.png)

TL;DR
AI companies face unique valuation challenges. Traditional metrics fail to capture displacement risk, capability thresholds, and market creation dynamics specific to AI. This framework provides a structured approach to evaluate what creates and sustains value in AI companies.
We propose a four-level hierarchy: Technical Foundation → Product Depth → Market Position → Sustainability. Each level builds on the previous one. Without technical edge, product integration fails. Without product depth, market position is fragile. Without all three, sustainability is impossible.
The Framework:
| 1. Technical Foundation | Domain Delta | Performance advantage on metrics that buyers actually care about, not just technical benchmarks. |
| Velocity Dynamics | Speed of model improvement relative to the current technological frontier. | |
| Data Advantage | Owning proprietary data that is defensible and survives major model resets. | |
| 2. Product Depth | Job Coverage | Superior performance today PLUS a credible path to achieving full task completeness. |
| Workflow Embedding | Progression of product stickiness: Peripheral → Integrated → Essential → Foundational. | |
| Execution Autonomy | Scale of automation: from suggestions (0%) to full, reliable task automation (100%). | |
| 3. Market Positioning | Capability Thresholds | Technical breakpoints that trigger adoption avalanches (mass-market buy-in). |
| Vertical vs. Horizontal | Choosing between deep specialization (vertical) or broad market applications (horizontal). | |
| Market Structure | Determining if the market will concentrate (2–3 winners) or fragment (hundreds of small players). | |
| 4. Sustainability (Sanity Checks) | The Reset Test | What protects you if GPT-N launches tomorrow with 10× better capabilities? |
| The Net Switch Test | Is the switching friction greater than the switching benefit? | |
| The New User Test | What is our win rate with new users today? |
Not all AI companies play the same game. Four archetypes exist: General-Purpose Foundation Models race for frontier capabilities, Vertical Specialists own industries through trust, Horizontal Applications capture mass markets via distribution, and Infrastructure providers dominate developer ecosystems. The framework applies differently to each.
AI rewards compound advantages. Single moats erode quickly. Sustainable value requires layering multiple defences that reinforce each other. The game has just begun.
1. Introduction: Why AI Needs a Different Framework
1.1. The Problem with Traditional Approaches
SaaSvaluation relies on predictable metrics: CAC/LTV, retention, growth rates. These assume stable markets, gradual innovation, and clear competitors. AI breaks these assumptions.
In AI, a new model release can make your product obsolete overnight. Markets don’t exist until capabilities create them. Competition comes simultaneously from startups, incumbents, and tech giants. Adoption happens in sudden jumps, not smooth curves.
Consider Jasper AI. In 2022, it was valued at $1.5B with strong metrics. Six months later, ChatGPT made its core offering nearly worthless. Traditional frameworks couldn’t predict this. The product didn’t gradually erode; it became irrelevant overnight when OpenAI crossed a capability threshold.
1.2. The Unique Dynamics of AI
Two characteristics fundamentally distinguish AI from traditional software markets:
-
Displacement Risk: Unlike SaaS where features erode gradually, AI companies face overnight obsolescence from capability jumps. Stability AI lost its edge when Midjourney and DALL·E 3 leapfrogged it in quality. Dozens of GPT-3 copywriting startups vanished when GPT-4 made their templates irrelevant.
-
Capability-Driven Market Creation: Traditional analysis assumes markets exist, but demand is endogenous in technology, In AI, capabilities create markets from nothing. Before November 2022, nobody budgeted for “AI assistants” because ChatGPT hadn’t created the category yet. Before ElevenLabs crossed the human-voice threshold, “AI dubbing” wasn’t a line item.
1.3. The Four Games in AI
Not all AI companies face the same dynamics. Four main distinct archetypes exist, each with different rules:
-
General-Purpose Foundation Model Labs (OpenAI, Anthropic, Mistral)
-
Vertical AI Specialists (Harvey, Jimini, Raidium, PriorLabs, Elevenlabs)
-
Horizontal AI Applications (Perplexity, Cursor)
-
AI Infrastructure (Scale AI, Weights & Biases, Orq.ai)
| Examples | OpenAI, Anthropic, Mistral | Harvey, Raidium, PriorLabs, ElevenLabs | Perplexity, Cursor | Scale AI, Weights & Biases, Orq.ai |
| Game / Objective | Push the frontier of what’s possible | Own a specific industry/modality | Capture the mass market with superior UX | Become the ‘picks and shovels’ |
| Currency / Key Asset | Talent density and capital access | Domain expertise and trust | Distribution velocity & Brand | Developer adoption and ecosystem position |
| Key Risks | Being taken over by the next GPT-N | Limited adoption, market fragmentation | Competition, platform giants | Cloud providers adding your feature |
1.4. Our Approach
This framework addresses these dynamics through four hierarchical levels:
-
Technical Foundation: What unique capabilities exist and can they survive resets?
-
Product Depth: How do capabilities become indispensable in workflows?
-
Market Position: What market dynamics favor or threaten the position?
-
Sustainability: Will the advantages compound or erode over time?
Each level depends on the previous ones. Technical edge without product integration remains academic. Product without market understanding is blind. All three without sustainability tests is wishful thinking.
2. [Part I] Technical Foundation
Technical advantage in AI differs fundamentally from traditional software. It’s not about having more features or better UI. It’s about performance gaps that survive resets, improvement velocity that outpaces alternatives, and data advantages that compound over time. These three elements: (i) Domain Delta, (ii) Velocity Dynamics, and (iii) Effective Data Advantage form the technical foundation.
2.1 Domain Performance and Evolution
2.1.1. Domain Delta (ΔD)
Definition: Domain Delta measures the performance advantage on metrics buyers actually care about, tested under real-world production constraints.
Why it matters: Customers care about performance on their specific tasks under their specific constraints. A model that’s 99% accurate but takes 30 seconds is worthless for real-time applications. Academic papers with state-of-the-art results are promising signals, but they’re not sufficient for commercial success. The performance gap is especially important as the business use case criticality increases.
What it measures: The gap between your performance and the next-best alternative, specifically on customer-relevant metrics under production constraints like latency, cost, and compliance requirements.
Drivers: task-specific optimisation that goes beyond general models, training that accounts for real-world constraints, domain expertise encoded into the system, and rigorous testing in production environments rather than lab conditions.
Archetype variations:
- General-Purpose Foundation Models: Must match frontier capability pace (3-4 month major releases) or become obsolete
- Vertical Specialists: Can improve models slower if domain advantage is strong enough
- Applications: Decouple product velocity from model velocity; they can use same model for months while shipping weekly UX/feature improvements
- Infrastructure: Tool performance improvements decoupled as well: underlying models can be stable
Failure mode: Without meaningful Domain Delta, customers default to cheaper, more accessible general models. The company loses pricing power and faces rapid commoditisation as open-source models catch up.
Example: Raidium’s Curia model in radiology. Its published benchmarks show state-of-the-art performance in detecting pathologies across multiple imaging modalities. Crucially, Curia demonstrates these gains while meeting clinical constraints on inference cost and latency, the criteria that matter to hospitals and radiologists. Domain delt is tangible: outperforming both open-source and commercial models on the buyer’s terms.
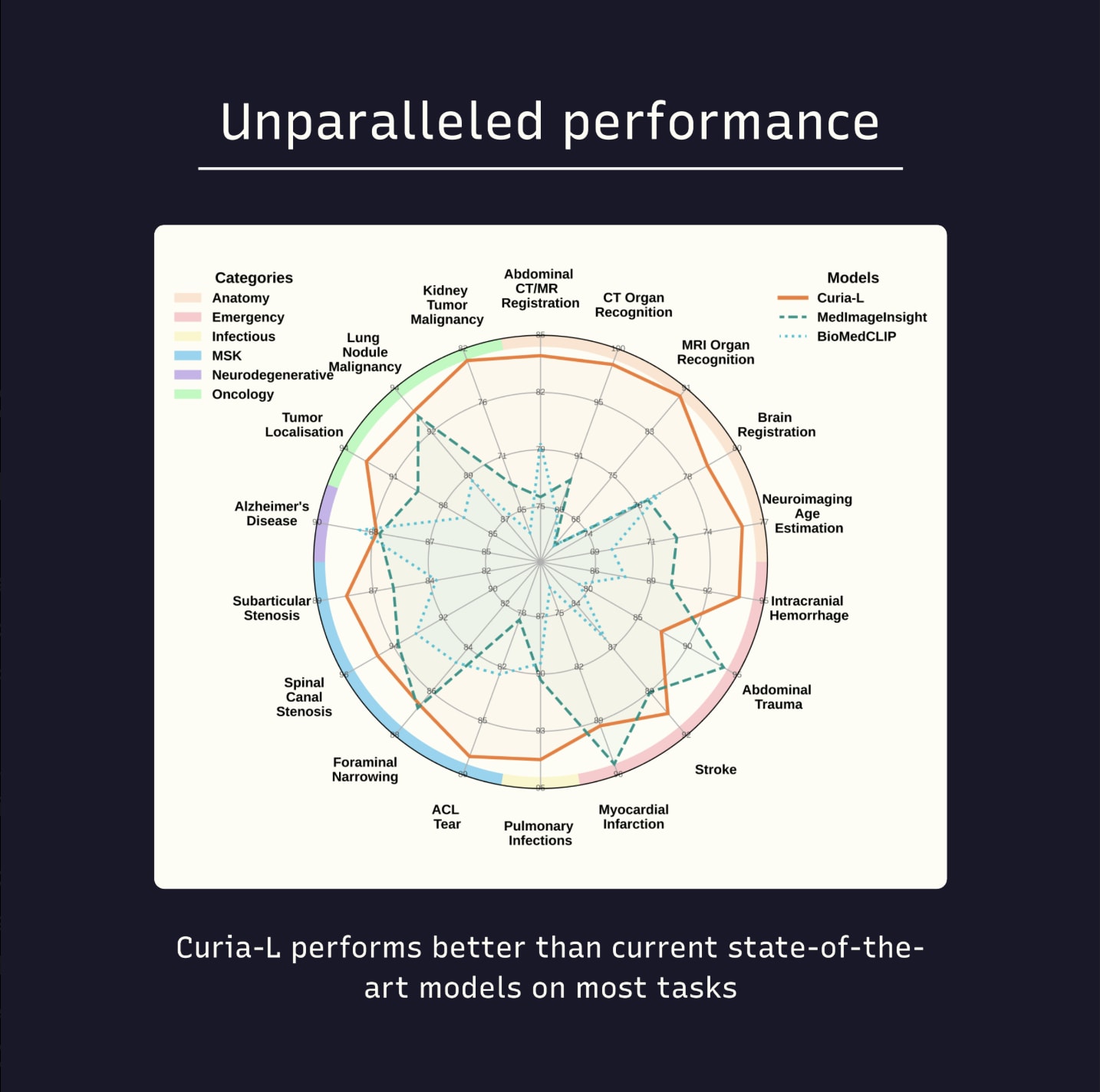
Benchmark for Curia vs frontier/open models on buyer-relevant tasks (latency/cost annotated) - source
2.1.2. Velocity Dynamics
Definition: The rate of improvement relative to the frontier and direct competitors.
Why it matters: In AI, static advantage erodes quickly. What determines survival isn’t your current position but whether you’re improving faster than alternatives. A company with lower performance today but higher velocity will eventually overtake a complacent leader.
What it measures: The frequency of meaningful improvements, performance gains per release cycle, speed relative to both frontier models and direct competitors, and momentum in market perception.
Signals include: release cadence (whether weekly, monthly, or quarterly), new capability additions with each update, measurable performance improvements, and critically, where new users are going when they enter the market.
Velocity requirements by archetype:
- General-Purpose Foundation Models: Must match frontier pace (3-4 month cycles) or become irrelevant
- Vertical Specialists: Can be slower (6-12 months) if deeply embedded
- Applications: Need weekly/monthly updates to maintain (and increase) user engagement
- Infrastructure: Quarterly releases acceptable if APIs remain stable
Examples:
-
Perplexity improves daily, with constant iteration based on user behavior and feedback
-
Orq.ai enables its customers to achieve 2-3x faster improvement cycles through better evaluation infrastructure, accelerating their own velocity
Failure mode: Companies with slow improvement cycles face gradual then sudden irrelevance as competitors pull ahead. Even a strong starting position can’t save you if your velocity is lower than the competition.
2.1.3. Effective Data Advantage (EDA)
Definition: The quality, uniqueness, and defensibility of data pipelines that create lasting competitive advantage.
Why it matters: Models commoditize quickly as techniques spread and compute becomes accessible. Data remains one of the few sustainable moats in AI. Proprietary data that competitors can’t access or replicate can maintain advantage even as foundation models improve.
What it measures: The exclusivity of data access, quality and relevance of the data to your specific use case, refresh rate that keeps data current, and ability to generate synthetic data that actually improves performance.
Critical components include: exclusive access through contracts, partnerships, or privileged channels that others cannot replicate; quality pipelines with superior annotation, curation, and verification systems; refresh mechanisms that continuously collect new data from users or systems; synthetic leverage that can generate useful training data without degrading model quality; and critically, robust data supply chains that avoid legal exposure, licensing traps, provider dependency and provenance uncertainty.
Example: PriorLabs’ TabPFN uses millions of synthetic datasets, generated via structural causal models, to pre-train its foundation model over diverse tabular prediction tasks. This gives enormous SLF: it achieves state-of-the-art performance on small datasets with minimal training, bypassing the need for vast proprietary tabular corpora, while sustaining ΔD.
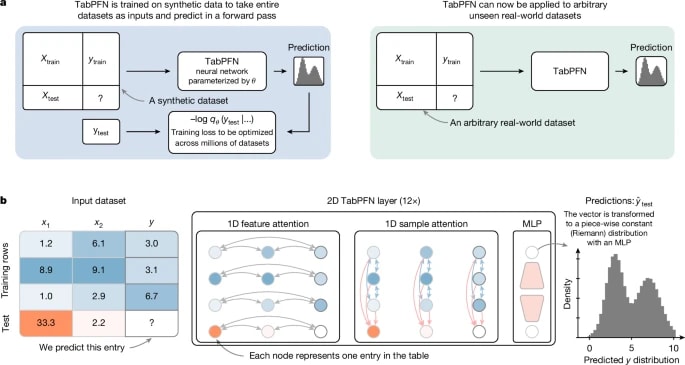
Figures: TabPFN’s pre-training on million on synthetic datasets (above) + performance vs tuned baselines (below). Highlights how synthetic SLF allows strong ΔD even in small datasets, and how public vs tuned baselines are surpassed.
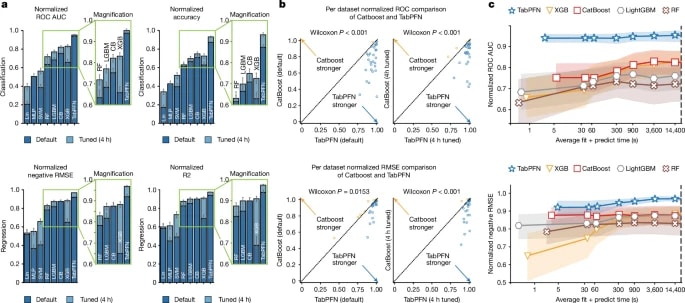
Failure mode: Dependence on public data means your advantage erodes as soon as competitors or open-source models train on the same sources. Without EDA, you’re in a race to the bottom on model performance.
2.2. Displacement Vulnerability
Every AI company faces existential threats from two directions: sudden capability jumps that reset the entire playing field, and platform giants that could absorb entire categories. Understanding these threats and building defences against them separates temporary leaders from durable winners.
2.2.1. Capability Displacement
Definition: The risk that a technical breakthrough makes your entire value proposition obsolete.
Why it matters: AI doesn’t evolve gradually. Each major model release can eliminate entire categories of companies overnight. GPT-3.5 to ChatGPT wasn’t an incremental update, it was a category killer that destroyed thousands of startups. This pattern repeats with each frontier model release, and accelerated dramatically in late 2024 with DeepSeek and other Chinese labs demonstrating that architectural innovations could match frontier performance at radically lower costs. The threat is now global, increasingly open source, and driven as much by efficiency breakthroughs as raw capability gains.
To assess vulnerability, one should ask two critical questions:
-
‘What technical advance would eliminate my advantage?‘
-
‘What would remain valuable after that advance occurs?‘
Valid defences against displacement include: proprietary data that new models cannot access, deep workflow integrations, trust and relationships that transcend technical capabilities, and regulatory moats that take years for competitors to cross.
Examples:
-
Jasper AI built its business on GPT-3’s need for templates and structured prompts. When ChatGPT could handle freeform requests, Jasper’s entire value proposition evaporated, after having raised $100m and reached $90m in ARR.
-
Character.ai had unique memory systems that differentiated it. When GPT-4 arrived with vastly larger context windows, that differentiation largely disappeared. Survivability depends on whether companies own their infra, some form of switching resistance, and providing real value beyond GPT prompts.
-
Tome built AI-generated slide decks and reached a $300M valuation with zero revenue. When Microsoft integrated similar generative capabilities directly into PowerPoint, Tome’s differentiation vanished. The episode highlights the risk of building on features that incumbents can easily absorb through native integration.
2.2.2. AI Giants Threat
Definition: The risk that giants like OpenAI, Anthropic, Google, Microsoft, or Meta enter your space and absorb your market.
Why it matters: The “what if Google builds it” (and its newer version “what if OpenAI builds it”) fear is often overblown, giants rarely build “niche” solutions. Generating a few hundred million dollars of annual revenue is niche at their scale. However, they can still destroy companies through acquisition dynamics, platform dependency changes, or eventual market entry if the opportunity becomes large enough. Understanding which threat you actually face shapes your defence strategy.
Assessment framework:
-
Market size threshold: Giants need billion-user opportunities to justify investment. The more specialised your solution, the less attractive your market segment.
-
If your TAM is under $10B, you’re likely safe from direct competition. Focus on building a niche monopoly
-
Between $10-100B, you might become an acquisition target. Competition will come mostly from other startups (and legacy players).
-
Above $100B, expect direct competition. Build a unique, durable competitive moat (data, network, embedding).
-
-
Platform dependency exposure: The hidden killer isn’t competition but dependency. When platforms change pricing or policies, dependent startups often die overnight, as happened with Twitter API changes, Google SEO algorithms, or GPT wrapper companies after ChatGPT. Assess your reliance on:
-
APIs (OpenAI, Claude, Gemini),
-
distribution channels (app stores, marketplaces, cloud platforms),
-
and data feeds (search results, social graphs).
-
-
Acquisition dynamics: Sometimes the threat isn’t competition but forced acquisition at unfavourable terms. Is the company more valuable to them as an independent company or absorbed into their ecosystem? Think Microsoft with GitHub, Google with DeepMind, or Facebook with Instagram.
Risk by archetype:
- General-purpose foundation models: Direct competition likely
- Vertical Specialists: Acquisition more likely than competition
- Applications: High platform risk if in their path
- Infrastructure: Medium risk, often become acquisition targets
The key insight: Giants typically buy rather than build, focus on billion-user markets, and often kill companies through platform changes rather than direct competition. The real question isn’t “will they build it?” but “will they buy my competitor?” or “will they change the rules I depend on?”
3. [Part II] Product Depth
Technical advantage without product depth is just an impressive demo. The most sophisticated AI means nothing if users don’t integrate it into their daily work. Product depth transforms capabilities into indispensable tools through workflow embedding and execution autonomy.
3.1. Workflow Integration
3.1.1. Job Coverage Excellence (JCE)
Definition: The combination of superior performance on critical tasks today AND a credible path to complete job coverage tomorrow.
Why it matters: Buyers don’t need feature parity to switch. They need two convictions: (1) the AI solution already outperforms on their most painful problems, and (2) it will inevitably expand to handle everything else. This dual assessment (current superiority on what matters + future completeness) drives adoption decisions.
This JCE equation has two core components, which are typical questions from corporate buyers:
-
Current Strategic Advantage: Does AI solve a few tasks that create 80% of value better than incumbents? Think: most time-consuming and repetitive work, high error-prone processes, bottlenecks limiting growth, and/or the tasks requiring scarce expertise
-
Expansion Credibility: Will you cover the entire feature set desired by clients? Buyers evaluate: architecture flexibility and integration (more below), development velocity (how fast are they shipping?), vision alignment (do they understand the full job and it?), resources in hand or ability to secure them (enough capital to build?)
Examples:
-
Vanta began with SOC 2 compliance but credibly promised to become the entire security and compliance platform
-
Ramp began with expense management (20% of CFO stack) but credibly expanding to full finance suite
Failure mode: Trying to match incumbents feature-for-feature from day one, diluting focus on strategic superiority and slowing time to market.
3.1.2. Workflow Embedding (WE)
Definition: The degree to which a product becomes embedded in critical business workflows and processes.
Why it matters: Peripheral tools are easily replaced when something better comes along. Deeply embedded systems become indispensable to operations. The deeper the integration, the higher the switching costs and the stronger the competitive moat. In AI particularly, building context over time (understanding user patterns, accumulating corrections, learning domain-specific terminology) creates compounding value that new entrants cannot replicate.
Products exist on a spectrum of embedding:
-
Peripheral: Tools are used occasionally when convenient.
-
Integrated: Products become part of regular workflows but aren’t critical.
-
Essential: Systems would cause significant disruption if removed.
-
Foundational: Entire business processes built on top of them.
| Peripheral | Tools used occasionally when convenient. | No critical data stored; no processes depend on them. | Essentially zero. Users can try alternatives with no effort. | ChatGPT, and Midjourney (casual use) |
| Integrated | Becomes part of regular workflows but is not critical. | Some data and context accumulated. AI learns user preferences and patterns. | Requires days of adjustment and loss of accumulated context. | GitHub Copilot, Grammarly (for professional writers) |
| Essential | Removal causes substantial disruption. Deep process dependencies and data lock-in. | Years of context and training make the AI uniquely valuable. | Requires weeks of migration and retraining, plus permanent loss of accumulated AI context. | Notion (for knowledge workers storing documentation) |
| Foundational | Products have entire business processes built on top of them. Impossible to remove without transformation. | Years of customer history or unique analytical patterns learned. | Months, almost impossible without destroying organizational knowledge. | Salesforce (for sales teams), Palantir (for intelligence agencies) |
Embedding patterns by archetype:
- General-purpose Foundation Models: Often stay peripheral (API calls)
- Vertical Specialists: Must reach “Essential” or die
- Applications: Success requires “Integrated” minimum
- Infrastructure: “Foundational” is the only winning position
Example: Darktrace in cybersecurity doesn’t just monitor, it integrates with Active Directory, cloud platforms, and network infrastructure, learning normal behavior patterns unique to each organisation over months
3.1.3. Execution Autonomy (ACS)
Definition: The percentage of a job that the system executes autonomously without human intervention.
Why it matters: The gap between AI that suggests and AI that executes is a key component of value creation (and ability to capture it). Suggestion tools might save time, but they’re far less valuable than supervised execution or even better, fully autonomous execution.
The autonomy spectrum progresses through distinct levels: suggestion only, human-in-the-loop, semi-autonomous and fully autonomous.
| Suggestion Only | Provides recommendations; executes no actions. | Makes all decisions and executes all actions. | Limited to time savings from better information. |
| Human-in-the-Loop | Proposes specific actions and executes them upon approval. | Approves each specific action proposed. | Gains in efficiency and reduced manual effort. |
| Semi-Autonomous | Executes routine tasks within defined boundaries (rules). | Handles exceptions and edge cases. | Real labor replacement (partial automation). |
| Fully Autonomous | Handles end-to-end execution of the entire task. | Audits and monitors final results. | Complete transformation of work and processes. |
Moving up this spectrum requires meeting increased trust, based on objective and perceived reliability: accuracy thresholds, regulatory approval where required, insurance and liability coverage, and cultural acceptance of AI decision-making.
Example: Relief AI moves beyond recommendations by generating advanced invoices, rooted on the users’ knowledge base.
3.2. Distribution and Network Effects
3.2.1. Distribution Power
Definition: The efficiency and defensibility of how a product spreads within and across organisations.
Why it matters: In AI, distribution often matters more than technology. The best model with poor distribution loses to good-enough models that spread effectively. Many technically superior products fail because they can’t distribute efficiently.
Three dynamics determine distribution success: entry, spread & lock-in.
| 1. Entry Dynamics | Defines how easily you land initial users and begin adoption. Low Friction: Free trials, Product-Led Growth (PLG), viral features |
High Friction: Enterprise sales cycles Slower adoption, increases initial stickiness and contract value. |
| 2. Spread Mechanics | Defines how usage grows after initial entry into the organization or market. Viral Spread: Users naturally invite others Organic Spread: Value visibility drives adoption |
Mandated Spread: Top-down organizational rollouts e.g. standardizing an internal tool. |
| 3. Lock-in Strength | Measures how hard it is to leave the product once adopted. Technical Lock-in: Due to data storage, integrations, or proprietary formats. Social Lock-in: Team workflows and collaboration depend heavily on the tool. |
Skill Lock-in: Users invest time in learning specialized interfaces and features. Goal: Increase the collective effort required to switch. |
Examples of strong distribution:
-
Cursor enters through individual developers trying it solo, spreads when teams see productivity gains, then locks in through shared workspace configurations
-
Contrast lands rapidly because it is available in HubSpot’s marketplace, bypassing long procurement cycles. Their webinar outputs also act as viral artifacts, creating inbound demand from shared recordings.
3.2.2. Network Effects in AI
Definition: Value multiplication effects where each additional user, data point, or integration makes the product more valuable for all participants.
Why it matters: Network effects create compound defensibility. Unlike feature advantages that erode, network effects strengthen over time. They’re one of the few moats in AI that actually get deeper with scale.
AI creates unique types of network effects (NFX): data, workflow, ecosystem a learning.
| 1. Data | Proprietary data from each user directly improves the underlying AI Model for everyone. | The model’s accuracy, core performance, and intrinsic quality. | Grammarly (corrections), Waze (traffic routing), Scale AI (labeling accuracy). |
| 2. Workflow | Deep embedding into mission-critical business processes (SaaS/B2B adoption). | The Switching Cost for the user/organization becomes extremely high. | Notion (personal notes into company knowledge), Slack (single team → entire organization). |
| 3. Ecosystem | Third-party developers multiply value by building external complementary tools on the platform. | The platform’s overall utility and market scope. | ChatGPT’s plugin ecosystem, LangChain’s library, Hugging Face’s model hub. |
| 4. Learning | The system learns from collective usage patterns to predict preferences for all users. | The quality of prediction, recommendations, and personalisation. | Spotify (recommendations), TikTok’s algorithm (engagement prediction). |
Network effect potential by archetype:
- General-purpose Foundation Models: Strong data network effects from RLHF
- Vertical Specialists: Limited to workflow network effects within industry
- Applications: Full spectrum possible (data, viral, ecosystem)
- Infrastructure: Developer ecosystem effects critical
Example: Hugging Face’s model hub creates all four network effects:
- Data: 500k+ models improve through community feedback
- Workflow: Integration in one project drives adoption in others
- Ecosystem: 15,000+ contributors create value
- Learning: System learns optimal model recommendations
Result: 10M+ users, $4.5B valuation despite no proprietary models
4. [Part III] Market Positioning & Competitive Dynamics
Markets in AI behave unlike traditional software markets. They can remain dormant for years, then explode overnight when capabilities cross critical thresholds. They can evolve toward winner-take-most dynamics or fragment into countless specialties. Understanding these patterns determines strategic choices.
4.1. Market Creation
4.1.1. Capability Thresholds
Definition: Technical break points that trigger mass market adoption.
Why it matters: AI markets don’t grow linearly. They exhibit step-function adoption, staying flat for years then exploding when capabilities cross critical thresholds. Companies that time these transitions capture enormous value. Those that arrive too early burn capital educating the market. Those that arrive late find entrenched competitors.
Three types of thresholds trigger adoption:
-
Performance thresholds activate when accuracy crosses 95% for medical diagnosis, latency drops below 100ms for real-time applications, or reliability exceeds 99.9% for production systems. Each market has specific break points where “not quite good enough” suddenly becomes “good enough for production.”
-
Cost thresholds unlock markets when AI becomes 10x cheaper than alternatives, when cost drops below value created making ROI obvious, or when marginal cost approaches zero enabling new use cases. Price points that seemed impossible become inevitable. Voice models did not spread before for a reason of performance but also because of costs per minute.
-
Ease thresholds democratise adoption when no training is required, natural language interfaces eliminate learning curves, or single-click deployment removes technical barriers. Complexity that limited AI to specialists disappears.
Examples:
-
Voice AI existed for decades as robotic text-to-speech. When ElevenLabs crossed the “indistinguishable from human” threshold in 2022, the market exploded from millions to hundreds of millions in 18 months
-
Code completion was a novelty for years. When GitHub Copilot crossed the “actually helpful more than annoying” threshold in 2021, it transformed software development
-
Image generation was an academic curiosity. When Midjourney crossed “professionally usable” quality in 2022, it disrupted the creative industry
Identifying approaching thresholds requires watching multiple signals: performance improvement curves steepening toward critical points, early adopters beginning to succeed with real use cases, platform giants starting to pay attention through partnerships or acquisitions, and explicit customer demand asking when capabilities will be ready.
4.1.2. Adoption Patterns
Definition: How markets adopt AI solutions based on their tolerance for imperfection and need for reliability.
Why it matters: Different markets have fundamentally different adoption patterns. Understanding your market’s pattern determines everything: go-to-market strategy, pricing model, product development priorities, and funding requirements. Misreading the pattern wastes resources and time.
Markets fall into distinct categories:
-
from “Good Enough” Markets that accept 80% accuracy because errors are tolerable, quality is subjective, or the use case is creative rather than critical. These markets adopt quickly through viral consumer spread. Content creation, design tools, and research assistants thrive here. The strategy is to move fast and prioritize reach over perfection.
-
to “Excellence Required” Markets that demand 99%+ accuracy because errors have serious consequences. These markets adopt slowly through careful enterprise evaluation. Healthcare, finance, and legal applications face this bar. The strategy requires deep expertise, compliance focus, and patient trust building.
Imminent adoption reveals itself through step function indicators. When early adopters concentrate usage, the product clearly works for someone. When major friction points are identified with clear problems to solve, opportunity crystallises and the market expands.
4.2. Strategic Positioning
4.2.1. Vertical vs Horizontal Strategy
Definition: The fundamental choice between depth in one domain versus breadth across many.
Why it matters: This choice cascades through every strategic decision. It determines product architecture, go-to-market approach, funding requirements, team composition, and exit opportunities.
Note: This choice is largely predetermined by archetype. General-purpose Foundation Models and Applications typically go horizontal. Specialists are vertical by definition. Infrastructure can go either way: Weights & Biases (horizontal) vs Ironclad (vertical for legal).
| Market Scope | Limited to a single industry (sometimes a few), which caps growth potential. | Massive (all industries and geographies) offers rapid scaling potential. |
| Core Advantages | Genuine moats via domain expertise and regulatory barriers; specialised value commands premium pricing; clear roadmap. | Massive TAM; rapid, viral growth potential; multiple expansion paths; potential for platform-driven network effects. |
| Core Disadvantages | TAM is limited; long sales cycles with conservative buyers; high concentration risk if the industry struggles; fewer exit options. | High platform vulnerability (easy for giants to copy); constant commoditisation pressure; shallow differentiation; intense competition. |
| Requirements for Success | Deep Domain Knowledge (takes years); specialized data access via exclusive partnerships; senior industry relationships; patience for slow, sticky adoption. | Superior User Experience; effective viral distribution mechanics; speed to market; significant capital for growth and defense. |
It’s worth noting that there are nuances between horizontal and vertical. Horizontal players tend to build adapted to certain industries, think of Dataiku which is a horizon platform but which provides specific offerings for banking, retail, manufacturing, insurance, public sector or utilities & energies. Also vertical players tend also to expand not only geographically but in adjacent markets, from very adjacent buyers (eg: from lawyers to notaries) or very different verticals relying on common resources (eg: from people transportation to food deliveries).
4.2.2. Market Structure Evolution
Definition: How markets naturally evolve toward concentration or fragmentation based on underlying economics and network effects.
Why it matters: Trying to anticipate where your market will end up guides strategic decisions. If your market concentrates into 2-3 winners, you must race for dominance or face elimination. If it fragments into hundreds of specialists, you can build steadily in your niche. Misreading terminal structure leads to wrong strategy.
Key parameters predicting concentrations: Network Effects Strengths, Data Flywheel Dynamics, Switching Costs Magnitude, Capital Requirements, Standardisation Potential, Regulatory Complexity, Economies of Scale.
| 1. Network Effects Strength | Strong network effects create winner-take-most dynamics. | Weak or non-existent network effects. | Concentrates: Foundation models (feedback loop), social platforms. |
| 2. Data Flywheel Dynamics | Rapid improvement where users generate data that improves the product for all. | Advantages remain static and non-proprietary. | Concentrates: Tesla’s fleet data. Without a flywheel, advantages are easily copied. |
| 3. Switching Costs Magnitude | Switching takes several months and abundant resources. | Switching takes less than 1 month, leading to price erosion. | Concentrates: Palantir (takes years to switch). High friction defends against competition. |
| 4. Capital Requirements | Requires >$100M for serious entry. | Requires just a few million $ for entry. | Concentrates: General-purpose foundation models (billions required). Most vertical AI apps fragment here. |
| 5. Standardisation Potential | One solution can serve 80% of needs across customers. | Every customer needs deep customisation and unique solutions. | Concentrates: Standardisation enables mass adoption and scale. |
| 6. Regulatory Complexity | Heavy regulation (e.g., medical, financial) creates high compliance barriers. | Light regulation enables easy entry for new players. | Concentrates: High barriers to entry limit the number of viable competitors. |
| 7. Economies of Scale | Unit costs drop >50% at 10× scale. | Scale advantages are minimal or non-existent. | Concentrates: Cloud infrastructure, foundation models. Massive scale is necessary to achieve cost efficiency. |
Examples:
-
General-purpose foundation models: Concentrated - Strong network effects + data flywheel + billions in capital + massive economies of scale = 2-3 winners (OpenAI, Anthropic, Google)
-
Voice synthesis: Concentrated - Data flywheel from usage + brand effects + quality threshold = concentrating around ElevenLabs
-
Vertical AI applications: Fragmented - Low standardization + domain expertise requirements + modest capital + rapid innovation = hundreds of specialists
-
AI marketing tools: Fragmented - Diverse use cases + low switching costs + rapid innovation + minimal scale advantages = thousands of niches
5. [Part IV] Sustainability
Building advantage is difficult. Maintaining it is harder. AI’s rapid evolution means every position faces constant erosion. Three sanity checks validate whether advantages will survive: the Reset Test, the Net Switch Test, and the New User Test.
5.1. The Three Sanity Checks
5.1.1. The Reset Test
Question: “If GPT-5, Claude-4, or Gemini-2 launches tomorrow with 10x better capabilities, what protects you?”
Why it matters: Major capability resets happen every 12-18 months. Companies that survive these resets have answers beyond “we’re better today.”
Valid protection against resets includes:
-
proprietary data moats with unique datasets that new models cannot access or replicate,
-
infrastructure ownership where specialised systems, GPU capacity, or inference architecture create barriers that competitors cannot quickly replicate,
-
workflow lock-in so deep that model improvements alone don’t change buying decisions,
-
regulatory barriers like certifications and compliance that take years to achieve,
-
trust capital in the form of relationships and reputation that transcend technical capabilities,
-
and network effects where value multiplies with users regardless of underlying model quality.
Invalid protection that won’t survive includes claims like “we’re ahead today” which is temporary by definition, “we have more features” which are easily copied, “we know the industry” when knowledge spreads quickly, or “we have funding” when money doesn’t stop obsolescence.
5.1.2. The Net Switch Test
Formula: Switching Friction / Switching Benefit = Net Switching Barrier
where:
- Friction equals time plus effort plus risk of switching,
- Benefit equals performance gain times cost savings times urgency to switch.
Why it matters: High friction alone doesn’t create moats if the benefit of switching is even higher. Low friction isn’t necessarily bad if the benefit of switching is minimal. The ratio between friction and benefit determines true stickiness. This test quantifies what many companies only discuss qualitatively.
5.1.3. The New User Test
Question: “Of 10 new users entering the market today, how many choose you?”
Why it matters: New users have no switching costs. They choose based purely on immediate benefits and anticipated viability: product quality, price, features, and reputation. This reveals true competitive post better than retention metrics, which can mask weakness through switching costs. High retention with low new-user acquisition indicates a dying product surviving on lock-in.
5.2. Dependencies and Trade-offs
Success requires alignment across all levels of the framework. Misalignment at any level undermines the entire position.
Technical edge without product depth equals impressive demos that don’t stick. Many AI startups have genuinely superior models, but fail to embed in workflows. Customers try them, appreciate the technology, even praise them publicly, but don’t depend on them. Usage remains sporadic, renewal rates disappoint, and eventually customers churn to integrated solutions.
Product depth without continuous improvement leads to gradual erosion. Being deeply embedded today doesn’t guarantee tomorrow’s position if competitors improve faster. Switching costs delay but don’t prevent eventual displacement. High friction only buys time—if you don’t use that time to improve, you’ll still lose.
Vertical depth without true specialisation delivers the worst of both worlds. Some companies claim vertical focus but offer generic solutions with minimal customisation. They accept the limited TAM of vertical markets without building the deep expertise that creates defensibility. These companies struggle to raise capital and fail to achieve market leadership.
Horizontal scale without differentiation guarantees a race to the bottom. Competing broadly with shallow value propositions invites platform crushing and price wars. Without unique advantages, horizontal plays become commodity providers competing on price alone, leading to margin collapse and eventual consolidation or failure.
6. Critical Factors Beyond Core Framework
6.1. Model Economics
While not our primary focus in this article, economics ultimately determine viability. The following metrics and ratios matter matter:
-
Inference Efficiency measures cost per query versus value created. The target is a value-to-cost ratio exceeding 10x.
-
Utilisation Rate tracks the percentage of compute capacity used productively. Profitability typically requires exceeding 70% utilization. Together AI achieves 85% through intelligent scheduling and load balancing.
-
Model Mix Optimisation involves routing between expensive and cheap models. The target is running 80% of queries on cheaper models while reserving expensive frontier models for the 20% that need them. Perplexity masters this by routing simple queries to small models.
-
Burn Multiple divides revenue growth by net burn. Below 1x is excellent, 1-2x is good, above 3x raises concerns. AI companies often show higher multiples due to compute costs, but this should improve with scale.
-
Margin Trajectory matters more than current margins. Margins should improve with scale through optimisation, volume discounts, and operational leverage. Declining margins with growth signal structural problems.
6.2. External Constraints
Several external factors create hard limits on growth regardless of execution quality.
-
Infrastructure limitations create absolute ceilings. GPU availability determines training capacity. Power access limits data center expansion. European AI labs face 12-month waits for power upgrades, capping their growth regardless of demand.
-
Regulatory requirements consume time and money. Healthcare and finance require years of certification. Raidium spent 18 months on medical device approval before generating meaningful revenue.
-
Capital access constrains AI companies more than traditional startups. Training runs cost millions. Compute bills compound monthly. Mistral raised $500M within its first year just to stay competitive.
-
Talent scarcity inflates costs dramatically. ML engineers command $500K-$1M+ packages in the US. Competition from giants makes hiring even harder. Anthropic recruited an entire OpenAI safety team, demonstrating the talent wars. They also acquired Humanloop for their talents.
6.3. Trust as Universal Gate
Trust multiplies or nullifies everything else. The best technology without trust remains experimental. Trust with technology unlocks transformation.
-
Technical trust requires reliability exceeding 99.9% uptime, consistency in outputs, transparency in decision-making, and graceful failure handling. One major ChatGPT outage damaged OpenAI’s enterprise sales for months.
-
Institutional trust demands certifications like ISO, SOC 2, and HIPAA, insurance coverage for errors and omissions, and compliance with regulations like GDPR and emerging AI laws. Harvey’s law firm insurance coverage enabled Fortune 500 adoption.
-
Social trust builds through brand reputation, customer references, and media coverage. Anthropic’s safety focus attracts enterprise customers who might otherwise hesitate.
Trust dynamics follow predictable patterns: building slowly over months or years, collapsing quickly from single incidents, and transferring poorly through acquisitions that often reset trust.
7. Synthesis: Applying the Framework
7.1. How to Evaluate an AI Company
Evaluation requires systematic progression through the hierarchy: start with the technical foundation → evaluate product depth → understand market positioning → apply the sanity checks.
| 1. Technical Foundation | Domain Delta | Performance advantage on metrics that buyers actually care about, not just technical benchmarks. |
| Velocity Dynamics | Speed of model improvement relative to the current technological frontier. | |
| Data Advantage | Owning proprietary data that is defensible and survives major model resets. | |
| 2. Product Depth | Job Coverage | Superior performance today PLUS a credible path to achieving full task completeness. |
| Workflow Embedding | Progression of product stickiness: Peripheral → Integrated → Essential → Foundational. | |
| Execution Autonomy | Scale of automation: from suggestions (0%) to full, reliable task automation (100%). | |
| 3. Market Positioning | Capability Thresholds | Technical breakpoints that trigger adoption avalanches (mass-market buy-in). |
| Vertical vs. Horizontal | Choosing between deep specialization (vertical) or broad market applications (horizontal). | |
| Market Structure | Determining if the market will concentrate (2–3 winners) or fragment (hundreds of small players). | |
| 4. Sustainability (Sanity Checks) | The Reset Test | What protects you if GPT-N launches tomorrow with 10× better capabilities? |
| The Net Switch Test | Is the switching friction greater than the switching benefit? | |
| The New User Test | What is our win rate with new users today? |
7.2. Key Insights
Displacement is the default state in AI. Every company faces obsolescence from capability jumps and platform threats. Building defences is existential. Companies that don’t actively build moats are building on sand.
Thresholds trigger avalanches. Markets stay flat for years then explode when capabilities cross critical points. Being too early burns capital educating the market. Being too late means fighting entrenched competitors. Timing matters more than gradual improvement.
Depth beats breadth initially. It’s better to be irreplaceable for 100 customers than nice-to-have for 10,000. True value comes from solving complete problems, not adding features. Expansion follows naturally after entrenchment.
Trust gates value creation. Technical capability without trust remains in the lab. Trust with capability unlocks transformation. One trust violation can destroy years of progress. Protect trust above all else.
Compound advantages win. Single moats erode quickly in AI. Sustainable advantage requires layering multiple defences that reinforce each other. Data plus workflow plus network effects plus trust equals durability.
7.3. Framework Limitations
This framework cannot predict breakthrough innovations. GPT-scale surprises will continue happening. It cannot time markets precisely, thresholds are visible approaching but not predictable far in advance. It cannot eliminate uncertainty since AI evolves too rapidly for complete confidence.
Use the framework as structured thinking, not formulaic answers. Markets will evolve. New patterns will emerge. Adapt the framework accordingly.
Conclusion
AI valuation requires new mental models. Traditional metrics assume stability that doesn’t exist. This framework addresses AI-specific dynamics: displacement risk, capability thresholds, market creation, and compound advantages.
The four-level hierarchy - technical, product, market, sustainability- provides structure for analysis. The three sanity checks provide validation of defensibility. Together they reveal what creates and sustains value in AI companies.
The framework will evolve as AI evolves. New categories will emerge. New dynamics will become important. But the core questions remain constant: What advantage exists? How does it become indispensable? What market dynamics apply? Will it survive resets?
The age of AI rewards those who build defensible positions. This framework tries to identify real advantages, evaluate true moats, and invest in durable value.
The game has just begun.

