.png)

Right or wrong, we still believe that we live in a world where traditional HPC simulation and modeling at high precision matters more than mashing up the sum total of human knowledge and mixing it with the digital exhaust of our lives to create a globe-spanning automation that will leave us all with very little to do and a commensurate amount of wealth and power to show for it for both us and those who control AI.
We still think scientists can create nuclear fusion and save the world, and cure cancer and other terrible diseases and save lives, and simulate the entire universe down to subatomic particles and create knowledge and maybe even wisdom. And that is why we still care about the national supercomputing facilities and their academic analogs who are still trying to do the very hard work of advancing the state of the art in simulation and modeling in a world that has gone hyperbolic with GenAI.
The happy confluence of accelerated HPC and early machine learning has long been surpassed, as we have predicted, and now HPC is being bent to the mixed-precision and lower precision ways of AI workloads because the AI tail not only wags the HPC dog, but has grown into a whale that the dog has no choice but to ride.
It is with this in mind that we have been contemplating the future NERSC-10 system that has been out for bid since April 2023 and that was recently awarded to Dell, in deep partnership with compute engine and interconnect juggernaut Nvidia, which is doing all of the heavy lifting in the system if you want to be honest about it.
Hewlett Packard Enterprise was awarded the deals to bring exascale machines to Oak Ridge National Laboratory (with the “Frontier” system in May 2022), Argonne National Laboratory (with the bedeviled “Aurora” system in June 2023, five years late to market after at least two architectural changes), and Lawrence Livermore National Laboratory (with the “El Capitan” system in November 2024). And with HPE having eaten both SGI and Cray, and Dell not normally taking down big HPC system deals, IBM walking away from the HPC systems business it played in for decades (because it cannot make a profit at it), neither Nvidia nor Intel being particularly interested in being prime contractors, and Atos not ever going to be allowed to bid in the national labs of the United States, we assumed HPE was a shoe in for the win here, but with a different compute and networking architecture plugged into its “Shasta” Cray EX system designs.
We turned out to be right about Nvidia getting the win, but did not anticipate that Dell would be the prime contractor. Which is understandable given that Dell doesn’t normally do this.
We have this theory that the US Department of Energy as well as the government lab powers that be in China likes to have multiple suppliers to spread out its risks, and historically the DOE and counterparts in the US Defense Advanced Projects Research Agency (DARPA), which used to fund a lot of supercomputer development in the 1990s and 2000s, used to have a half dozen HPC system makers under contract, often with competing architectures. Nick Wright, NERSC chief architect of the NERSC-10 procurement and lead of the Advanced Technologies Group, tells The Next Platform that this is a nice theory, but that is not how it worked.
“We released an RFP, and we picked the solution that provided the best value for NERSC and its users,” Wright explained succinctly. “It just kind of turned out that way.”
That said, we didn’t think there was a chance that Lawrence Berkeley National Laboratory, which is home to the National Energy Research Scientific Computing Center, would use a variant of the CPU and GPU configurations deployed in Frontier and El Capitan – and there was no way in hell that any national lab was going to bet on Intel’s “Falcon Shores” GPU accelerators after the Aurora delays and Intel’s foundry woes.
We were right about the motors, but apparently not for the logical reasons we cited. It is good to be right, nonetheless.
NERSC, Dell, and Nvidia are not saying much at this point about the NERSC-10 system design, but we have a few data points and some hunches that explain the choice of Dell over HPE as the prime contractor and Nvidia over AMD as the compute engine and interconnect supplier.
The NERSC-10 machine has had a few twists and turns of its own, apparently. The request for proposal (RFP) documents for NERSC-10 came out in April 2023, and the contracts for the system build and non-recurring engineering (NRE) add-ons were expected to be awarded in the fourth quarter of 2024. That obviously didn’t happen, with the NERSC-10 system award being announced on June 2. The NERSC-10 early access system was expected to be installed in 2025, system delivery was slated for the second half of 2026, and full production use was set for 2027 in the original RFP docs.
Here is the original NERSC supercomputer roadmap from that time:
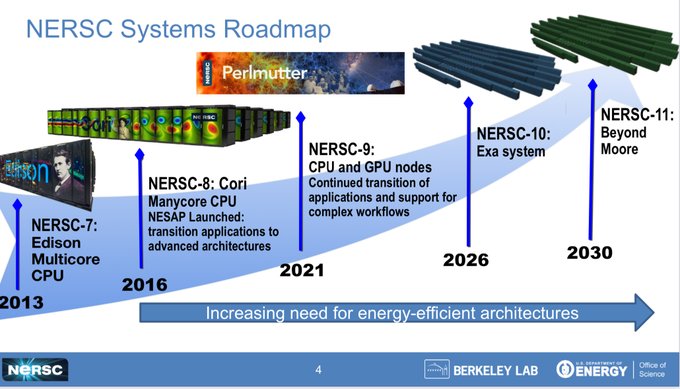
Last October, we caught wind of an updated roadmap that showed an upgrade plan that was quite different for NERSC as well as touched on the plans for the future “Discovery” system at Oak Ridge and the future “Helios” system at Argonne. This showed the current “Perlmutter” NERSC-9 machine, the first Cray Shasta machine to come to market, having its operational life extended by two years, with a NERSC-10 pilot system coming in 2026 and the NERSC-10 machine being operational from the fall of 2028 through the end of 2032. Take a look:
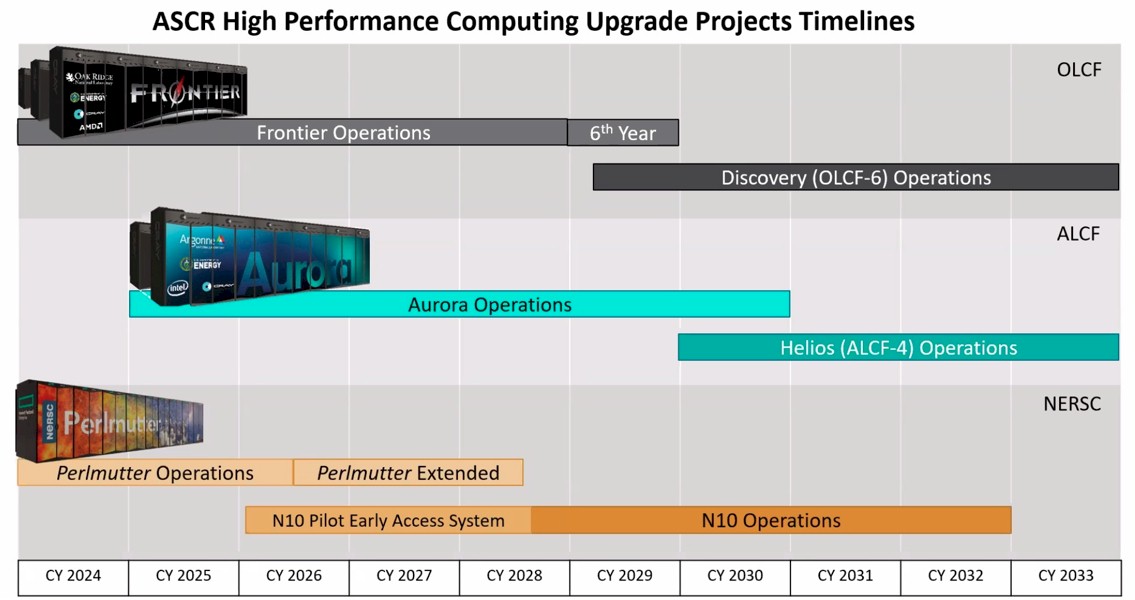
Apparently, somewhere after we posted The Stepping Stones In America To Exascale And Beyond in October 2024, going over this and other roadmaps for the supercomputers at the US national labs, the planned changed back to something more like the original NERSC roadmap above, according to Wright. (No one reached out to us with an update, and the people who published this chart, who worked for Lawrence Berkeley at the time, did not, to our knowledge, update the roadmap further, either.)
In any event, the current plan with the NERSC-10 machine is to get a relatively small test system based on current Nvidia “Grace” CPUs and “Blackwell” GPU accelerators – it is not clear which variant of the Blackwell GPUs – in the fall of 2025, with the full-blown NERSC-10 machine based on future Nvidia “Vera” CPUs and “Rubin” GPUs arriving at LBNL in the fall of 2026.
By the way, we like both synonyms and nicknames, and the NERSC-10 machine is being named “Doudna” after Jennifer Doudna, a biochemist at the University of California at Berkeley who, along with Emmanuelle Charpentier invented the CRISPR method of gene editing. Both Doudna and Charpentier were awarded the Nobel Prize in chemistry in 2020 for this work.
Beyond having Dell as the primary contractor and Nvidia as the supplier of the CPU and GPU compute engines as well as the 800 Gb/sec Quantum-X800 InfiniBand interconnect that will be used to lash the Doudna cluster nodes together, we don’t know much about the system. We did tease out a budget for the system – not the system and the NRE expenses, not the system plus NRE plus an operational budget, but the system budget – as being somewhere between $250 million and $300 million.
For an HPC supercomputer, this is an absolutely respectable budget. In the GenAI boom, this is a starter system in a world that is spending $1 billion or $2 billion for a single system to train the biggest large language models these days. And importantly, that much money does not buy as much aggregate FP64 high precision floating point compute as you might think, as we discussed in Sizing Up Compute Engines For HPC Work At 64-Bit Precision back in February. And that has important implications for how LBNL and other HPC centers will have to rework their applications, creating solvers that use mixed precision to converge to the same answers as algorithms running solely in FP64 mode. Or, possibly using AI techniques to augment HPC applications in other ways.
“As part of the procurement, we released a benchmark suite that had some AI apps in it, as well as some more traditional FP64 modeling and simulation applications,” Wright hinted. “And that led to many discussions with the vendor community along the lines of what you are talking about. And we actually have some interesting innovations in the architecture along those lines. Unfortunately, none of them I’m allowed to talk about at this point.”
The exact plan is intentionally vague, as we think Nvidia does not want to talk to much about the future Rubin GPUs, despite declaring its roadmaps for compute and networking out to 2027 in a very general way. We know that the Doudna system has consume less than 20 megawatts at maximum power draw and fit in a system footprint of 4,784 square feet. This being NERSC, energy efficiency is of the utmost importance and that means liquid cooling of some sort given the expected compute density of Vera-Rubin systems from Nvidia.
What has not changed is the promise of boosting applications that are running on the current Perlmutter system by 10X by switching them to the Doudna system next year. Lawrence Berkeley has a suite of quantum chromodynamics, materials, molecular dynamics, deep learning, genomics, and cosmology applications that are being used to gauge that 10X performance boost. We look forward to seeing how these applications change. If the AI applications are boosted by a lot — multiple factors of 10X — and the HPC applications are boosted by somewhere between 2X and 3X, with others in-between, it could all average out to at least 10X.
This 10X is not just a goal for the increase in peak or sustained flops ratings on the CPUs and GPUs in the system – or more precisely, maybe it was a few years ago, but a 10X increase in FP64 flops is no longer “a given” considering the way GPUs are being architected with a lot of lower precision performance and much less significant increases in FP64 performance. NERSC is also interested in making the Doudna system more directly connected to the science that is being done, and allowing researchers to calibrate their systems and their applications more quickly to gain insights.
Wright explains the plan like this:
“So basically, the idea is, instead of thinking about batch queues and Fortran and file systems of the supercomputing of yesteryear – which we are going to continue to do – we are also looking at coupling the supercomputer as part of a workflow that supports DOE experimental facilities. So it might be a beamline, it might be a genomic sequencer, it might be a telescope.”
“And so then what you need to do is ensure that the data gets in and out of the datacenter to the supercomputer in a timely way, so that you can interpret the data and adjust the angle of diffraction or the object that the telescope points out in the sky, or whatever. What that means is that we are looking at making the whole datacenter programmable. So it’s really about APIs all the way down, and ensuring quality of service, such that your networking traffic gets all the way into the supercomputing without somebody else getting in your way. The data gets to the storage and back in a timely manner, and then the output gets back out again to the experimental resource such that you can turn it around.”
“So it’s a more of an integrated research infrastructure rather than a supercomputer, as one scientific instrument on its own. It’s a scientific instrument that’s also helping other scientific instruments succeed.”
That tells us how Doudna will be integrated more closely with scientific instruments, but it still doesn’t tell us what it might be.
Without knowing the price of the NERSC-10 machine, as no one did last year outside of those making bids, it was hard to guess at an architecture. We now know the price, but we do not know the exact architecture and the nature of the tradeoffs that LBNL is willing to make to get a machine that can be in the field for five years and accelerate the science it is doing by a factor of 10X.
What we know is that the Perlmutter system, which was operational in May 2021, cost $146 million for the system and its support, plus another $4 million in NRE to Nvidia to help with porting codes from CPUs to GPUs. Perlmutter had a CPU-GPU partition with most of its compute and a CPU-only partition for running legacy codes. The hybrid partition of Perlmutter consisted of hosts with AMD “Milan” Epyc 7763 CPUs hosting Nvidia “Ampere” A100 GPU accelerators, with “Rosetta” Slingshot 11 interconnects lashing them all together. The machine had a peak FP64 performance of 113 petaflops and a sustained High Performance LINPACK performance of 79.2 petaflops. We don’t know how much of that $146 million was for hardware and systems software – the system, in our language – and how much was for support. Assume that support was around 15 percent to 20 percent of that price, which is not unreasonable, then the Perlmutter system cost, including networking and storage, was probably somewhere between $117 million and $124 million. Call it $120 million at the midpoint for the Perlmutter system cost.
What we do know, based on what Wright told us, is that the Doudna system will cost between $250 million and $300 million. That is a factor of 2.1X to 2.5X more budget than was allocated to buy Perlmutter. This is a big increase in budget for a five year span, especially for a national HPC center during a time of intense scrutiny on any kind of spending on science, research, and development.
The Blackwell B200 GPU socket had a pair of reticle-limited GPU chiplets compared to a single monolithic GPU for both the Ampere A100 and Hopper H100 GPUs that came before it. The A100 was rated at 19.5 teraflops at FP64 precision on its tensor cores, and the H100 boosted that to 60 teraflops. Oddly enough, the Blackwell B200 – the Blackwell GPU best suited to HPC work – stepped down to 40 teraflops at FP64, and we think the Rubin B200 might be lucky to get to 80 teraflops at FP64 on its tensor cores. So, going from A100 to R200 is a 4.1X jump right there. If Rubin R200 sticks with FP4 as its lowest precision and it only doubles the performance of the Blackwell B200 because it has twice as many chiplets in the socket, then the jump in AI performance from the A100 at 312 teraflops at FP16 precision on the tensor cores to around 20,000 teraflops at FP4 precision on the R200’s tensor cores (again, all in dense matrix mode) is a boost of 64.1X on mixed precision.
That is quite a leap, and the mixed basket of math precisions in applications and boosts from A100 to R200 could average out to 10X pretty tidily.
So just how big will this Doudna system have to be?
A Blackwell B200 probably costs around $40,000 a pop, with a Hopper H100 costing around $22,500 at list price when Nvidia launched it; an Ampere A100 probably cost around $11,000 at list price when it came out. A Rubin R200 might be very pricey indeed – somewhere around $60,000, which is a 50 percent price increase for a device that does 2X the FP64 work and 2X the FP4 work.
If you assume the higher number of $300 million for the Doudna system, and assume further that GPUs will comprise about half of the system cost, you get a mere 2,500 Rubin R200 GPUs at a cost of $150 million, which delivers around 200 petaflops of FP64 performance on the tensor cores in dense matrices but also has 50 exaflops of FP4 performance. Using rackscale nodes with 72 GPU sockets that are memory coherent is not necessary for HPC work, we reckon, but that would occupy only 35 racks, not including storage and networking. Moving to less dense HGX R200 systems in an eight-way memory domain for the GPUs would take up twice as much space, or about 70 racks – again, not including storage and networking.
There are several AI model training companies with 100,000 GPUs in a single system today, machines that cost somewhere between $2 billion and $3 billion to build. These AI model builders are talking about 200,000 GPUs lashed together in systems in late 2025 into 2026, with a goal of 1 million GPUs in the not-too-distant future – costing tens of billions of dollars.
The amount of science such AI behemoths could do is enormous – but that is not what they are going to be tasked with. In the meantime, NERSC is going to be trying to help create sustained nuclear fusion on a shoestring budget. This makes little sense to us, and probably to you, too.
There is a chance, of course, that Nvidia is cutting NERSC a better deal than this, and could end up with a machine that has a lot more oomph than these numbers suggest. A lot depends on how hard Uncle Sam is playing ball and how amenable Nvidia might be to tough tactics if they are being used. Perhaps Nvidia is just going to be smart and proactively give the DOE an excellent deal on this one and fill the NERSC datacenter to its power limit. Assuming 72 Rubin GPU sockets and their surrounding CPUs and network interfaces and such burn about twice as much power as Blackwell GPU sockets, you end up with around 70 racks in 20 megawatts.
Funny coincidence, that.

Sign up to our Newsletter
Featuring highlights, analysis, and stories from the week directly from us to your inbox with nothing in between.
Subscribe now



