.png)

A couple of months ago, we launched Arch-Router with a simple observation: developers don't just plug in new models into their agentic workflows based on how well they rank on benchmarks like MMLU or MT-Bench. They evaluate LLMs against real-world scenarios, assessing fit to domain, task coverage, reliability, speed, and accuracy. In practice, model usage and selection are guided by subjective preferences and use-case-specific evaluation criteria.
Arch-Router put this observation into practice by letting developers encode their preferences directly into routing logic—decoupling the what from the how. Route selection is expressed in human-readable policies (e.g., code understanding, analyze earnings report), while model assignment maps each policy to the most suitable LLM based on a team’s evaluation cycles. That might mean assigning a powerful model for deep reasoning, a lightweight one for low-latency tasks, or any other preference informed by real-world testing. In short, we shifted the conversation from benchmark-based routing to preference-aware routing. And in doing so, we unlocked a practical way for developers to build better agents, faster.
Today we’re extending that approach to Claude Code via Arch Gateway, bringing multi-LLM access into a single CLI agent powered by preference-aware routing from Arch-Router.

Developers no longer need to force every workflow through a single model or toggle endlessly between drop-down menus. Instead, you can route different coding tasks to the model you think is best suited for the job. This means two things for you as a user of Claude Code:
- Model Access: Use Claude Code alongside Grok, Mistral, Gemini, DeepSeek, GPT, or local models via Ollama.
- Preference-Based Routing: Assign different models to specific coding tasks, such as:
- Code Generation → Route to models optimized for speed and fluency when scaffolding new functions, generating boilerplate, or iterating on implementation details.
- Code Comprehension & Reviews → Use reasoning-heavy models to explain complex snippets, walk through logic step by step, or flag subtle issues during code review.
- Architecture & System Design → Delegate high-level design discussions—APIs, module boundaries, trade-offs—to models that can sustain longer context windows and nuanced reasoning.
- Debugging & Error Resolution → Direct prompts to models that balance depth with speed, surfacing likely root causes quickly while staying cost-efficient in repeated troubleshooting loops.
By encoding these preferences once, every coding task is automatically handled by the right model—without brittle orchestration code, manual switches, or guesswork.
Getting Started
To get started, we have packaged a fully working demo in our GH repo here. But i'll walk you through the overall experience quickly in this blog as well.
1. Define Routing Preferences & Start Arch
Clone the GH repo (shared above) and edit the config.yaml file to describe how different coding tasks should be handled. For example:
llm_providers:
- model: openai/gpt-4.1-2025-04-14
access_key: $OPENAI_API_KEY
routing_preferences:
- name: code generation
description: generating new code snippets and functions
- model: anthropic/claude-3-5-sonnet-20241022
access_key: $ANTHROPIC_API_KEY
routing_preferences:
- name: code reviews
description: analyzing code for bugs, readability, and improvements
This ensures Arch-Router knows what each model should do and how to route prompts accordingly. Now start Arch Gateway

2. Launch Claude Code via Arch Gateway CLI
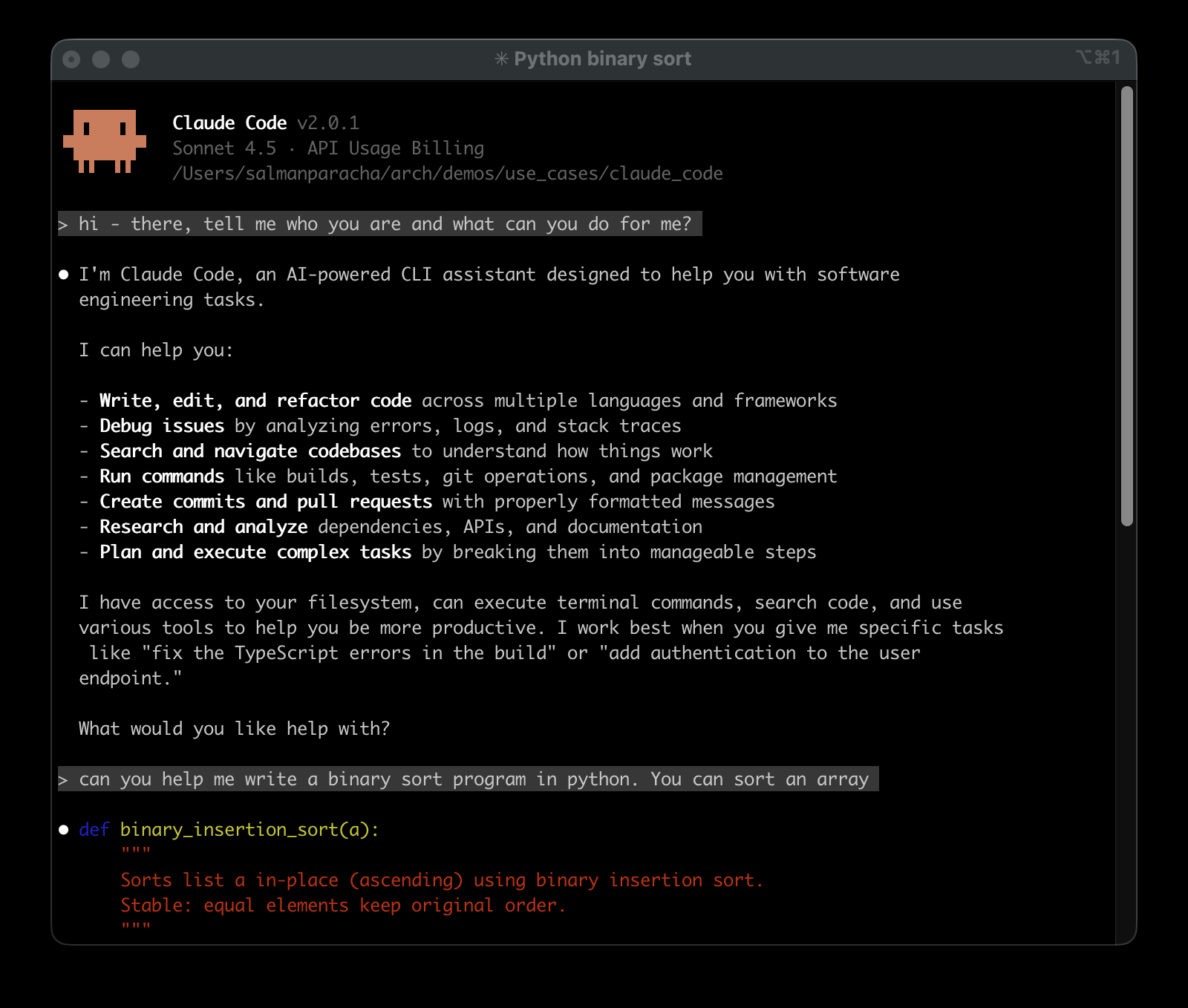
Try out Claude Code with real-world developer tasks:
- Generate boilerplate for a new function
- Ask for a detailed explanation of a tricky snippet
- Review code for potential bugs
- Debug a runtime error
Each task will be automatically routed to the most suitable model based on your preferences.
3. Monitor Routing Decisions in Real-Time
Arch is built using Docker, so you can tail the logs using familiar tools to monitor the routing decisions it makes. But you can also run the utility in the demo folder (pretty_model_resolution.sh) to more easily monitor Arch's routing decisions in real time. You’ll see exactly what model was request by Claude Code 2.0 and what model received the traffic:
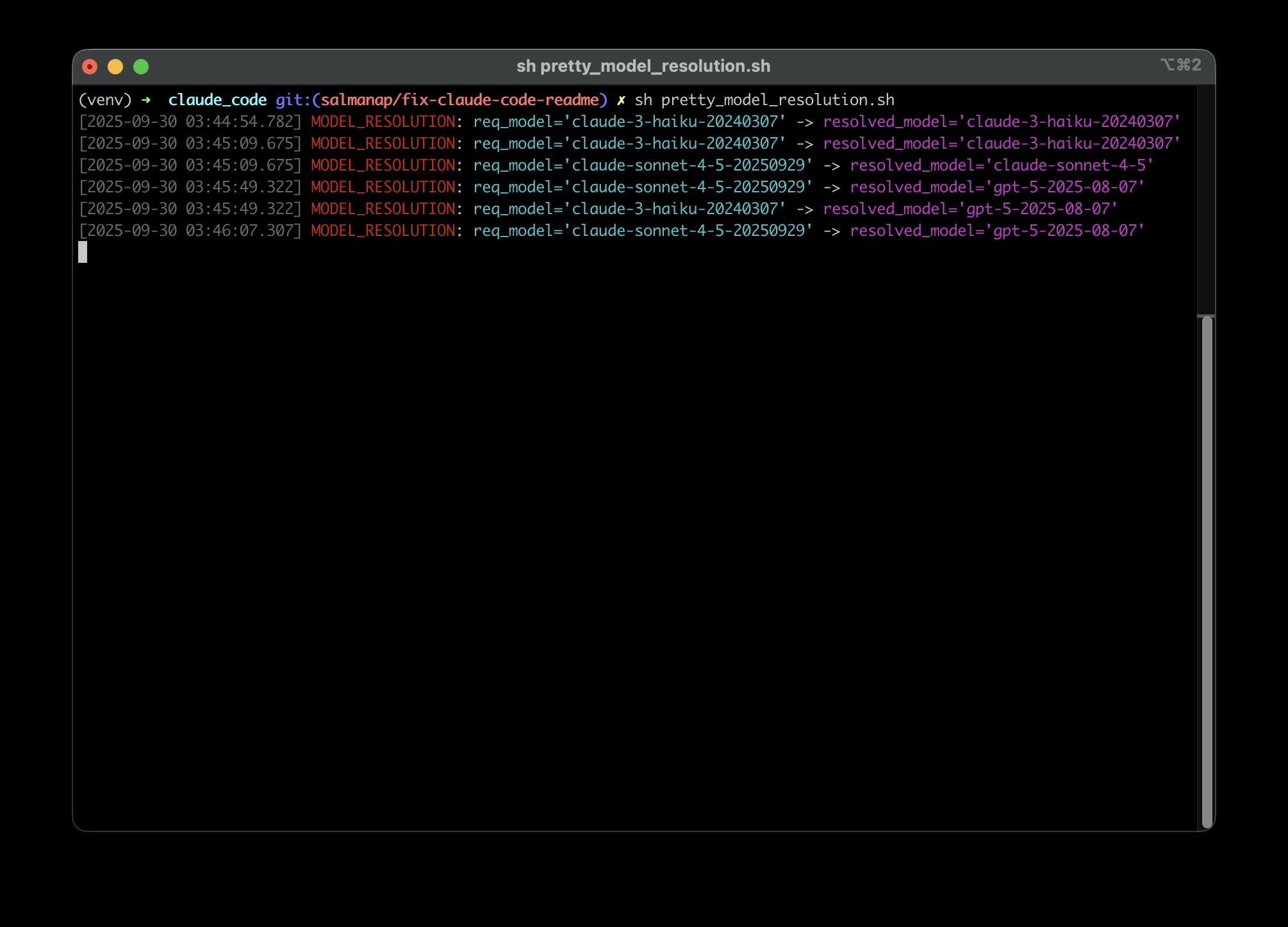
4. Iterate & Refine
Adjust config.yaml as you go. Route code generation to a smaller model. Need deeper reasoning for architecture discussions? Assign those prompts to GPT-4o or Claude Sonnet.
Hope you enjoy the release, check out the demo in our GH repo. And if you like our work, don't forget to ⭐️ the repo 🙏.



