.png)

Community-powered benchmarks from real developers
Upload existing code (refactoring, debugging, code review) → Compare 6 premium AI models → Vote on the winner → Build the world's most accurate benchmark
GPT-5Claude Opus 4.1Claude Sonnet 4.5Grok 4Gemini 2.5 Proo3
Public Beta • 3 Free Evaluations Daily
✓ No credit card required • ✓ Results via email within 24hrs • ✓ 6 top AI models tested
See Who's Winning
Community-driven rankings updated in real-time as developers vote on their favorite solutions
How It Works
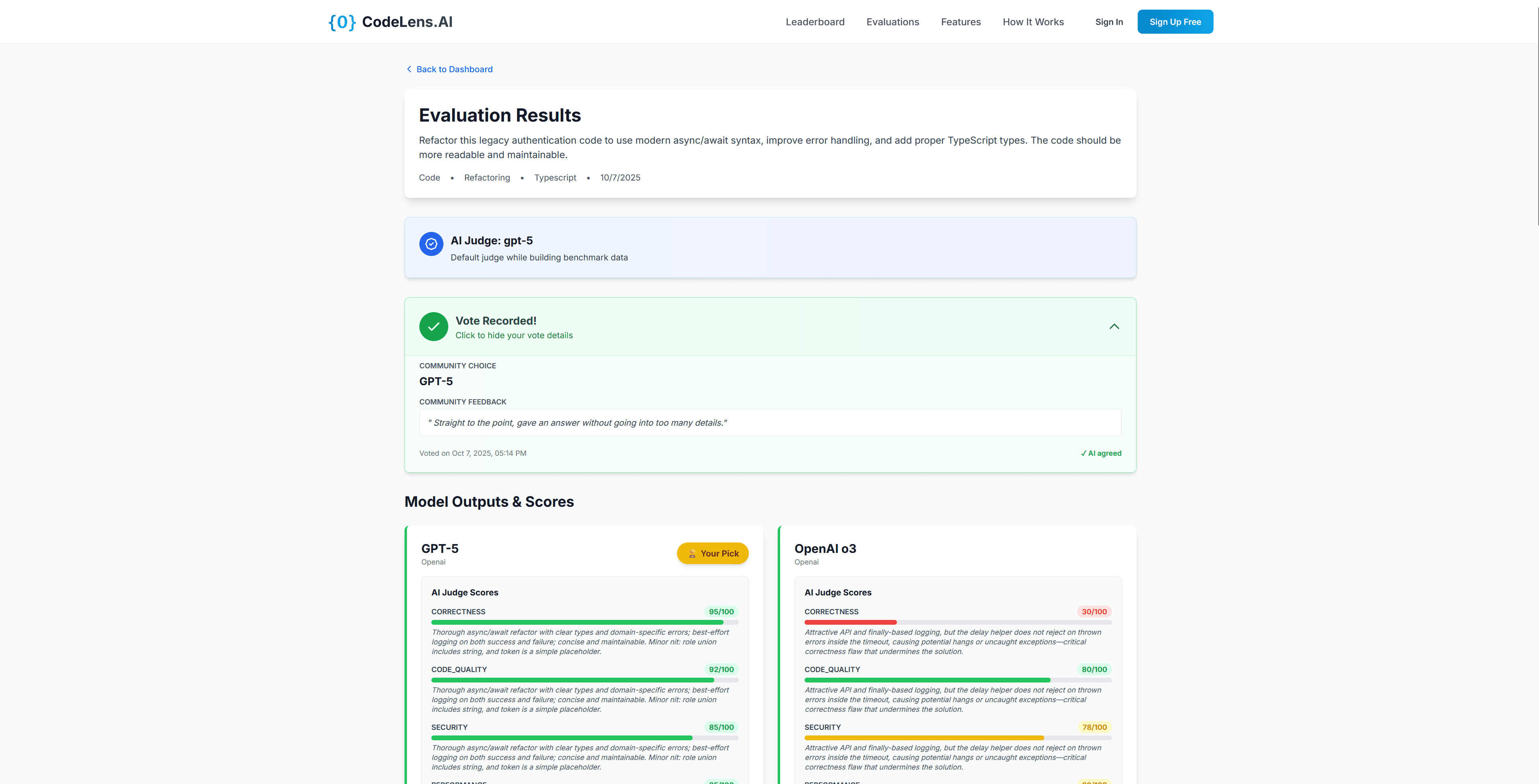
See All 6 Models Side-by-Side
Compare outputs, AI judge scores, and community votes in real-time. Every evaluation helps build the world's most accurate benchmark.
Email When Ready
Get notified via email when your evaluation is ready (typically within 24hrs). The current champion model scores all outputs instantly.
You Cast the Final Vote
Pick the winner and explain why in your own words (required comment builds qualitative insights)
Leaderboard Updates Live
Your vote instantly updates win rates and rankings for the entire community to see
Why Choose CodeLens.AI?
Stop relying on vendor marketing claims. Get unbiased, community-driven insights on which AI model solves YOUR specific coding challenge best. Every evaluation helps build the world's most accurate benchmark of real-world LLM performance.
How It Works
Four simple steps to discover which AI model solves your code challenge best
Submit Your Code Challenge
Paste your code and describe the task. Our AI automatically detects the domain, task type, and language—no dropdowns needed.
All 6 Models Compete
We run your challenge through GPT-5, Claude Opus 4.1, Claude Sonnet 4.5, Grok 4, Gemini 2.5 Pro, and o3 in parallel.
AI Judge + You Vote
The current champion model judges all outputs. Then YOU vote on the winner and share your reasoning (required comment).
Build the Benchmark
Your vote updates the live leaderboard. Over time, we build the world's most accurate dataset of real-world LLM performance.
What Makes Us Different
🎯
Real Tasks
No synthetic benchmarks. Real code from real developers.
🗳️
Community Truth
Developers decide winners, not algorithms or vendors.
🔍
Task-Specific
See which model excels at security vs refactoring vs architecture.
No credit card required • Results via email within 24hrs • 6 top AI models tested
Frequently Asked Questions
Everything you need to know about CodeLens.AI
Ready to Find Your Perfect AI Model?
Discover which AI model solves your code challenges best
Free•No credit card•Results in 2 minutes

