.png)

A while ago, our team was working on a Rust project where std::sync::Mutex was everywhere. A team member suggested switching to parking_lot::Mutex instead. They heard that it has better performance, smaller memory footprint, and more predictable behavior under contention.
I had no idea how to evaluate this claim. A quick search online returned results favoring parking_lot. This felt wrong to me. Why? It contradicted my belief that std should be the gold standard. The standard library team knows what they’re doing, right? And if parking_lot’s mutex really was the performance winner, there had to be trade-offs between the two implementations that people weren’t talking about.
That mystery haunted me. I couldn’t just take it on faith. So I jumped down the rabbit hole: read both implementations, wrote the benchmarks, and here we are. In this post, I will:
Explain how std implements the mutex (v1.90.0)
Explain how parking_lot implements their mutex (v0.12.5)
Show you the benchmark with key findings
Give you a decision guide for when to use each
But first, let’s ground our foundation on mutexes (skim it if you’re already familiar).
A classic example of the kind of problem that mutex solves is withdrawing and receiving money at the same time. Imagine you have $100 in your account. Thread A tries to withdraw $80, and Thread B tries to deposit $50. Without proper synchronization, both threads might read the balance as $100 simultaneously, then write back their results independently:
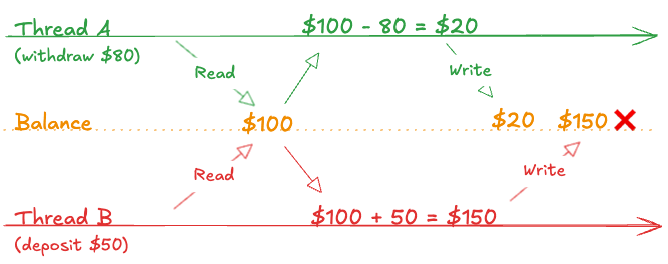
Mutex solves this nicely by having a thread wait until the other finishes its update:
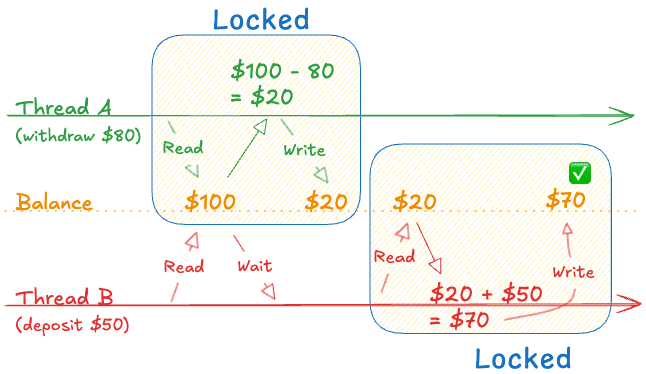
The operations that read and write the balance are what we need to protect - these are called critical sections. Any code that accesses shared data needs to be inside a critical section, guarded by a mutex.
Simple enough, right? Now let’s see how to use a mutex. (Again, skim this if it’s too basic for you)
In languages other than Rust, you typically declare a mutex separately from your data, then manually lock it before entering the critical section and unlock it afterward. Here’s how it looks in C++:
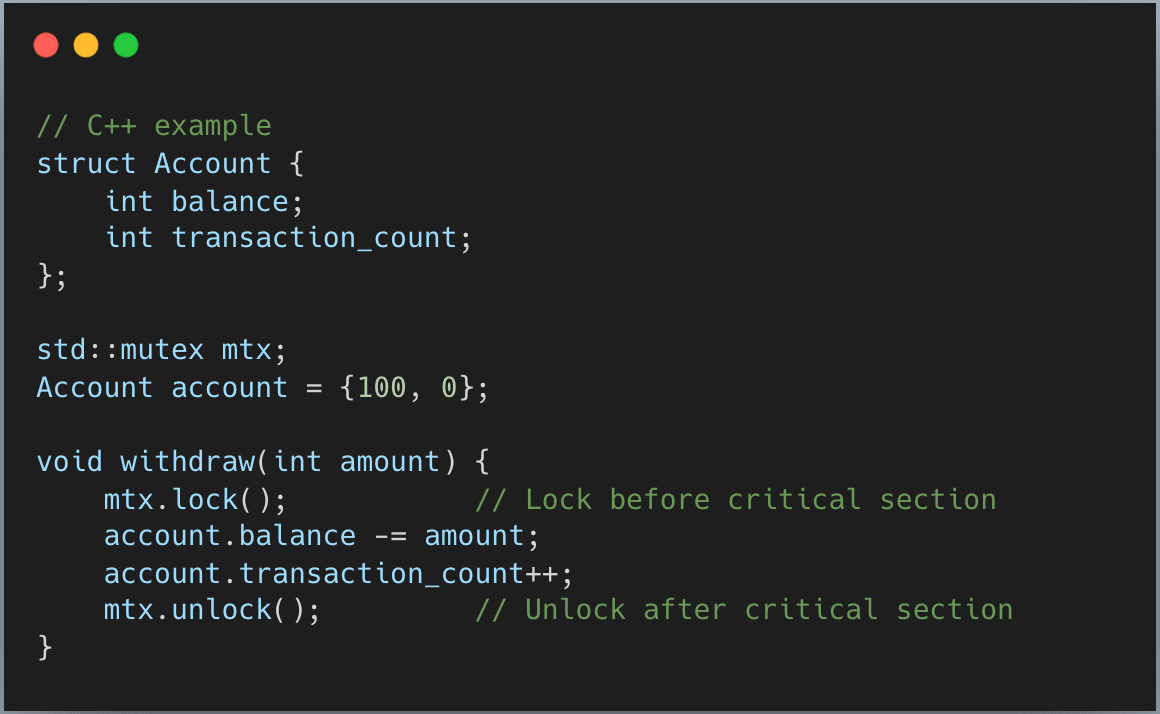
The problem? Nothing stops you from accessing account without locking the mutex first. The compiler won’t catch this bug.
Rust takes a completely different approach - the mutex wraps and owns the data:
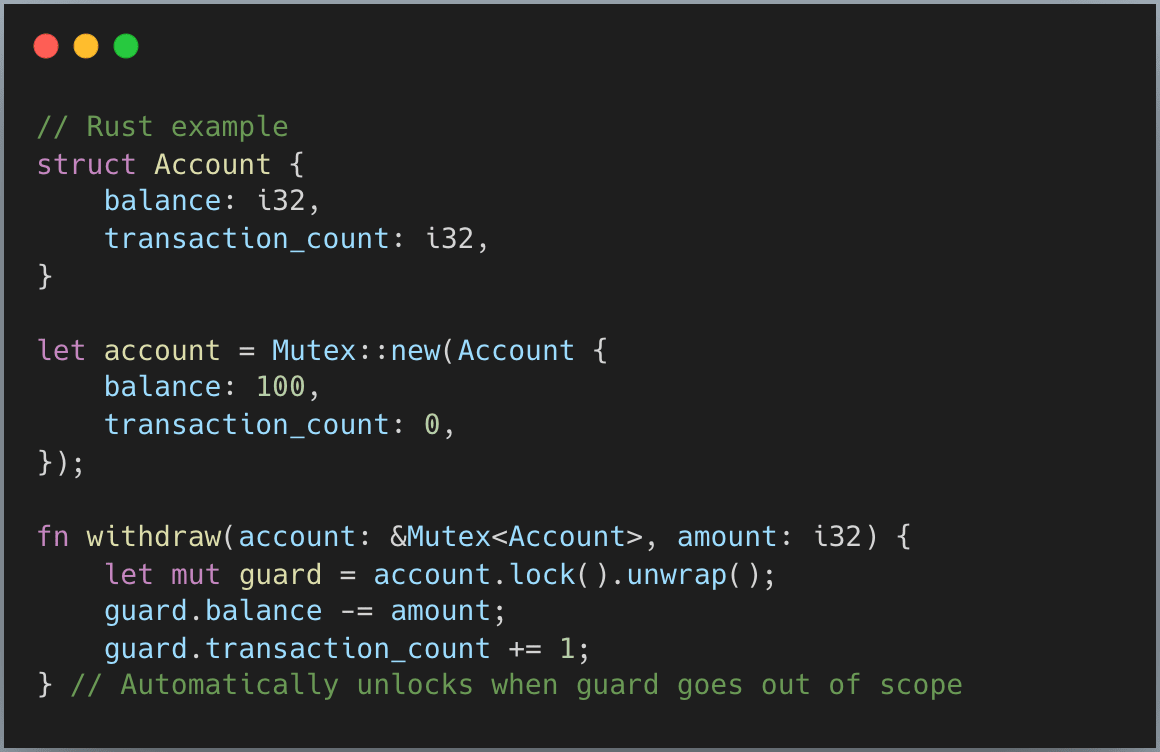
Three things to pay close attention to:
The mutex wraps the data: This makes it impossible to access account without holding the lock. The compiler enforces this.
Automatic unlock: When you lock, you receive a guard. When the guard goes out of scope, it automatically unlocks. No manual cleanup needed.
Lock can fail: Notice the .unwrap() on .lock()? It returns a Result because locking can fail due to poisoning. I’ll explain this shortly.
That’s enough of the basics. Let’s have some fun. Here is how mutex is implemented, starting with Rust std.
A quick look into std::Mutex gives us this
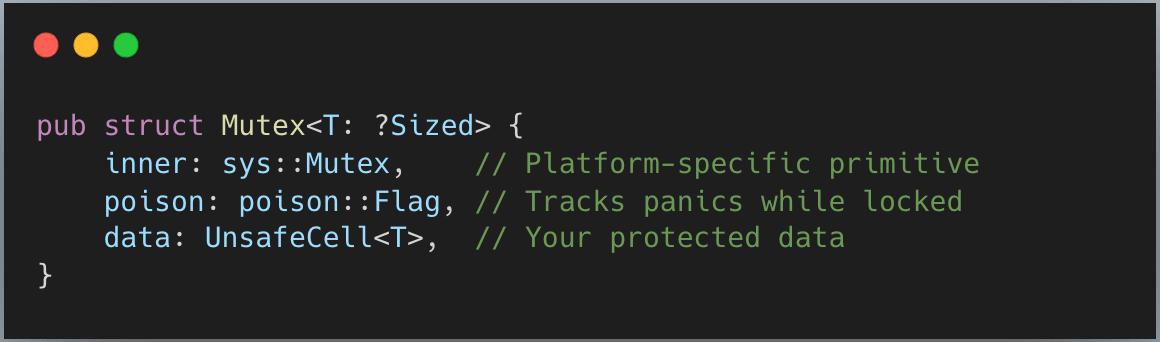
data is the easy part. Since the mutex enforces exclusive access, Rust uses UnsafeCell to give you safe mutable access once it’s locked.
poison is just Atomic<bool> flag to tell if the last thread acquired the lock panic. So, maybe you would want to handle it next time you lock it.
inner is interesting part, let’s look at it next. The code is really long, so I just show a simplified version here
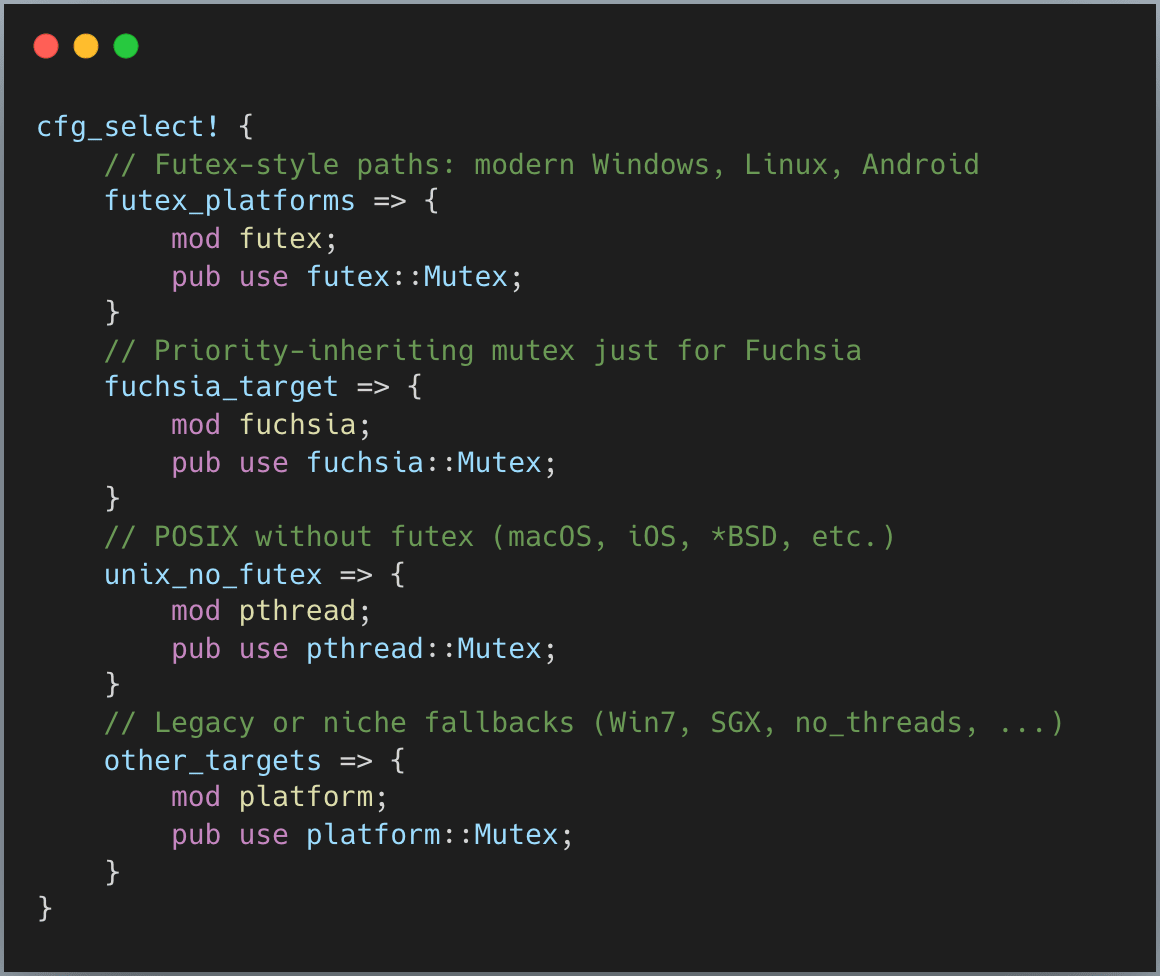
The main idea is that for different OS (and OS version), Rust uses different Mutex implementation. However, we can divide these implementation to 2 big groups: Futex and other platform primitive.
Futex (short for “fast userspace mutex”) is used where the OS kernels expose a “wait on this address” API. We will dive deeper into this one soon.
When that API is missing, Rust falls back to the best available platform traditional locks.
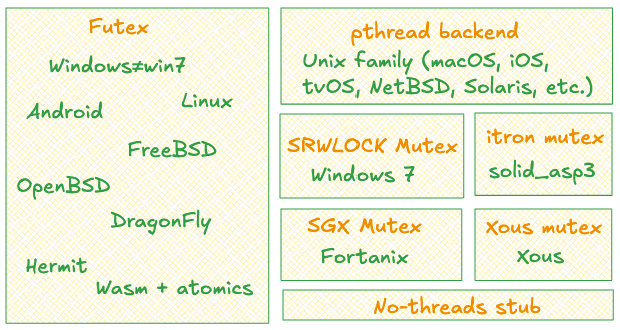
(I’m in awe btw - that’s a lot of different implementations. Writing and maintaining all this platform-specific stuff must be exhausting. Major respect to whoever’s doing this.)
Since Futex is the most used and is quite a typical implementation for Mutex. Let’s look inside it.
At its heart, futex is just an atomic u32 (simplified here):

Atomic type has this powerful operation called “Compare And Swap” (CAS) where the CPU executes it in an atomic call. It works by first comparing the value, if the value equals what is asked for, then it sets the value.
In other words, if we use value 0 for Unlocked state, and 1 for Locked state, we have a simple mutex where the thread can simply try to compare the state to 0 (Unlocked), and set to 1 (Locked). If the state is currently 1, keep doing that until successful.
So, a simplified version of mutex look like this:
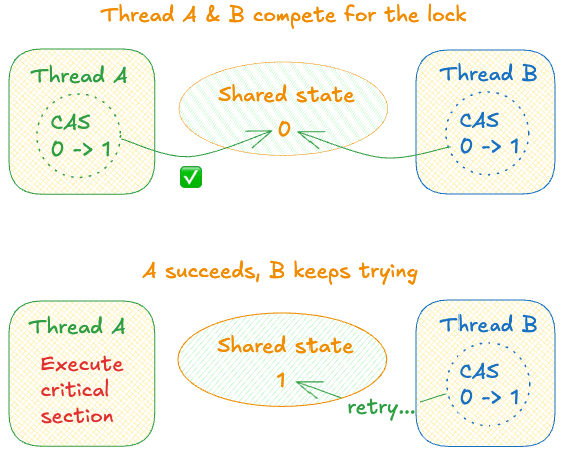
But you might ask: if the first thread holds the lock for a long time, then the second thread needs to keep trying (like a infinite loop)? How about if there are hundreds or thousands of them? Maybe the CPU will soon be burnt.
Of course, there is the solution to this problem. In real implementation, Rust futex has 3 states:
0: Unlocked
1: Locked
2: Contended - locked, but there are waiter.
Notice the Contended state? A thread will try its best to acquire the lock. But if it can’t, it will mark the lock as contended and go to sleep, waiting for the process to wake it up when the mutex is released.
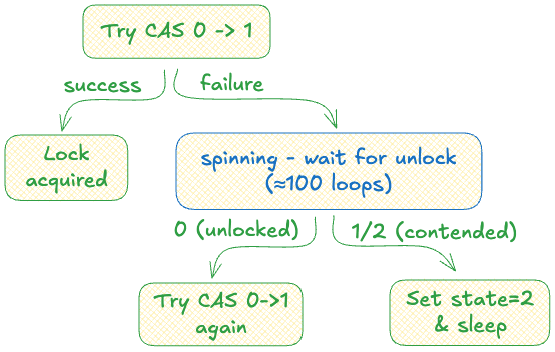
Note: See that spinning part in the diagram? Before a thread goes to sleep, it keeps checking the lock state for about 100 loops - if it becomes unlocked, the thread immediately tries CAS. This avoids the expensive syscall if the lock is released quickly.
What happens when a thread goes to sleep? The kernel helps us put these sleeping threads into a queue. Take a look at the system call on Linux and Android to put the thread into sleeping state (this is usually called “park a thread”):
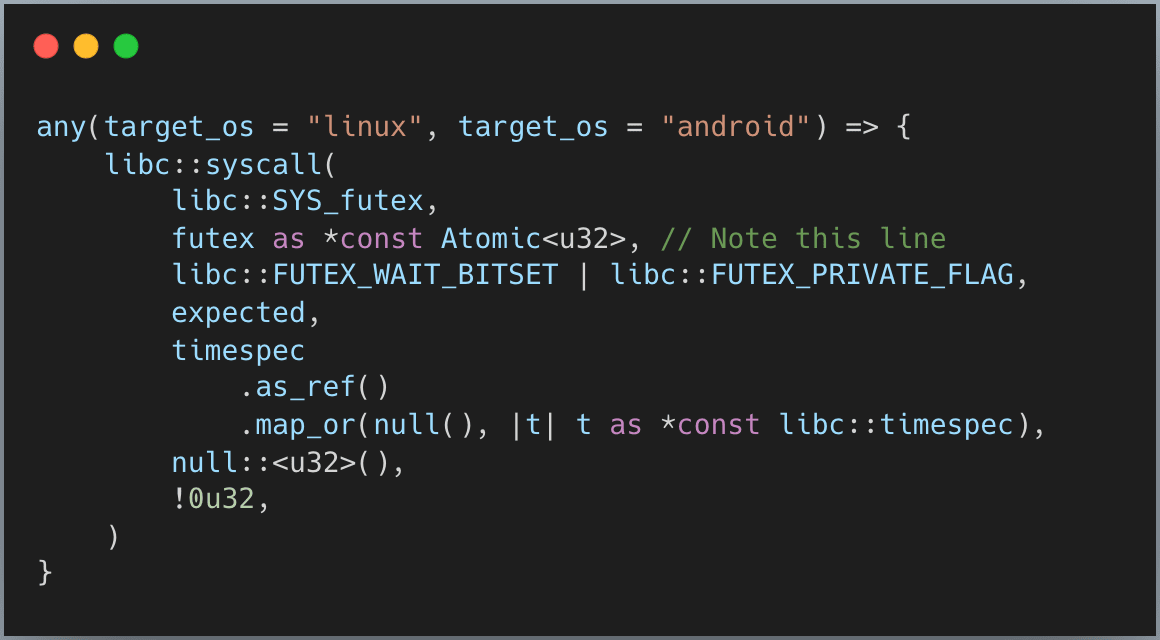
The key part is futex as *const Atomic<u32> - you give the kernel a memory address, and it queues your thread there. Later, when you want to wake a thread, you give the kernel that same address, and it dequeues and wakes a sleeper.
When a thread finishes, it sets the state to unlocked. If the state was contended, it wakes one waiting thread via syscall. This continues until the queue empties.
The final piece of std’s mutex is poisoning, a unique feature you won’t find in most other languages.
One unique feature of Rust’s standard mutex is poisoning. When a thread panics while holding a lock, the mutex becomes “poisoned.” Any subsequent attempts to lock it will return an Err(PoisonError), but you still get the guard inside the error:
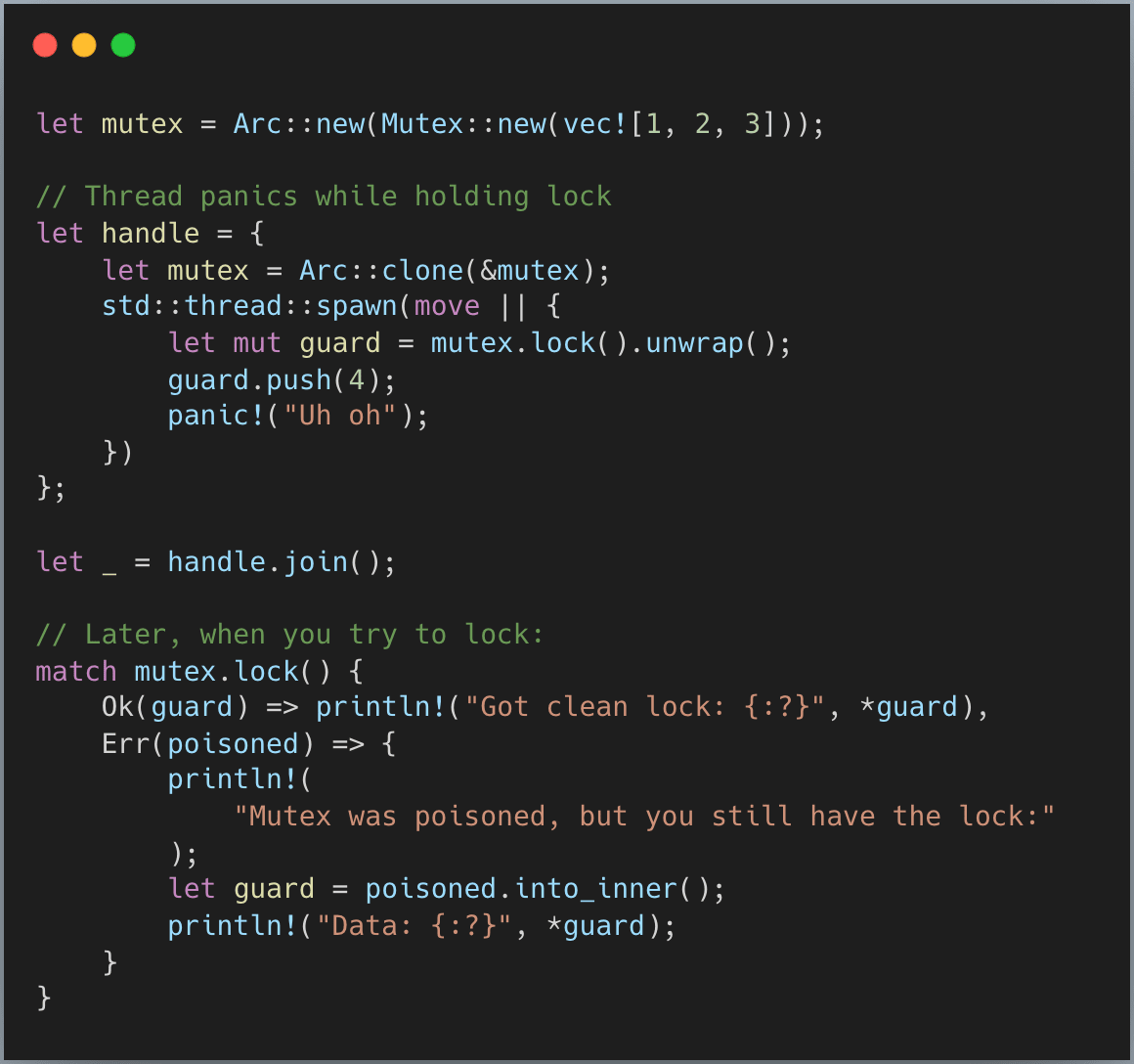
How does poisoning work? Conceptually, it happens in the MutexGuard::drop() path (simplified here for clarity):

The guard captures whether the thread was panicking when the lock was acquired. If we weren’t panicking then but we are now, a panic must have occurred in the critical section. The mutex is marked as poisoned with a simple atomic store.
This is a “best effort” mechanism. It won’t catch all cases (like double panics or non-Rust exceptions), but it provides a useful safety net. The key insight is that you still get access to the data even if the mutex is poisoned, allowing you to inspect and potentially recover from the corrupted state.
Big note: mutex poisoning gets both love and hate. It catches data corruption but feels awkward compared to other languages (Me too, I know it’s helpful. But I still hate it, lol). The Rust team is adding a non-poisoning variant - see issue#134645
parking_lot takes a fundamentally different approach. Two key differences:
std uses different mutex implementations per platform. parking_lot uses one algorithm everywhere, calling platform-specific code only for sleep/wake.
std’s queues live in the kernel. parking_lot manages its own queues in user space via a global hash table.
parking_lot’s mutex is remarkably small:
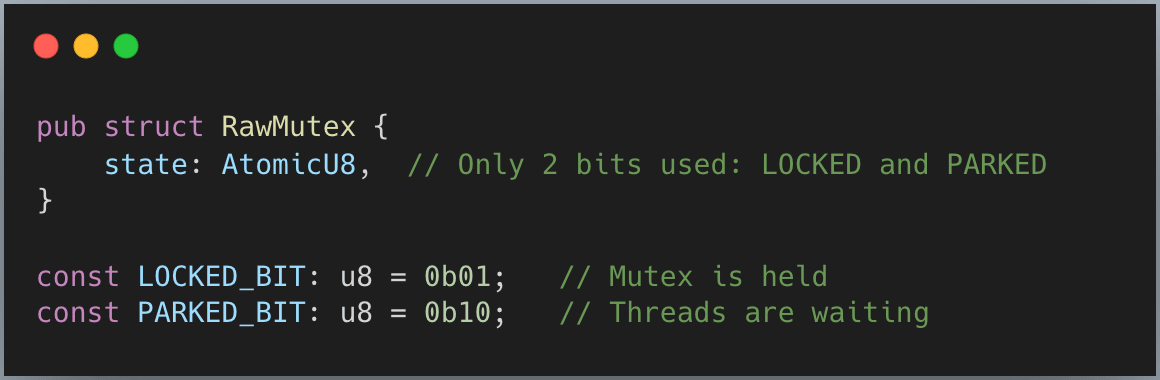
Why can parking_lot use just one byte while std needs more? It comes down to how queues work.
std’s futex uses the kernel to manage wait queues. When you call the futex syscall, you pass the memory address of your atomic variable, and the kernel uses that address as the queue ID. But there’s a catch: the kernel requires this address to be aligned to a 32-bit boundary. So std’s mutex must use AtomicU32, even though it only needs a few bits for state.
parking_lot manages its own queues in user space. It hashes the mutex’s memory address to find the right queue bucket. Since it doesn’t need to satisfy kernel alignment requirements, it can use a single AtomicU8.
More states for queue bookkeeping
Using separate bits gives parking_lot four possible states:
00: Unlocked, no waiters
01: Locked, no waiters
10: Unlocked, but threads still waiting
11: Locked with waiters
That third state (10) might seem odd at first. Why would a mutex be unlocked but still have waiting threads? This is a transient state that happens during parking_lot’s unlock process. Because parking_lot manages its own queue, it uses the PARKED_BIT as bookkeeping to track whether threads are still in the queue. This helps avoid lost wakeups where a thread might miss its notification. It’s not an advantage over std, just a consequence of managing queues in user space rather than delegating to the kernel.
When a thread can’t acquire the lock, it needs somewhere to wait. This is where parking_lot’s global hash table comes in.
Instead of each mutex maintaining its own queue (like kernel futexes do), parking_lot uses a single global hash table shared by all mutexes in your program. When a thread needs to wait:
Hash the mutex’s memory address to find a bucket in the global table
Add the thread to the bucket’s wait queue
Go to sleep
Being able to manage the thread queue itself is important for parking_lot to enforce fairness. As you can see right away in the next section.
Here’s where parking_lot differs from std in behavior. std’s futex uses a “barging” strategy where any active thread can grab the lock when it’s released, even if others have been waiting in the queue longer. This maximizes throughput but can cause starvation.
When a thread unlocks, there are two sources of threads that can lock again:
An active thread that is calling for locking
A sleeping thread in the queue
As you can see, the active thread will tend to win the fight of “who locks first”. So if a thread keeps calling for lock, finishes its work, then locks right away, it keeps all other threads starved.
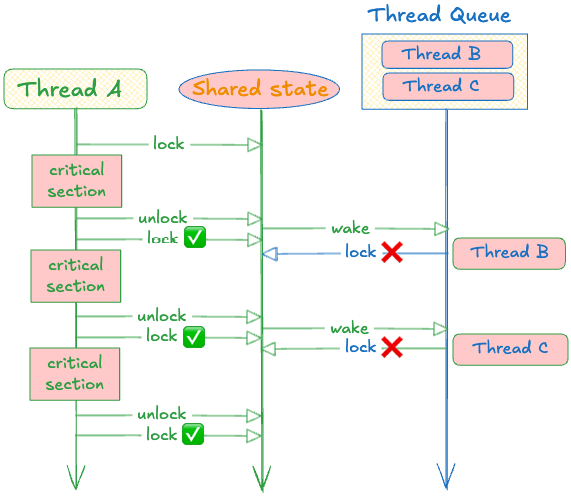
As you can see, thread A keeps grabbing the lock immediately after releasing it. Threads B and C do get woken up by the syscall, but by the time they try to acquire the lock, thread A has already grabbed it again. They’re completely starved.
parking_lot implements “eventual fairness” to prevent this.
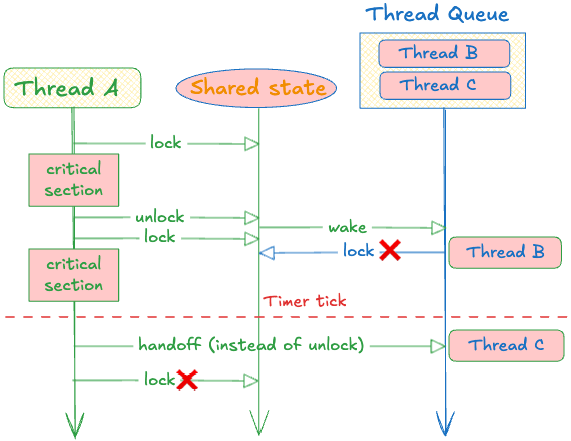
Each bucket in the hash table has a timer that fires approximately every 0.5 milliseconds. When the timer fires, the next unlock becomes a “fair unlock”:
The unlocker keeps the LOCKED_BIT set
The woken thread receives the lock directly (a “handoff”)
That thread owns the lock immediately without racing with other active threads
So this means, instead of letting anyone who is fast grab the lock, parking_lot forces the lock to be given directly to the next one in the queue (it keeps the LOCKED_BIT set and hands off; it doesn’t even unlock).
This timer-based approach means parking_lot is unfair most of the time (for performance), but guarantees fairness every ~0.5ms to prevent any thread from being starved indefinitely. You can also force a fair unlock explicitly with unlock_fair() if needed.
This eventual fairness technique from parking_lot is pretty clever, isn’t it?
Now let’s see how these implementations perform in practice. I ran benchmarks across four scenarios that reveal different aspects of mutex behavior. All benchmarks ran on Linux with the futex backend for std. You can find the source code and full report at https://github.com/cuongleqq/mutex-benches.
For each scenario, you’ll see:
Per-thread operation counts: Shows how many lock acquisitions each thread completed
Performance metrics: Throughput, wait latencies (median, mean, P99), and standard deviation
Analysis: What the results tell us about each mutex’s behavior
(If the numbers feel overwhelming, just read the scenario configuration and skip straight to the takeaway.)
Configuration: 4 threads, 10 seconds, minimal work in critical section
Scenario: This simulates a typical application where threads frequently acquire and release locks with very little work inside the critical section. Each thread simply increments a counter, representing the common case of protecting small data structures or quick state updates.
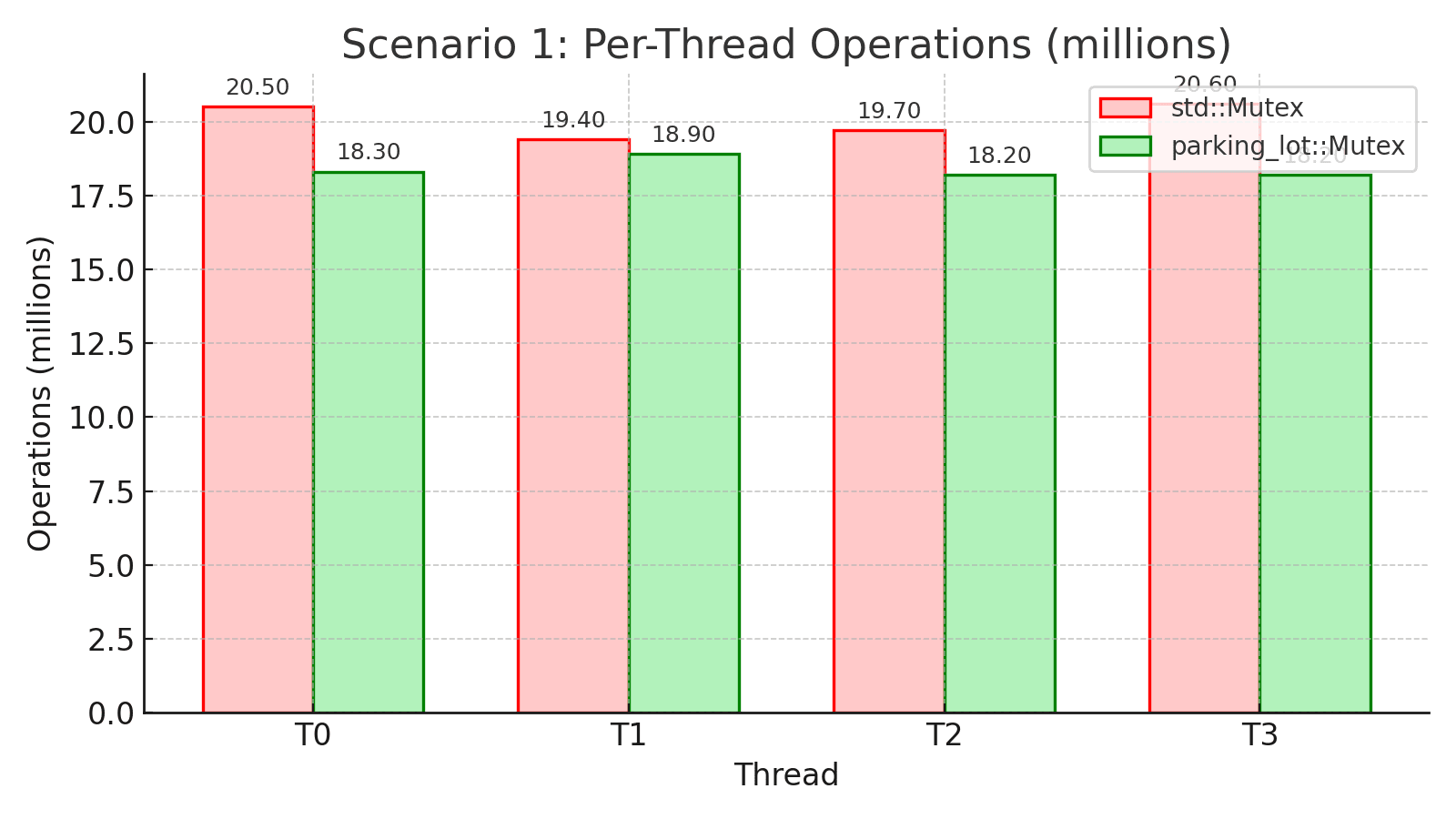
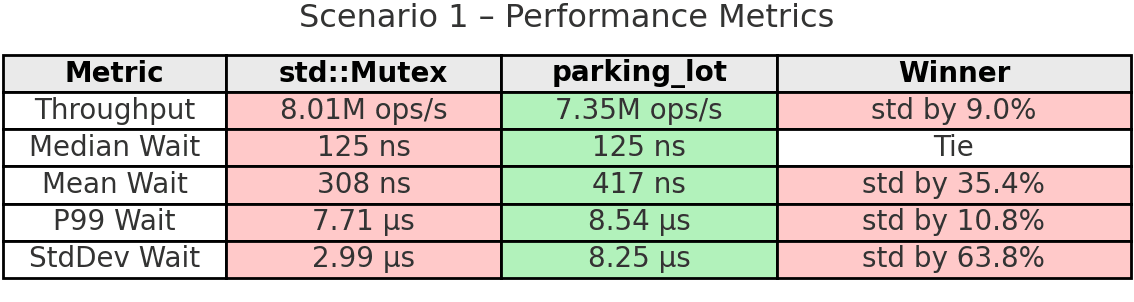
Takeaway: In moderate contention with short critical sections, std’s futex shines with 9% higher throughput and lower average latency. The uncontended fast path and efficient kernel-managed queues work well here. However, look at the per-thread operations: std has 5.6% variation (20.6M vs 19.4M) while parking_lot has only 3.9% (18.9M vs 18.2M). Even in this favorable scenario for std, parking_lot’s fairness mechanism ensures more even work distribution across threads.
Configuration: 8 threads, 10 seconds, 500µs sleep while holding lock
Scenario: This tests heavy contention where threads hold the lock for a long time (500 microseconds). This simulates scenarios like I/O operations, slow computation, or accessing remote resources while holding a lock. With 8 threads competing for a lock that’s held for 500µs each time, contention is severe.
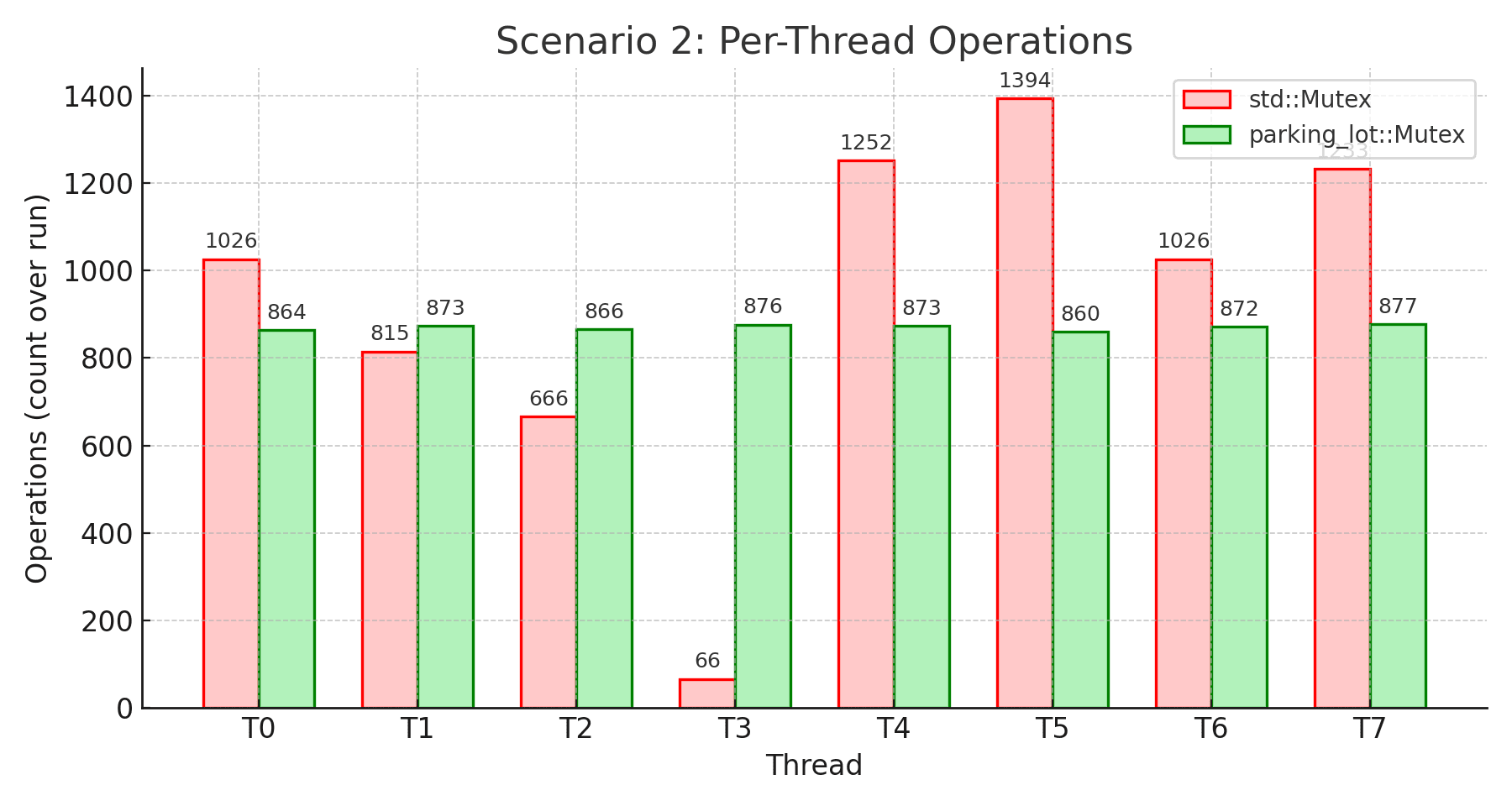
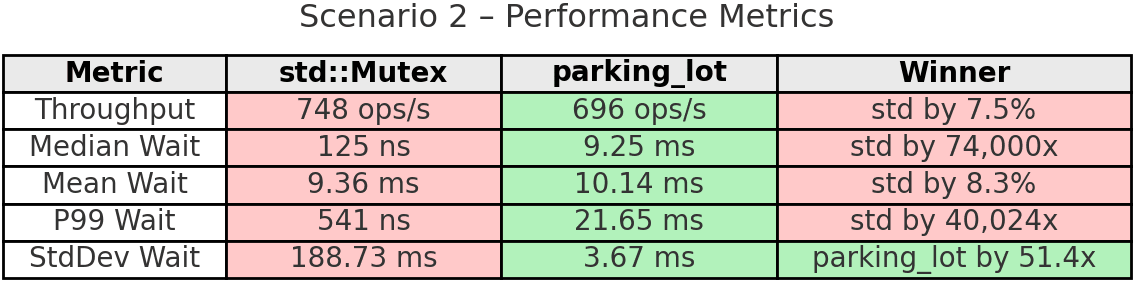
Takeaway: This benchmark reveals std’s critical weakness under heavy contention. Look at thread 3 in std: it completed only 66 operations while thread 5 completed 1,394. That’s a 95.3% variation - complete starvation. The extremely low median (125ns) combined with massive standard deviation (188.73ms) shows most lock attempts are fast, but some threads suffer extreme delays and essentially never get the lock.
parking_lot tells a different story. Every thread completed 860-877 operations (1.9% variation). The fairness mechanism worked exactly as designed. Yes, parking_lot has 7.5% lower throughput and higher median wait time, but that’s because it’s ensuring all threads make progress. The 51x more stable wait times (3.67ms vs 188.73ms standard deviation) show the predictability benefit. When fairness matters, parking_lot prevents the pathological starvation that std exhibits.
Configuration: 8 threads, 15 seconds, 200ms active / 800ms idle
Scenario: This simulates bursty workloads where threads alternate between periods of high activity (200ms of rapid lock acquisitions) and idle periods (800ms sleep). Think of web servers handling traffic spikes, batch processing systems, or applications with periodic activity patterns. This tests how mutexes handle sudden contention spikes followed by quiet periods.
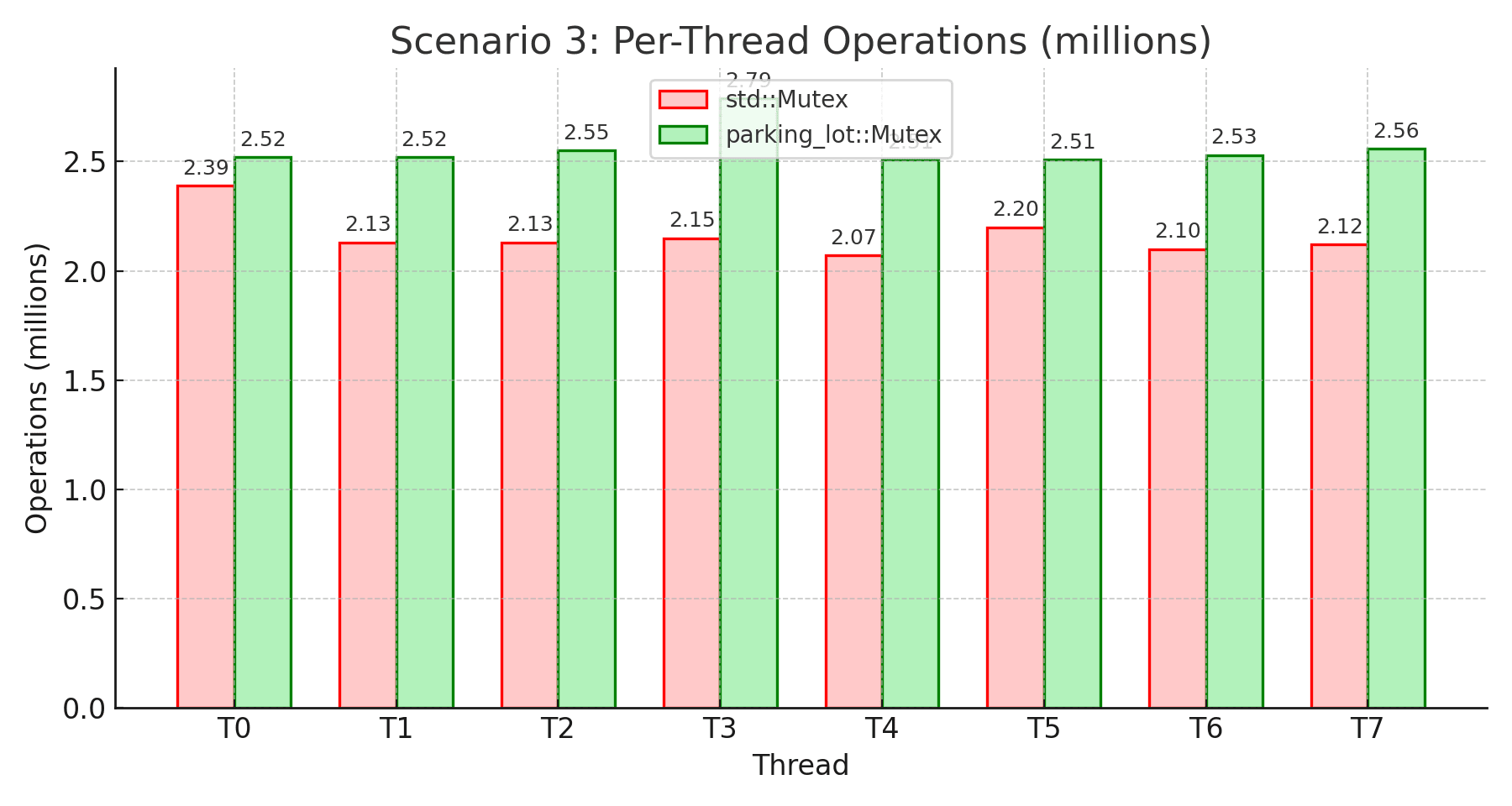
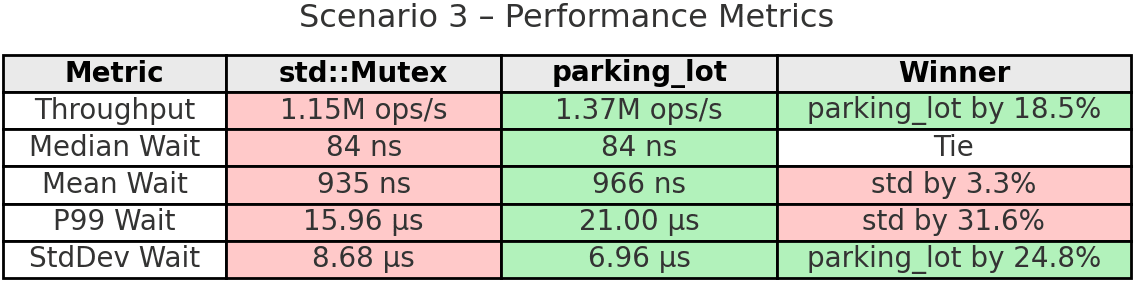
Takeaway: parking_lot excels in bursty workloads, achieving 18.5% higher throughput than std. During activity bursts, all 8 threads compete intensely for the lock. parking_lot’s adaptive spinning and fairness mechanisms handle these periodic spikes better, ensuring more even work distribution (9.9% variation vs 13.6%). The 24.8% more stable wait times show parking_lot handles the transitions between idle and active periods more smoothly. While std has lower tail latencies, parking_lot’s better stability and fairness during bursts translate to higher overall throughput.
Configuration: 6 threads, 15 seconds, one thread monopolizes (sleeps 500µs while holding lock)
Scenario: This tests the worst-case scenario: one “hog” thread repeatedly acquires the lock and holds it for 500µs, while 5 other threads compete normally. This simulates real-world situations like priority inversion, where a high-priority or busy thread keeps grabbing the lock immediately after releasing it, potentially starving other threads. Can the mutex prevent monopolization?
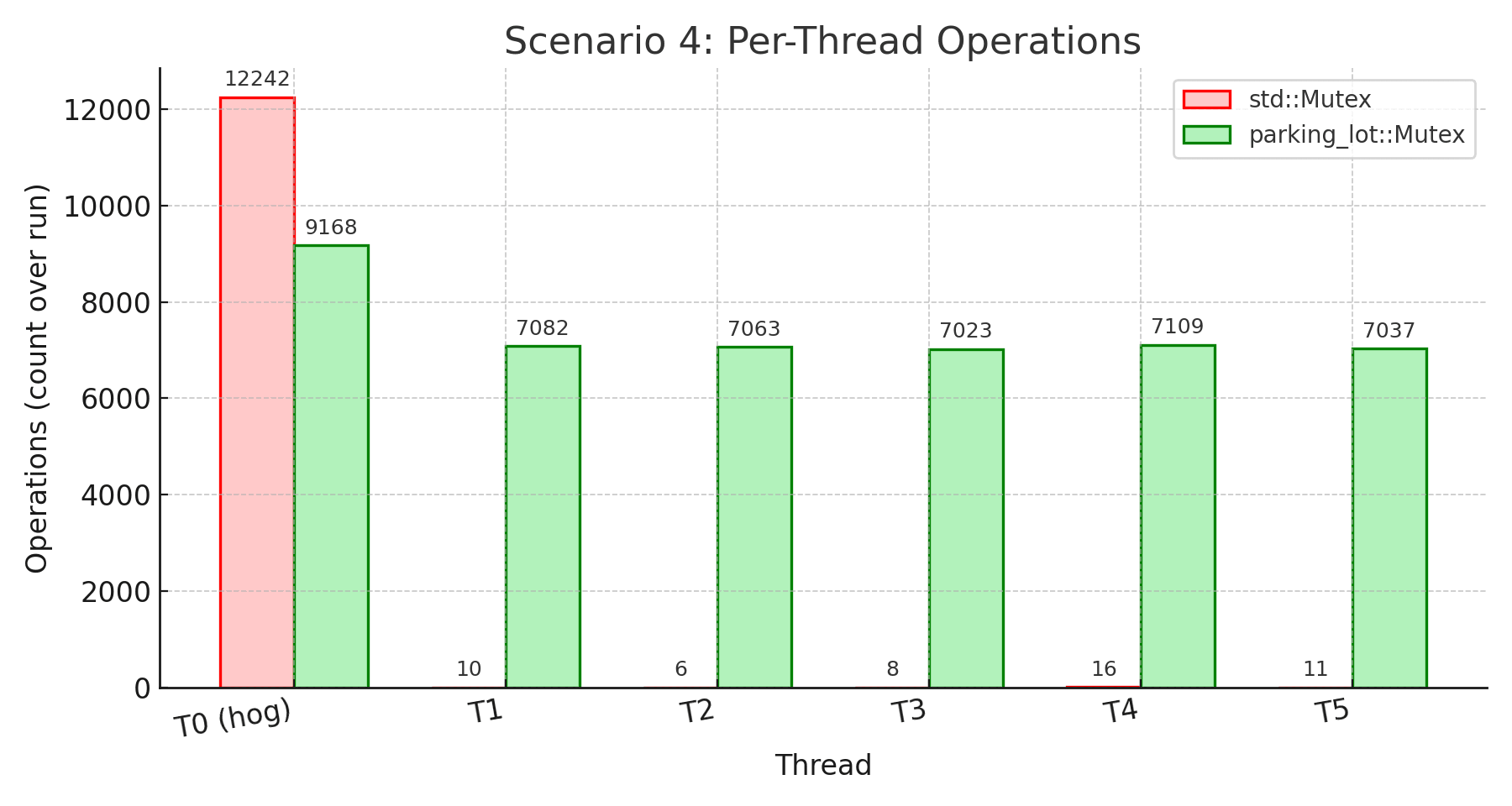
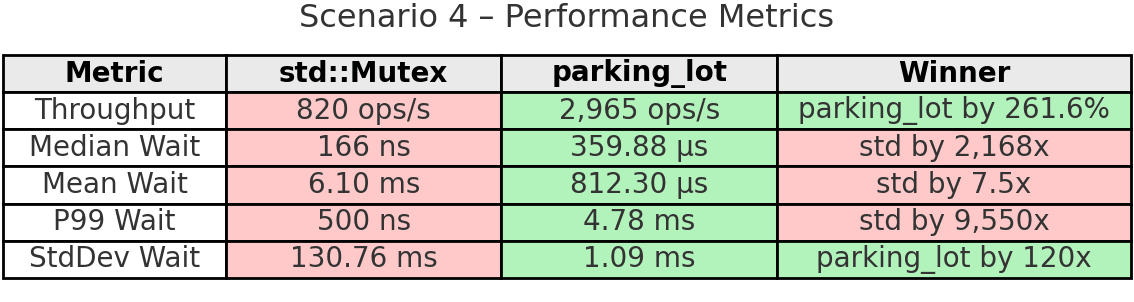
Takeaway: This is the smoking gun that demonstrates std’s fundamental unfairness. The hog thread completed 12,242 operations while the other threads completed only 6-16 operations each. That’s complete starvation - the non-hog threads essentially never got the lock. The 100% variation and 130ms standard deviation show the extreme unpredictability.
parking_lot’s fairness timer prevented this catastrophe. The hog still got more operations (9,168) but nowhere near monopolization. All other threads made meaningful progress (7,023-7,109 operations). The result: 261.6% higher overall throughput because all 6 threads contributed work instead of 5 threads sitting idle. The 120x more stable wait times (1.09ms vs 130.76ms) show parking_lot’s predictability. The 0.5ms fairness timer does exactly what it promises: prevent any thread from monopolizing the lock indefinitely.
After diving deep into the implementations and running comprehensive benchmarks, here’s when to use each:
You need zero dependencies - It’s in std, always available
Low to moderate contention with short critical sections - futex implementation is excellent here (9% faster throughput in our short-hold test)
You want poisoning for debugging - Helps catch panic-related bugs during development
Platform-specific optimizations matter - Gets priority inheritance on Fuchsia, etc.
Fairness is critical - Prevents thread starvation (49x better fairness in heavy contention)
Risk of monopolization exists - The hog scenario showed 261.6% better throughput by preventing starvation
Bursty workloads - 18.5% faster in our burst scenario
You need predictable behavior - 51x more stable latency under heavy load
Memory footprint matters - Always 1 byte regardless of platform
You want timeouts or fairness control - try_lock_for(), unlock_fair(), etc.
Cross-platform consistency is important - Same behavior everywhere
The benchmarks reveal a fundamental trade-off: std::Mutex optimizes for throughput in the average case, while parking_lot::Mutex optimizes for fairness and predictability in the worst case.
For most applications, where contention is light and critical sections are short, std::Mutex performs excellently. But if your application has any of these characteristics:
Long-running critical sections
Risk of lock monopolization (e.g., one high-priority thread)
Need for predictable latency across all threads
Requirement that all threads make forward progress
Then parking_lot::Mutex’s eventual fairness mechanism becomes invaluable. The 0.5ms fairness timer is a small price to pay for preventing complete thread starvation.
If you made it this far, you’re probably as obsessed with understanding how things really work as I am. I’m Cuong, and I write about Rust and programming. If you share the same passion, I’d love to connect with you. Feel free to reach out on X, LinkedIn, or subscribe to my blog (substack, medium) to keep pushing the boundaries together!



