.png)

Are your cloud bills spiraling out of control? You're not alone. 84% of organizations struggle to manage their cloud spend1. 69% of IT organizations experience budget overruns2. A whopping 28% of cloud spending is wasted annually, and an astonishing 70% of companies are unsure about their exact spend on cloud3.
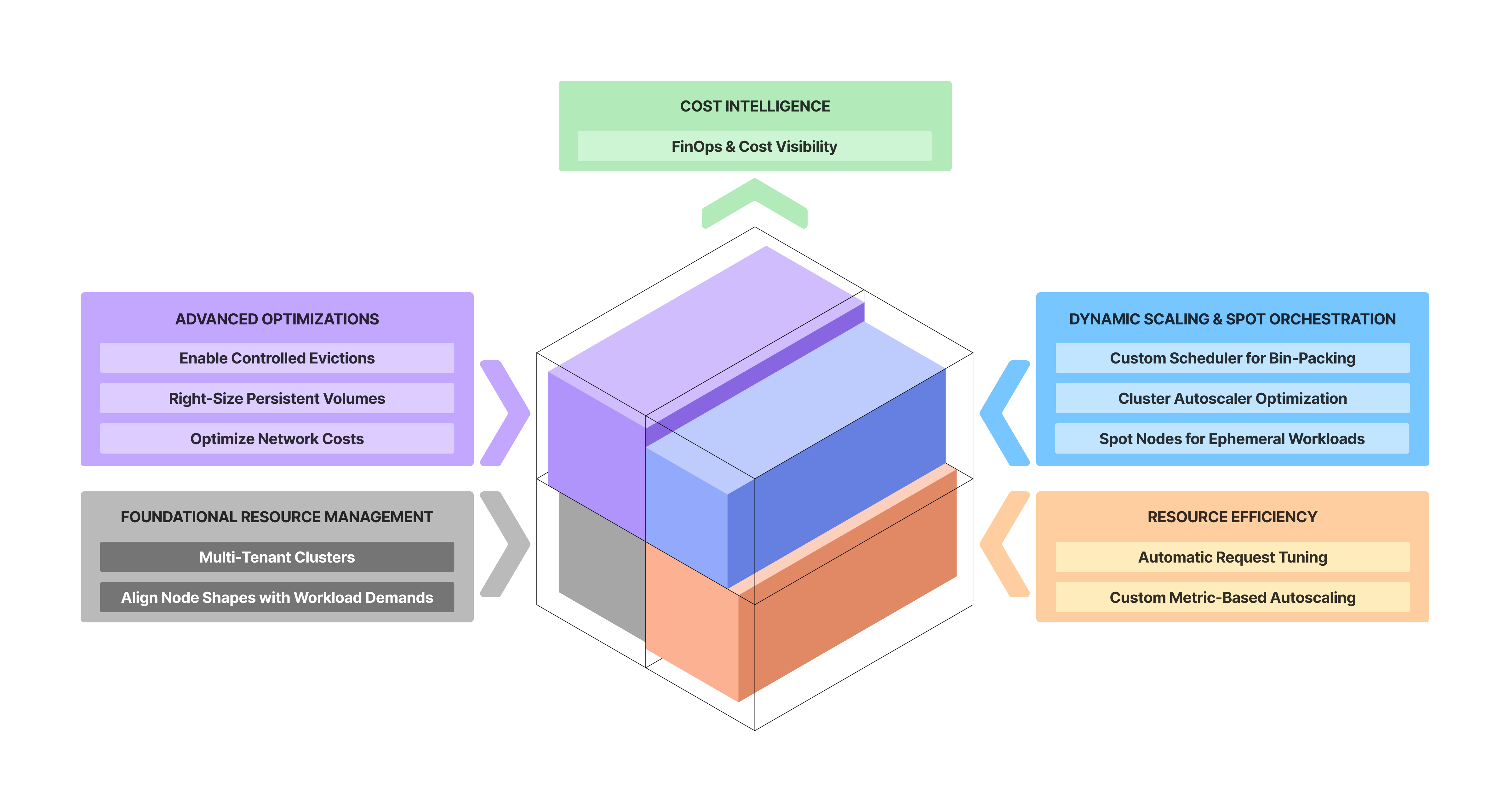
As infrastructure scales, cloud compute costs can quickly snowball, especially when operating 100s of Kubernetes clusters. In this blog we will lay out 11 actionable strategies to improve compute utilization on Kubernetes.
Keep these principles in mind as you craft your own cost optimization blueprint:
There's no single magic bullet. Optimizing costs extends beyond implementing clever technical solutions; it demands understanding and navigating the nuances and operational realities of your applications and underlying infrastructure.
You can't optimize what you don't see. Before you can effectively control costs, you must be able to accurately measure and attribute where your money is going. Optimization efforts are merely guesswork without visibility
High utilization doesn’t always equal low cost. Don’t fall for the illusion of high utilization. Ultimately, cost should remain the overarching measure of success for any optimization effort.
Optimization vs. reliability is a delicate dance. Overly aggressive cost optimization will compromise system stability and performance. Balance with reliability indicators while only eliminating true waste.
Shift Left by building cost consciousness. Cost optimization isn’t solely the responsibility of a central FinOps or platform team. Foster a culture where developers are empowered with cost insights and tools to operate efficient applications.
Architect for efficiency early. While it’s wise to avoid premature optimization on unconfirmed needs, foundational architecture choices like multi-tenant clusters, or planning data residency, have long-term impact on your cloud spend.
Kubernetes workloads often autoscale and are distributed across diverse node types, especially in shared multi-tenant clusters. This obscures compute cost origins, prevents identifying inefficiencies, and assigning accountability of resources to specific teams or applications. Cloud providers usually have built in cost dashboards, but only provide visibility only at the VM or node level and lack attribution at the application level,
Solution: Adopt cost visibility and attribution for your platform. For simpler deployments, off-the-shelf tools like OpenCost provide real-time cost allocation by pod, label, namespace, and service, capturing price signals for CPU-seconds, memory bytes, storage IOPS, network egress, etc. For complex, multi-cloud, or customized platforms, consider developing an in-house attribution system by aggregating utilization metrics and reconciling them with cloud provider billing data.
Pitfalls to avoid:
Delayed Adoption: Cost visibility is frequently an afterthought. The painful result? Substantial, untraceable waste.
Umbrella Cost Models: This rarely works for shared resources (databases, metrics, blog storage, etc.) due to unclear ownership. Define a clear cost model that allocates shared resource costs based on usage or pre-defined criteria to teams or applications.
Lack of Governance: Without continuous audits and automated alerts, optimization efforts can easily regress. Implement regular review processes to flag anomalies based on projected modeling.
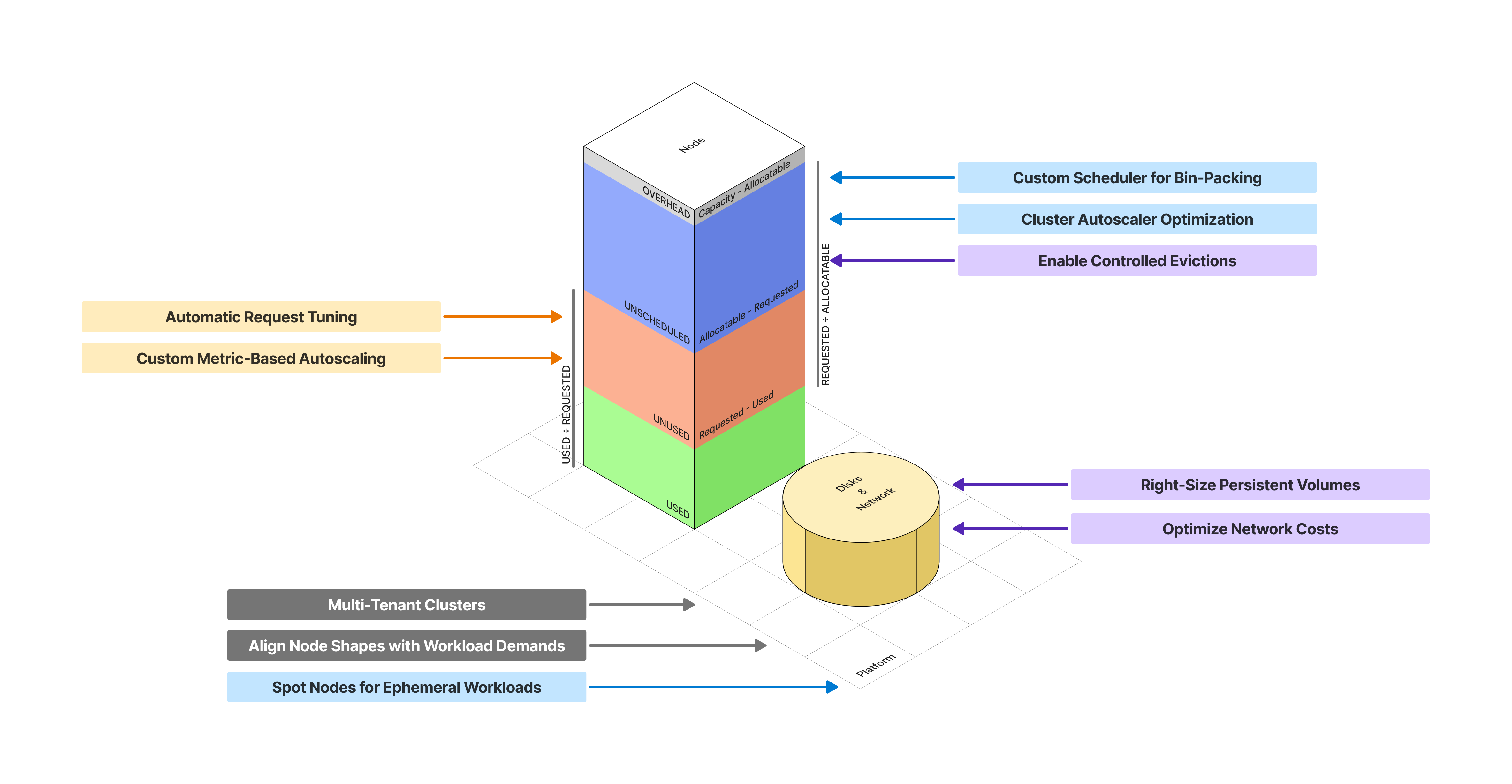
The default Kubernetes scheduler distributes workloads uniformly across nodes. This leads to persistent overprovisioning resulting in unused capacity across multiple nodes and sparse bin-packing.
Solution: Configure a custom Kubernetes scheduler to favor tighter bin-packing using MostAllocated or RequestedToCapacityRatio scoring strategies. This fills existing nodes more completely before provisioning new ones, boosting resource utilization. Combine with cost-aware scheduling (e.g. prioritize cheaper node types) when multiple node pools are involved.
Pitfalls to avoid:
Scheduler Unavailability: The self-managed custom scheduler can become unavailable and lead to pending pods. Design for high availability and consider using it in conjunction with the default scheduler with fail-open mechanics.
Pods per node limits: Cloud providers’ max-pods-per-node limits on larger node instance types can restrict how tightly you can bin-pack pods on them. Carefully plan for use of larger instance types, or use a combination of large and small nodes.
Default Cluster Autoscaler (CA) settings like --scale-down-utilization-threshold of 0.5 (50% node utilization) and --scale-down-unneeded-time of 10 minutes, lead to slow scale-down operations. In dynamic platforms, this conservative behavior results in nodes lingering longer than necessary translating into unnecessary costs.
Solution: Configure CA to more aggressively consolidate nodes by increasing --scale-down-utilization-threshold to a higher value (e.g. 0.7 to scale down nodes when utilization falls below 70%), and decreasing --scale-down-unneeded-time (e.g. to 5 minutes) to consolidate nodes faster. Combine this with appropriate CA expander strategies (e.g., priority, least-waste, spot-instance) to optimize node selection when multiple node pools are involved. This strategy works with CA alternatives like Karpenter as well.
Pitfalls to avoid:
Scaling Oscillation or Thrashing: Overly aggressive scale-down can lead to nodes being removed then immediately added back. This is wasteful as most cloud providers price nodes per hour. Balance stability by fine-tuning scale-down delays timers like --scale-down-delay-after-add and --scale-down-delay-after-delete.
Anti-affinity Rules: Pods with anti-affinity or topology spread constraint can block node scale-down and remove underutilized nodes. Use multi-tenant clusters to alleviate this.
Workloads Blocking Eviction: Workloads configured with PodDisruptionBudgets (PDBs) set to 0 or annotations like safe-to-evict: false explicitly block node scale-down by preventing pods from being drained from a node.
Short-lived ephemeral workloads like analytics pipelines, batch jobs, data ingestion agents, etc. frequently spin-up and spin-down. This prevents Cluster Autoscaler from scaling down nodes. Running these workloads on on-demand nodes doesn’t make financial sense.
Solution: Schedule ephemeral workloads onto spot nodes. Spot nodes are significantly cheaper (at least 60% cheaper on all AWS EKS, GCP GKE and Azure AKS) than on-demand instances. Also use spot nodes for non-business-critical workloads where occasional interruptions are acceptable.
Pitfalls to avoid:
Sudden Eviction: Cloud providers reclaim spot nodes with short notice (e.g., 30 seconds on Microsoft Azure). Ensure workloads are fault tolerant and can withstand abrupt termination.
Non-Standard Shutdowns: Some cloud providers may not follow standard Kubernetes shutdown processes (e.g., sending SIGTERM). See this blog that describes hardening spot nodes with custom tooling.
Spot Capacity Shortages: Spot availability fluctuates. Derisk by diversifying your spot instance types. Combine with a baseline of on-demand instances for stability, allowing workloads to spill over to on-demand nodes only when spot capacity is unavailable. Configure Cluster Autoscaler expander to prioritize scaling up spot nodes before others.
Manually configuring CPU and memory requests and limits for pods is inefficient. Developers often err on the side of overprovisioning, driven by concerns about performance, stability, and the potential impact of noisy neighbors. Furthermore, initial resource requests are rarely audited or adjusted over time as application needs evolve. This leads to wasted resources.
Solution: Automate resource request setting and tuning. Continuously monitor actual workload usage and dynamically adjust requests and limits to match consumption patterns. Kubernetes Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) cannot be used in conjunction. But you can leverage VPA recommendations to tune requests alongside HPA, paired with cool-off logic to prevent thrashing. Note that newer Kubernetes versions support VPA in initial mode where it assigns resource requests on pod creation and never changes them later.
Pitfalls to avoid:
Phased Rollout and Escape Hatches: Implement with a fail-open approach and provide clear escape hatches for developers to temporarily disable or override automation for specific workloads during critical issues.
Developer Control and Trust: For platforms with hundreds of microservices foster trust by providing dashboards with tuning recommendations.
Resource Use Profiles: Craft tuning profiles (e.g. guaranteed, burstable, etc.) to cater to diverse workload consumption patterns and criticality.
Application of Scaled-Down Requests: If tuned down requests are applied only at deploy time, it can confuse developers troubleshooting new changes. Implement safe, programmatic restarts that attribute changes clearly.
HPA natively supports scaling based on CPU and memory utilization. However, this is insufficient for applications with scaling needs reflected best in business or application-level metrics like requests per second, queue depth, active connections, etc. Scaling solely on CPU or memory can cause instability and failures, leading to reliability concerns. Consequently, teams often overprovision to handle peak loads.
Solution: Enable custom metric-based autoscaling. Deploy a custom metrics adapter (e.g. Prometheus Adapter) that exposes metrics from your monitoring system to the Kubernetes Custom Metrics API (custom.metrics.k8s.io). Alternatively, KEDA provides flexible, event-driven autoscaling with built-in “scalers” for various event sources (message queues, databases, cloud services), including the ability to scale down to zero pods.
Pitfalls to avoid:
Metrics Infrastructure Reliability: Scaling behavior is tied to metrics pipeline’s availability, and can lead to incorrect scaling decisions. Ensure high reliability for your metrics infrastructure.
Metric Accuracy: Inaccurate metrics can lead to undesirable scaling behavior (e.g., thrashing or flapping).
Single Custom Metrics Server Limitation: Historically, Kubernetes environments only supported one custom metrics server. Carefully plan your metrics ecosystem.
Failure Modes and Defaults: Design for failure modes. Implement sane default replica counts or fallbacks to ensure application stability during metric outages.
It is common to provision single-tenant Kubernetes clusters per team or application when starting off. This approach, driven by a perceived need for strict isolation or sometimes developer insistence, is a classic recipe for overprovisioning.
Solution: Transition to a multi-tenant cluster architecture. Kubernetes offers robust controls for diverse workloads to coexist securely and efficiently on shared hardware:
Namespaces: Logical tenant isolation within a cluster.
Resource Requests and Limits: Manage pod resource consumption, preventing individual workloads from monopolizing resources.
Resource Quotas and LimitRanges: Enforce aggregate resource consumption per namespace.
Role-Based Access Control (RBAC): Restrict tenant access to only their designated namespaces, ensuring API isolation.
Network Policies: Providing network isolation by controlling inter-pod communication across namespaces.
Pod Security Standards (PSS) or Security Contexts: Enforce security hygiene and prevent privilege escalation.
Pitfalls to avoid:
"Noisy Neighbor" Phenomenon: Workloads can still spike CPU or memory usage, impacting applications co-located on nodes. Applications that constantly exceed their requests are problematic as Kubernetes schedules by resource requests not real-time use.
Network and Disk I/O Bottlenecks: Kubernetes doesn’t currently allow specifying network and disk I/O requests. I/O intensive applications can starve colocated workloads of shared bandwidth on nodes. Implement monitoring and consider pod anti-affinity or topology spread constraints.
Discrepancies between node CPU:memory ratios and that of workload consumption lead to resource imbalances. For example, memory-intensive workloads on high CPU:memory nodes can underutilize CPU while bottlenecking memory. This leads to more nodes than actually required.
Solution: Migrate each node pool to node shapes that closes the gap between CPU and memory efficiency. To do so, adjust your node instance types’ CPU:memory ratio to align with aggregate workload consumption, Σ(CPU Used):Σ(memory Used). This will reduce overall compute costs. You can easily use an off-the-shelf tool like Karpenter to automate this.
Pitfalls to avoid:
In-place Node Type Changes: Node instance types cannot be changed in place. Build custom tooling to orchestrate node pool replacement without disrupting workloads. See this blog for a highly automated way of replacing a node pool.
Premature Optimization: Best executed after workloads are right-sized. Optimizing node shape before workload rightsizing is ineffective as the CPU and memory efficiency will change later, requiring replacing node instance type again.
System Overhead: Kubernetes components (kubelet, kube-proxy, container runtime) consume a portion of node resources. Account for this overhead when evaluating available CPU and memory, especially on smaller nodes.
Workloads with PodDisruptionBudgets (PDBs) set to 0 or safe-to-evict: false annotations block Cluster Autoscaler node scale-down operations. These configurations are common for singletons or critical workloads, and are problematic in multi-tenant platforms.
Solution: Instate policies to disallow PDB set to 0 and safe-to-evict: false annotations. For most cases, proper application architecture hygiene (handling SIGTERM, setting terminationGracePeriodSeconds) suffices. For complex workloads, build custom tooling to orchestrate graceful workload eviction by exposing a pre-shutdown hook. For example, in stateful applications like CockroachDB this may execute steps like draining connections, committing transactions, or backing up data.
Pitfalls to avoid:
Long-Running Jobs: Long-running workloads, like Apache Flink, with significant internal state, may not recover gracefully from disruptions. Restarts are costly due to re-processing or extended execution times. Isolate such workloads onto a dedicated node pool or cluster. Newer versions of Flink may support checkpointing (or similar specialized recovery mechanisms).
Cost of Exceptions: Strictly control non-evictable workloads by isolating them onto dedicated node pools or clusters. This simplifies cost accounting for these exceptions and prevents impacting overall cluster efficiency.
Persistent storage costs in Kubernetes can accumulate rapidly when using cloud managed Persistent Volumes (PVs). Without active management, teams default to expensive storage classes, over-provision volume sizes, or leave unused volumes lingering, leading to accumulating costs.
Solution: Continuously monitor storage consumption. Cloud managed disks are easy to size up as needed, so always start with the smallest possible volume. Encourage the use of different StorageClass definitions exposing various cloud storage types based on workload performance needs. For large-scale complex platforms, consider building custom tooling to dynamically resize PVs to align with actual usage.
Pitfalls to avoid:
Accidental Data Loss: Implement backup and retention strategies to avoid accidental data loss from aggressive deletion policies, or when resizing.
Unused or Orphaned Volumes: Unused volumes often liner after application decommissioning or even from incomplete pod evictions sometimes. Automate identifying and deleting unused or orphaned PVCs and their underlying PVs.
Network costs can become an unexpected line item in cloud bills, because cloud providers charge for all ingress and egress traffic, cross-region data transfer, load balancers, gateways, etc. A multi-region Kubernetes architecture built for resilience can come at an exorbitant price. Applications with high data transfer or public-facing services can rapidly accumulate network charges too.
Solution: Minimize cross-region and inter-zone traffic by carefully architecting your data residency. For example, prohibit stateless services from direct cross-region data access. Prefer internal Load Balancers, Ingress Controllers, and private endpoints for internal traffic. Minimize data flowing out of the cloud provider’s network to the internet, and use Content Delivery Networks (CDNs) for static content.
Pitfalls to avoid:
Network Complexity: Advanced networking solutions (e.g., custom ingress setups, service mesh for traffic routing) add complexity to your Kubernetes environment, and come with management and troubleshooting overhead.
Reduced Resilience: Confining network traffic to a single zone or region, without implementing robust failover mechanisms, increases the risk of application downtime during cloud provider zone or regional outages.
Provider Pricing Maze: All cloud providers charge differently for network traffic, so an architecture that works for one may not work for another. Study your specific cloud provider's cost structure. For instance, it may be cheaper to perform data backup onto another region instead of maintaining continuous cross-region data consistency.
Continue reading Part 2 (coming soon) of this blog, where we share a case study detailing real-world application of these strategies by an organization operating cloud-scale Kubernetes infrastructure across multiple cloud providers and continents. Get ready for behind-the-scenes war stories and first-hand lessons.


