.png)

Ultra-responsive, full-duplex voice assistant tuned for Apple Silicon + MLX. End-to-end round trip (speech → LLM → TTS) is consistently under 1 second, even while handling barge-in.
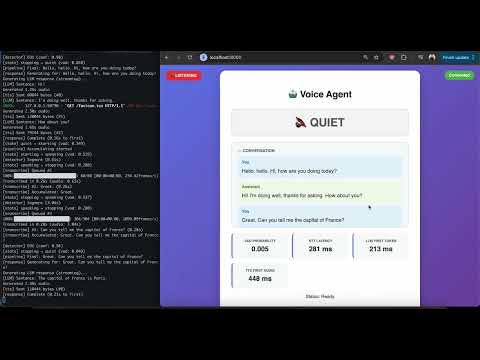
- On-device VAD, STT (Whisper), LLM, and Kokoro TTS sharing a single MLX runtime
- Sentence-streaming LLM responses with immediate, cancellable TTS playback
- Client-side AudioWorklet correlator for robust echo suppression and barge-in
- Rolling audio buffer to preserve context around interruptions
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python server.py
Then open http://localhost:8000 and hit Start Listening.
- config.py: audio rate, VAD thresholds, queue sizes, model choices
- index.html: INTERRUPTION object for interruption sensitivity
- requirements.txt: pin runtime dependencies for MLX + Kokoro
Mic (16 kHz) → Correlator → VAD State Machine → Segment Queue
↓ ↓
WebSocket ↔ Browser UI MLX Whisper STT
↓
MLX LLM → Kokoro TTS
↓
Playback + barge-in feedback
- server.py – FastAPI WebSocket server + pipeline orchestration
- audio_buffer.py, vad_detector.py – speech segmentation utilities
- transcriber.py, llm_handler.py, tts_handler.py – model wrappers
- index.html, correlator.js – interactive UI with barge-in logic
Silero VAD, Whisper, MLX, Kokoro TTS, and Pipecat SmartTurn for EoU detection. MIT licensed.



