.png)

Our browser-based game development software Construct commonly saves user projects to a .c3p file. However that is really just a ZIP file containing a folder project. You can rename the .c3p project file to .zip and extract it with anything that can read ZIP files.
With disturbing frequency, people emailing support desperate for us to recover their project file that no longer opens in Construct. In rare cases this is due to a bug with Construct, in which case we treat it as a high priority issue to resolve. However in most cases they send us a project file that is corrupt. Sometimes the file consists entirely of zero bytes, meaning there is no data to recover and nothing can be done. Other times the file appears to have valid data in it, but it is no longer a valid ZIP file. Sometimes we have a go with tools like WinRAR's Repair feature. These occasionally produce a handful of files, but not enough to be able to open the project. More often, they don't manage to recover any files at all. In these cases we have to tell the customer: sorry, your only option is to recover a backup. Because everyone backs up their important digital work to multiple off-site locations, right?
Of course, not everyone does. Stuff happens, people end up with a corrupt project file, and sometimes they either don't have backups or their backups ended up corrupted too. Oh dear. Usually all we can say is unfortunately it's a tough lesson on the importance of backups. But recently we had a particularly bad case: a customer sent us an approximately 1 GB project file which was corrupt, for a game already published to Steam, which they'd spent months working on. They told us all their backups were corrupt too. Ouch. I took pity and decided to see what could be done.
Predictably, WinRAR's repair tool produced a 1 GB ZIP file that contained nothing. I'm not sure what it does exactly, but it doesn't seem very effective. After searching around a bit I found another tool that did seem to be able to recover files, but was excruciatingly slow - it took hours on a high-end development PC - and then after that unimpressive performance, it asked me to pay before I could extract anything. It was so slow, I thought I'd race it: could I write some code to extract what files were still intact from the ZIP before it finished? Indeed, I won!
The ZIP file format
ZIP is an ancient file format, dating back to the 1980s. Some design decisions are to optimize writing to a floppy disk. It was not designed by an industry standards body - its specification appears to be a very long text file named APPNOTE.TXT which references IBM mainframes, MS-DOS and many other defunct systems and manufacturers. This is hardly ideal and frequently a compatibility nightmare for app developers. However backwards compatibility can end up a mighty force; newer and better archive formats exist, but have little hope of completely replacing ZIP. So we are pretty much stuck with it and will be for many years to come.
Wikipedia has a good summary of the ZIP file format with some helpful diagrams, one of which I've included below.
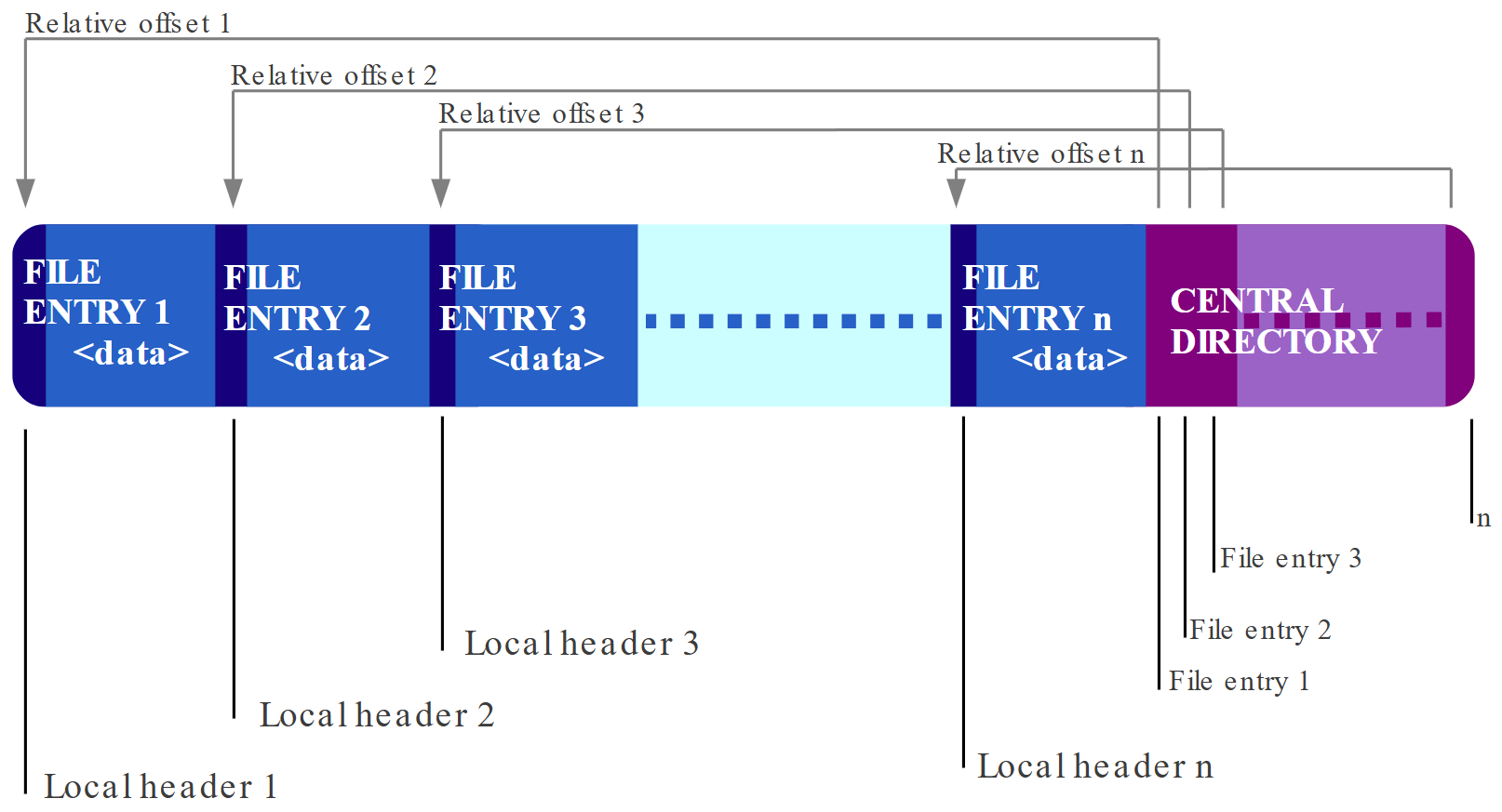 The ZIP file format diagram. Credit: Wikipedia
The ZIP file format diagram. Credit: Wikipedia
Perhaps surprisingly, the ZIP file puts the central directory - which lists the content of the ZIP file - at the end of the file. ZIP files start with a sequence of "local" file headers followed by compressed file data. There are tons of quirks and amendments that make it pretty difficult to write a ZIP file reader - for example the file header can leave the data size as 0, and then attach a data descriptor after the compressed data, which itself can come in four variants (I think). We'll come back to that.
A key thing to note though is that each file header starts with a special signature: the bytes 50 4B 03 04. This means they are potentially identifiable even without the central directory.
The corrupt ZIP
The file I had been sent was about 1.1 GB, but looked like it mostly contained valid data. However typical ZIP tools could not read it, indicating damage towards the end of the file meaning the central directory was not readable. What if the intact file entries could be recovered without referring to the central directory at all? This is indeed possible! I couldn't find an easy-to-use tool that does this. One probably exists and a commenter may end up pointing out. But as I couldn't find one, and I've worked with the ZIP file format a bit in the past, I had a go myself.
Directly extracting file entries
Each file header contains the following information (amongst several other details):
- The special signature identifying the file header
- The compression method used
- The compressed and uncompressed size
- The filename
Then the compressed file data follows. This is actually enough information to extract the file if you know where the file header is. Usually the location is provided by the central directory. File entries can in theory be anywhere: tightly packed in the file, or with lots of padding in between; the first entry could appear some way in to the file; some file entries may even be unused and not referenced by the central directory. However in recovery mode, we can just scan the file for the special byte sequence 50 4B 03 04, assume it's the start of a file header, and hope for the best.
Identifying the data size
I wrote code to scan a file for file headers this way, with lots of error checking and continuing the search if things looked wrong. However the main complication is finding the compressed data size. Normally this is just specified in the compressed size field of the header. However there are several ways the data size can be specified:
- In the file header normally
- In the "extra field" as part of the Zip64 format
- Appended after the compressed file data, in a special "data descriptor" - in both standard 32-bit and also extended Zip64 format
- In the central directory entry for the file - which in this case we're ignoring
There's a lot of redundancy in the ZIP file format, but fortunately for recovery purposes, this means there's multiple sources of information to try.
It would surprise me none if there were a couple of other ways to specify the data size, or if some files out there use different values in different places for the same file. There are extra complications, like the compressed size in the file header may be 0, or may be 0xFFFFFFFF, depending on which of the other modes is in use. It's a real headache working out the details.
I wrote code to work out the compressed size as best as I could. However the file I was working with consistently used data descriptors after the compressed data. I think in this case normally a ZIP extractor will refer to the size in the central directory. However in this case we're disregarding that. We need the information in the data descriptor to work out where it is to read it - an unfortunate catch-22. So how can we figure out where it is?
Finding the data descriptor
The data descriptor looks like this:
- An optional signature: the bytes 50 4B 07 08
- A CRC-32 checksum of the uncompressed data (4 bytes)
- The compressed size (4 bytes)
- The uncompressed size (4 bytes)
We can scan through the compressed data looking for the byte sequence of the signature. Of course this is not reliable: it is possible the compressed data contains that byte sequence by chance. We can reduce the chance of mistakes by verifying the compressed size we read matches what we expect at that position in the data, and if not, continue searching. This is still possible to return a false positive - compressed data could contain anything, after all - but hopefully the chances of that are slim.
A more difficult case - yet again proving that the ZIP file format is completely bananas - is that the data descriptor may not start with any signature at all. ZIP files may contain compressed file data immediately followed by a CRC-32 checksum, which could be anything, followed by the compressed size we want. And indeed the ZIP file in question does this. How can we find the data descriptor in that case?
The solution is to scan through the compressed data looking for the compressed size that we'd expect at that point! Given there is no signature in this case, the compressed size we want comes 4 bytes after the end of the compressed data (past the CRC-32). For example if the compressed data is 100 bytes, then there should be a 4-byte value reading 100 at 104 bytes from the start of the compressed data. We can also scan for this. Again it's not perfectly reliable, as the compressed data can contain anything, and we might hit a false positive. Strangely enough though, this seems generally fairly reliable - in my admittedly brief testing, it seemed to get the vast majority of files.
One small refinement I came up though was to make use of the smallest possible file sizes, many of which have been helpfully collected here. For example I found some PNG files - stored with compression disabled as they are already compressed - were incorrectly finding the compressed data was just 28 bytes long. It's not surprising that a 4-byte value reading 28 might be in a PNG file at an offset of 32 bytes. The minimum size of a valid PNG is apparently 67 bytes. Therefore if we assume the PNG file is valid, it is not possible for the file to end that soon; the search should in fact only begin at the minimum size. My intuition is that the larger the number, the less likely it is to be a false positive. This helped correctly extract some small PNG files in one sample ZIP.
So there you have it - if there is one, searching for the data descriptor like that is the one weird trick to extract a corrupt ZIP file. And a legitimate use for finding the minimum possible size of various file formats!
Extracting files
Once the compressed size is known, we finally have what we need to extract the file. Things like the uncompressed size and CRC-32 can be disregarded. We can just take the range of compressed data, decompress it, and write it to a folder with the given filename. Conveniently modern browsers provide DecompressionStream, which supports the "deflate-raw" format commonly used by ZIP files. I also used the File System Access API method showDirectoryPicker to gain write access to a folder for extracting files to, complete with the subfolder structure of the ZIP file. That's Chromium-only (Chrome, Edge etc) for the time being, but for a small tool like this it'll do.
Results
So now I have a custom tool that is able to scan through a ZIP file, ignoring the central directory completely, finding files by scanning for file headers, and using different strategies including scanning for a data descriptor to establish the compressed data size, and then finally extracting the file directly to a chosen folder on disk.
The customer's project file successfully extracted up until about the last 80 MB of the file, beyond which it failed to extract anything. I think that's pretty good - in terms of data, it got through about 93% of the archive, which is far better than any other tool I've managed to use. I haven't looked closely at the data, but my best guess is that last 80 MB turned to garbage: the tool could not find another file header signature in any of that data. Perhaps a system fault occurred and it wrote random or unrelated data at the end of the file, wiping out the central directory, and rendering it unreadable to most tools.
Unfortunately the rest of the story wasn't such good news: dozens of other files were entirely missing, including significant parts - sadly, all event sheets were lost. Further, it then transpired that even after extracting the files successfully from the corrupted ZIP, many other files were still corrupt. I'm not sure why this is - it's possible the tool hit false positives and incorrectly read out truncated files, or it's possible the system in question had a fault that regularly corrupted files. Still, after considerably more work manually adjusting the project file to remove references to missing files and replace corrupt files with placeholder content, I did eventually produce an openable Construct project file. It's still a hard lesson in the importance of backups, but it might help them get a head start rebuilding their project if they had no other option.
Conclusion
Keep backups, folks. This is your periodic reminder: disasters happen. Neither the hardware nor software in your system is perfect. Things can and do fail. And you don't want to have months of work at stake when it does. Assume your hard drive fails and starts writing random data every time you press 'Save'. How do you get your work back then?
The key is to have off-site backups - somewhere else entirely with a copy of your data. Then even if your PC goes bang and never starts again, or the building burns down, or someone breaks in steals all your devices, or you're hit by a ransomware attack, or any of dozens of other possible disasters happen - you can get a new device, restore your backup, and continue on.
Construct's cloud save feature is good for reliable off-site backups. Some cloud services also provide a file history, allowing you to roll back to earlier versions of files. If you have important work that is definitely worth paying extra for if it's not included in the base product. Even better, use a folder project with source control like GitHub, even if you work alone. GitHub counts as an off-site backup, and the ability to roll back to any prior version of your project means no matter what goes wrong with your project data, you can always undo it.
To help others I've published my ZIP recovery tool online, and the source code is on GitHub. You can also test it with valid ZIPs! It should still be able to extract them even without reference to the central directory. I intend to tweak it over time to better recover corrupt ZIPs, as we get sent them from time to time, and they will probably all be corrupt in different ways. We're also intending to make changes to Construct to ensure it writes ZIP files that are more recoverable, such as by adjusting its use of data descriptors. Hopefully over time this means we can develop a robust tool that can as reliably as possible extract whatever remains from a corrupt ZIP file - and hopefully save a couple of people from disaster. But it is never guaranteed to work, and using it is a desperate measure. So save yourself the stress: check you have a good backup procedure in place!



