.png)

This is the fourth post in my series about differentiable programming for dynamic workflows. The code is available here.
In my previous post, I explored how differentiable programming transforms static agent workflows into learnable graphs — where structure emerges from program execution, and every decision becomes a learning target. We built a customer service agent that could learn to route tickets correctly, moving from hardcoded decision trees to adaptive classification that improved with data.
But routing is just the foundation. Getting your agent to correctly identify "My order is late" as an ETA request doesn't guarantee the ETA branch knows how to respond appropriately. This is where most production agents break down: they fail at ensuring that branch knows how to behave once it gets there.
Let's revisit the customer service agent from the previous post. We had a Router that classified tickets into four categories, dispatching to specialized branches that handled ETA requests, missing items, driver issues, and fallback cases.
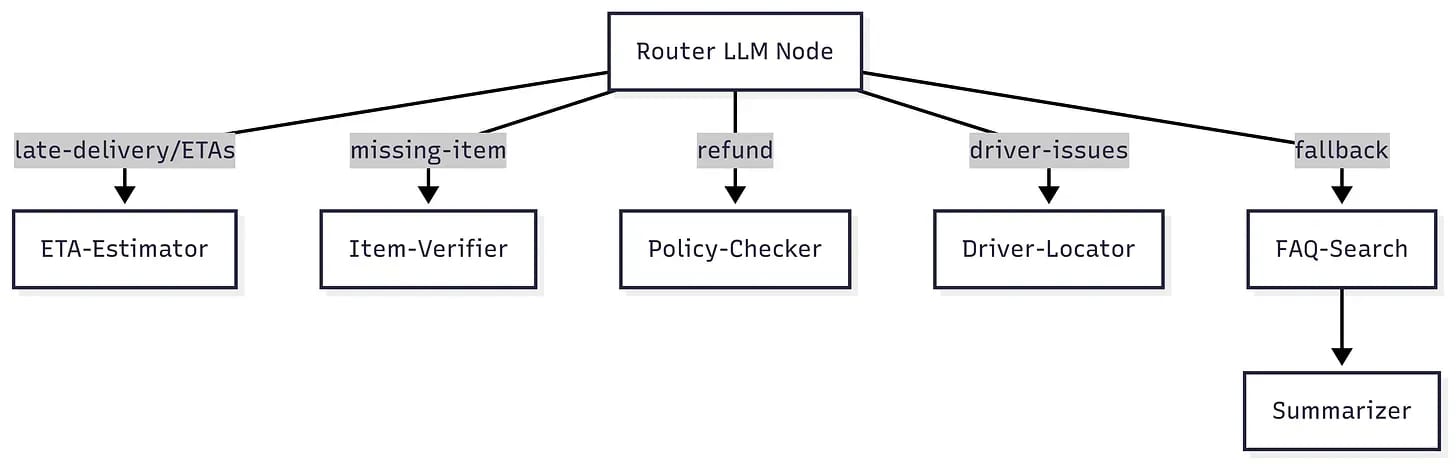
The routing worked beautifully after optimization. But when we look at the actual responses coming from each branch, something was off. The ETA branch would produce responses like:
"The eta for your order #1783 is currently being reviewed, and we'll provide an update as soon as possible."
Compare that to what a well-trained support agent might say:
"Thank you for reaching out about your order #1783. I've checked on this for you, and the current ETA is approximately 20 minutes. We appreciate your patience, and if there are any further updates, I'll be sure to let you know right away!"
Same information. Same routing decision. But — completely different impact on the end user! So the question becomes: can we train an agentic workflow to not just route correctly, but to behave appropriately once it gets there?
The key insight from learnable graphs applies here too: you can't optimize what you don't measure. If we want behavioral consistency to be learnable, we need to define exactly what good behavior looks like.
For ETA responses, we care about several behavioral properties: appropriate tone, concrete information, acknowledgment of the user's concern, and reasonable length. Here's one way we can encode that as a metric.

In the above, we create explicit behavioral supervision — four concrete rules that define what good ETA responses should contain:
Must mention "eta" (content requirement)
Must include friendly language like "thank" or "please" (tone requirement)
Must be appropriately sized: neither too terse nor too verbose (format requirement)
Must provide a concrete time estimate in minutes (specificity requirement)
Each satisfied rule earns a point. The final score is the average — a clean 0.0 to 1.0 signal that the optimizer can learn against. The beauty of this approach is composability. Each branch can get its own behavioral requirements to optimize against. For instance,
Missing Items
Must acknowledge problem within first 15 words
Include concrete timeline (3-5 days, 24 hours, etc.)
Mention specific remedy (refund/replacement/credit)
Empathy score > 0.7 (via sentiment analysis)
Driver Issues
Provide contact method within 20 words
Include estimated resolution time in minutes/hours
Action-to-explanation ratio > 2:1
Must contain trackable reference (phone number, tracking ID)
Fallback
Redirect without negative language ("can't," "unable," "sorry")
Offer 2+ alternative solutions
Escalation path mentioned within 25 words
Question-to-statement ratio < 0.3 (more definitive guidance)
Each metric transforms subjective "good service" into measurable behavioral targets like word positioning, sentiment thresholds, and information density ratios that the optimizer can systematically improve.
Here's where it gets interesting. In traditional prompt optimization, you'd “vibe tweak” each branch independently — better ETA prompts, better missing item prompts, better fallback prompts, etc. But behavioral consistency emerges from how these components interact across the entire execution path.
DSPy's joint optimization approach treats the entire program as the learning target. It doesn't just optimize individual modules — it optimizes how routing decisions set up behavioral responses for success.
Here’s some example code that creates an evaluate function using DSPy that measures how our support bot does on the friendly ETA metric we defined above:


Running this evaluation on our baseline agent shows exactly what you'd expect: decent routing accuracy, but inconsistent behavioral quality. The system gets messages to the right place but doesn't always know how to behave appropriately once they arrive.
Now we run the optimizer, but this time we're optimizing for behavioral consistency across the entire execution graph:
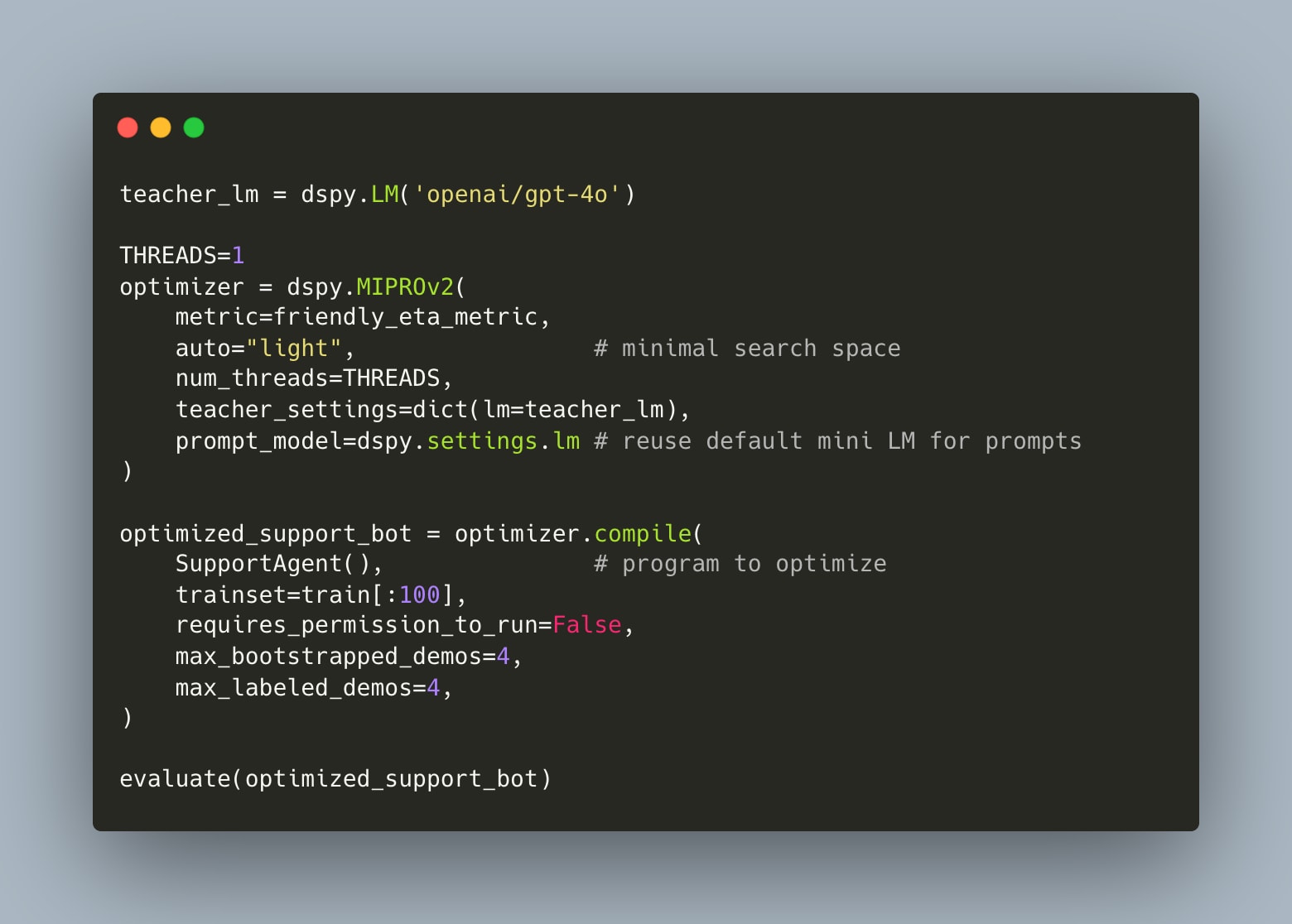
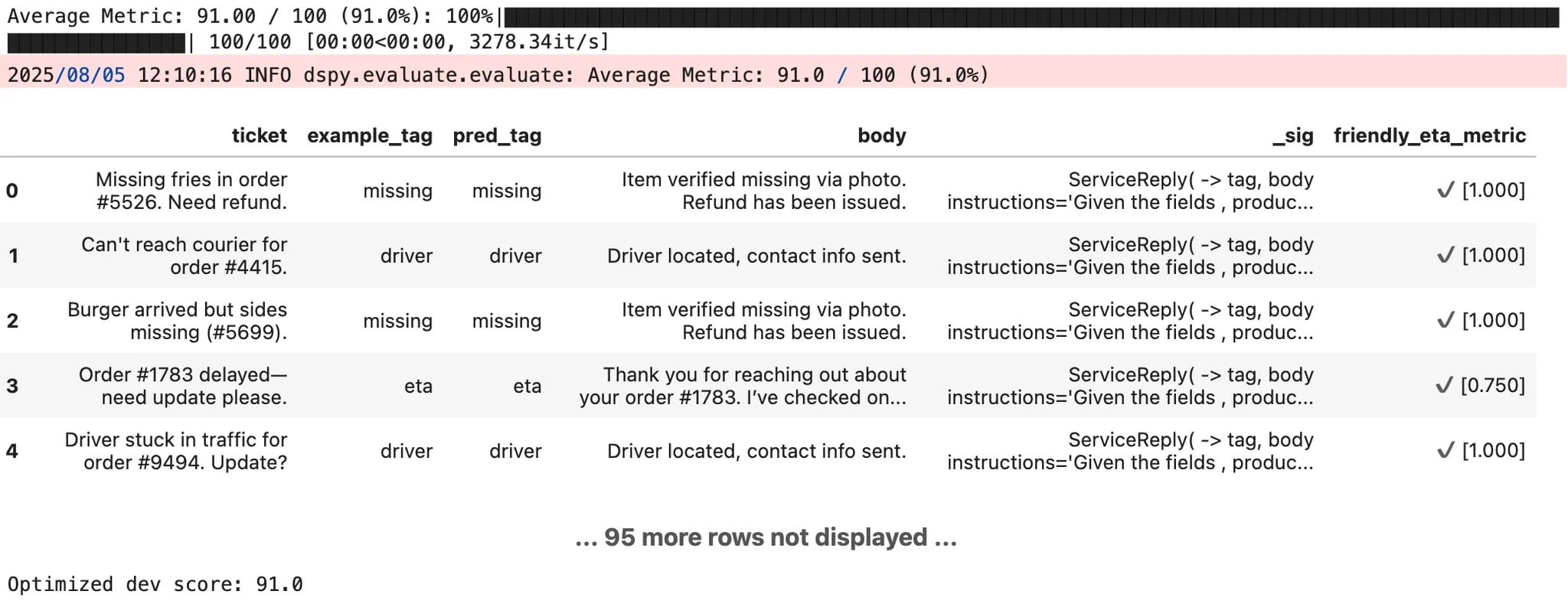
What happens under the hood is fascinating. The optimizer traces the entire program execution, identifies all the learnable parameters (routing logic, response generation, context flow), and searches for improvements that maximize behavioral consistency across component interactions — in effect, learning how routing decisions should preserve context for downstream behavioral responses, and how each branch should maintain consistency with the overall interaction pattern.
This creates the same kind of emergent intelligence we saw with routing optimization, but at a higher level. Better routing enables more contextually appropriate responses, which generates better training signals for behavioral consistency, which improves how routing decisions consider downstream behavioral requirements. The components co-evolve to support system-level behavioral properties.
What makes this approach powerful is how it scales to compound scenarios — orders that are both late and missing items, or driver problems requiring policy escalation.
Previously, behavioral consistency meant extensive manual oversight: reviewing every response type, tuning individual prompts, hoping local improvements would compose into good global behavior. Now, behavioral consistency becomes a first class optimization target. Define appropriate behavior at the system level, and the optimizer ensures it's maintained across all execution paths as complexity grows. What we're building toward are workflows that don't just make correct decisions, but learn better ways to communicate those decisions based on what actually works in practice.
Most agents today function like sophisticated routers — they manage state, classify inputs, and dispatch to appropriate handlers.
They're reliable executors, but they don't learn how to execute better over time.
Making behavioral properties learnable changes that foundation. Your agent becomes something more than a script that follows routing logic. It becomes a system that evolves its behavioral patterns based on how well they work in practice.
When both routing decisions and behavioral execution are learnable, you move from automation to genuine adaptation. Not just systems that follow predefined rules, but systems that discover better ways to behave through experience.
This represents the next evolution of learnable graphs: from optimizing what decisions to make, to optimizing how to execute those decisions appropriately across different contexts and interaction types.
Coming next! Allowing workflows to learn new paths — dynamically grow system capabilities based on execution patterns rather than predetermined architectures.

/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/filer_public/71/c5/71c530e2-e726-4e9f-9053-6a4242425b7d/uzbek2025_250725_0003-21.jpg)
![Caching Playwright on CI [video]](https://www.youtube.com/img/desktop/supported_browsers/opera.png)
