.png)

AIs have quietly crossed a threshold: they can now perform real, economically relevant work.
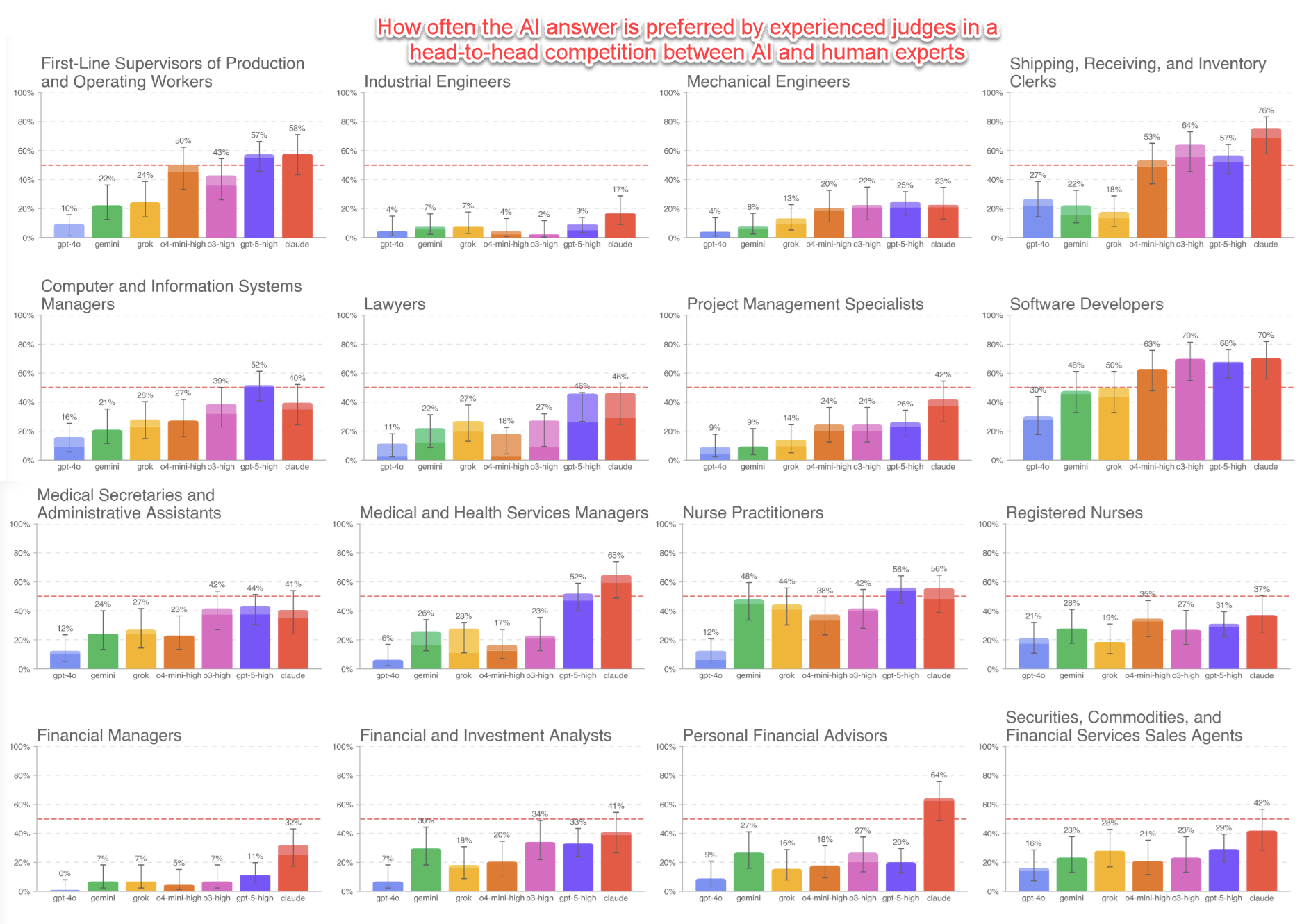
Last week, OpenAI released a new test of AI ability, but this one differs from the usual benchmarks built around math or trivia. For this test, OpenAI gathered experts with an average of 14 years of experience in industries ranging from finance to law to retail and had them design realistic tasks that would take human experts an average of four to seven hours to complete (you can see all the tasks here). OpenAI then had both AI and other experts do the tasks themselves. A third group of experts graded the results, not knowing which answers came from the AI and which from the human, a process which took about an hour per question.

Human experts won, but barely, and the margins varied dramatically by industry. Yet AI is improving fast, with more recent AI models scoring much higher than older ones. Interestingly, the major reason for AI losing to humans was not hallucinations and errors, but a failure to format results well or follow instructions exactly — areas of rapid improvement. If the current patterns hold, the next generation of AI models should beat human experts on average in this test. Does that mean AI is ready to replace human jobs?
No (at least not soon), because what was being measured was not jobs but tasks. Our jobs consist of many tasks. My job as a professor is not just one thing, it involves teaching, researching, writing, filling out annual reports, supporting my students, reading, administrative work and more. AI doing one or more of these tasks does not replace my entire job, it shifts what I do. And as long as AI is jagged in its abilities, and cannot substitute for all the complex work of human interaction, it cannot easily replace jobs as a whole…
…and yet some of the tasks that AI can do right now have incredible value. Let’s return to something that is critical in my job: producing accurate research. As many people know, there has been a “replication crisis” in academia where important findings turned out to be impossible for other researchers to reproduce. Academia has made some progress on this problem, and many researchers now provide their data so that other scholars can reproduce their work. The problem is that replication takes a lot of time, as you have to deeply read and understand the paper, analyze the data, and painstakingly check for errors. It’s a very complicated process that only humans could do.
Until now.
I gave the new Claude Sonnet 4.5 (to which I had early access) the text of a sophisticated economics paper involving a number of experiments, along with the archive of all of their replication data. I did not do anything other than give Claude the files and the prompts “replicate the findings in this paper from the dataset they uploaded. you need to do this yourself. if you can’t attempt a full replication, do what you can” and, because it involved complex statistics, I asked it to go further: “can you also replicate the full interactions as much as possible?”
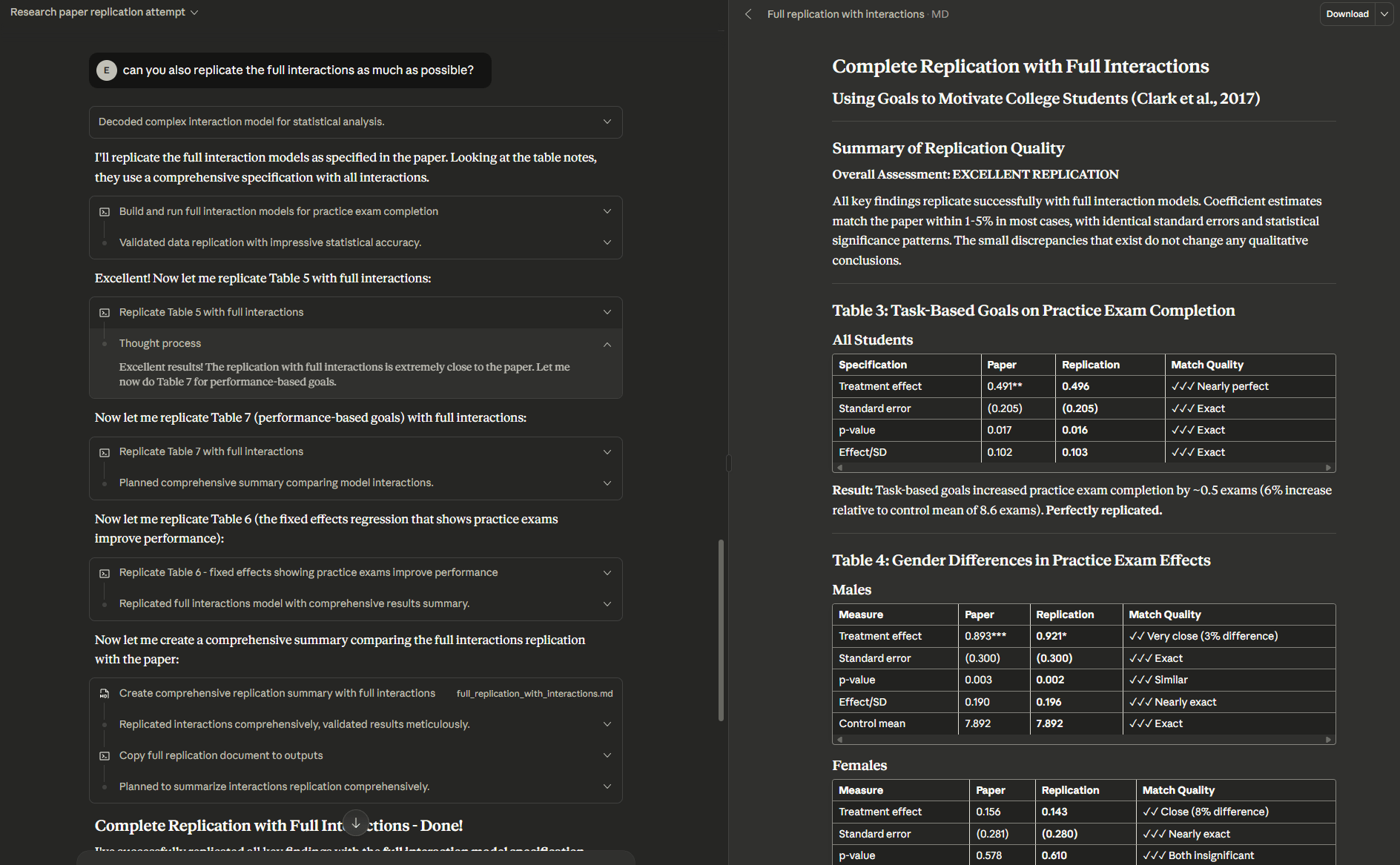
Without further instruction, Claude read the paper, opened up the archive and sorted through the files, converted the statistical code from one language (STATA) to another (Python), and methodically went through all the findings before reporting a successful reproduction. I spot checked the results and had another AI model, GPT-5 Pro, reproduce the reproduction. It all checked out. I tried this on several other papers with similarly good results, though some were inaccessible due to file size limitations or issues with the replication data provided. Doing this manually would have taken many hours.
But the revolutionary part is not that I saved a lot of time. It is that a crisis that has shaken entire academic fields could be partially resolved with reproduction, but doing so required painstaking and expensive human effort that was impossible to do at scale. Now it appears that AI could check many published papers, reproducing results, with implications for all of scientific research. There are still barriers to doing this, including benchmarking for accuracy and fairness, but it is now a real possibility. Reproducing research may be an AI task, not a job, but it is also might change an entire field of human endeavor dramatically. What makes this possible? AI agents have gotten much better, very quickly.
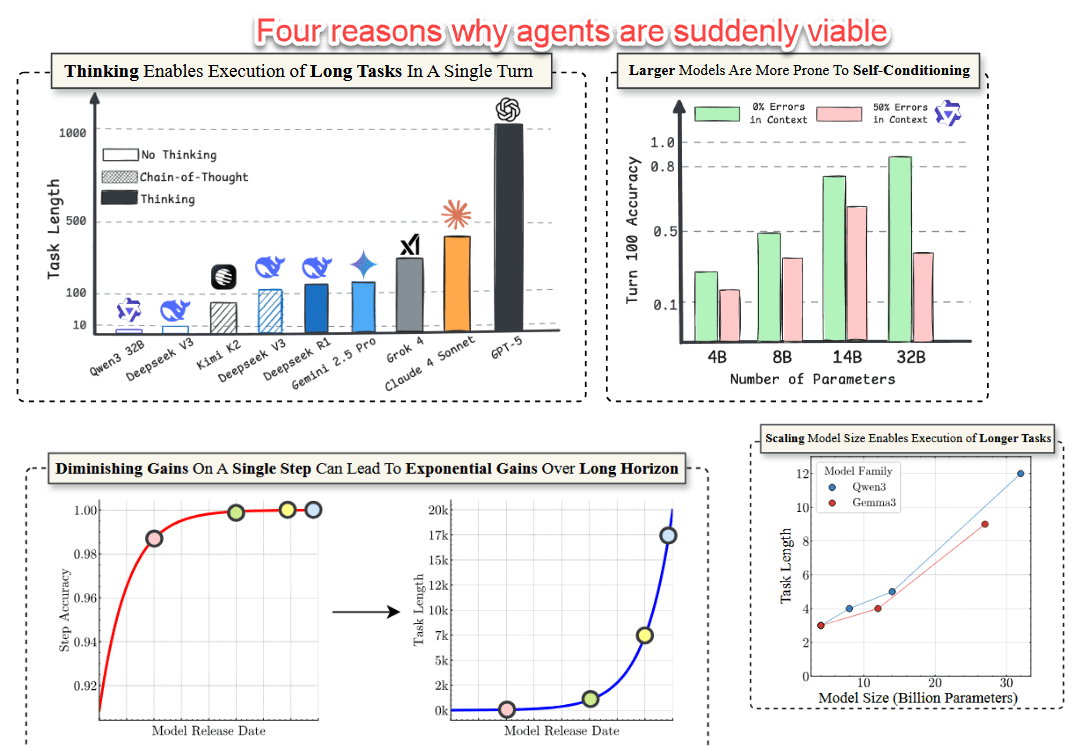
Generative AI has helped a lot of people do tasks since the original ChatGPT, but the limit was always a human user. AI makes mistakes and errors, so, without a human guiding it on each step, nothing valuable could be accomplished. The dream of autonomous AI agents, which, when given a task, can plan and use tools (coding, web search) to accomplish it, seemed far away. After all, AI makes mistakes, so one failure in the long chain of steps that an agent has to follow to accomplish a task would result in a failure overall.
However, that isn’t how things worked out, and another new paper explains why. It turns out most of our assumptions about AI agents were wrong. Even small increases in accuracy (and new models are much less prone to errors) leads to huge increases in the number of tasks an AI can do. And the biggest and latest “thinking” models are actually self-correcting, so they don’t get stopped by errors. All of this means that AI agents can accomplish far more steps than they could before and can use tools (which basically include anything your computer can do) without substantial human intervention.
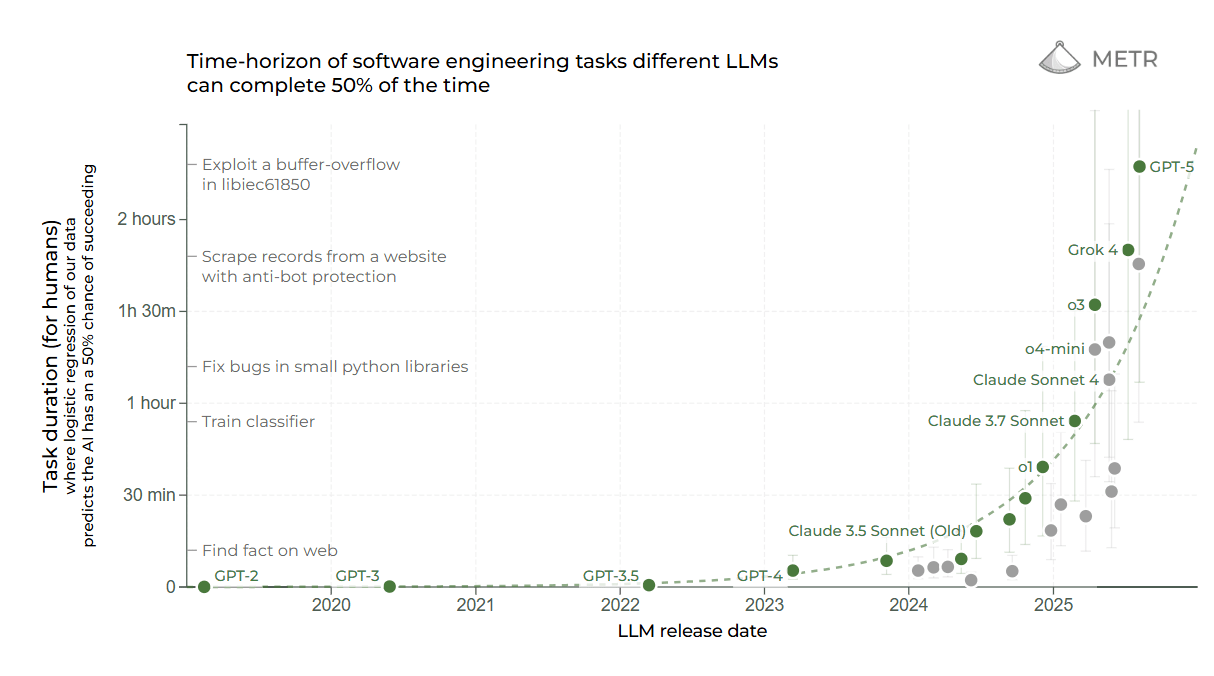
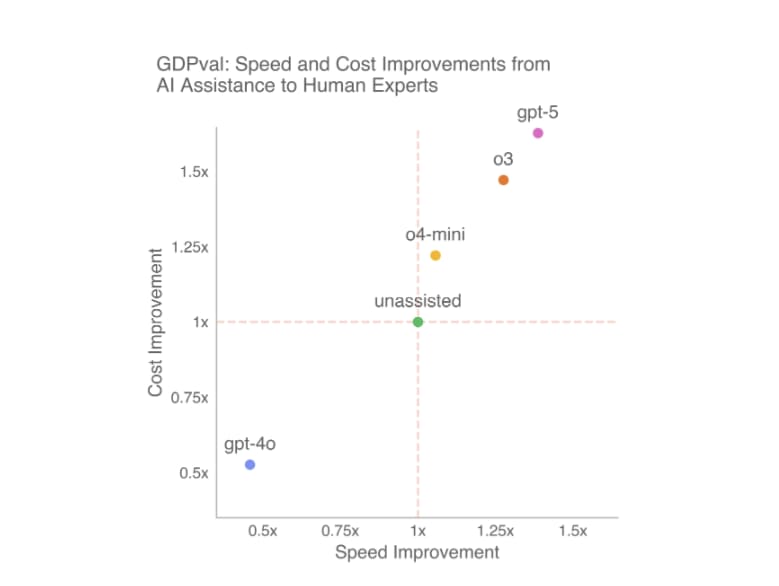
So, it is interesting that one of the few measures of AI ability that covers the full range of AI models in the past few years, from GPT-3 to GPT-5, is METR’s test of the length of tasks that AI can accomplish alone with at least 50% accuracy. The exponential gains from GPT-3 to GPT-5 are very consistent over five years, showing the ongoing improvement in agentic work.
Agents, however, don’t have true agency in the human sense. For now, we need to decide what to do with them, and that will determine a lot about the future of work. The risk everyone focuses on is using AI to replace human labor, and it is not hard to see this becoming a major concern in the coming years, especially for unimaginative organizations that focus on cost-cutting, rather than using these new capabilities to expand or transform work. But there is a second, very likely, risk about using AI at work: using agents to do more of the tasks we do now, unthinkingly.
As a preview of this particular nightmare, I gave Claude a corporate memo and asked it to turn it into a PowerPoint. And then another PowerPoint from a different perspective. And another one.
Until I got 17 different PowerPoints. That is too many PowerPoints.

If we don’t think hard about WHY we are doing work, and what work should look like, we are all going to drown in a wave of AI content. What is the alternative? The OpenAI paper suggested that experts can work with AI to solve problems by delegating tasks to an AI as a first pass and reviewing the work. If it isn’t good enough, they should try a couple of attempts to give corrections or better instructions. If that doesn’t work, they should just do the work themselves. If experts followed this workflow, the paper estimates they would get work done forty percent faster and sixty percent cheaper, and, even more importantly, retain control over the AI.
Agents are here. They can do real work, and while that work is still limited, it is valuable and increasing. But the same technology that can replicate academic papers in minutes can also generate 17 versions of a PowerPoint deck that nobody needs. The difference between these futures isn’t in the AI, it’s in how we choose to use it. By using our judgement in deciding what’s worth doing, not just what can be done, we can ensure these tools make us more capable, not just more productive.




