.png)

Identity preservation is everywhere in GenAI. Models and products claim they can "preserve your identity" when generating avatars, portraits, or videos.
But what does that actually mean? And why is it so difficult?
At its core, identity is not just a single face frozen in time. It's a collection of elements that make you recognizable. To understand what preservation really requires, we need to break it down.
Identity is static, dynamic and transient.
We can think of identity as three buckets of features:
- Static features: facial structure, geometry, eye shape, bone lines and the elements that don't change day to day.
- Dynamic features: the way you smile, frown, or raise an eyebrow. These are tied to how your muscles move, which is subtle but uniquely yours.
- Transient features: hair color, makeup, beard, glasses. Things that shift easily but still impact recognition.
A system that truly preserves identity must capture static and dynamic features reliably and in a generalized way, while allowing transient ones to change naturally or with user control.
Aging complicates this further. Some aspects shift slowly but permanently like bone structure. In that sense, aging spans across both static and transient features.
Despite all this variation, humans are remarkably good at generalization when it comes to people we know. That simply means we can still recognize a friend from dimly lit cafe, or meet them as adults and still pick them out instantly in a childhood yearbook photo. For people we know, recognition rarely fails — even as their appearance shifts over time, lighting, or expression. That's the bar systems must aim for.

Generalization is key and it is hard.
Generalization is key here. Because recognition depends on generalization. Humans don't just memorize one face; we learn to recognize faces across lighting, angles, and expressions.
It's extremely challenging to have a system preserve identity reliably. Humans struggle too. Think about meeting a colleague in person after months of only seeing them on Zoom. “You look different in real life” is a recognition failure caused by limited views. You’ve only seen a narrow slice of their identity: mostly frontal views, low-resolution, inside a screen. Identity emerges from variation. Without diverse observations, no system - biological or artificial - can form a reliable identity model.
This is why a single image isn't enough. You can't reliably infer someone's side profile from just their front view, or imagine their smile from a neutral face. Sometimes, the information simply isn’t there. Think of an input image where the subject accidentally has their eyes closed, or a noisy input where the facial features are barely recognizable.


Collecting full appearance data is almost impossible (unless you have a million-dollar lightstage!), but GenAI has a useful shortcut: priors learned from billions of faces. With enough examples of one person, a model can often interpolate to make convincing guesses at unseen angles or expressions.
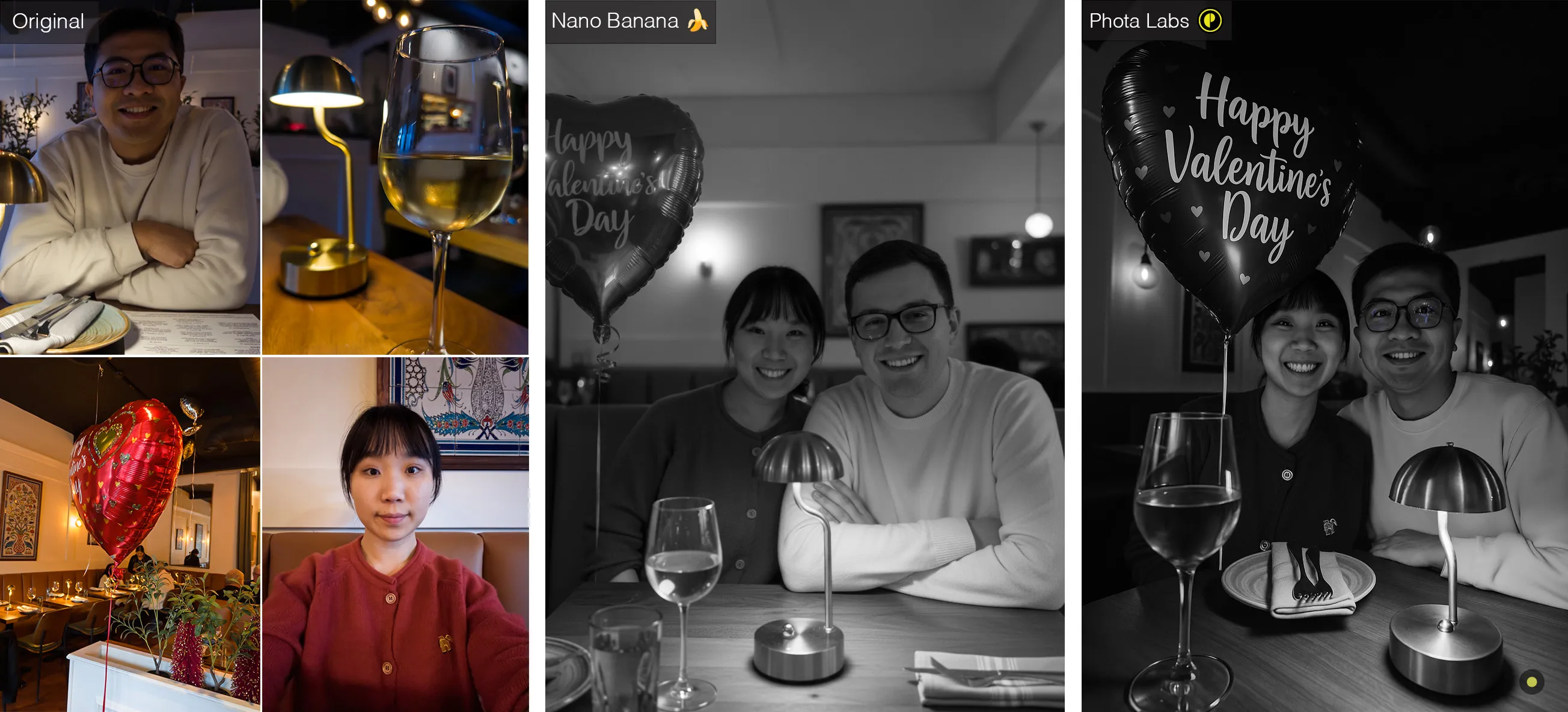
But how many examples are enough? This remains an active and interesting research question. It depends on the application, but for photography we've found a few dozen images are usually required to produce reliable results. This illustrates a key property of GenAI: compositionality, which is the ability to recombine known concepts and elements. In Fig. 3, because the model has seen the person in different contexts (glasses + big smile, no glasses + serious face, see Fig. 1), it can faithfully predict him in a new combination — no glasses + big smile — even if that pairing never appeared in the training set.
The gold standard for evaluating identity preservation is self-judgment.
Once we have a model that can preserve identity reasonably, how do we measure success?
Tools like ArcFace embeddings or “ID similarity scores” give a quantitative measure of identity. They work well for recognition because people are often uniquely identifiable from just part of the face — say, the upper eyes and brow[1]. Remember Face ID also works when you're wearing a face mask? But generation is a different problem: a convincing image requires the whole face, not just a subset of features. This is why ID scores alone are not sufficient.
The gold standard for identity preservation is still human judgment. But even here, things aren't simple: judging yourself is fundamentally different from judging others. When it's your own face or someone you know well, the bar is absolute. Small mismatches stand out instantly. For strangers, fictional characters, or even celebrities, we're far more forgiving; "close enough" often feels good enough.
That's why generated images and videos of celebrities often look convincing[2], while attempts with your own photos don't work. With our own faces, the threshold is binary: it's either me or it isn't.
This makes it hard to "prove" identity preservation or design a perfect benchmark. In practice, the most reliable test is still to try it yourself. So, sign up for our beta.

What about transient features in an identity like makeup, face paint, or an acne that only happened to be there in that photo? Whether to preserve these features in the generated output is a subjective choice and should be a user control.

Aging is one of the most challenging aspects of identity. Our appearance evolves, and so must the model. With recent photos, the system can grow with you, updating automatically as you change. A truly smart system should also know which age to apply in context.
An accidental feature here. When a model applies someone's current age to their old wedding photo, it creates a kind of unintended "photo recreation." It's a reminder of how we often revisit past moments by posing the same way years later.

Photography sets the highest bar for identity preservation.
In entertainment or gaming, "close enough" may be acceptable. In photography, especially personal photos, the question is brutally simple: "Would I share this photo as me?". What's interesting is how instinctive that judgment is. We can usually say "yes" or "no" instantly, but struggle to explain why. That mirrors the uncanny valley in CGI: when something is almost real, yet just off enough to feel unsettling. With identity preservation, that same unease comes from authenticity. Is it the forehead shape, the depth of the eye socket, or simply that I'd never smile like that?
Photography is also uniquely unforgiving because it is static. In still images we scrutinize every detail, whereas in motion our brains are far more forgiving. Smooth movement can often hide small mismatches.

At Phota Labs, we believe in personalization.
We're building for personalization. We've created a layer that lets a generic model actually learn you. This means that it knows your eye color and nose shape, and it also understands how your eyes crinkle when you smile or how your nose casts shadow to the side under a glaring sun. With a one-time setup, your model can generalize across photos, producing results that reflect you.
The most magical moment is seeing generated contents on your photos. We're rolling this out through our beta app and API. Sign up here for early access.
Finally, a topic that deserves a deep discussion on its own: should identity be preserved exactly?
Beauty filters already dominate photo apps, smoothing skin, enlarging eyes, reshaping jaws. These edits distort "true" identity but are widely accepted because they feel closer to how people want to be seen.
That suggests identity preservation isn't only a technical challenge, but also a social and ethical one. In the end, it’s subjective: if you look at an image and feel "this is me," maybe that’s enough.
[1] Thanks Colin from Red Note for the insights on face ID.
[2] Celebrities also tend to look more faithful because their photos are abundant in training data, giving models stronger priors. But even then, what looks "close enough" to us might not pass for the celebrity themselves. They may not see those outputs as truly them.
Phota of the day
The dynamic side of identity is fascinating. A genuine laugh that carries the joy of the moment is crucial to preserve in the output. That happiness breaks through the screen.



