.png)

# Should we apply old-school multi-core scheduling to GPUs?
by [@bwasti](https://x.com/bwasti)
---
Recently, the big usability and efficiency wins in ML have largely been
from researchers adopting time-tested engineering concepts.
- [PyTorch](https://arxiv.org/abs/1912.01703) brought huge usability improvements to the space
by leveraging the efficiency of interpretted execution (Python)
modern dynamic memory allocation.
- Loop-fusion, a concept from the 70's, became highly popular
with the widespread adoption of compilers like [XLA](https://arxiv.org/abs/2301.13062) (in JAX)
and [Triton](https://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf).
- [Paged-attention](https://arxiv.org/abs/2309.06180) applied the idea of memory paging
to the space of KV-caches and is now present in the most popular
and efficient inference engines like vLLM.
What all of these systems have in common is that they
split out a conceptual overhead. Frontend users
don't need to consider deep technical details while backend engineers
are able to (without getting in the way).
So, what else should we conceptually split up?
## Scheduling sucks
I think the most glaring problem right now
is the *tight coupling between training code and distributed scheduling*.
A common approach to handle this is to slap on
a piece of code that mutates the underlying modules.
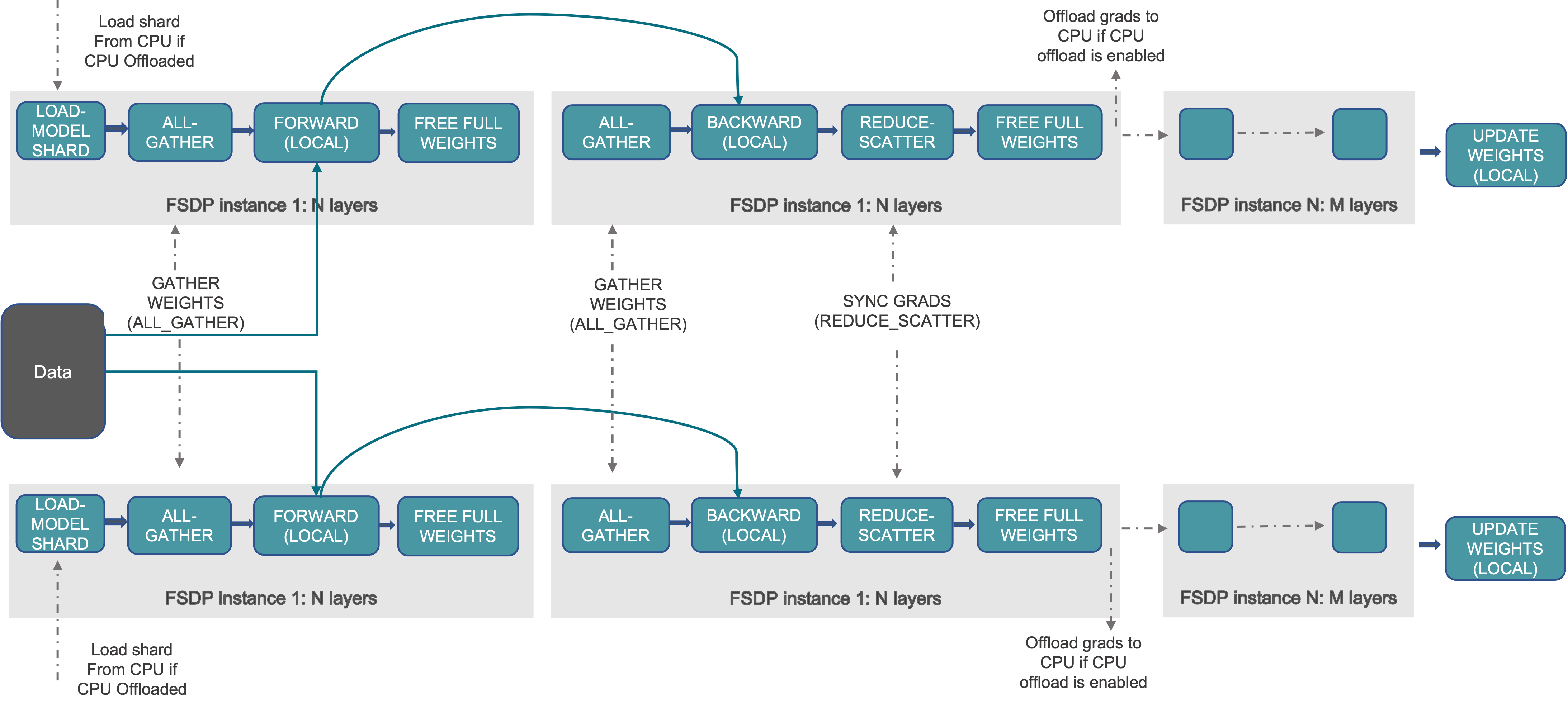
[FSDP](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) is a good example of this: it hacks into the modules
to shard up weights that it can. If your code and weights are normal,
this is a perfectly good solution.
Another approach is to just use modules that handle the parallelism natively.
Megatron defines things like [ColumnParallelLinear](https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/core/tensor_parallel/layers.py#L743)
that, although looking and feeling like a Linear module,
is actually a super optimized distributed version that can scale to many GPUs.
If you know what Column means and why you'd use that over the Row version,
this is a nice API that's quick to get running with.
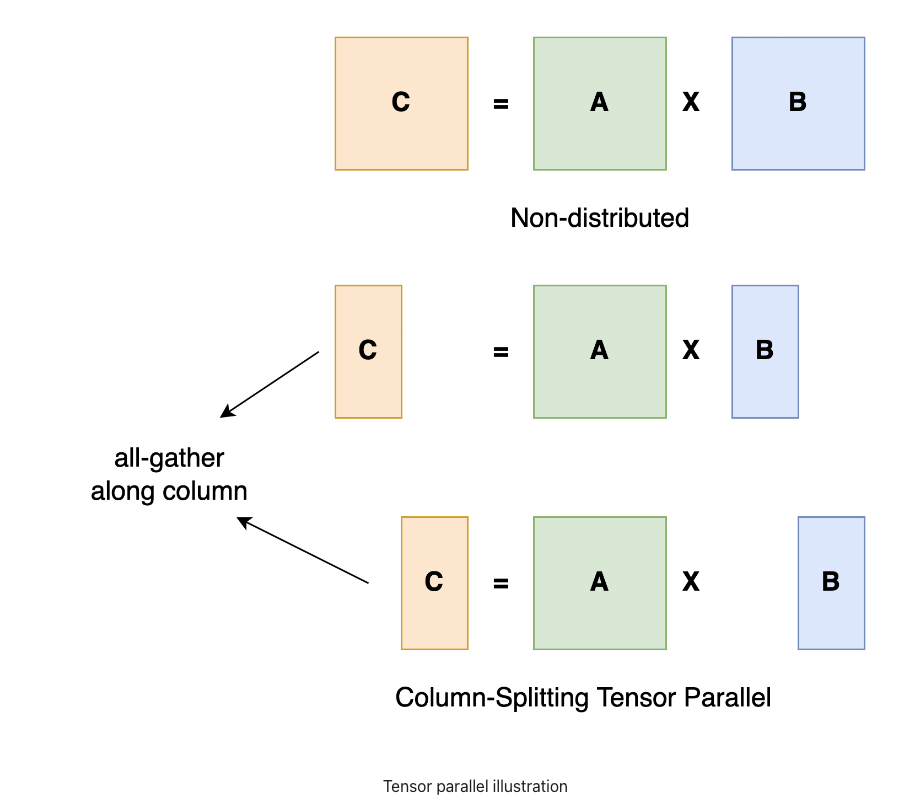
([*source*](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/libraries/neuronx-distributed/tensor_parallelism_overview.html))
## Scale
These are compatible ideas and, as a result, both are heavily used.
But things start to break down when you start *really^(tm)* scaling.
The first thing to *really^(tm)* scale is to get a ton compute per node.
That means amping up the batch size to insane levels.
GPUs have a ton of RAM these days, but if you want to *really^(tm)* scale
it's simply not enough because weights and optimizer states are massive.
The trick is to split the model's sequential elements (layers)
onto different GPUs. That way you free up a ton of RAM and
can batch up a lot more computation.
And while this works well in theory, it's super fucking annoying.
This is what happens:
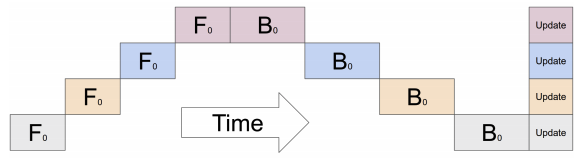
And the obvious fix (moar batches!) still has issues:
([*source*](https://alband.github.io/doc_view/pipeline.html))
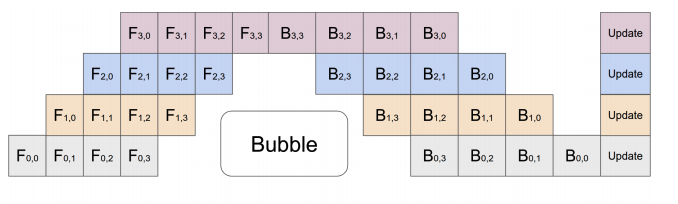
So what do people do these days?
Well the trick is to get really smart people to
think really hard and derive stuff like this:

([*source*](https://github.com/deepseek-ai/DualPipe))
Which basically has zero "bubbles" of idleness.
Now I am certainly impressed with this rubics cube solution,
I don't think I'd personally be able to derive such a thing.
But wait, didn't our industry tackle problems like this decades ago?
## Ancient History
Multi-core machines have been around for a while;
since at least the 90's with the development of the [Stanford Hydra CMP](https://arsenalfc.stanford.edu/kunle/publications/hydra_MICRO00.pdf).
That means engineers have been scheduling workloads on these
types of architectures for at least three decades.
There's basically two types of multi-core scheduler paradigms,
either one or multiple task queues.
In 1998, [Cilk-5](https://dl.acm.org/doi/10.1145/277650.277725) was written and introduced the canonical "work-stealing"
implementation
(which had been around before, but not as elegantly).
This solves for multiple task queues, where chips effectively
do their own thing until they're idle. When they're idle
they check on their neighbors to take some additional work.
This scales quite well but often creates a tension between
when to "peak" and how much work to take on. [(more discussion here)](https://pages.cs.wisc.edu/~remzi/OSTEP/cpu-sched-multi.pdf)
Single-queue systems are vastly more simple
but take on the burden of locking mechanisms which slows them down.
Despite that, they have their place and you can find them
in one of the Linux kernel's schedulers (BFS, [citation](https://research.cs.wisc.edu/adsl/Publications/meehean-thesis11.pdf)).
## GPUs are not CPUs
Of course we can't just jump in an apply all these concepts
to GPUs, because they don't really work like that.
There are, as far as I can really tell, three key differences
that impact the application of CPU scheduler algorithms.
- GPU workloads stretch over multiple nodes with varying comm latencies.
- GPUs don't have a shared memory system.
- GPUs don't have interrupts.
Stretching over multiple nodes makes
this whole thing super annoying to deal with.
Luckily, Nvidia picked up on this a while ago and their new B series GPUs
can be interconnected as if they're on the same host
at a crazy degree: 72 at once!
Older H series GPUs follow an 8x per node with high latencies to
other GPUs.
Let's just consider the new stuff and scratch out that first issue.
- ~GPU workloads stretch over multiple nodes with varying comm latencies.~
- GPUs don't have a shared memory system.
- GPUs don't have interrupts.
Having a shared memory system is nice because it makes work-stealing
and migration a lot easier: every task has the same access latency
and switching things up is basically free.
Just kidding. Even before modern multi-core CPUs added NUMA
(non-uniform memory access), the L1 and L2 caches were thrashed
on workload changes, so scheduling algorithms typically
had very advanced affinity logic.
With the new stuff
(hitting some parts of memory is more expensive for certain cores),
the logic is even more robust.
With GPUs we have decent RDMA in the interconnects,
so instead of paging to a shared memory space with implicit hierarchitcal
latencies, we just have to inject operations to move things around.
Basically the same idea though: *switching tasks may require memory that
is not nearby and our scheduler should know that.*
- ~GPU workloads stretch over multiple nodes with varying comm latencies.~
- ~GPUs don't have a shared memory system.~
- GPUs don't have interrupts.
This one is *particularly* obnoxious to deal with.
In CPU land you can pause execution and switch to different tasks.
This is a fundamental requirement for listening Spotify while
reading blogs on your browser.
You can't just stop a GPU and even worse you can't really wait until
it's done executing (without injecting a stupid amount of latency).
That's because GPUs are asynchronous as hell and you're supposed
to load them up with a stream of kernels to keep them occupied.
The lag here can be on the order of 10 to 50 microseconds.
A lot of full operations run in that time (or less) so taking a hit
like that can be disastrous.
So what's the fix? I don't really know. My thinking right now
is that operations are pretty fast, so we can bundle them up (somewhat
arbitrarily) and it won't be too bad. If we want to get fancy with it,
we can leverage the fact that ML workloads
are obscenely repetitive and create simple cost models to predict how long
operations will take to run.
If we want to get dumber with it: expose the bundling to the user
so they can tell us what "forward_first_chunk" and "backward_last_chunk" are.
## [GT](https://github.com/bwasti/gt) - an experimental bit of code
To play with ideas above I wrote/vibe-coded a [PyTorch wrapper](https://github.com/bwasti/gt)
that uses the single-queue technique to schedule
really simple code onto many GPUs.
[](https://github.com/bwasti/gt)
It is currently *very* dumb, but I think the
design is in a solid state and won't change.
The key (and somewhat lame) bit is that I had to re-implement
autograd in the "client." PyTorch is leveraged at the worker
and if you leave the autograd that low-leve you can't
schedule backward passes in a clever way.
Everything else basically just passes user "instructions"
as a stream to a dispatcher that then rewrites the instructions
to be distributed PyTorch operations.
One could imagine disabling the dispatcher entirely and still
getting the same results, albeit slower.
This frees up the client to be *pure* math,
with little need to consider things like FSDP or ColumnParallelLinear.
Dispatch logic can then convert this pure math
into reasonable distributed execution by implementing algorithms
similar to the ones mentioned above.
But... maybe we need an escape hatch?
This stuff is simply not super developed, and we may want to be
much more explicit about where stuff lives.
I didn't want to destroy the "pure math" aspect of the client
so I added this optional "signaling" feature:
```
import gt
with gt.signal.context('forward_layer1'):
x = gt.randn(100, 64)
y = x @ w
```
which does *nothing*. Unless you load a config into the dispatcher:
```
forward_layer1:
shard:
axis: 0 # Shard batch dimension
workers: [0, 1, 2, 3] # Use workers 0-3
backward: backward_layer1 # Different config for gradients
backward_layer1:
shard:
axis: 0
workers: [0, 1, 2, 3]
```
This makes life way easier yet still thoroughly decouples the
code from the "schedule."
If you want to play with this (or contribute!!! 😁😁),
check out the largely AI-generated docs: https://bwasti.github.io/gt/.
I tried to set things up in a way that AI contribution is pretty easy.
The main trick was creating "instruction tape"
that allows for easy algorithm debugging.
For humans there's something that kind of looks like `top`:
```
python -m gt.scripts.top
```

which will show which GPUs are running which operations.
## Future
I'm an inference infrastructure engineer by trade, yet I recently lead
the pre-training of a small/medium-sized production model.
This leaves me in a bit of a confusing spot professionally, but
I'll keep playing with the single-queue scheduler idea in my spare time.
Thanks for reading!