the calculation, or defines a poetic form correctly but can’t generate an example. Now there's a term for it.
From Benchmarks to Potemkins#
The paper introduces a formal framework for thinking about how LLMs understand concepts and where that understanding can break down. The researchers argue that most benchmarks only make sense as tests of understanding if models fail in human-like ways. A test like the AP Literature exam is designed around predictable types of misunderstanding. If you get the right answers, that typically signals real comprehension. But this logic only works if the test-taker is human.
With LLMs, that assumption doesn’t hold. These models might get the right answer for reasons no person would. That opens the door to something the authors call a “potemkin," an example where the model looks like it understands a concept but fails on follow-up tasks that require applying that concept in practice.
For instance, GPT-4o can explain what an ABAB rhyme scheme is. But when asked to write a poem in that format, it fails to generate rhymes. Then it turns around and correctly identifies its own output as non-rhyming. This kind of contradiction wouldn’t make sense coming from a person. But for a model, it’s surprisingly common.
The researchers explained how potemkins differ from AI hallucinations:
Potemkins are to conceptual knowledge what hallucinations are to factual knowledge—hallucinations fabricate false facts; potemkins fabricate false conceptual coherence. Yet potemkins pose a greater challenge: hallucinations can be exposed through fact-checking, but potemkins require unraveling subtle inconsistencies in a model’s apparent understanding.The objective of the research is to identify potemkins and their prevalence in order to turn the vague idea of "understanding" into something that can actually be measured. This will enable the industry to build frameworks that test whether benchmarks really reflect what they claim to, and that help identify where models need to improve.
Measuring the Illusion#
To test how often this happens, the researchers introduced two complementary methods. One was a human-curated benchmark built around 32 concepts from three domains: literary techniques, game theory, and psychological biases. The other was an automated self-evaluation process where the model generates an answer, then tries to grade it.
In both setups, they found that potemkins are ubiquitous.
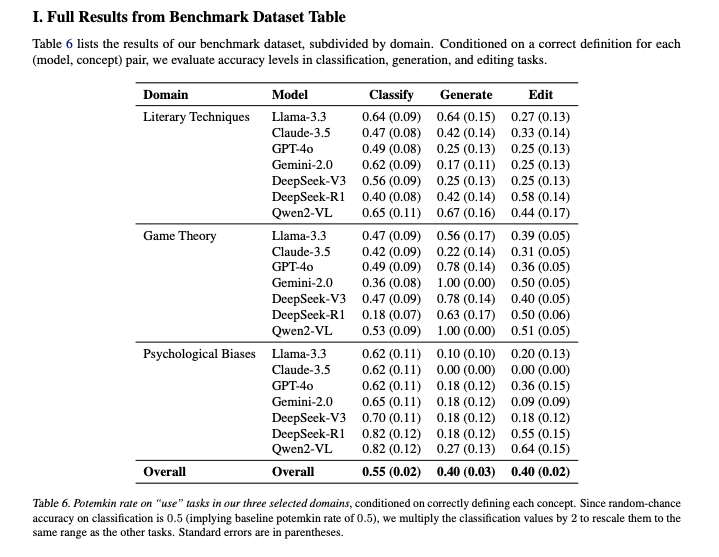
In the benchmark dataset, models correctly defined concepts 94.2 percent of the time. But when asked to use those concepts in practice, through classification, generation, or editing tasks, they failed at surprisingly high rates. The average potemkin rates were:
- 55 percent on classification
- 40 percent on generation
- 40 percent on editing
The second method is broader and doesn’t rely on domain-specific definitions. Instead, it checks for internal inconsistency. If a model generates an example of a concept, can it correctly identify whether that example actually fits the concept? Not always. GPT-4o, for example, had an incoherence score of 0.64, where 0 is perfect consistency and 1 is as bad as guessing randomly.
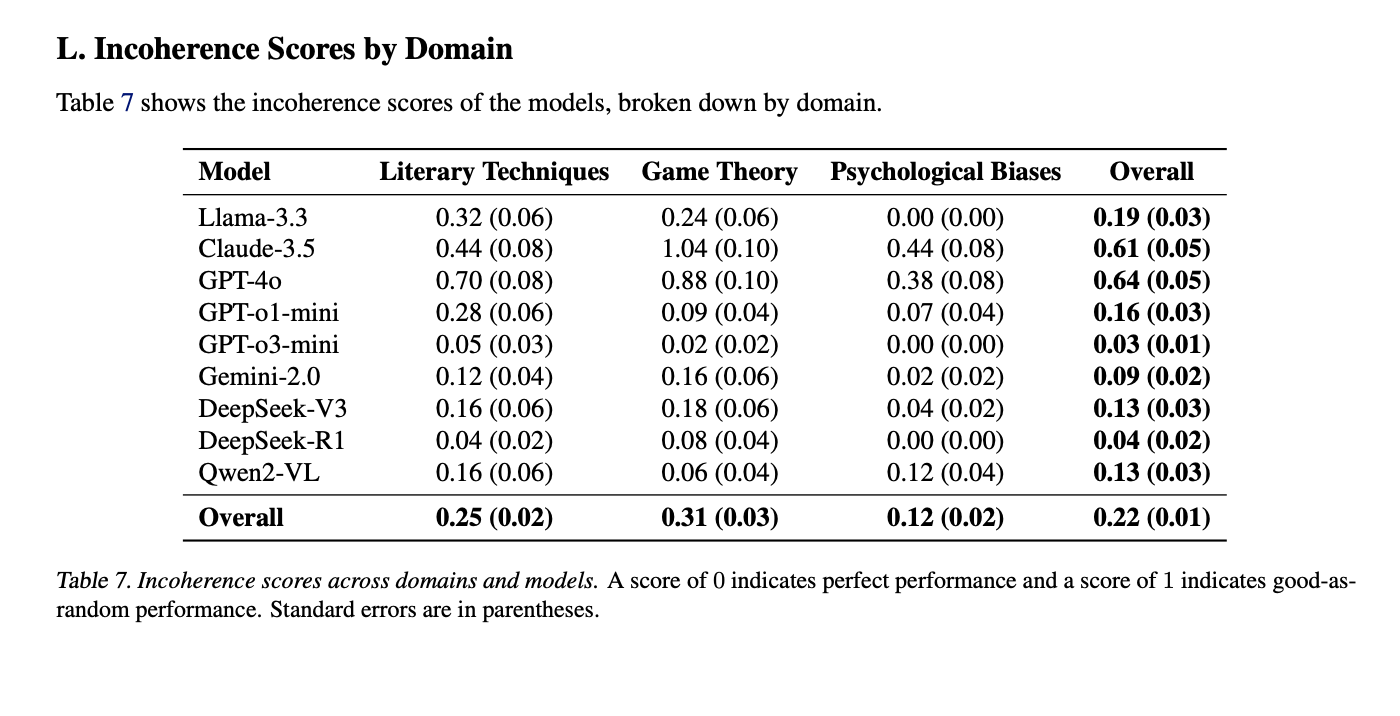
Despite being conservative (it only catches incoherence the model recognizes), this method still revealed high potemkin rates. For instance, GPT-4o scored an incoherence rate of 0.64, meaning nearly two-thirds of its outputs could not be reconciled with its own definitions.
Some standouts:
- GPT-4o had the worst overall score: 0.64, driven by especially poor coherence on game theory (0.88) and literary techniques (0.70).
- Claude 3.5 followed closely at 0.61, with a very high score of 1.04 on game theory.
- Smaller models like GPT-3.5-mini (0.03) and DeepSeek-R1 (0.04) performed better, though this may reflect lower ambition or simpler outputs.
Interestingly, the domain breakdown shows that psychological biases were easiest for models to stay consistent on (average score 0.12), while game theory posed the biggest challenge (average score 0.31).
Toward Better Evaluations#
Benchmark scores are everywhere in AI evaluation. They’re how we compare models, measure progress, and often, how we decide what’s ready to ship. But if LLMs can get the right answers without genuine understanding, then benchmark success becomes misleading.
The researchers frame this in terms of keystone sets, small groups of questions that are supposed to reliably measure understanding. In humans, getting a keystone set right usually means the person has the right mental model. For LLMs, though, that logic only works if the model's mistakes mirror human ones. If models can stumble in ways people never would, then getting all the keystone questions right might just mean the model learned a clever shortcut. It doesn’t necessarily mean it understood the idea.
That distinction is important. Potemkins are harder to detect than hallucinations. You can fact-check hallucinations. Potemkins require a deeper look at how a model reasons, applies concepts, and contradicts itself.
The paper stops short of prescribing a fix, but the authors suggest a clear direction. If we want to measure real conceptual understanding, we need evaluations that test for internal consistency, application skills, and robustness across varied tasks. That could mean new benchmarks, or new ways of analyzing model outputs beyond pass/fail answers.
Until then, we should be skeptical of benchmark wins that seem too clean. As this paper shows, some of them might be Potemkin villages.
Subscribe to our newsletter
Get notified when we publish new security blog posts!
Try it nowReady to block malicious and vulnerable dependencies?