.png)


Serious NULL BITMAP heads know my love for the Query Plan Diagram.
This is a 2D-rendering that represents the selection of plans for a particular shape of query. To construct it, we take the two parameters of a query and vary them along each axis.
Consider this query from TPC-H:
In TPC-H scale factor 1, the customer relation has 150,000 rows and the order relation has 1,500,000 rows, so by varying $1 and $2 in the above query, we can vary what proportion of the table is considered for the query. We can say two pairs of ($1, $2) values are equivalent if our database chooses to use the same query plan for both of them. If we plot the regions that these equivalences form for a particular database, like Postgres, we can get a visual representation of the space of plans for this query:
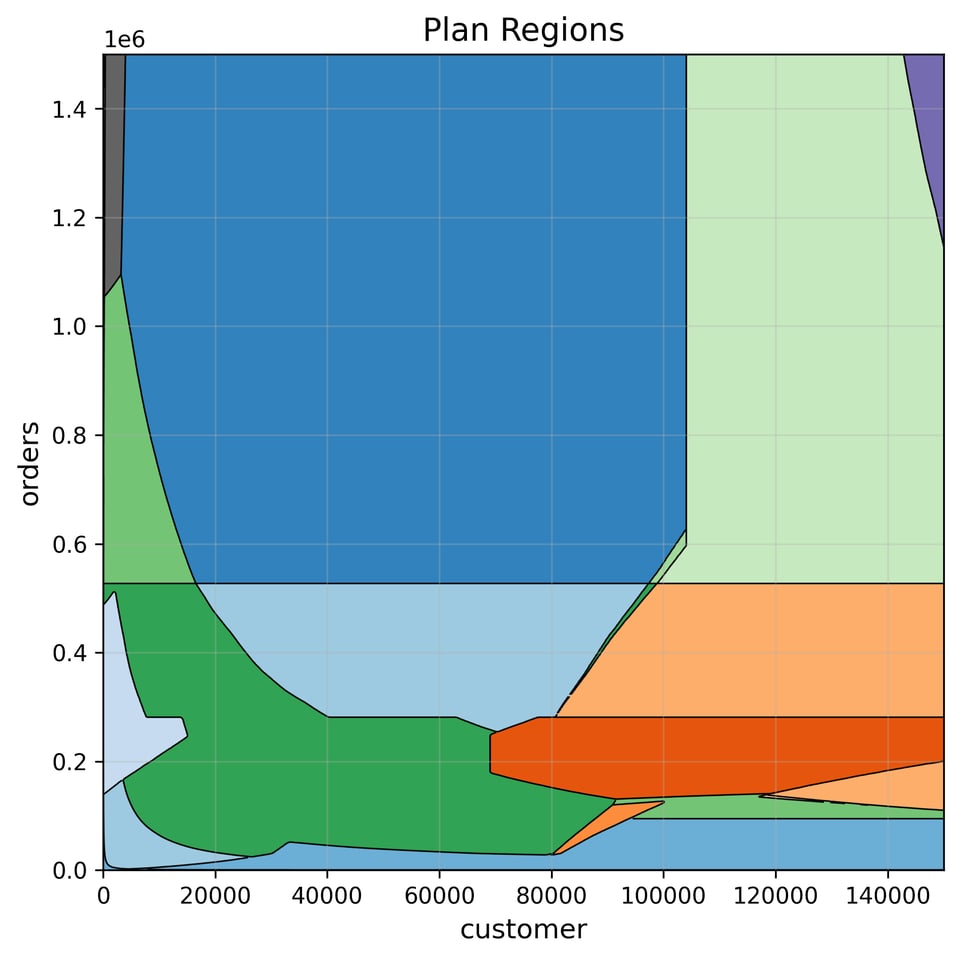
Each region in a plan diagram corresponds to a particular plan. If two sets of values give the same plan (modulo any concrete values, like cost estimates, or filter conditions derived from the templating) they're given the same colour. It was generated on my laptop for TPC-H scale factor 1.
This is an important object for us to keep in mind while we're thinking about plan caching.
Part of the conceit of a SQL database in the first place is that it's not appropriate to couple "what we want a query to compute" with "how that should be computed." This is why we have a query planner in the first place: two queries with different parameters might demand different plans, depending on data distribution. This is why we bundle the planner with the database, rather than having our client submit something like a plan directly: it lets clients ignore how a particular query is executed at the part of their application that's submitting it. The user probably still has to think about such things, of course, but it lets us separate the concerns of logical and physical schema design into separate places.
The plan diagram sort of represents this idea: when we get a new query, it will have different values for the "parameters" of it, and might necessitate different a different query plan.
Doing this planning for every query can be expensive, especially if the actual execution of the queries are comparatively cheap. This is why many database implement some form of plan caching.
A cached plan is a kind of templated query, whose values can be filled in cheaply.
When we see a query, in order to use a cached plan, we need to identify:
- which values in this query are "parameters," if the protocol does not allow for the user to specify such things explicitly,
- once we mod out by those parameters, does this query resemble some known "shape" of query, and
- which cached plan, if any, should we use for this query?
In a perfect world, we'd do this according to the above diagram: when we got a fresh query, we'd see if we've planned another query in the same region as it in the plan diagram, and use that same cached plan. In practice, this is neither easy, nor particularly necessary: it's not easy because building the plan diagram is slow, and checking containment in these arbitrary regions is not particularly easy, because they could have arbitrary discontinuities. And it's not necessary because the planner is already using plenty of heuristics and guesses as it is, so if we fudge a bit around the edges, that's fine. If it's wrong, it's not wrong by much.
Let's look at what the only real text we have on this subject has to say:

What they're saying is that they approximate the plan diagram into axis-aligned boxes to determine plan template usage. Empirically, this approximation works well enough in practice, and gives easy containment checks. But we should keep in mind that the thing we're actually doing here is approximating the diagram. That's the thing we're actually trying to model, we're trying to pretend that we've re-planned the query each time, and doing this sort of bucketing is a tractable alternative.
![Someone built a CRT case for the Switch 2 [video]](https://www.youtube.com/img/desktop/supported_browsers/edgium.png)


