.png)

- A quick primer on agents
- Why Graph RAG is inherently agentic
- Create a vector index
- Graph RAG with BAML
- Evaluation
- Observations
- Conclusions
- Code
- Footnotes
When it comes to building RAG applications, I’ve long held the belief that knowledge graphs and vector search go hand-in-hand. However, anyone who has experimented with Text2Cypher in Graph RAG is likely familiar (as I am) with a common frustration: the MATCH query returns an empty result (most likely because there isn’t an exact match for the property value in the database). This stalls the retrieval step, and the LLM cannot generate a response.
In this post, I’ll demonstrate how to address this limitation by enhancing retrieval with Kuzu’s vector search capabilities, introducing an agentic router that leverages tool calling to handle empty results more intelligently. I’ll pay special attention towards testing and evaluating the agent workflow vs. the vanilla Graph RAG workflow, to show that the performance is indeed improved by the agentic approach.
In an earlier post, I demonstrated a methodology to transform unstructured data (images and/or text) from multiple sources into a graph using BAML and Kuzu. This post picks up from where I left off, by reusing the existing graph of patients, the drugs they take, the conditions the drugs treat, and the side effects (symptoms) experienced by the patients taking these drugs. The schema of this graph is shown below.
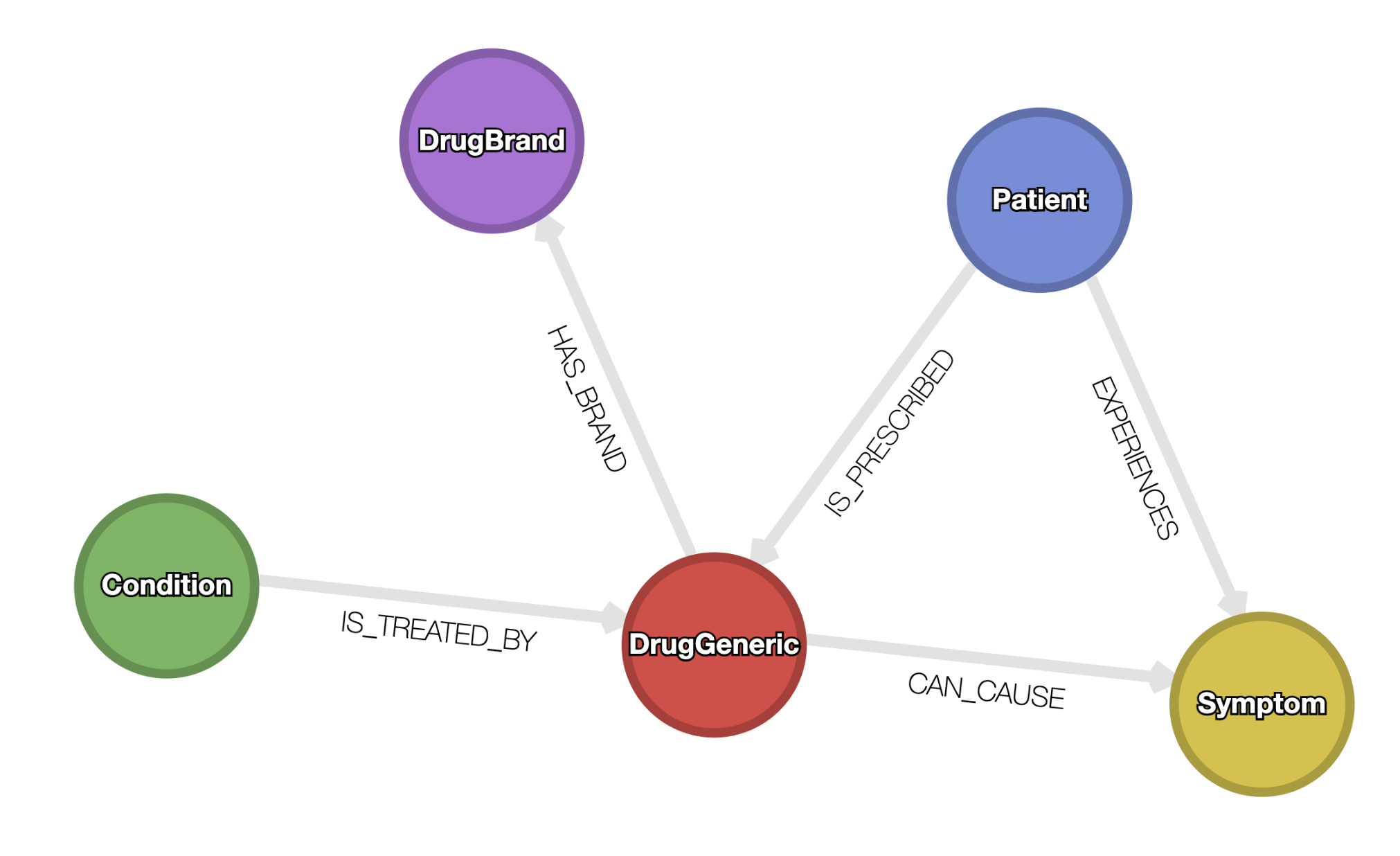
Graph schema showing patients, drugs, conditions and side effects. See this post for details on how this graph was constructed from multiple unstructured sources
TL;DR: The key takeaways are:
- Not 0 to 1: Real world agentic systems exhibit a spectrum of autonomy (the degree of autonomy in the system is not binary). These systems are typically a combination of autonomous agentic components driven by LLMs, and deterministic components that involve hardcoded logic.
- Agents 🤝🏽 Graph RAG: Graph RAG is an inherently agentic problem, because the system needs to be able to recover from incorrect Cypher queries or retrieval failures at various stages.
- Text2Cypher capabilities: Recent LLMs from popular commercial providers, for e.g., openai/gpt-4.1 and google/gemini-2.0-flash, are quite capable at translating natural language questions into valid Cypher queries by inspecting the given graph schema.
- Performance: Graph RAG performance can be significantly enhanced by using a simple tool-calling router agent that can leverage vector search alongside graph queries.
- Evaluation is key: It’s a good idea to incrementally add autonomy to the Graph RAG workflow while regularly evaluating the outcome on an end-to-end basis. This inspires more trust in the system across a wide range of user inputs, while also allowing for future upgrades as LLMs get better over time.
A quick primer on agents
Just like Graph RAG itself, the term “agentic” can mean different things to different people, so let’s qualify our definition before using it liberally in the rest of this post. Based on information from multiple reputable sources1,2,3, the consensus on what makes a workflow “agentic” is that it involves LLMs making decisions about the control flow at one or more stages. This is in contrast to the purely deterministic workflows you may be used to from software engineering, where the control flow is explicitly defined by hand.
An agent is a system that uses an LLM to decide the control flow of an application.4
The key point to remember is that there exists a continuous spectrum of autonomy in which an agentic system can operate — it’s not “all or nothing” when it comes to the degree of control in the hands of the LLM! Any real-world workflow typically consists of multiple stages, not all of which can, and should, be handled by an LLM. To help guide the system towards the desired outcome, interspersing LLM-driven stages with deterministic steps (simple while loops, if statements, etc. in code) is a good way to go.
In general, LLMs can make decisions on an application’s control flow in various ways:
- Route to one of many tools or tasks downstream, depending on the output of a previous stage
- Inspect the output from a previous stage and decide if it’s sufficient. If more work is needed: a) run it again in a loop, or b) pass the work to other LLM-enabled agents downstream.
The level of autonomy of an agentic workflow can be succinctly summarized by the following figure.4
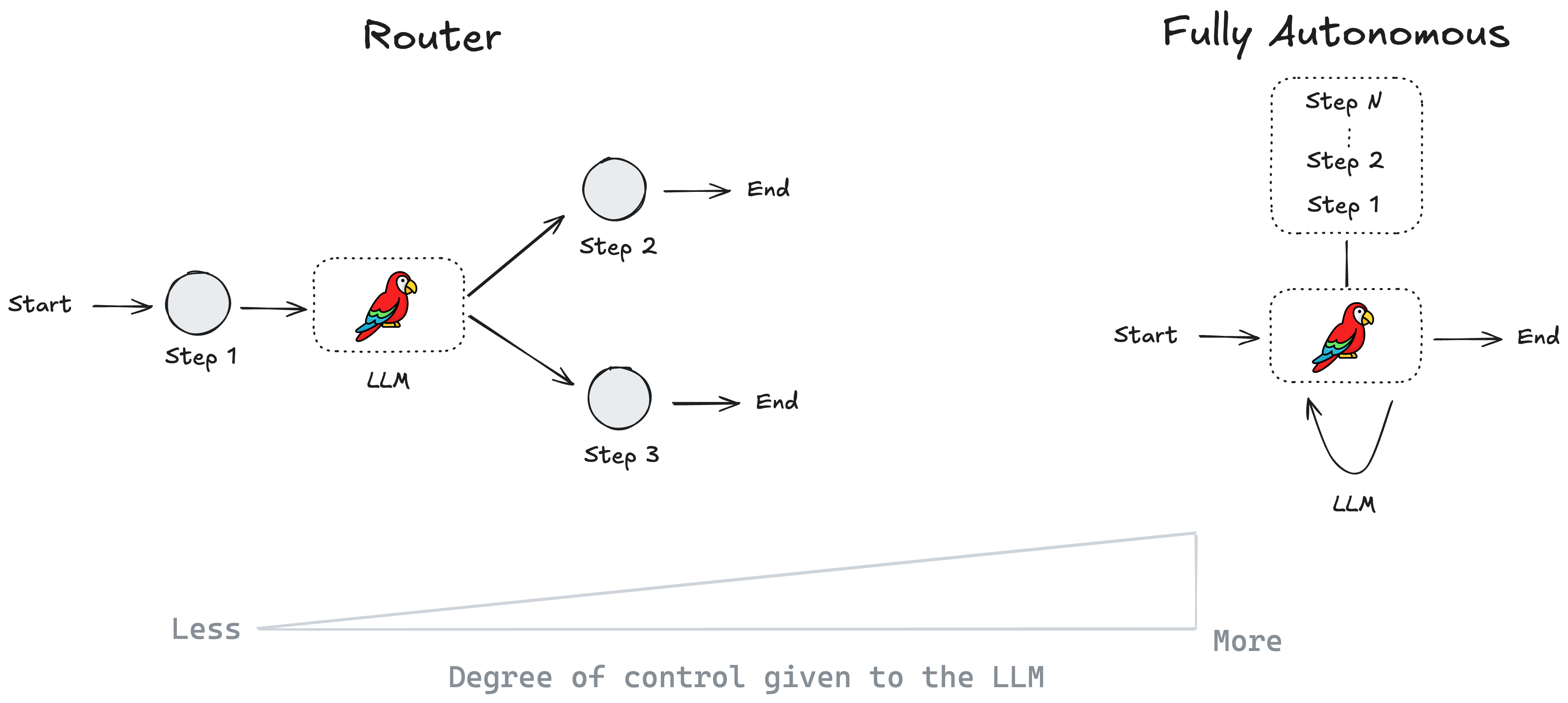
At the lower end of the scale, the LLM is used to route the control flow to upstream/downstream components that may be fully deterministic in and of themselves. At the upper end of the scale (fully autonomous), an LLM can pass control to other LLM-enabled agents, making the entire workflow non-deterministic. In practice, real-world agentic systems tend to be a combination of autonomous components on either end of this scale (or somewhere in between), with deterministic components at intermediate stages that impose adequate checks, balances and guardrails to guide the system towards the desired outcome.
Why Graph RAG is inherently agentic
Per the definition from prior posts in this blog, Graph RAG is a form of RAG where the retrieval step depends on a knowledge graph, providing the answer-generation LLM relevant context based on factual information in the graph — this is in contrast to retrieving the “most semantically similar” text based on embeddings of unstructured data in vector-based RAG.
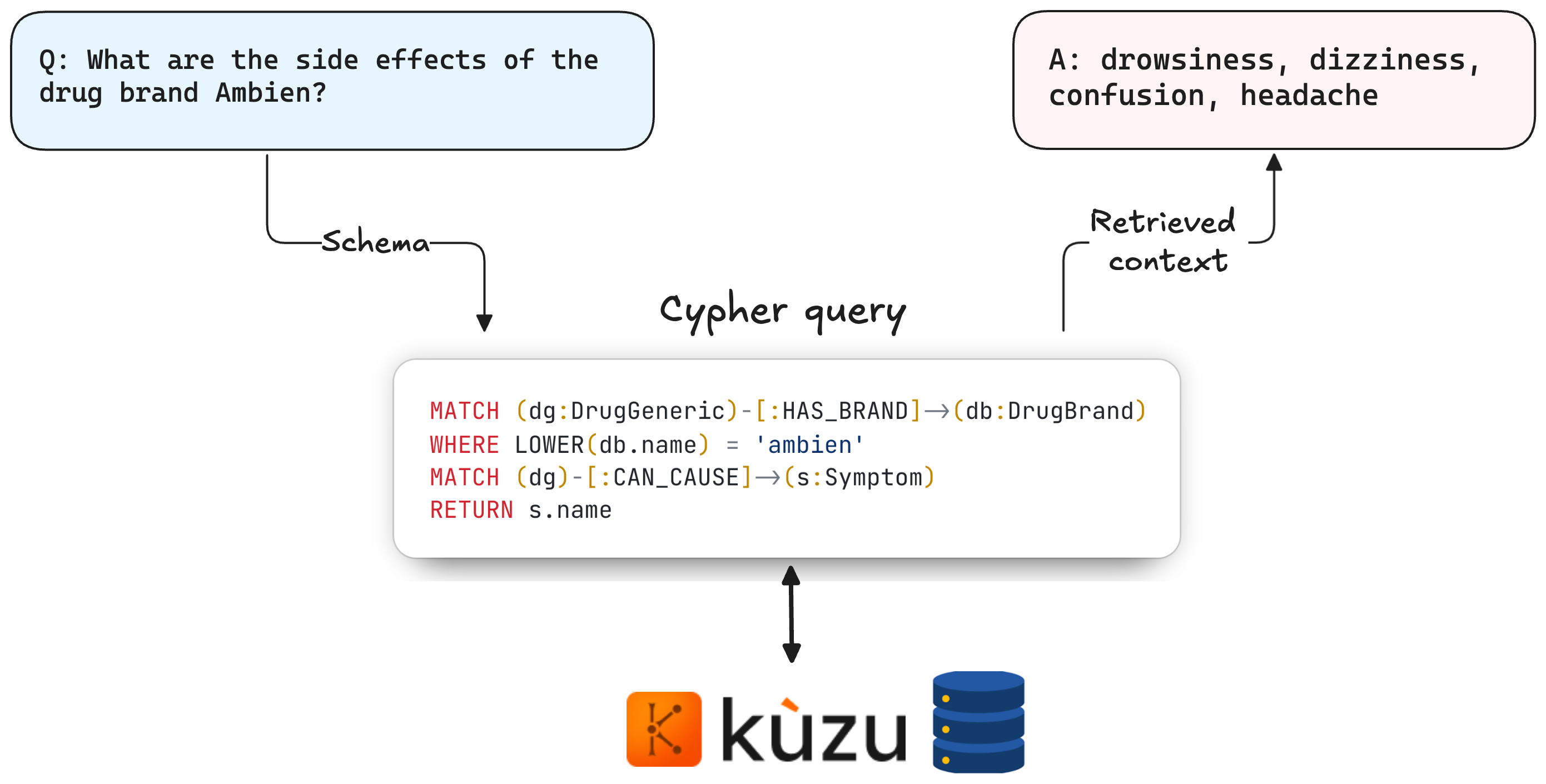
To retrieve from a graph database in a generalizable manner, a “Text2Cypher” LLM inspects the user query and the graph schema, translating them into a Cypher query that can retrieve from the graph. The results from this query are then appropriately formatted and passed as context to an answer-generation LLM, which can formulate a response in natural language. An example of this (when it works as intended) is shown below.
Vanilla Graph RAG, based on Text2Cypher alone, has an important limitation: even if the Cypher query generated is syntactically correct, if there isn’t an exact MATCH for the value specified in the query, it will return an empty result. In the example below, the question is asking for drugs that have the side effect “sleepiness”, but the database has nodes with the side effect “drowsiness”, resulting in an empty result from the Cypher query because no exact match is found. Not ideal by any means.
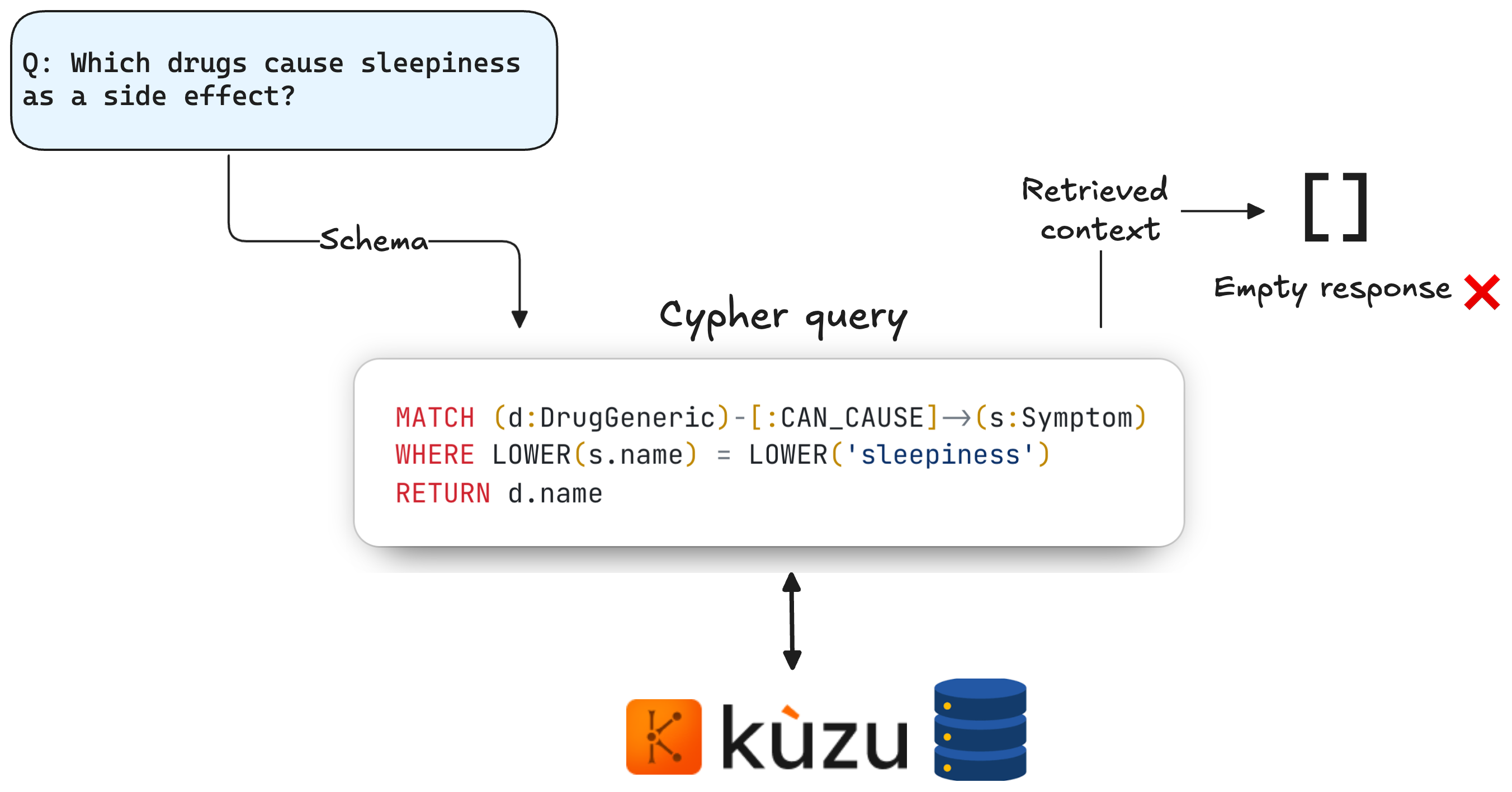
Naively running a single pass of Text2Cypher can quite often fail to return a useful response from the graph query. This is why vector search (based on semantic similarity) is a core component of most RAG systems. Because “drowsiness” and “sleepiness” essentially mean the same thing, we’d want our RAG system to try again, looking for similar symptoms experienced by patients or caused by drugs. Importantly, the retry logic may not easily be determined beforehand by a human, because the choice of downstream action can depend on the user query and the output from the prior step. This is why Graph RAG is inherently agentic: the retrieval process can benefit from the reasoning capabilities of LLMs at various stages to improve the outcome.
In the sections below, I’ll show how to expose Kuzu’s vector index function as a tool that an LLM can call as a fallback, in case an initial attempt at Text2Cypher returns an empty response. These are the beginnings of an agentic Graph RAG pipeline, where an LLM decides what tools to call to improve the results. Rather than aiming for fully autonomous agents right off the bat, the goal is to incrementally add more autonomy to the system, starting with a routing-based approach, and testing it end-to-end to see if the performance indeed improves.
Create a vector index
Kuzu provides a performant, on-disk HNSW index via a vector extension that scales as your data grows in size. You simply store vector embeddings (which are basically floating point arrays of a fixed dimensionality) as properties on your node tables. In this graph, there will be two vector indices — one for the Condition node table’s name property, and another for the Symptom node table’s name property. You can use any embedding model of choice and transform the name property values of either table into embeddings, and ingest them into their respective tables as follows. The following code snippet shows this.
import kuzu import polars as pl from sentence_transformers import SentenceTransformer db = kuzu.Database("ex_kuzu_db") conn = kuzu.Connection(db) # Load the embedding model model = SentenceTransformer('all-MiniLM-L6-v2') # Symptoms symptom_ids = conn.execute(""" MATCH (s:Symptom) RETURN s.name AS id """) symptom_ids = symptom_ids.get_as_pl() # type: ignore # Embed symptoms symptom_embeddings = model.encode(symptom_ids["id"].to_list()).tolist() symptoms_df = pl.DataFrame({ "id": symptom_ids["id"], "symptoms_embedding": symptom_embeddings }) print("Finished creating symptom embeddings") # Add a new property `symptoms_embedding` to the node table conn.execute( """ ALTER TABLE Symptom ADD IF NOT EXISTS symptoms_embedding FLOAT[384]; """ ) # Bulk-ingest the symptom embeddings to the node table conn.execute( """ LOAD FROM symptoms_df MATCH (s:Symptom {name: id}) SET s.symptoms_embedding = symptoms_embedding """ )The code shown above gathers all the name property values for the Symptom node table and embeds them using an embedding model from the sentence-transformers library in Python. A new symptoms_embedding property is added to the existing node table, and the embeddings are bulk-ingested into the Symptom node table via Polars. A similar approach is followed to ingest embeddings for the Condition node table as well. If you’re interested in the code that does this, you can find it here.
Once the embeddings are in the Kuzu database, it’s simple to create a vector index as follows:
# Create a vector index on the product summary embedding conn.execute( """ CALL CREATE_VECTOR_INDEX( 'Symptom', // Node table name 'symptoms_index', // Index name 'symptoms_embedding' // Column name on which to create index ) """ )You can now run a vector search query to find nodes whose symptoms are most similar to “sleepiness”. The vector search outputs the top 100 most similar results, and we return the nodes’ symptom names in ascending order of distance (i.e., the closest to the query vector).
# Transform the query string into a vector using the same embedding model query_vector = model.encode("sleepiness").tolist() response = conn.execute( """ CALL QUERY_VECTOR_INDEX( 'Symptom', 'symptoms_index', $query_vector, 100 ) RETURN node.name AS symptom, distance ORDER BY distance LIMIT 1 """, {"query_vector": query_vector}) print(response.get_as_pl()) ┌────────────┬──────────┐ │ symptom ┆ distance │ │ --- ┆ --- │ │ str ┆ f64 │ ╞════════════╪══════════╡ │ drowsiness ┆ 0.199042 │ └────────────┴──────────┘The above result shows that “drowsiness” is the symptom that’s closest to “sleepiness” in vector space. The two Python functions that allow vector search on the Symptom and Condition nodes are what I’ll refer to as “tools”5 that an LLM can call to enhance the final output. The tools are used in the BAML workflow shown below.
Graph RAG with BAML
Effective Graph RAG involves combining the vector search functions (as tools) with the Text2Cypher functions. A tool-calling routing agent is implemented in order to call the right vector index depending on the user’s question. Let’s look at how these parts come together.
BAML is a programming language that makes it very simple to get structured outputs from LLMs. In the previous post, I showed how BAML’s clean, concise syntax, its type system, and its strong emphasis on prompt testing makes the entire development process with LLMs a breeze. In this post, I’ll continue the exercise by creating a BAML prompt that can call the following tools:
- Text2Cypher: Convert the user’s question into a valid Cypher query, based on the provided graph schema
- PickTool: Based on the terms used in the user’s question, perform tool-calling to select the right vector search tool that can find similar terms in the database
- AnswerGeneration: Use the retrieved context to answer the user in natural language, without deviating too far from the provided context.
Text2Cypher
The BAML function used for Text2Cypher is shown below. It takes in a graph schema, the user’s question, and an optional additional_context (explained further below). The function’s output signature is a Query class that clearly tells the LLM that we want a valid Cypher query with no newlines (per the @description annotation).
class Query { cypher string @description("Valid Cypher query with no newlines") } function RAGText2Cypher(schema: string, question: string, additional_context: string | null) -> Query { client OpenRouterGoogleGemini2Flash prompt #" Translate the given question into a valid Cypher query that respects the given graph schema. <INSTRUCTIONS> - ALWAYS respect the relationship directions (from -> to) as provided in the <SCHEMA> section. - Use only the provided nodes, relationships and properties in your Cypher statement. - Properties can be on nodes or relationships - check the schema carefully to figure out where they are. - When returning results, return property values rather than the entire node or relationship. - ALWAYS use the WHERE clause to compare string properties, and compare them using the LOWER() function. - Pay attention to the ADDITIONAL_CONTEXT to figure out what to add in the WHERE clause. - Do not use APOC as the database does not support it. </INSTRUCTIONS> {{ _.role("user") }} <QUESTION> {{ question }} </QUESTION> <ADDITIONAL_CONTEXT> {{ additional_context }} <ADDITIONAL_CONTEXT> <SCHEMA> {{ schema }} </SCHEMA> <OUTPUT_FORMAT> {{ ctx.output_format }} </OUTPUT_FORMAT> "# }As always, BAML formats the prompt (via ctx.output_format) in a way that the system instructions and output signature are respected as much as possible6. In addition, BAML encourages you to test your prompt right away (in the same file, interactively via the editor). This makes it incredibly easy to begin experimenting and swapping out LLMs to gauge qualitative performance on a specific task — in this case, whether the Text2Cypher function generates queries that are syntactically correct.
🚩 Full path schema
The format in which the graph schema is presented in the LLM prompt is really important. For this blog post, I’ve used the format described in a recent paper7, which suggests that displaying the schema as full paths, i.e., the nodes and relationships as well as their property values, can help LLMs better interpret the schema to write good enough Cypher to answer the question.
The full path schema representation of the Kuzu database is shown in the BAML test below. In the application code, the schema information is extracted from Kuzu during query runtime and reformatted to the below format as a string. In this way, the latest version of the graph schema is always available to the LLM each time a new query is asked.
test RAGText2Cypher1 { functions [RAGText2Cypher] args { schema #" (:Patient {patient_id: string}) -[:EXPERIENCES]-> (:Symptom {name: string}) (:Patient {patient_id: string}) -[:IS_PRESCRIBED {date: date, dosage: string, frequency: string}]-> (:DrugGeneric {name: string}) (:DrugGeneric {name: string}) -[:CAN_CAUSE]-> (:Symptom {name: string}) (:DrugGeneric {name: string}) -[:HAS_BRAND]-> (:DrugBrand {name: string}) (:Condition {name: string}) -[:IS_TREATED_BY]-> (:DrugGeneric {name: string}) "# question "Which drugs are prescribed to patients with hypertension?" additional_context "" } // The assertions check that the right property value and node table names // are in the generated Cypher query @@assert({{ this|regex_match("[hH]ypertension") }}) @@assert({{ ":Condition" in this.response }}) }The main advantages of specifying the schema as “full paths” are the following:
- The directions of the relationships are made explicitly visible to the LLM, in the fewest tokens possible
- The property names and their data types are right next to the node and relationship labels. This means that the LLM’s attention window can focus on the information relevant to a path’s nodes and relationships in the same area of the model’s token space. In contrast, stringified JSON schemas can be overly verbose, and the property information may be separated from the node/edge labels in token space.
Router agent with tool calling
For the router agent, BAML provides an enum type that makes it simple to specify tools that an LLM can call. In this case, three tools are defined: Text2Cypher, VectorSearchSymptoms and VectorSearchConditions, that are each custom Python functions wrapped as FastAPI endpoints that can be called by the application. The PickTool function is shown below.
enum Tool { Text2Cypher @description("Translate the question into a valid Cypher statement") VectorSearchSymptoms @description("Search for symptoms or side effects mentioned in the question") VectorSearchConditions @description("Search for a condition or ailment mentioned in the question") } function PickTool(schema: string, query: string) -> Tool { client OpenRouterGPT4o prompt #" A prior attempt to write a valid Cypher query failed because an exact match with a property value was not found. Analyze the given query and select the most appropriate tool that can retrieve more useful context to answer the question. {{ _.role("user") }} <QUESTION> {{ query }} </QUESTION> <SCHEMA> {{ schema}} </SCHEMA> <OUTPUT_FORMAT> {{ ctx.output_format }} </OUTPUT_FORMAT> "# }Note how the PickTool function’s prompt clearly states that a prior attempt at Text2Cypher failed to generate a response — the LLM router kicks in and picks a tool if, and only if, the first attempt at Text2Cypher returns an empty result (which is all too common in vanilla Graph RAG).
For the example mentioned earlier — where the user asks for drugs that cause “sleepiness” as a side effect — because we have the term “drowsiness” in the database, we would expect the following sequence of events when the vector search tool is made available:

This time, the LLM router picks the VectorSearchSymptoms tool, which returns the most similar term to “sleepiness”, i.e., “drowsiness”. The LLM then uses this additional context to write a better Cypher query, which is then run on the Kuzu database. Hopefully, this approach makes sense at a conceptual level. Let’s architect a router agent-based Graph RAG system and test it, end-to-end!
Logical flow
The logical flow of the application is described in the figure below. All deterministic steps are shown as grey circles, and the LLM-driven steps are clearly marked as such.
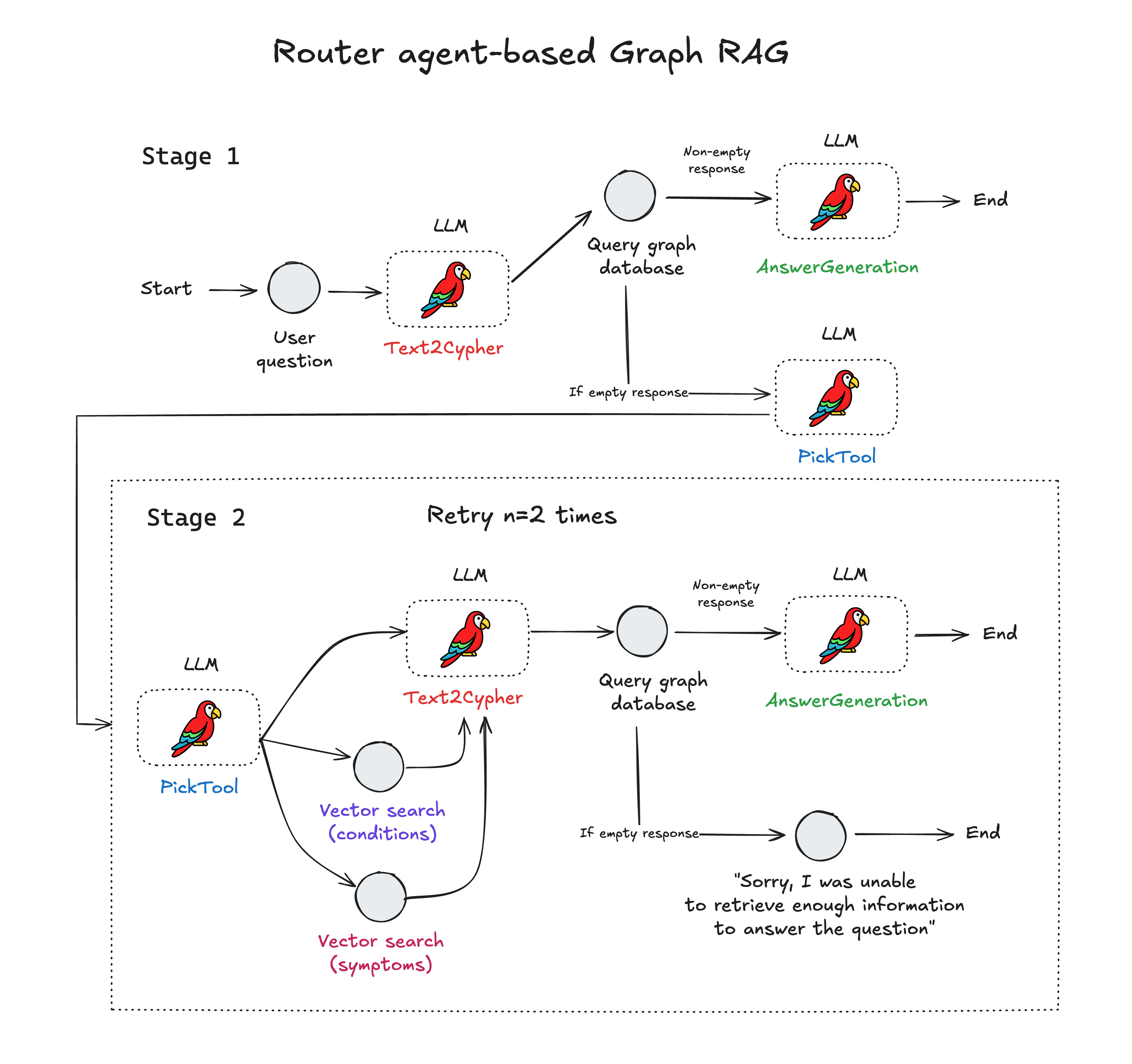
The workflow starts with a user’s question in natural language. This is translated into a Cypher query via an LLM that can interpret the graph schema. The query is run on the Kuzu database, after which the following sequence of steps occurs:
- If the response is non-empty, end the workflow.
- If the response is empty, the routing agent (PickTool) kicks in. One of three tools is selected based on the LLM’s assessment of the user’s question and the terms it identified.
- The vector search outputs “additional context”, i.e., the most similar terms to those used in the user’s question.
- The output of the vector search functions are once again sent to the Text2Cypher tool, which attempts
another Cypher query using the additional context.
- If the response is non-empty, end the workflow.
- If the response is still empty, the router agent workflow is run in a while loop until the maximum number of retries is reached, after which the workflow ends.
Architecture
From an architectural standpoint, the system is structured as shown below. BAML sits at the lowest level, closest to the LLM prompts, and the client code generated by BAML’s runtime is utilized by Python helper functions and classes. These are then exposed as endpoints on a FastAPI server, which can then be used by a Streamlit frontend.
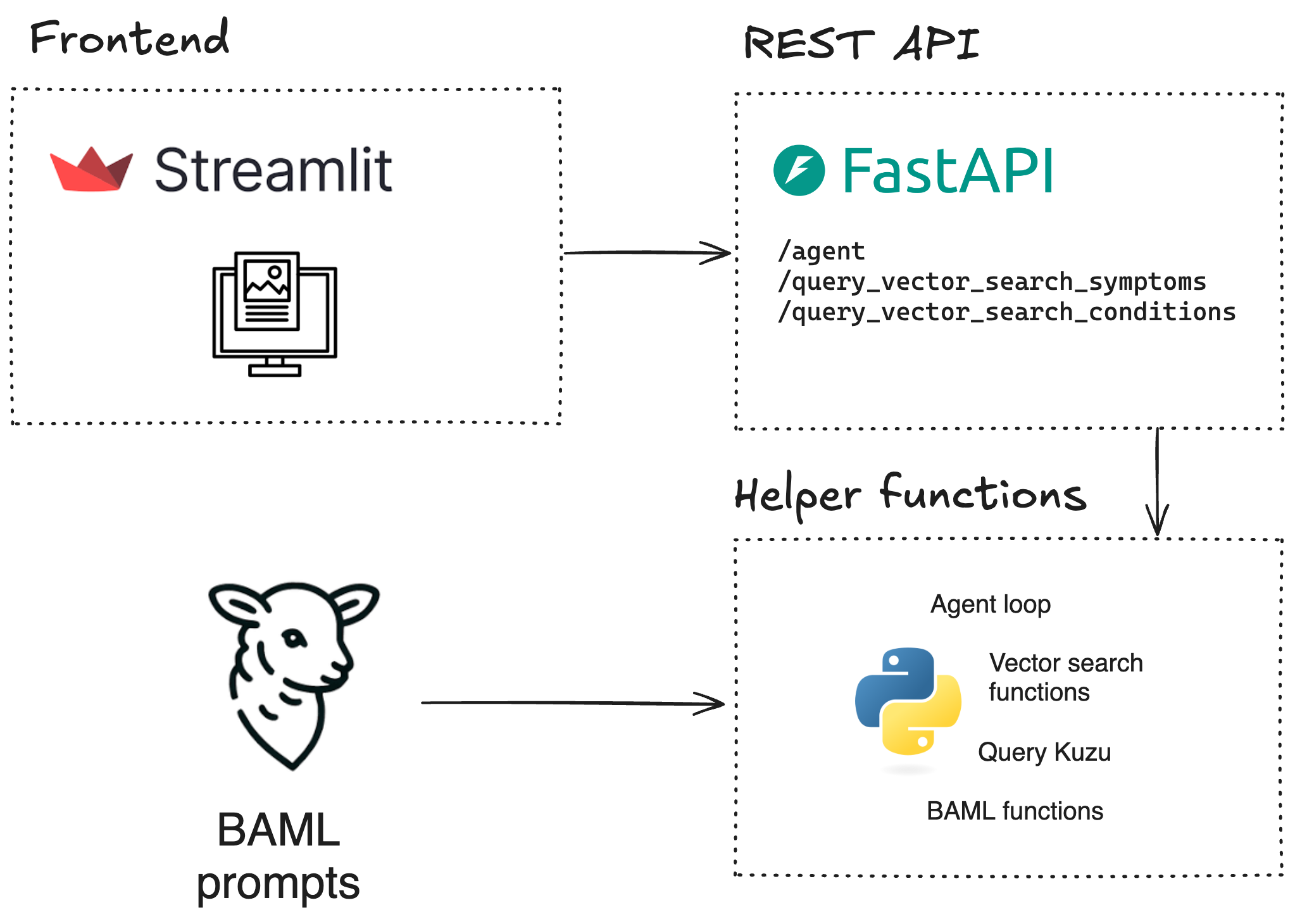
BAML for prompting
BAML is the bedrock of the prompting layer - anything that touches the LLM, goes through BAML. This ensures that the prompts have been thoroughly tested, while ensuring that the tool-calling functionality can be expanded as more tools become available in the future (for e.g., full-text search for keyword matches). BAML provides a powerful type system that helps LLMs produce the desired outputs, more often than not.
FastAPI for serving
The helper functions that call the BAML client code (interfacing with the LLMs) are exposed as FastAPI endpoints so that they can be used by downstream services, like a frontend that the user can interact with. One of the biggest strengths of BAML is that it can generate client code in multiple languages (TypeScript, Ruby, Golang, etc.), so you don’t need to write the API server in Python if your application is written in another language.
Streamlit for user interaction
Once the API endpoints that provide access to the router agent and vector search tools are made available, it’s straightforward to implement a frontend interface to which a user can ask questions in natural language. An example UI written in Streamlit is shown below. This is for representative purposes only — you can add as much custom functionality as required, in languages other than Python.
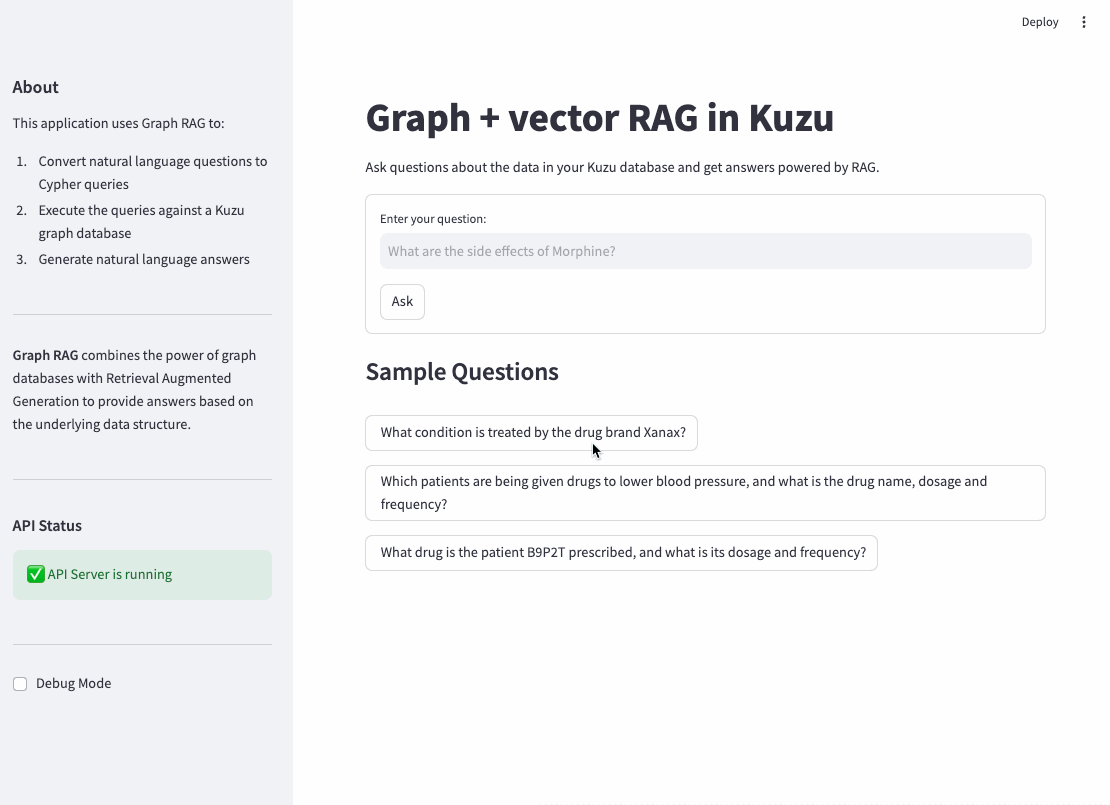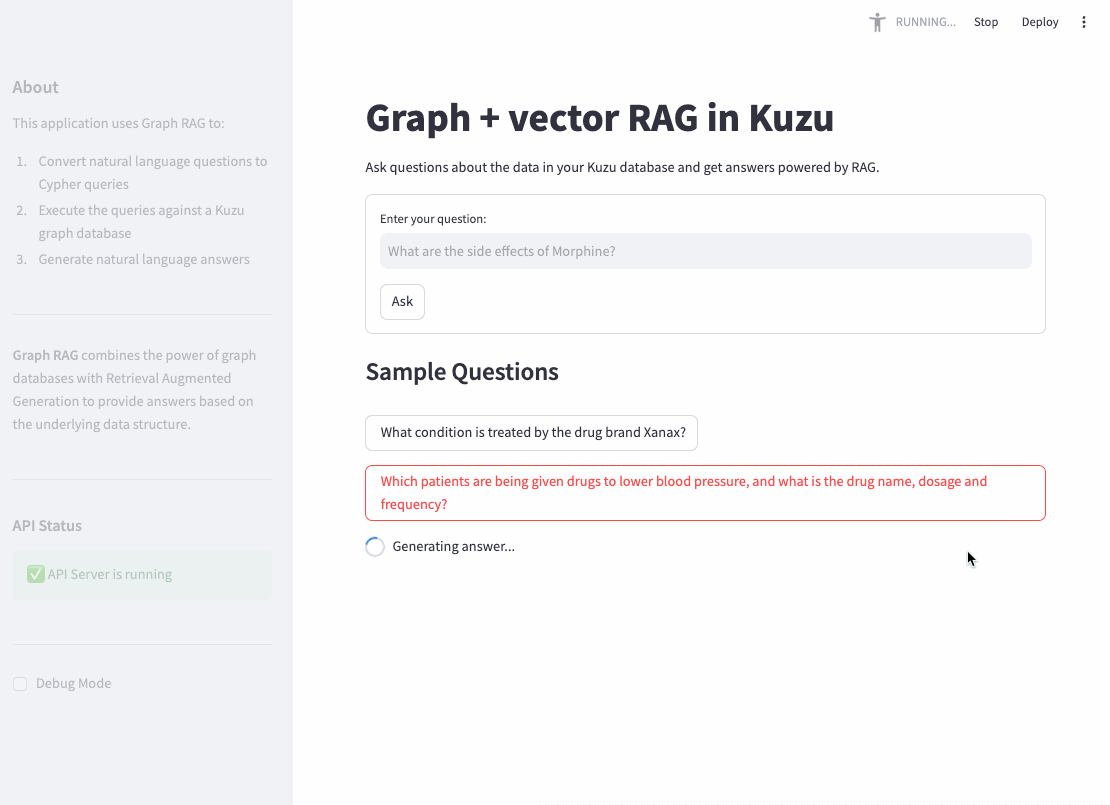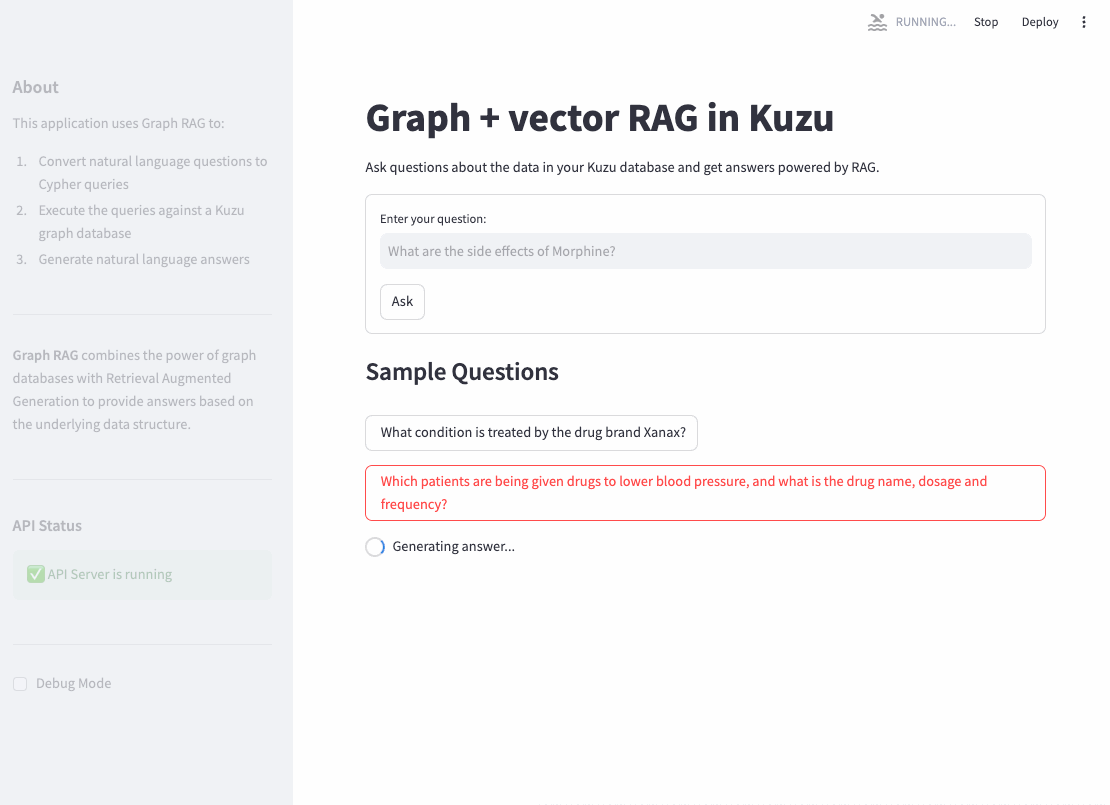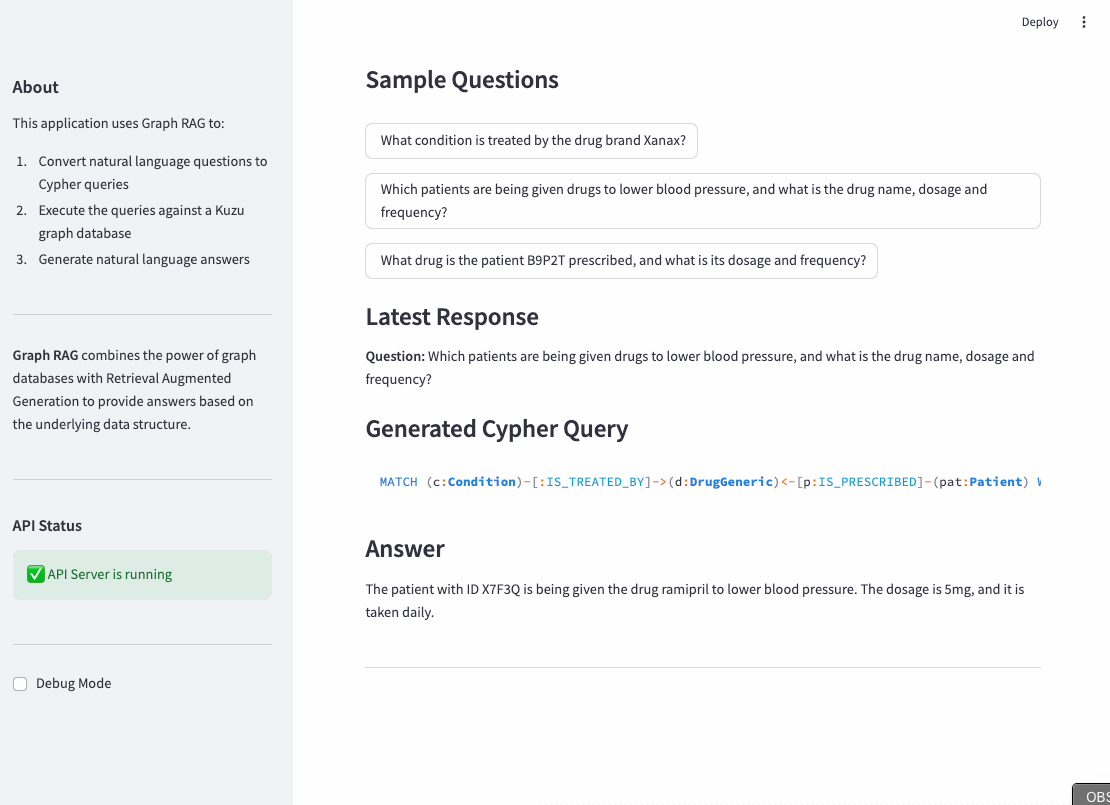
Evaluation
Having put in all this work to build an end-to-end application, an important next step is to evaluate the performance of the agentic workflow in comparison to vanilla Graph RAG over a range of queries. That’s exactly what this section is about!
Test suite
First, we’ll define a test suite of 10 path-like queries, based on an understanding of the data. These are listed below.
| Q1: | What is the drug brand Xanax used for? | sleepy, calm, nerves |
| Q2: | Which patients are being given drugs to lower blood pressure, and what is the drug name, dosage and frequency? | X7F3Q, ramipril, 5mg, daily |
| Q3: | What drug is the patient B9P2T prescribed, and what is its dosage and frequency? | lansoprazole, 30mg, daily |
| Q4: | What are the side effects of the drug brand Ambien? | drowsiness, dizziness, confusion, headache |
| Q5: | What drugs can cause sleepiness as a side effect? | diazepam, morphine, oxycodone |
| Q6: | Which patients experience sleepiness as a side effect? | L4D8Z |
| Q7: | Can Vancomycin cause vomiting as a side effect? | yes |
| Q8: | What are the side effects of drugs for conditions related to lowering cholestrol? | upset stomach, headache, muscle pain |
| Q9: | Which patients experience sleepiness as a side effect?8 | L4D8Z |
| Q10: | What drug brands treat the condition of irregular heart rhythm? | Digitek, Cordarone, Inderal, Pacerone, Lanoxin |
To pass the tests, the LLM must first write syntactically correct Cypher, and once the retrieval from the Kuzu database yields a non-empty response, the answer-generation LLM must then correctly translate the given context into a natural language answer that contains the expected terms.
Note that some queries in the test suite are objectively hard (and borderline impossible) to answer with naive Text2Cypher — they would require some sort of agentic loop. For instance, Q6 and Q7 ask about the side effects “sleepiness” and “vomiting”, but upon inspecting the data, the actual side effects that exist in the Kuzu database are “drowsiness” and “upset stomach”. These types of queries require some form of semantic search to compliment the graph retrieval. Using a router agent with tool-calling can help with this!
To keep the experiments more controlled, the PickTool and AnswerGeneration LLMs are fixed to be the same across all experiments: openai/gpt-4o. Only the Text2Cypher LLM is varied in each experiment. This tells us the following:
- How good is the LLM at generating syntactically correct Cypher?
- How well does the LLM reason about the graph schema and the terms mentioned in the user’s question, to include the right nodes, relationships (including direction) and property values in the generated Cypher query?
As you’ll see in the results below, not all LLMs are created equal, when it comes to Text2Cypher.
Results
The test suite is run as per the code here. The plots below indicate whether the tests passed or failed.
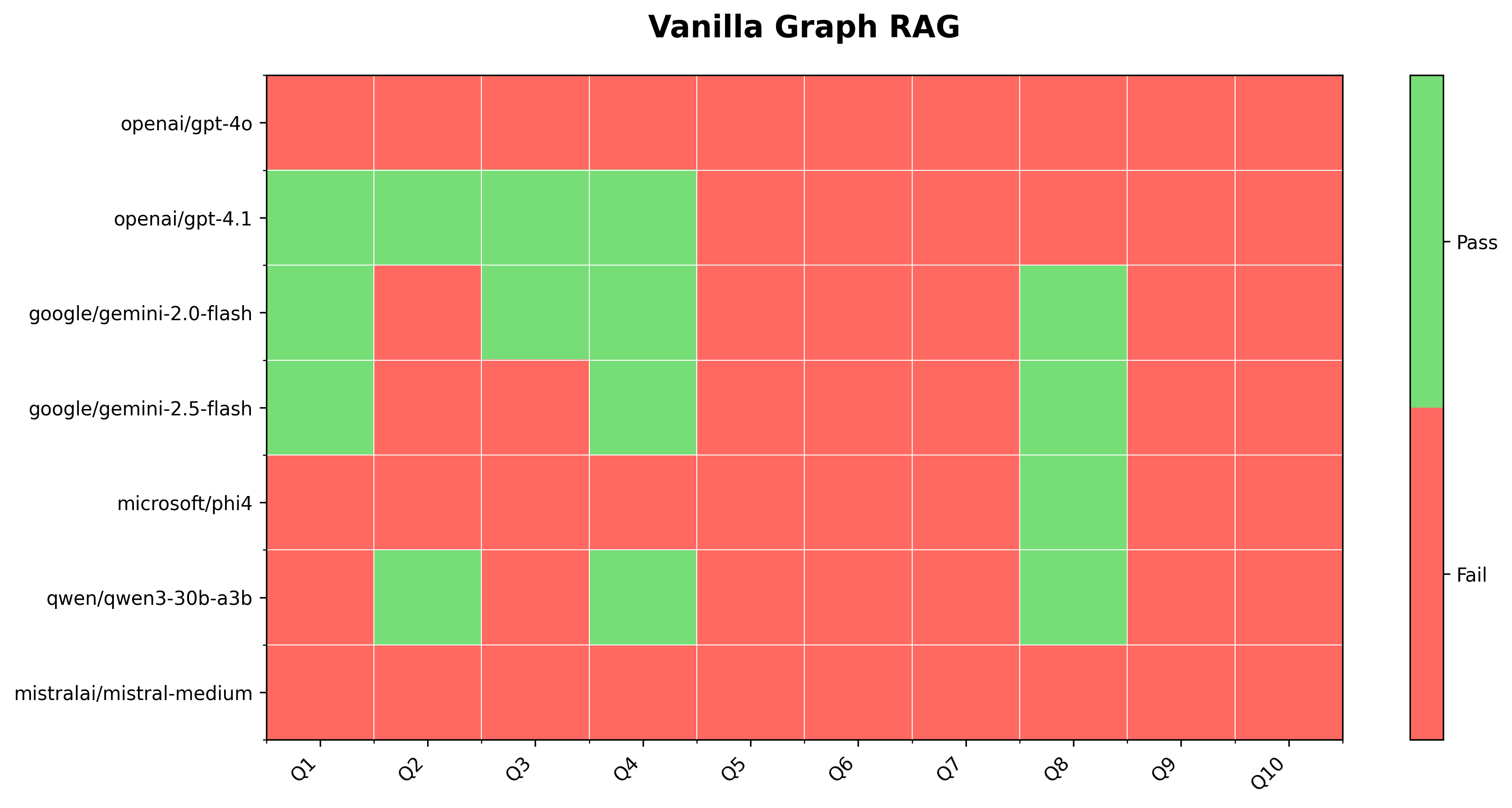
Vanilla Graph RAG
When running vanilla Graph RAG (i.e., a single pass at Text2Cypher), OpenAI’s gpt-4.1 passes the most tests (4/10). Google’s gemini-2.0-flash is the next best model for Text2Cypher in these experiments. A lot of the smaller, cheaper and open source LLMs, like phi4, qwen3-30b and mistral-medium perform markedly worse across all the queries. Certain queries like Q6 and Q7 are not expected to pass, regardless of the LLM used, because these queries reference terms that do not have an exact match in the database (vector search is needed to find similar terms). Under these conditions, gpt-4.1 and gemini-2.0-flash still perform admirably well.
Router-Agent Graph RAG
Now that we have an idea of the baseline case for vanilla Graph RAG, we can get a better sense for the router agent’s performance. The same two models: openai/gpt-4.1 and google/gemini-2.0-flash pass all 10 tests! The next best model is google/gemini-2.5-flash, which passes 9/10 tests. The remaining models perform better than in the vanilla Graph RAG case, but still do not always produce the expected answer, meaning that somewhere in the intermediate stages, the Cypher queries they generated weren’t good enough.
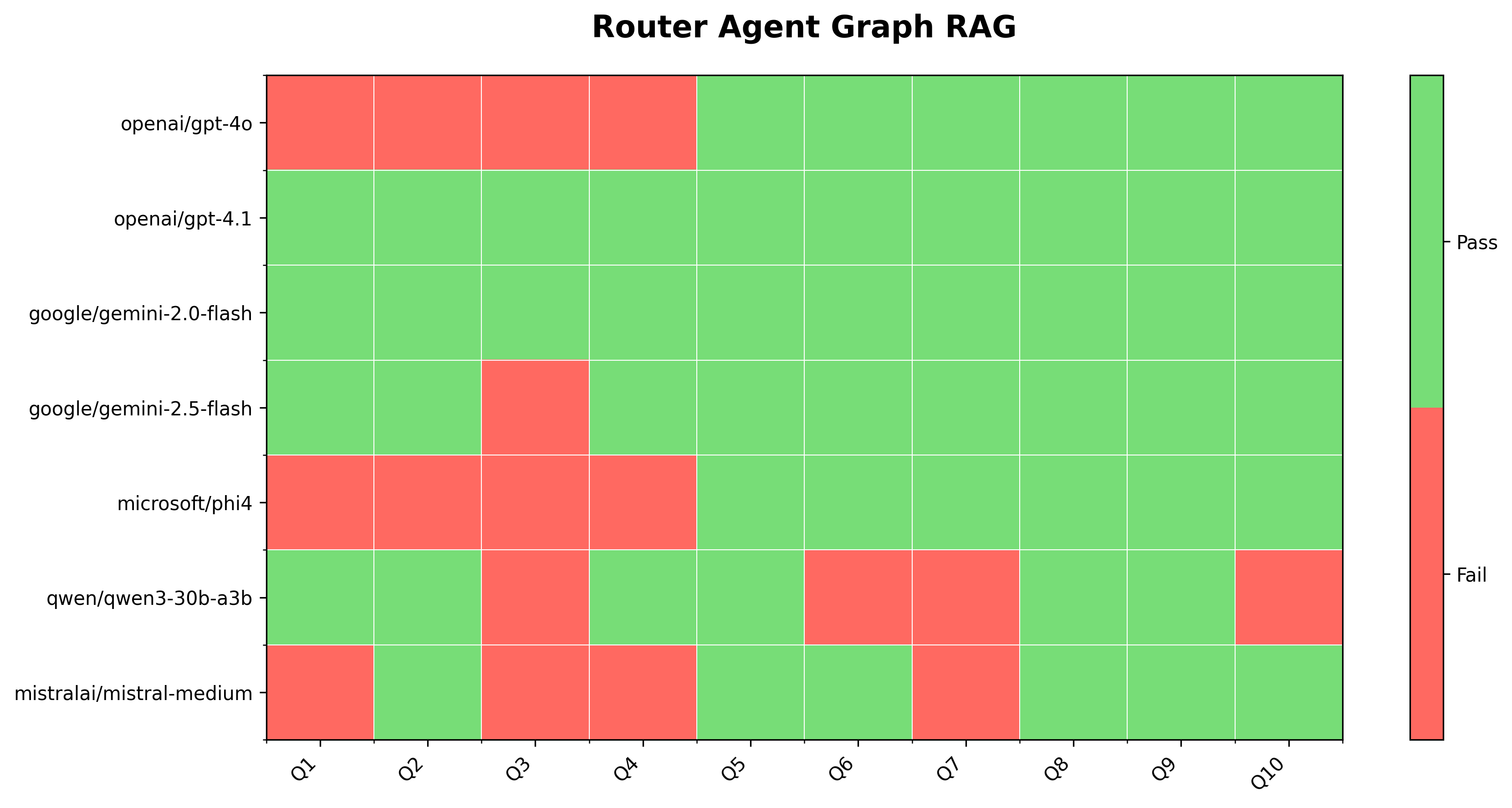
One interesting observation is regarding the only failing test for the google/gemini-2.5-flash model, which several other LLMs pass. Inpecting the BAML logs for this test, the Cypher query generated by google/gemini-2.5-flash is totally wrong — the query is syntactically incorrect, as per the RETURN clause shown below. The syntax error happens repeatedly, even on multiple runs, and only on this query (Q3) with this model. Interestingly, google/gemini-2.0-flash does not suffer from this problem.
// The query below was generated by google/gemini-2.5-flash // It's syntactically incorrect, as per the contents of the `RETURN` clause MATCH (patient:Patient {patient_id: 'B9P2T'})-[:IS_PRESCRIBED {dosage: 'dosage', frequency: 'frequency'}]->(drug:DrugGeneric) RETURN drug.name, IS_PRESCRIBED.dosage, IS_PRESCRIBED.frequencyObservations
The log files from the test suite for each LLM can be seen here. It’s clear that frontier models from well-known providers, such as openai/gpt-4.1 and google/gemini-2.0-flash are good at reasoning on the graph schema to translate the user’s question into a valid Cypher query. The openai/gpt-4o model is significantly worse than openai/gpt-4.1 at Cypher generation, indicating that newer-generation LLMs can be significantly better than older ones, even if they’re released just a few months apart.
To write a syntactically correct Cypher query, it’s important that the LLM has sufficient reasoning ability to understand the property names and the relationship directions — this explains why the smaller, open source models like mistralai/mistral-medium, microsoft/phi4 and qwen/qwen3-30b-a3b perform so much worse (they have less reasoning capabilities than the larger, proprietary models).
A common concern with using large, proprietary LLMs is cost. The following table compares the cost implications of using these models for Text2Cypher.
Tokens in/out
The cost of LLM usage typically depends on the number of tokens going into and coming out of the LLM.
- Text2Cypher tokens in/out (approx.): 400/50
- Answer generation tokens in/out (approx.): 200/80
Cost
The cost numbers for each LLM call are reported on a per-query basis, as well as the estimated “queries per dollar” (QPD), i.e., the number of queries you can run for $1. The answer generation LLM (openai/gpt-4o) is kept constant in all experiments and costs $0.001 on average (1,000 QPD).
| openai/gpt-4o | $0.001 | 1,000 |
| openai/gpt-4.1 | $0.001 | 1,000 |
| google/gemini-2.0-flash | $0.0001 | 10,000 |
| google/gemini-2.5-flash | $0.0003 | 3,333 |
| microsoft/phi4 | $0.00003 | 33,333 |
| qwen/qwen3-30b-a3b | $0.002 | 500 |
| mistralai/mistral-medium | $0.0003 | 3,333 |
Depending on when you read this and what model you use, your cost numbers may be different. However, one thing is very clear: LLMs will continue to become better and cheaper, very quickly, so it’s always worth evaluating the latest models for your use case.
Conclusions
This post covered how to create a vector index in Kuzu and how to expose the function as a tool for an agentic router, with the goal of enhancing the performance of a Graph RAG application. By placing LLMs at appropriate points in the workflow, the performance of the vanilla Graph RAG workflow was significantly improved, across a variety of queries. The results from multiple LLMs were compared to show that the approach can generalize to different LLMs (assuming they have sufficient reasoning capabilities).
Using an agent router that can perform tool-calling, is just the starting point. To build a truly robust and reliable Graph RAG application, a higher degree of autonomy is needed at multiple stages. For example, an “agent loop” can be added to the workflow to allow an LLM to decide whether to run the workflow again, or to end it. Additionally, a “planning agent” could be added to the workflow to break down the user’s question into a series of steps, and then run a series of Cypher queries to answer more complex questions, followed by a “consolidation agent” to synthesize the results into a final answer.
MCP tools
In this example, the vector search tools were exposed as REST API endpoints. This was a simple way to get started, but it’s becoming increasingly common to build custom MCP tools for each specific task, allowing LLMs an easy way to access a variety of tools. For example, a hybrid search MCP tool (that combines vector search and keyword-based search) could provide a more robust and flexible way to discover relevant information in the graph. As more tools get added over time, it’s relatively straightforward to extend the router agent to pick the appropriate tool for the task at hand.
The importance of evaluation
Due to the pace at which the agent and LLM ecosystems are evolving, having a good test suite on which to run experiments and gauge performance, is all the more important for building robust and reliable systems that can leverage the latest tools. Regardless of the complexity of the workflow, it’s always recommended to spend time developing a good evaluation framework that’s unique to your business case. Evaluation does not always have to be deterministic — it could involve having “critic agents” downstream of the LLM’s generated response to subjectively analyze the quality of the response. Or, it could also involve human-in-the-loop (HITL) agents where a human can step in at intermediate stages.
Memory is the next frontier in AI
As more and more systems become agentic in nature, memory is becoming vital. Incorporating memory allows agents to learn from past experiences and adapt to new tasks. Short-term memory, such as conversational memory in the current user session, is only one part of it. Long-term memory (recall) can help agents retain context across different interactions, while also becoming familiar with the user’s preferences over time.
To build these kinds of highly autonomous multi-agent systems, frameworks can help abstract away the code to manage session state, tool calling and memory. Knowledge graphs will also likely play an increasingly significant role in these systems by providing LLMs with structured sources of context. At Kuzu, we’re excited to be following these developments and contributing integrations to this ever-growing ecosystem. Over the coming months, I’ll be exploring and building with some of these agent frameworks, so stay tuned for more posts on this topic!
Join the Kuzu team on Discord to ideate on your next Graph RAG or agentic application!
Code
All the code and data required to reproduce the agent router workflow end-to-end are available in this project’s GitHub repository.

