.png)

Let’s walk through the evolution of image optimization strategies using a common scenario: turning large, user-submitted images into lightweight thumbnails for fast, responsive websites.
Each approach solves certain problems while introducing new complexities, leading us to a solution that redistributes responsibilities in an elegant way : the client first tries to load the processed image directly, and if it’s missing, it goes through a proxy that takes care of processing and caching it.
TL;DR check the GitHub repo err0r500/imgproxy-cache to see an example implementation.
Strategy: Serve exactly what users upload, no questions asked.
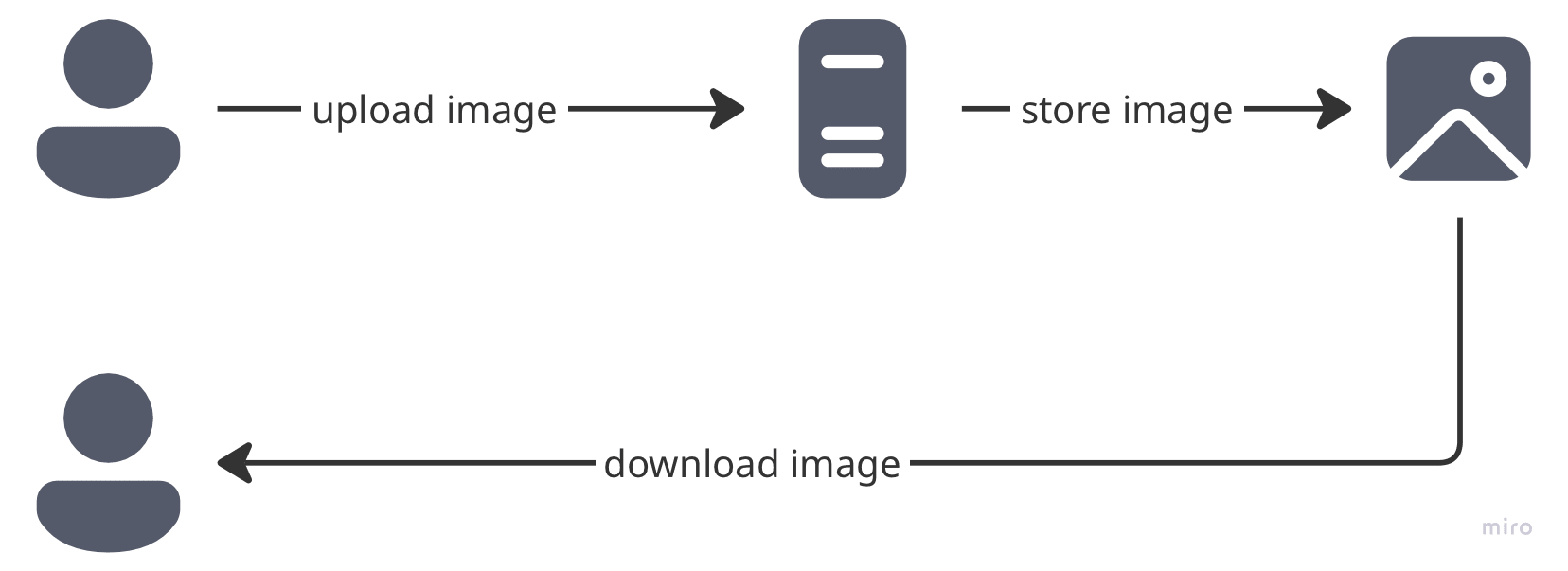
The simplest and sadly least viable option is to not optimize at all: just serve what the user uploaded.
Reality Check: This approach quickly becomes untenable. Users waiting 30-60 seconds for a page full of thumbnails to load will abandon your site. Your bandwidth costs skyrocket, and mobile users on limited data plans suffer the most.
Verdict: Simple but completely unviable.
Strategy: When a user uploads an image, you optimize it, store the original and the optimized version, then serve the latter.
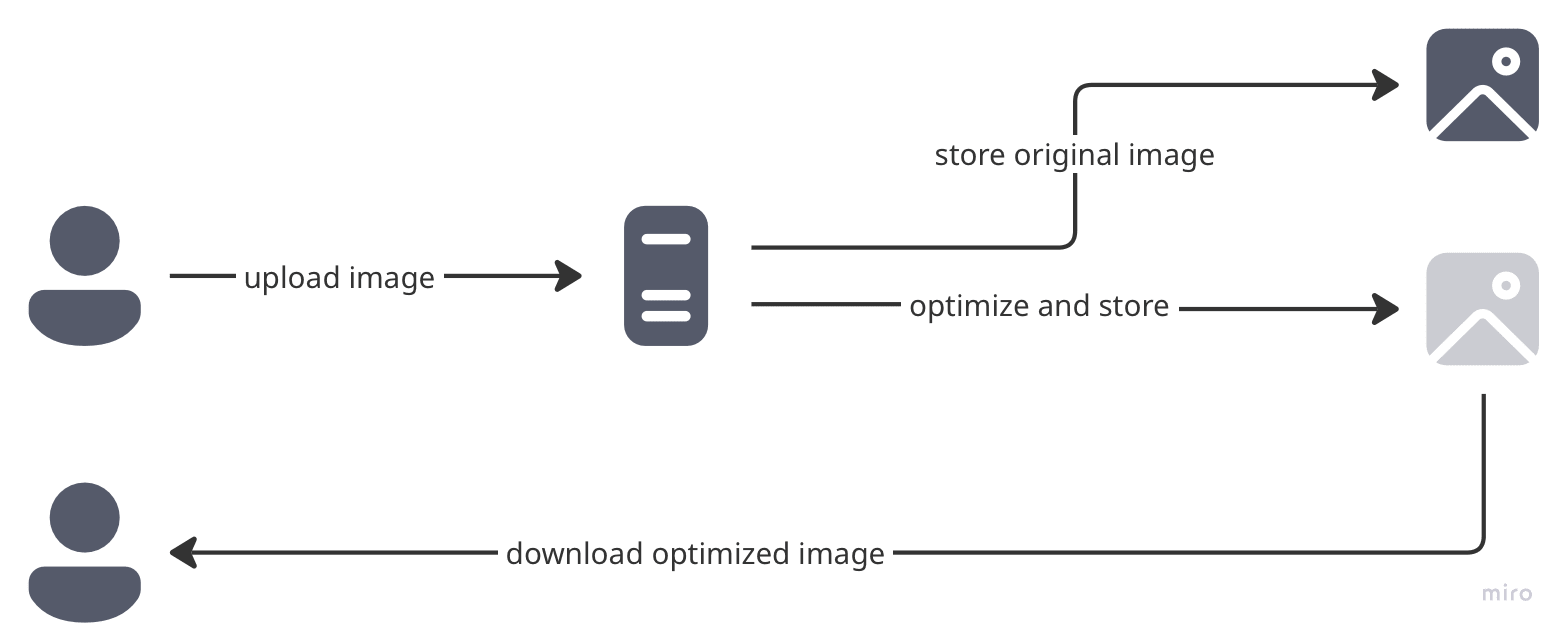
This one is just a bit more complicated, right? Wrong. It comes with nasty surprises:
The Format Evolution Nightmare: What happens when you need to transition from JPEG to WebP? Or when AVIF becomes the new hotness? Surprise! You’re stuck reprocessing your entire image library while your server melts down.
The CPU Hostage Situation: All the load of image optimization (which can be quite CPU-intensive) is on the same server that processes other requests. Picture this: “Alice, please wait until I finish crunching Bob’s 20 high-resolution paintball photos before you can log in.” Your server is basically held hostage by pixel-crunching operations.
Verdict: Works great until it doesn’t. Then it really, really doesn’t.
Strategy: OK, so now the server just stores the original image and another service reacts to file creation or runs regularly to process new images and store optimized versions.
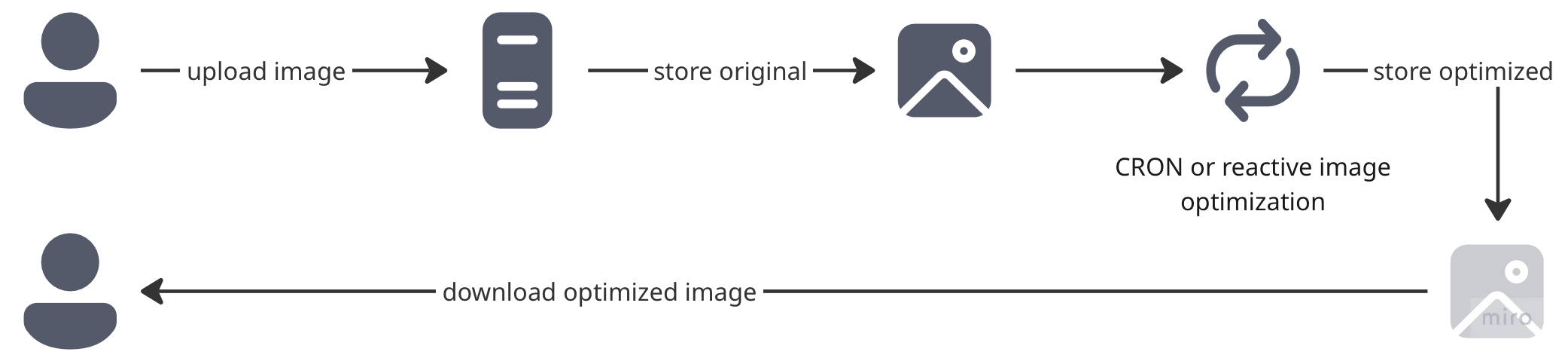
Congratulations! We don’t have a single service supporting all the load. But guess what? We’ve just traded our old problems for shiny new ones:
The Synchronization Dance: With asynchronous handling, how do we know when we’ll be able to serve the optimized version? Do we show placeholders? Return 404s and hope for the best? Serve the unoptimized original and watch our CDN bill explode?
The Reprocessing Hamster Wheel: We’ll still have to reprocess all images if we change what “optimized” means. Every optimization strategy change means your background workers are about to have a very bad week.
Storage Bill Multiplication: Every optimization variant needs storage space. Ten formats times five sizes equals... bankruptcy?
Verdict: Solves the CPU hostage crisis but introduces a coordination nightmare.
Strategy: Route image download requests through an image processing proxy that processes and serves images on the fly.
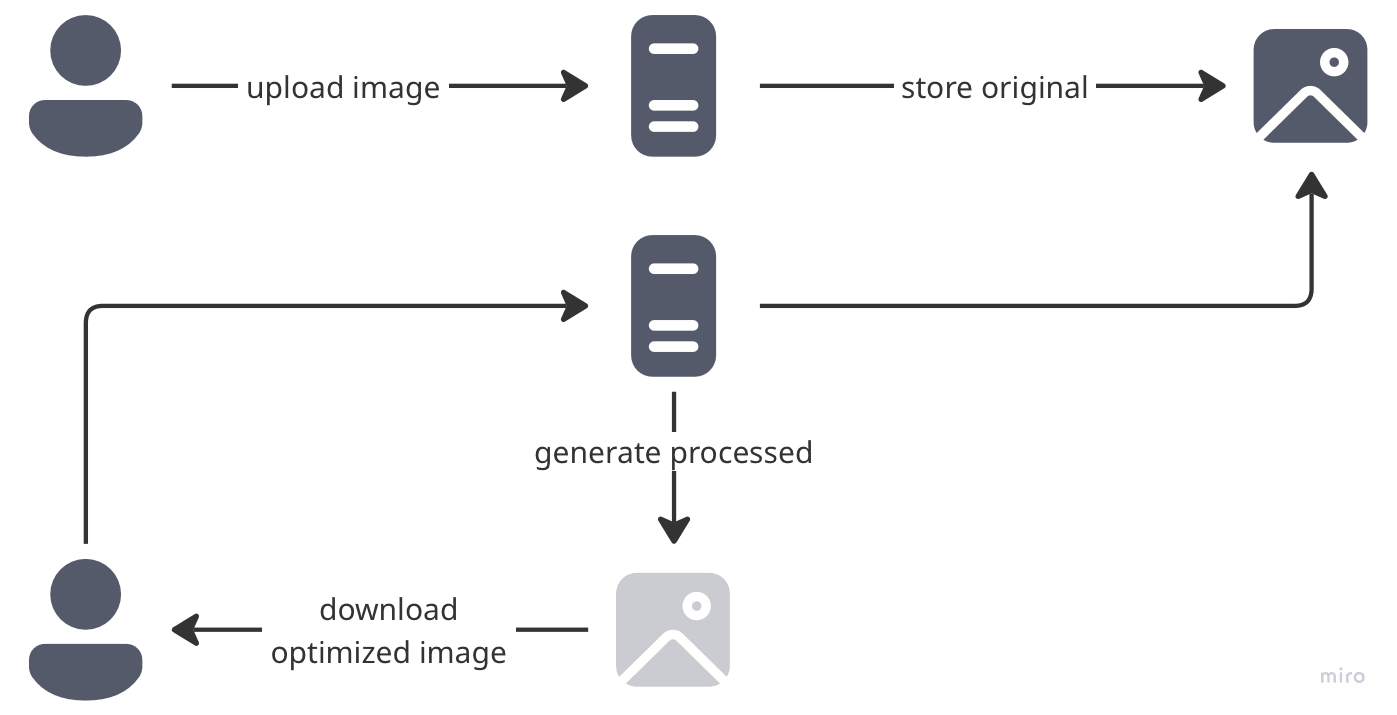
A more recent way to handle this—very modern, very cool. The nice thing is that optimization specs come from the client, so we don’t have to run background jobs to reprocess everything. The client wants WebP? They get WebP. Need a different size? Coming right up!
The Catch: It quickly becomes expensive to process every single image every time. Your proxy is essentially burning CPU cycles like they’re going out of style.
Verdict: Flexible and modern, but your CPU bills will make you cry.
Strategy: So let’s add a cache proxy in front of the image processing proxy.
Each download request goes through this cache proxy. If the optimized image exists, it’s served. Otherwise, the image processing proxy is hit to generate and store the optimized image.
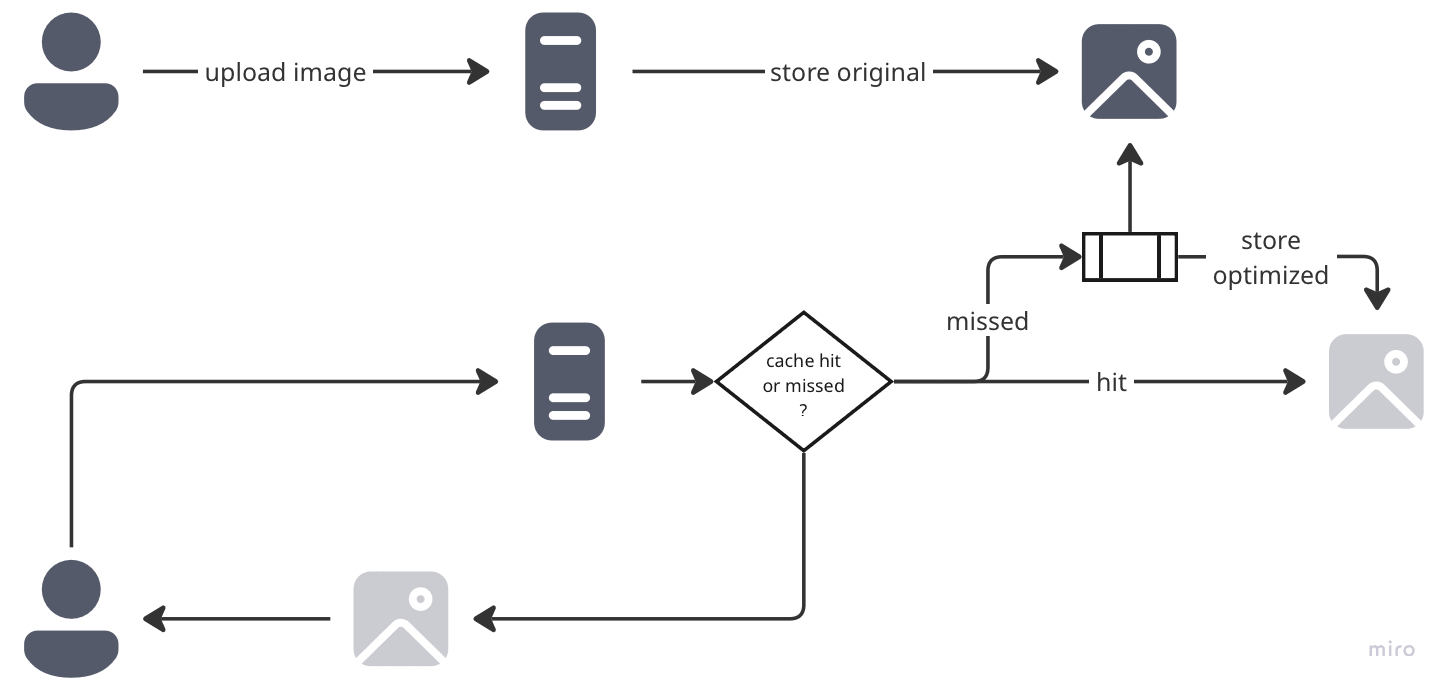
Sounds perfect, right? Well...
The New Reality: This proxy is hit on every single request and becomes a critical part of your infrastructure. This proxy goes down? Your entire image infrastructure goes down!
Verdict: Efficient but you’ve just created a new single point of failure that gets hit on every single image download.
Strategy: A more viable solution is to replace your cache proxy by a CDN.
This feels like the sweet spot, right? You get on-demand processing AND global distribution. The first request hits your proxy, processes the image, and the CDN caches it. Subsequent requests? Lightning fast from the edge!
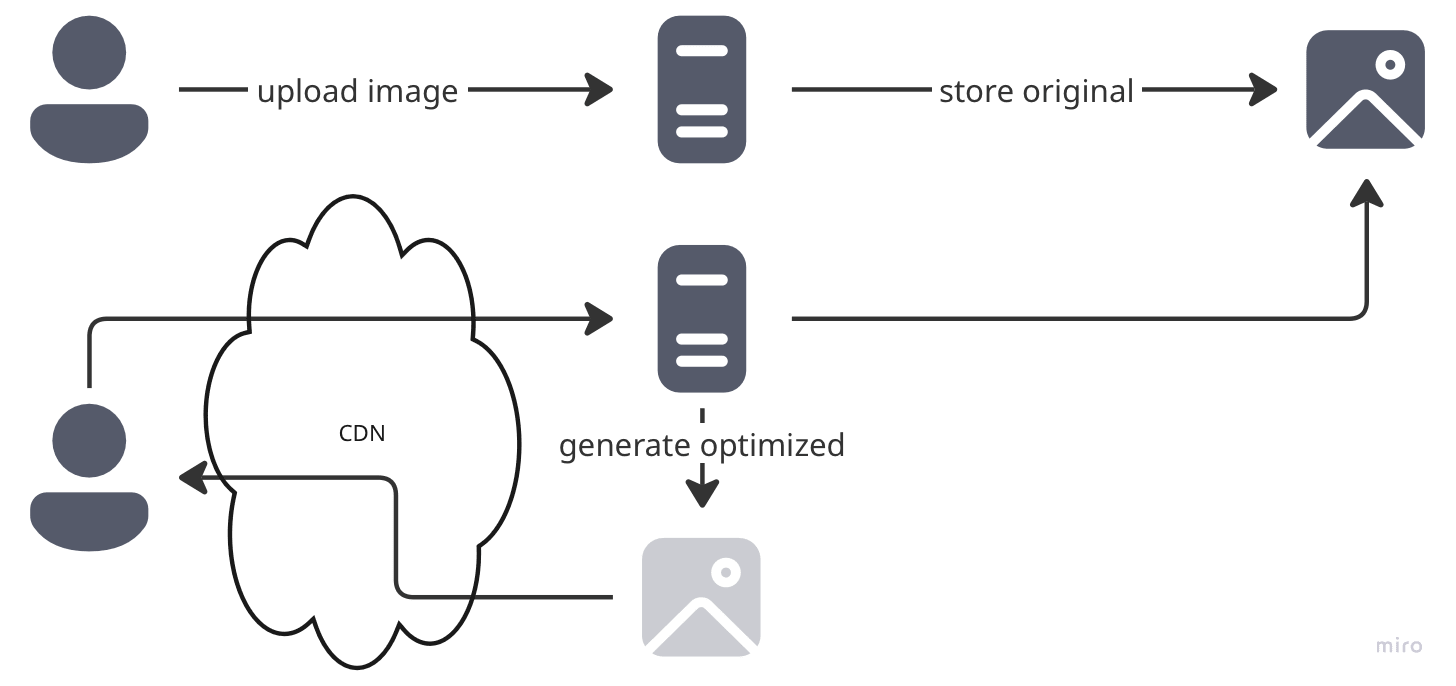
Actually, this one works quite well. Some may wonder why you added 2 elements to your architecture for something “as simple as” serving images but that’s most likely because they never had to deal with the problem.
Verdict: Better than raw proxy serving, but you’re managing two complex systems that need perfect coordination.
Strategy: Just throw money at the problem and let someone else implement the option 6 for you ! Use Cloudinary, Imgix, ImageKit, or any of the dozen services that promise to handle all your image needs and believe the sentence “[redacted]’s price will always be more cost effective than doing all of this in-house.”
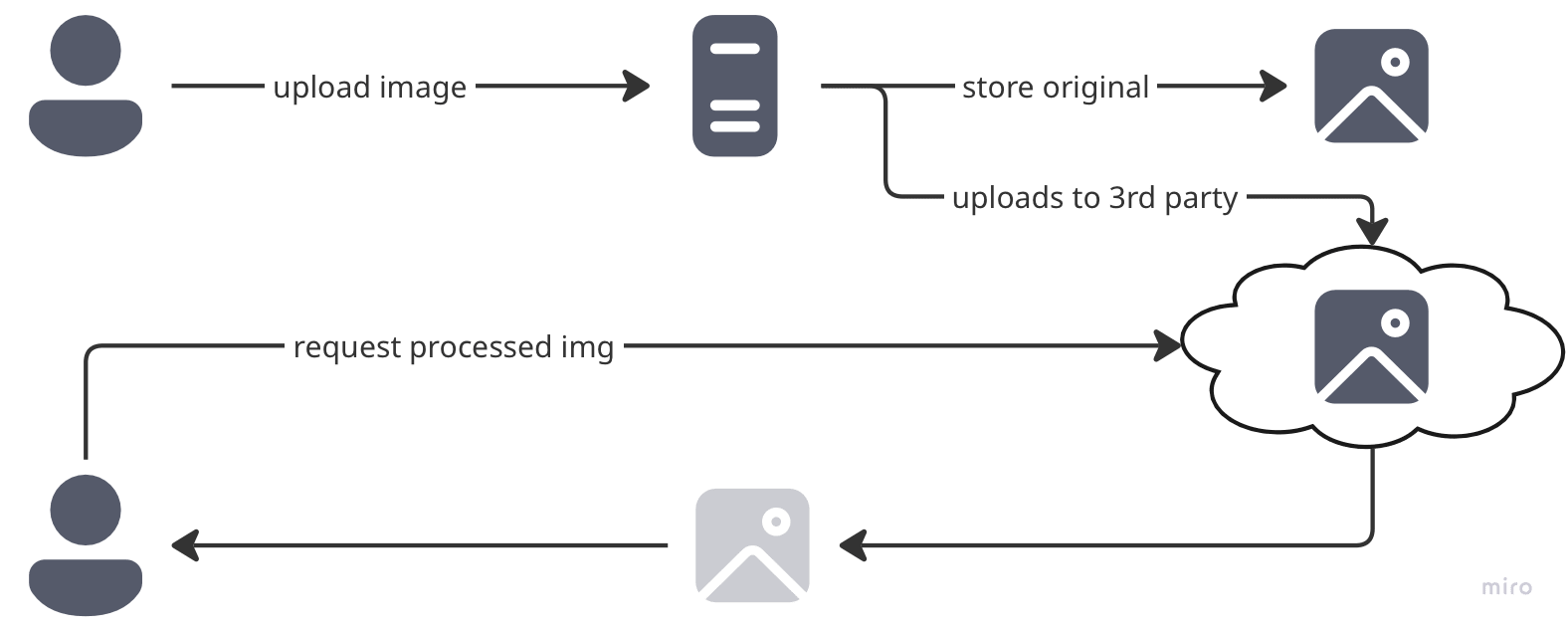
These services handle everything—resizing, format conversion, smart cropping, even AI-powered background removal if you’re feeling fancy. Just change your image URLs to point through their service and boom, problem solved!
But here’s the catch:
The Outage Domino Effect — When their service hiccups (and it will), your entire site turns into a modern art gallery of broken image icons. Your status page now depends on their status page.
The Price — Honestly, I tried to figure it out, but with everything hidden behind ad-hoc, made-up pricing terms, it’s nearly impossible to predict your bill. This article from imgproxy (so they’re both judge and party) might interest you.
Verdict — Great option if you’re fine with handing over all your image handling to a third party and gambling with your infrastructure bill.
Strategy: Let’s give the client the responsibility. It will attempt to get the optimized image directly, and if it fails, will request through the image processing proxy wrapped in a cache proxy.
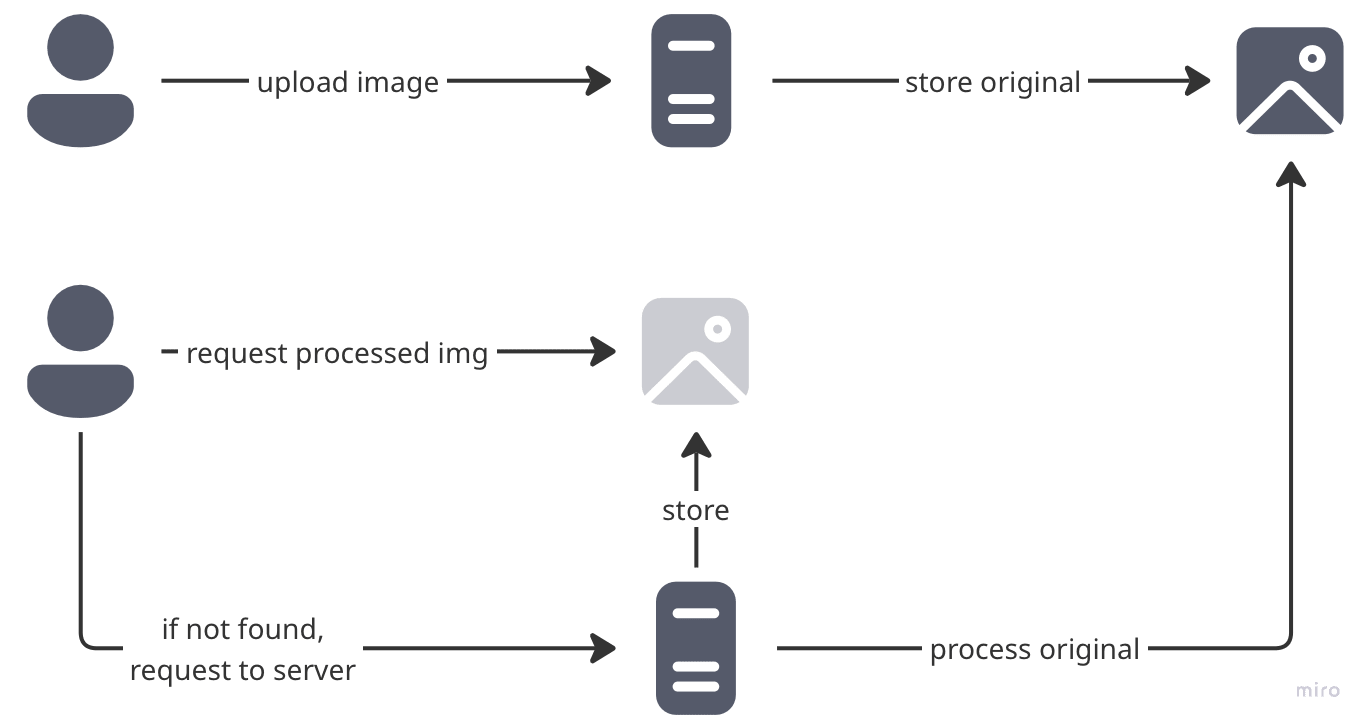
Here’s the most basic flow :
First Attempt: Client tries to fetch the optimized image directly from cache bucket (and if you use a storage like Tigris, you get CDN-like performance out of the box)
Smart Fallback: On 404, client requests through the processing pipeline which will respond with the processed image and asynchronously save it to the cache bucket.
Future Glory: Subsequent clients get the now-cached optimized version directly
a very simple client implementation would be :
<img src="https://processed-image-url" onerror="this.onerror=null; this.src='https://proxy-url/original-image-url';" />Infrastructure Load? What Infrastructure Load?: The majority of requests (cache hits) bypass your processing infrastructure entirely. Only cache misses trigger processing, and that’s exactly how it should be.
Reuse existing infrastructure: You use the same storage technology for your cached images as for the original ones.
Progressive Enhancement: Clients can now implement smarter strategies, ex: try WebP first, fall back to JPEG if the browser is ancient
The Not-So-Good: First-time image loads might be slower (but hey, it only happens once)
I wrote the Imgproxy-cache project to implement this pattern.
It simply adds to the popular ImgProxy docker container a sidecar proxy that writes the processed images to a bucket. Combined with a storage like Tigris we get a CDN-like behavior “for free”.

![Justice for Daniel Naroditsky [video]](https://www.youtube.com/img/desktop/supported_browsers/opera.png)
