.png)

“The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. The ultimate reason for this is Moore's law, or rather its generalization of continued exponentially falling cost per unit of computation.” - Richard Sutton, The Bitter Lesson
In February 2025 at OpenAI, I got RL-pilled. Reinforcement Learning allows an LLM to hill-climb any problem where verification is easier than generation, and by scaling up RL compute, the Strawberry team was saturating all their environments every few weeks. So I started wondering to myself what the highest value RL environment might be.
If you’ve read The Bitter Lesson, you understand that AI is fundamentally advanced by scaling. But do you Take the Bitter Lesson Seriously? We, AI researchers, continue to go about our work on algorithms, architecture, and data as if it were still 2019 and scaling laws were yet to be discovered. But now it’s 2025, and we know that more compute & more energy is the most reliable path to advancing AI.
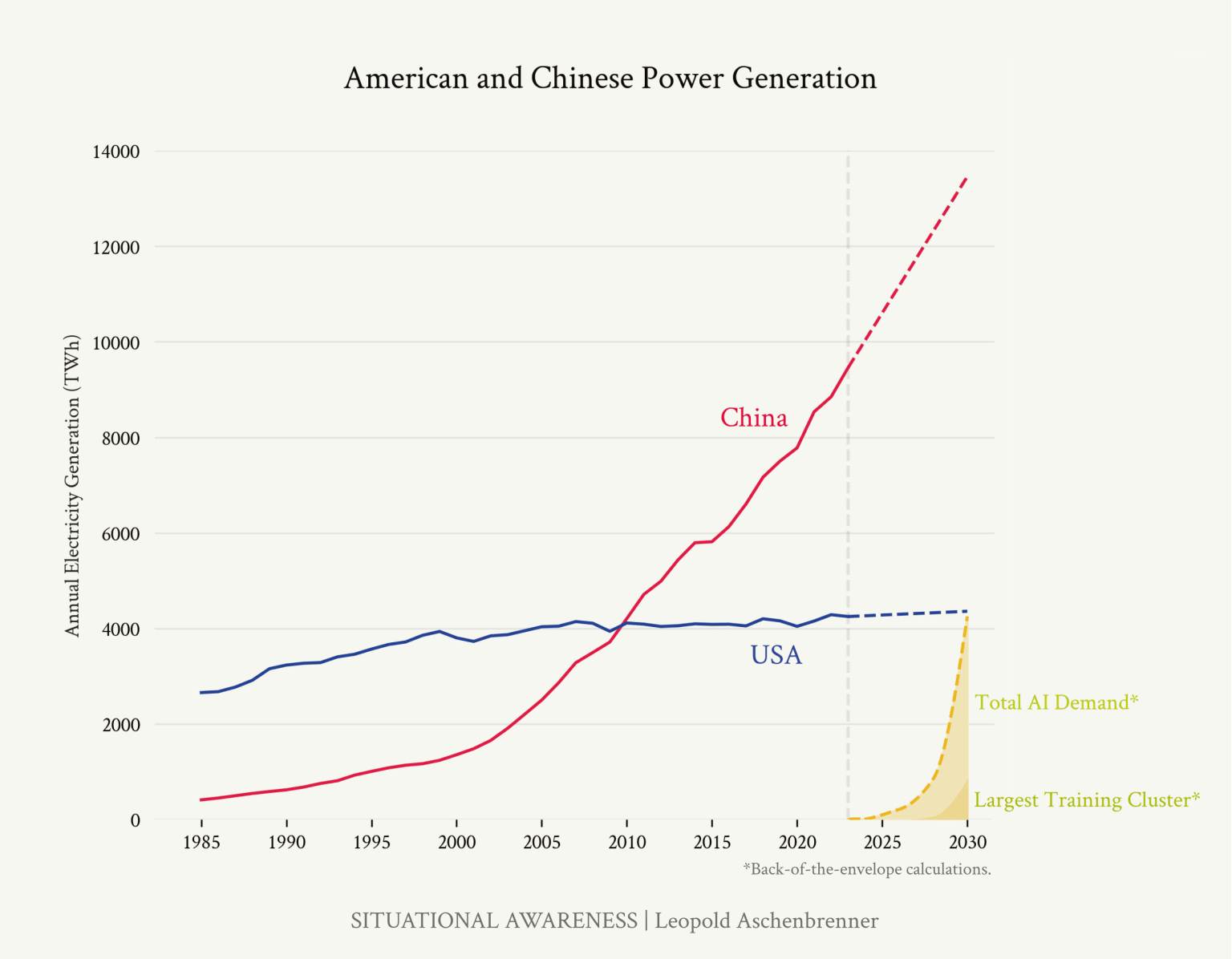
The dream at many frontier labs is recursive self-improvement: AI good enough to code a better n+1 version of itself, which codes a better n+2, …, until the Universe is overflowing with intelligence. Technology has been accelerating its own progress for centuries, but the notion that AI will algorithmically self-improve ad infinitum forgets the Bitter Lesson and that research is compute-bound. Kick off a few agents to run pretraining experiments and see how quickly you run out of H100s.
Is it hopeless then? Does the Bitter Lesson doom us to be compute-bound, waiting for Nvidia to ship GB300, for ASML to perfect High-NA EUV, and for nuclear fusion to be solved? No.
If you Take the Bitter Lesson Seriously, recursive self-improvement means freeing AI to accelerate compute & energy—technologies bottlenecked by real-world science.
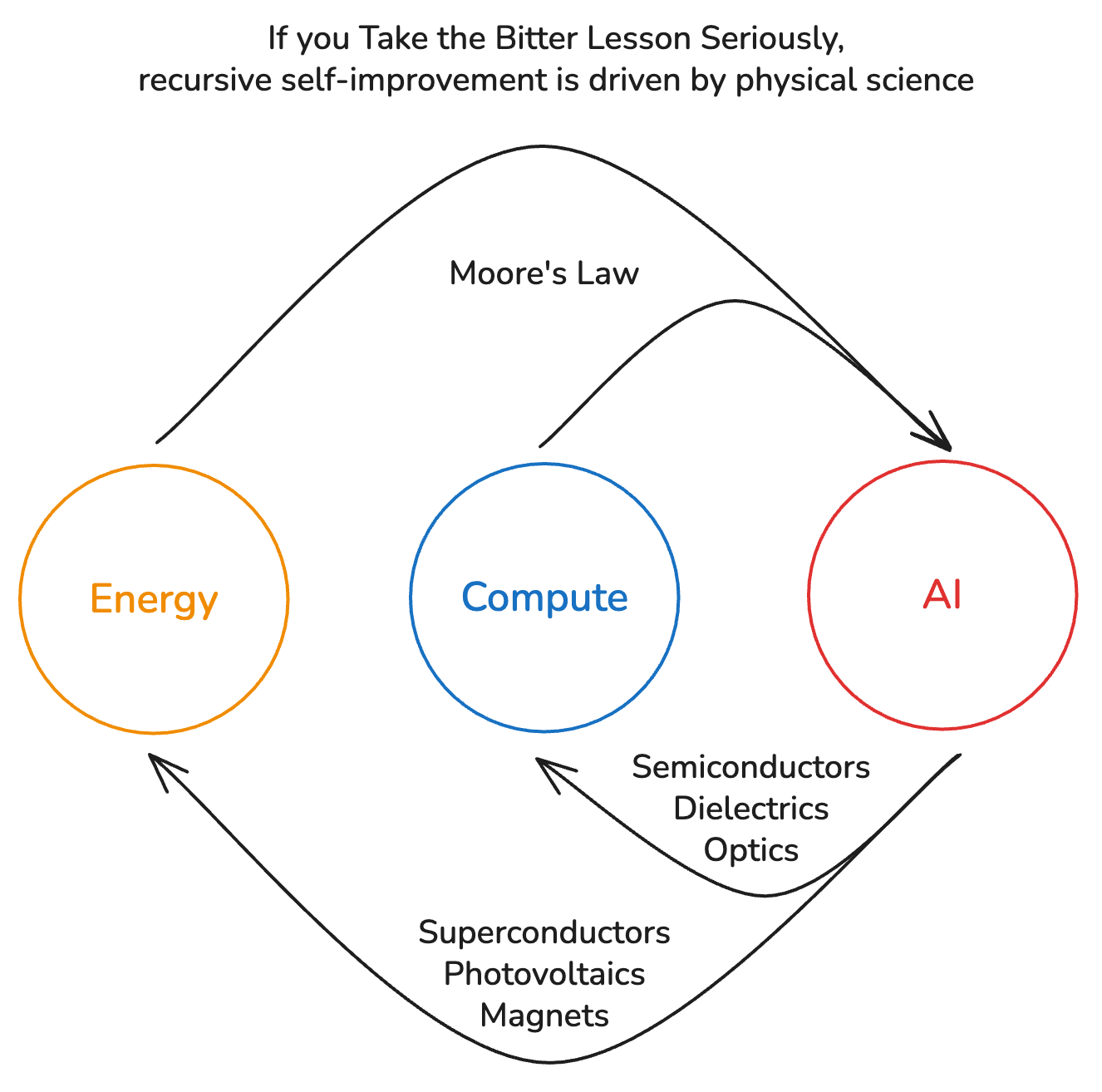
At Periodic Labs, we’re building the highest value RL environment: an autonomous laboratory for matter. Our first lab in Menlo Park gives AI the robotic & scientific tools to spark an exponential scale-up of compute & energy through breakthroughs in advanced materials.
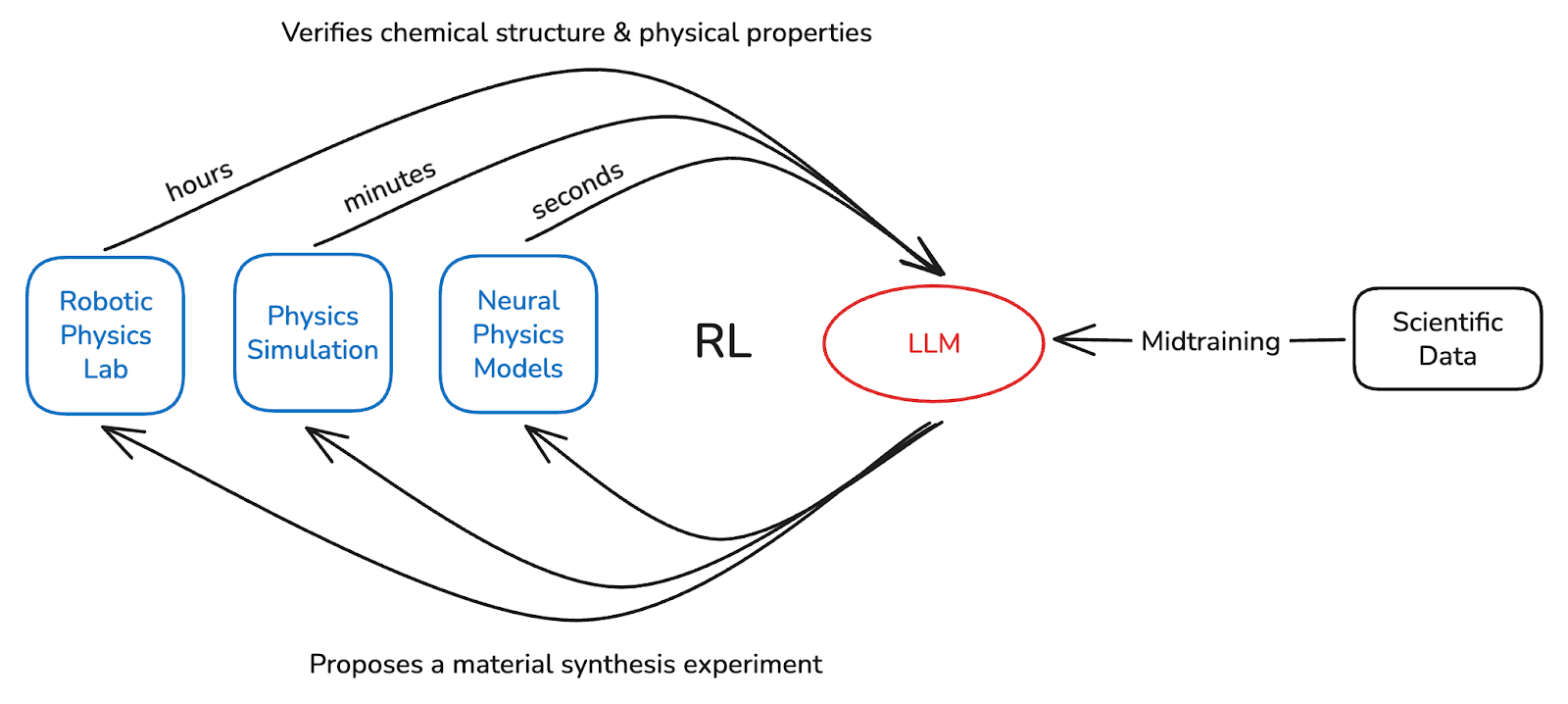
For example, to discover a high temperature superconductor (i.e. an LK-99 that works), we might take an LLM we’ve midtrained on terabytes of condensed-matter physics data and run RL guided by a reward for higher critical temperature. In each iteration, the LLM hypothesizes & proposes experimental materials like Li2Be1Ga6Rh3 which are executed in simulation for rapid feedback or synthesized by robots in the lab for ground-truth Tc verification. Verifiability makes physics as hill-climbable as math or coding.
Autonomous Science is thus the most worthy problem for a bitterlessonpilled AI researcher, and comes loaded with questions about RL, synthetic data, & supercomputing that Periodic Labs is actively hiring for. I’m incredibly lucky to work on such a talented, well-capitalized team led by our founders Liam (ex-VP of Post-training at OpenAI) & Dogus (ex-Head of Quantum Materials at Google DeepMind) who pioneered ChatGPT & GNoME. I hope you’ll join us as we ascend the Kardashev scale.
Acknowledgements: Thank you to John Hallman, Archie Sravankumar, Aryaman Arora, Bayes Lord, Roon, Will Brown, Dwarkesh Patel, Clive Chan, Dylan Patel, Liam Fedus, Tamay Besiroglu, and Anjney Midha for reviewing drafts of this essay.

/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/filer_public/66/ce/66cecad8-25c4-4946-988a-deb3ab74e9c7/gettyimages-3289977.jpg)

