.png)

Introduction
Qwen3-VL represents a breakthrough in multimodal vision-language modeling, offering both dense and Mixture-of-Experts (MoE) variants alongside Instruct and Thinking versions. This advanced model series builds upon its predecessors with significant improvements in visual understanding while maintaining exceptional text processing capabilities.

Key Architectural Innovations
Enhanced MRope with Interleaved Layout: Provides superior spatial-temporal modeling for complex visual sequences.
DeepStack Integration: Effectively leverages multi-level features from the Vision Transformer (ViT) architecture for richer visual representations.
Advanced Video Understanding: Features evolved text-based time alignment, transitioning from T-RoPE to text timestamp alignment for precise temporal grounding.
Model Variants and Performance
Qwen3-VL-235B-A22B-Instruct
-
Achieves top performance across most non-reasoning benchmarks
-
Significantly outperforms closed-source models including Gemini 2.5 Pro and GPT-5
-
Sets new records for open-source multimodal models
-
Demonstrates exceptional generalization and comprehensive performance in complex visual tasks
Qwen3-VL-235B-A22B-Thinking
-
Excels in complex multimodal mathematical problems, even surpassing Gemini 2.5 Pro on MathVision benchmarks
-
Shows notable advantages in Agent capabilities, document understanding, and 2D/3D grounding tasks
-
While maintaining competitive performance in multidisciplinary problems, visual reasoning, and video understanding
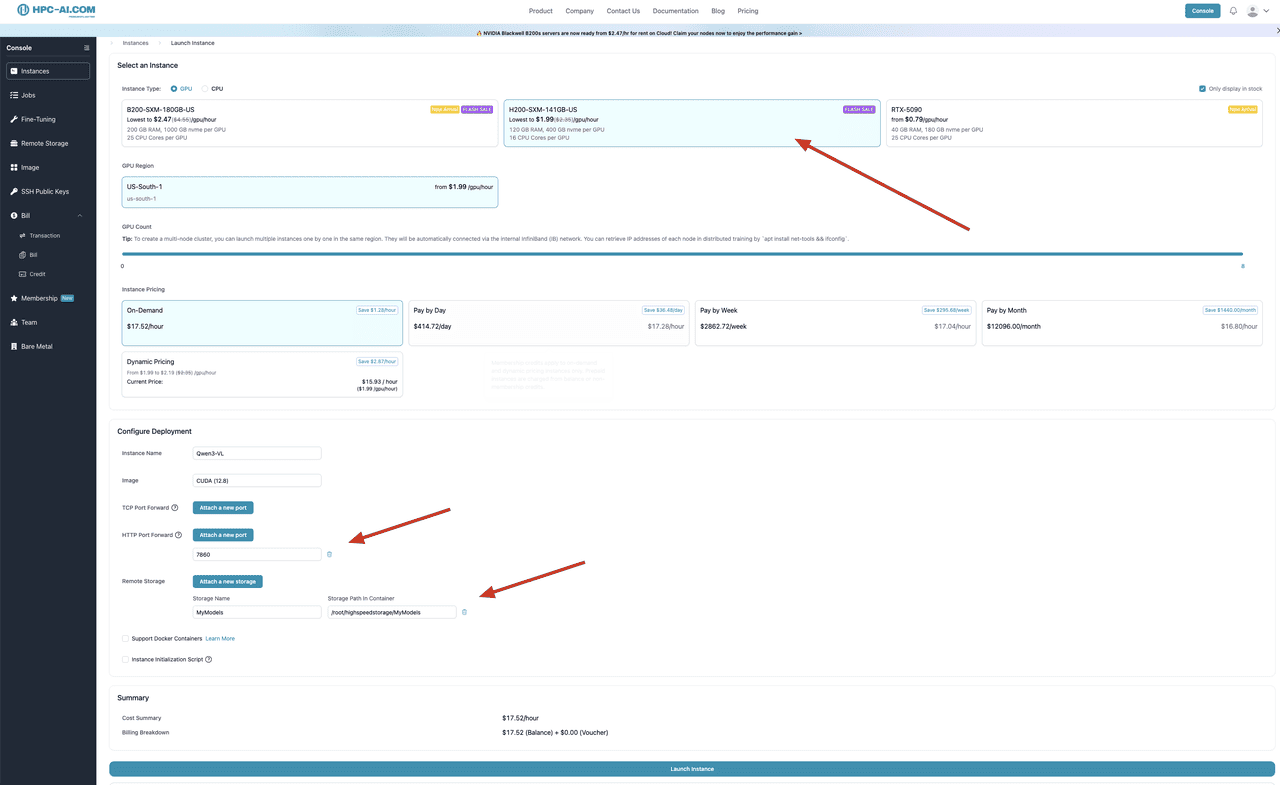
HPC-AI.COM provides the ideal platform for deploying Qwen3-VL, offering high-performance GPU access at competitive prices with flexible scaling options tailored to your specific requirements.
Hardware Requirements
Qwen3-VL-235B-A22B-Instruct requires enterprise-grade GPU infrastructure for optimal performance and reliability:
Minimum Specifications
-
GPU Memory: 480GB VRAM for full precision (BF16) inference, or 112-143GB with advanced quantization techniques (Q3-Q4)
-
System Memory: 128GB+ high-speed DDR5 RAM (256GB strongly recommended for smooth operation and efficient data processing)
-
Storage: 500-600GB high-performance NVMe SSD storage for model weights, inference cache, and system dependencies
Recommended Configuration
HPC-AI Optimized Setup: Select our pre-configured 8x H200 GPU cluster with CUDA 12.8 environment for optimal performance, memory distribution, and seamless deployment. This configuration provides:
-
Total VRAM: 1.12TB across 8 GPUs (141GB per H200)
-
Tensor Parallelism: Native 8-way distribution for maximum efficiency
-
Pre-optimized Environment: CUDA 12.8, cuDNN, and necessary ML libraries pre-installed
-
High-Speed Interconnect: NVLink connectivity for efficient inter-GPU communication
Environment Setup
Create Conda Environment
conda create -n qwen3-vl-instruct python=3.10 -y conda activate qwen3-vl-instructTransformers
pip install git+https://github.com/huggingface/transformers # Alternative: pip install transformers==4.57.0 (when released) pip install --upgrade torch torchvision torchaudio pip install --upgrade accelerateNote: Transformers deployment requires additional VRAM. We recommend using 8x H200/B200 GPUs for this approach.
vLLM (Recommended)
uv pip install -U vllm \ --torch-backend=auto \ --extra-index-url https://wheels.vllm.ai/nightlyImportant: Use the vLLM nightly build as the stable release is currently being updated.
Model Deployment with vLLM
- Download Model from Cluster Cache
- Deploy with vLLM
Critical Parameters Explained
-
--tensor-parallel-size 8: Distributes the model across 8 GPUs. This value must match your available GPU count.
-
--gpu-memory-utilization 0.8: Utilizes 80% of GPU memory. Reduce to 0.75 or 0.7 if out-of-memory errors occur.
-
--max-num-batched-tokens 1024: Maximum tokens processed in a single batch. Higher values improve throughput but increase memory usage.
-
--limit-mm-per-prompt.video 0: Disables video processing to conserve memory for image-only tasks.
-
--enable-prefix-caching: Improves efficiency by caching common prompt prefixes.
Getting Started
Once deployed, your Qwen3-VL instance will be accessible at your local address http://localhost:7861 or port-forwarded address http://notebook.region.hpc-ai.com ready to handle complex multimodal tasks with state-of-the-art performance. The model excels in visual reasoning, document understanding, mathematical problem-solving, and agent-based applications.
For production deployments, consider implementing load balancing, monitoring, and auto-scaling solutions to maximize efficiency and reliability.
Use Cases
We build it using vLLM server with Gradio.
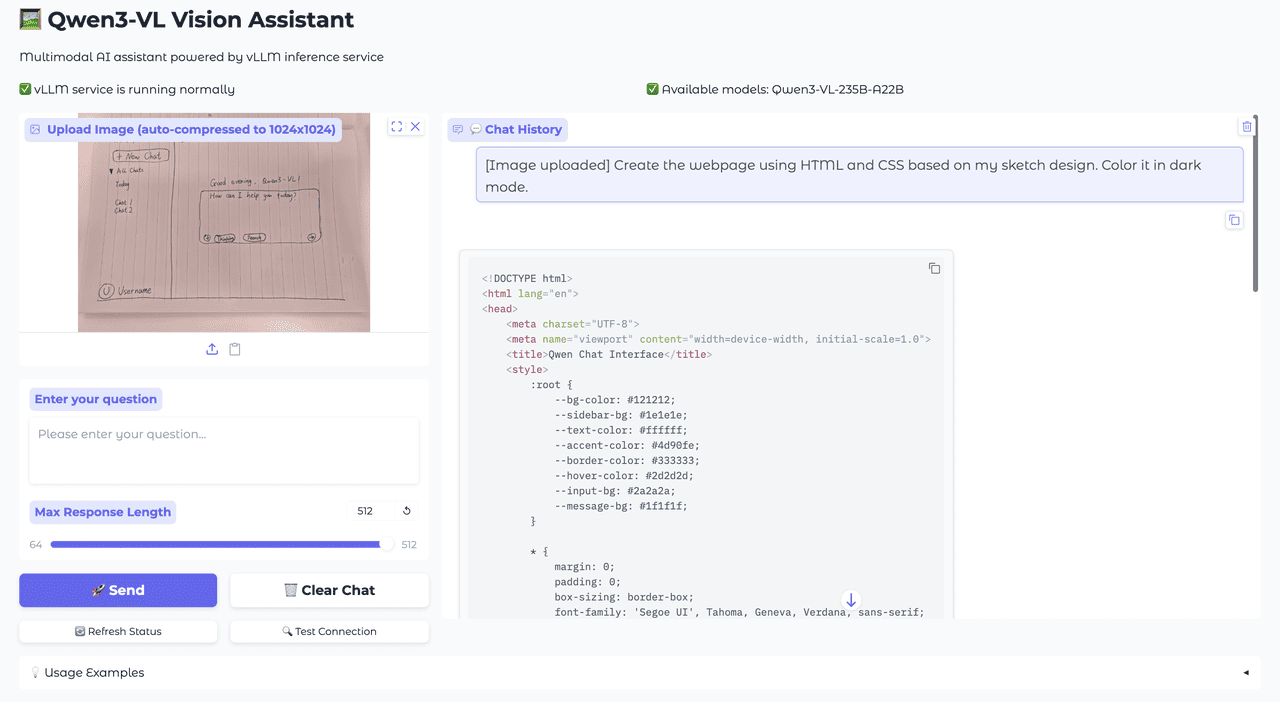
Code Programming and Development
Qwen3-VL combines visual understanding with advanced code generation capabilities, demonstrating exceptional potential in frontend development. The model can transform hand-drawn sketches into functional web code and assist with UI debugging, significantly enhancing development efficiency and streamlining the design-to-code workflow.
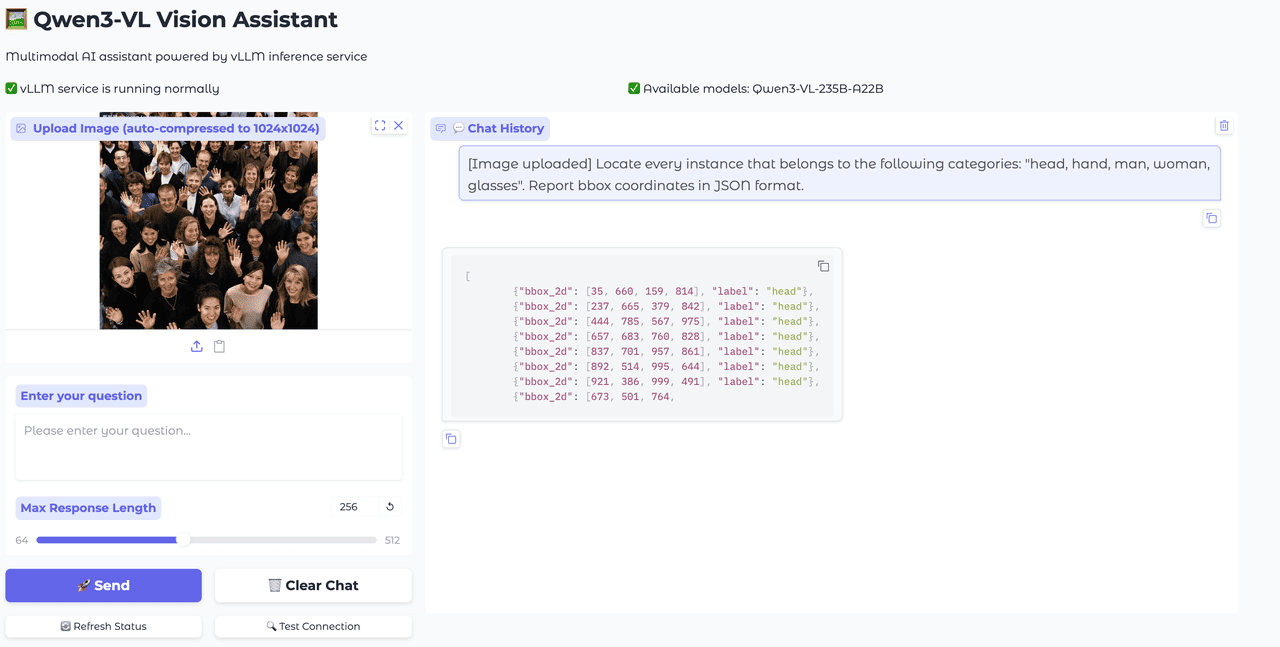
2D/3D Positioning and Spatial Understanding
The model excels in spatial reasoning tasks, accurately identifying and localizing objects in both 2D images and 3D scenes. This capability makes it invaluable for applications requiring precise object detection, spatial analysis, and scene understanding.
Universal Object Recognition
Qwen3-VL demonstrates comprehensive object recognition capabilities, identifying and understanding a vast array of items, entities, and concepts across diverse visual contexts. This universal recognition ability enables versatile applications in content analysis, inventory management, and visual search systems.
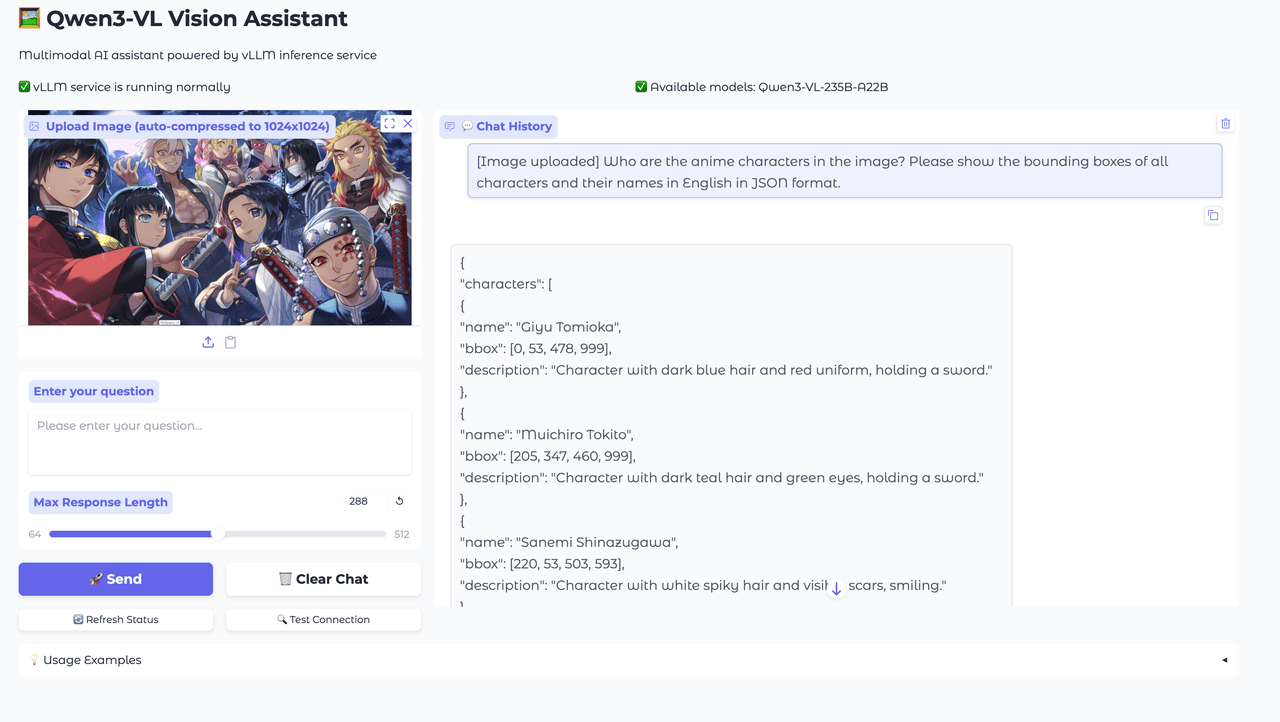
Complex Instruction Following
Qwen3-VL exhibits superior comprehension of complex textual instructions, accurately understanding and executing multi-step processes, conditional logic, and structurally intricate requests. Even when faced with sophisticated task requirements involving multiple conditions and decision points, the model ensures reliable task completion with high precision.
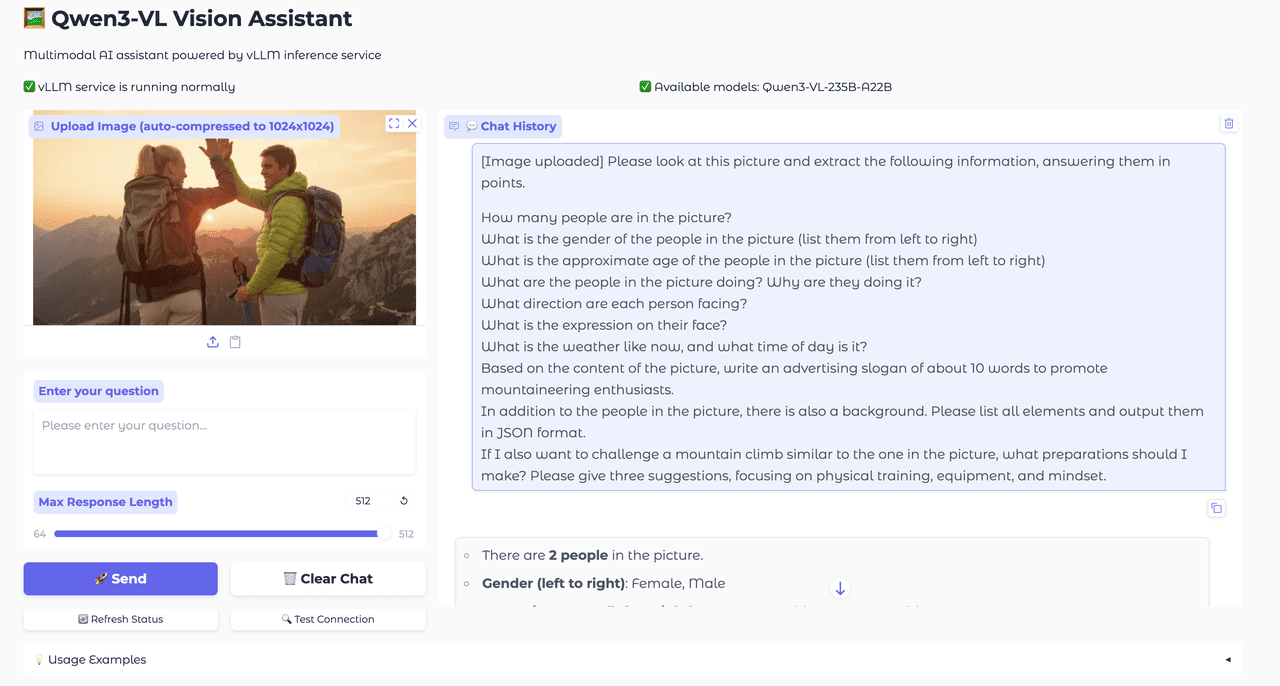
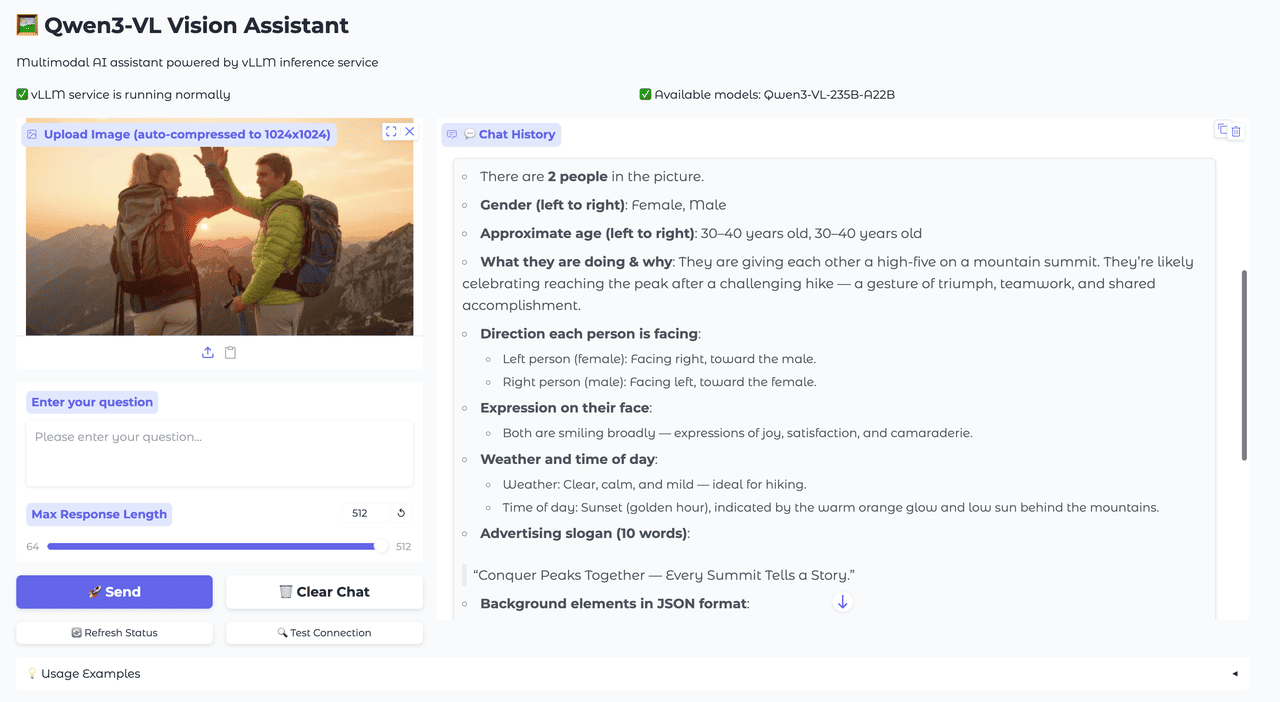
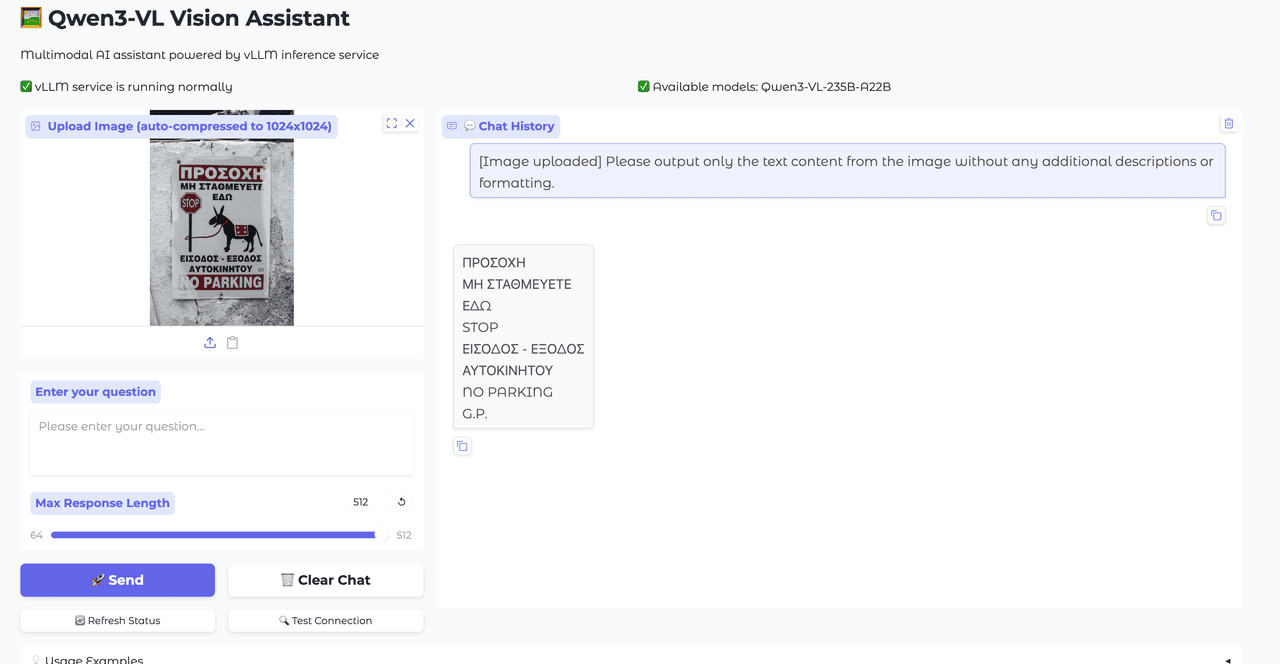
Multilingual OCR and Question Answering
The model's OCR capabilities have been significantly expanded from 10 to 32 supported languages, now including Greek, Hebrew, Hindi, Thai, Romanian, and many others. This enhancement better serves diverse international markets and regional requirements. Additionally, Qwen3-VL supports multilingual image-text question answering, facilitating seamless cross-language communication and making it accessible to global users regardless of their native language.
Reference
Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef\&from=research.latest-advancements-list



