.png)

 Photo by Raimond Klavins / Unsplash
Photo by Raimond Klavins / Unsplash
I've spent the last week or two writing code to make sense of the massive hack of data from TeleMessage, the comically insecure company that makes a modified Signal app that Trump's former national security advisor Mike Waltz was caught using. I've decided to publish my code as open source in the hopes that other journalists will use it to find revelations in this dataset.
While the source code for TeleMessage Explorer is public, it requires the TeleMessage dataset to use it. DDoSecrets is distributing this dataset to journalists and researchers with a history of reporting who agree to publish their findings. Contact DDoSecrets (not me) to request access.
In this post, I explain how journalists who have access to the dataset can crunch the TeleMessage data and then explore it using TeleMessage Explorer. I also show a bunch of screenshots from the tool showing TeleMessage data, and I describe some details I found out about one 24-year-old (today is his birthday!) White House staffer bro who has Signal messages in this dataset.
I used this tool myself to publish my recent post, TeleMessage customers include DC Police, Andreessen Horowitz, JP Morgan, and hundreds more. Reuters has reported on this dataset too, and I know plenty of other journalists and newsrooms currently have access to it.
I'm crunching data and writing these newsletters in my free time. If you want to support my work, considering becoming a paid supporter.
💡
TeleMessage Explorer is unpolished software. I built it initially just for my own use. I don't promise to maintain it, fix bugs, or anything else. If your newsroom wants help working with it, or wants specific features implemented or anything like that, contact me and I might be interested in consulting.
Like BlueLeaks Explorer before it
Back in 2020, in the middle of the Black Lives Matter uprising, someone hacked hundreds of law enforcement websites and exfiltrated about 270 GB of data. That dataset, called BlueLeaks (it's completely public for everyone to download from DDoSecrets), is full of evidence of police misconduct. I wrote a tool called BlueLeaks Explorer to help me dig into it and write articles.
It wasn't until 2024, when I published my book Hacks, Leaks, and Revelations: The Art of Analyzing Hacked and Leaked Data, that I decided to release BlueLeaks Explorer as open source, basically as an education tool. At this point, the BlueLeaks data was years old.
I still think there are tons of revelations in BlueLeaks that even today no one has found, because no one has looked, but at this point it's all old news. If you want to dig into secret 2020-era docs from your local police intelligence agency yourself, I recommend reading my book (which is available for free online, though I'd appreciate if you buy a copy), and particularly these chapters:
I'm hoping that by releasing TeleMessage Explorer right now, a lot of good journalists will use it to find a lot of good stories while the data is still fresh.
Prerequisites
Since most journalists I know are Mac users, I'll show you how to get started using macOS.
Here's what you'll need:
- Access to the TeleMesage dataset from DDoSecrets, with telemessage.7z downloaded.
- About 530 GB of free space. You can do this on your internal disk or on a USB disk. If you use a USB disk, I highly recommend using an SSD.
- Comfort with running commands in the the terminal.
Here's the software that you'll need to install:
- You need Docker. You can download Docker Desktop here. (Because Docker the company is kind of annoying, it will try to get you to login to an account, but you can skip this, you don't actually need an account to use it.)
- You'll also need Python and Poetry installed. If you use Homebrew, you can install these with: brew install python3 poetry
You'll also need a copy of the TeleMessage Explorer code itself. You can either run git clone https://github.com/micahflee/telemessage-explorer.git or download the zip file of the code from GitHub.
Download telemessage.7z from DDoSecrets. This is 54 GB. Then, extract it. If you're not familiar with 7-zip files, one way to extract it is to install 7-zip (brew install 7zip), and then you can extract it like 7zz e telemessage.7z.
After extracting, you'll get a folder with 2,729 heap dump files, taking up 384 GB of space. These files will be called heapdump, heapdump.1, heapdump.2, ..., heapdump.2728.
My code expects all files to have a number at the end, so in your terminal, change to the folder with the heap dump files and rename heapdump to heapdump.0:
mv heapdump heapdump.0Most of the data in these heap dump files isn't relevant. All TeleMessage Explorer cares about are the JSON objects in the heap dumps, and the easiest way to cut out the useless parts is by using strings. Run the following command to loop through all heap dump files and for each file, run strings on it and output it to the same filename but with the .strings extension:
for F in $(ls); do echo $F; strings $F > ${F}.strings; doneThis takes awhile to run. But at the end, you'll have an additional 83 GB of just text data.
How the code is organized
There are four components to TeleMessage explorer:
- The backend is programmed in Python and Flask. It's a simple API, used by the frontend, to access data from the database.
- The frontend is programmed in TypeScript and uses Vue.js. It's pulls data from the backend using its API.
- The database is PostgreSQL, and you run it in Docker.
- Finally, the "cruncher" part of the code will read all of the heap dump strings files, search for relevant JSON objects, and insert them into the database. I call this "crunching the data."
You'll start the backend, frontend, and database as containers using Docker Compose. Go ahead and build the containers right now by running:
docker compose buildYou'll crunch the data by running the cruncher Python script. You'll need the database Docker container up to do that though.
Crunch the data
Make sure Docker is running on your computer. Change to the telemessage-explorer folder with the source code and run this command to start the database container:
docker compose up dbThis should start the db container. Note that it stores its data in the volumes/db-data folder.
Once that database is running, open a new terminal window. Switch to the cruncher folder:
cd cruncherInstall the Poetry dependencies:
poetry installNow you can use the crunch script like this:
$ poetry run crunch --help Usage: crunch [OPTIONS] Options: --path DIRECTORY Path to folder with heap dump .strings files [required] --num-threads INTEGER Number of threads to run --num-skip INTEGER Skip the first N heap dumps --help Show this message and exit.When you crunch the data, you must include --path with the path to the folder with the .strings files you created.
If you want, you can pass in --num-threads to choose how many threads you want the cruncher to use (by default, it uses one the number of CPU cores you have available).
Before crunching data, you need to set some environment variables to tell the cruncher how to connect to the database:
export DB_NAME=db export DB_USER=db export DB_PASSWORD=db export DB_HOST=localhost export DB_PORT=54320Finally, crunch the data like this, replacing the path with the location of the strings files you created above:
poetry run crunch --path ~/datasets/2025-TeleMessage/stringsHere's what it should look like:
0:00
/0:27
Video of crunching the data
As you can see in the video, on my Mac the cruncher is using 8 threads, meaning that it's crunching 8 heap dump files at a time. When it's done with each file, it shows some output explaining how many of which different types of JSON objects it's looking for that it found, as well as the overall progress.
It will probably take your computer a few hours to finish crunching the data. But at the end, you'll have a PostgreSQL database full of data from the heap dump files.
The database
After crunching the data, you'll have a PostgreSQL database full of messages, groups, users, attachments, validations, and various join tables. As long as the database container is running, you can connect to it using psql or any other PostgreSQL client.
In the following screenshot, I ran a query (using TablePlus) that selected everything from all groups, joined them with the number of messages and users in each group, and sorted them by the groups with the most messages.
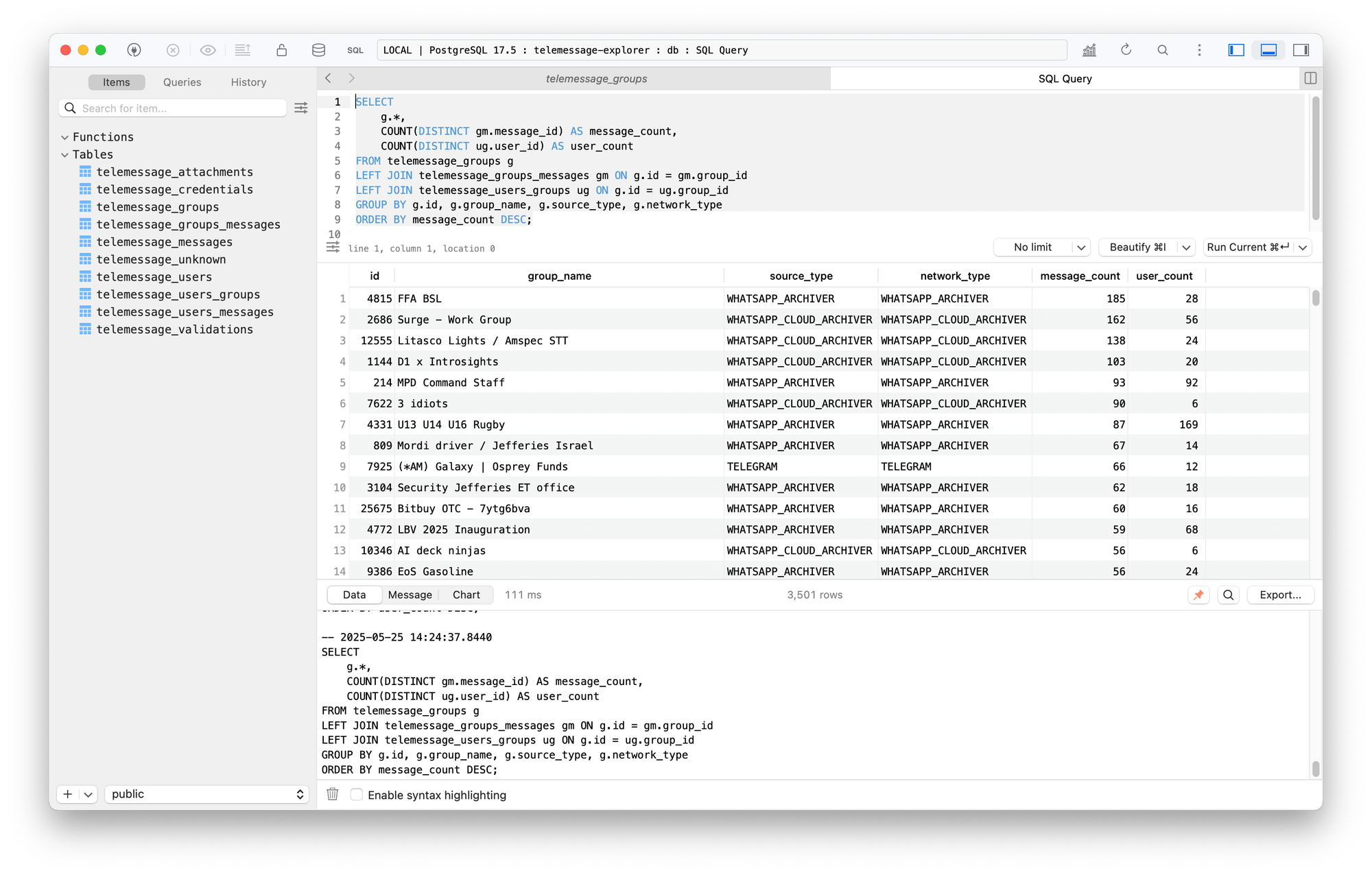 The crunched data in a PostgreSQL database
The crunched data in a PostgreSQL databaseWhen I started coding this, at fist I only planned on inserting relevant data into a database. I could then write my own SQL queries to find the good stuff.
But then I quickly realized that it would be much easier to research if I had a user interface built for browsing the data. So, I made one.
TeleMessage Explorer
In your terminal window that's running Docker Compose, press Ctrl-C to quit the database container. Then start all containers together like this:
docker compose upThis should start three containers: backend, frontend, and db. In your browser, load the frontend by going to http://localhost:5173.
Here's a screenshot of the same data as from the SQL query above, except using TeleMessage Explorer:
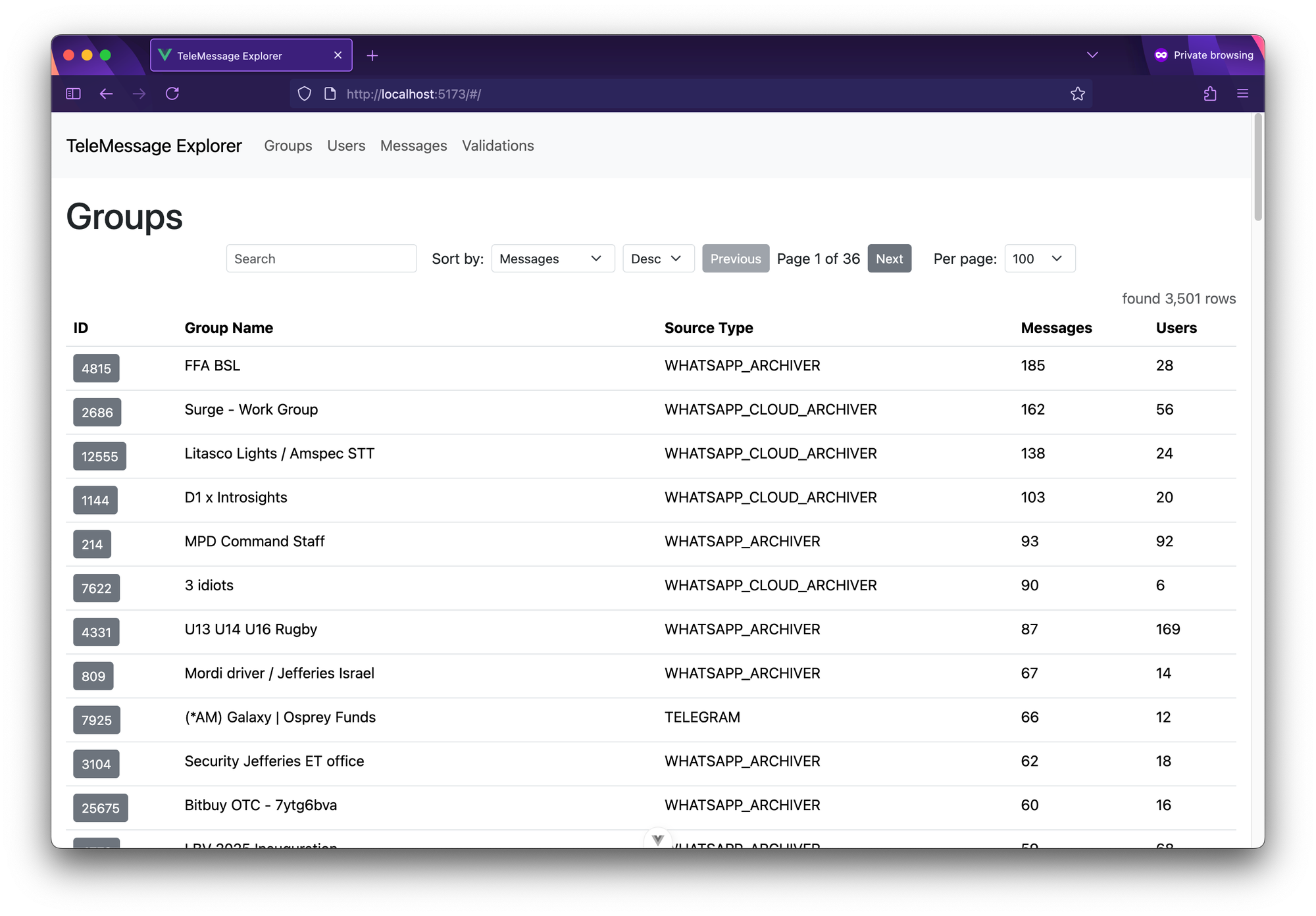 Viewing groups in TeleMessage Explorer.
Viewing groups in TeleMessage Explorer.You can filter the the groups by entering text in the "search" field. This will only show results where the string appears in either group name or source type. There are 28 groups when I search for "signal":
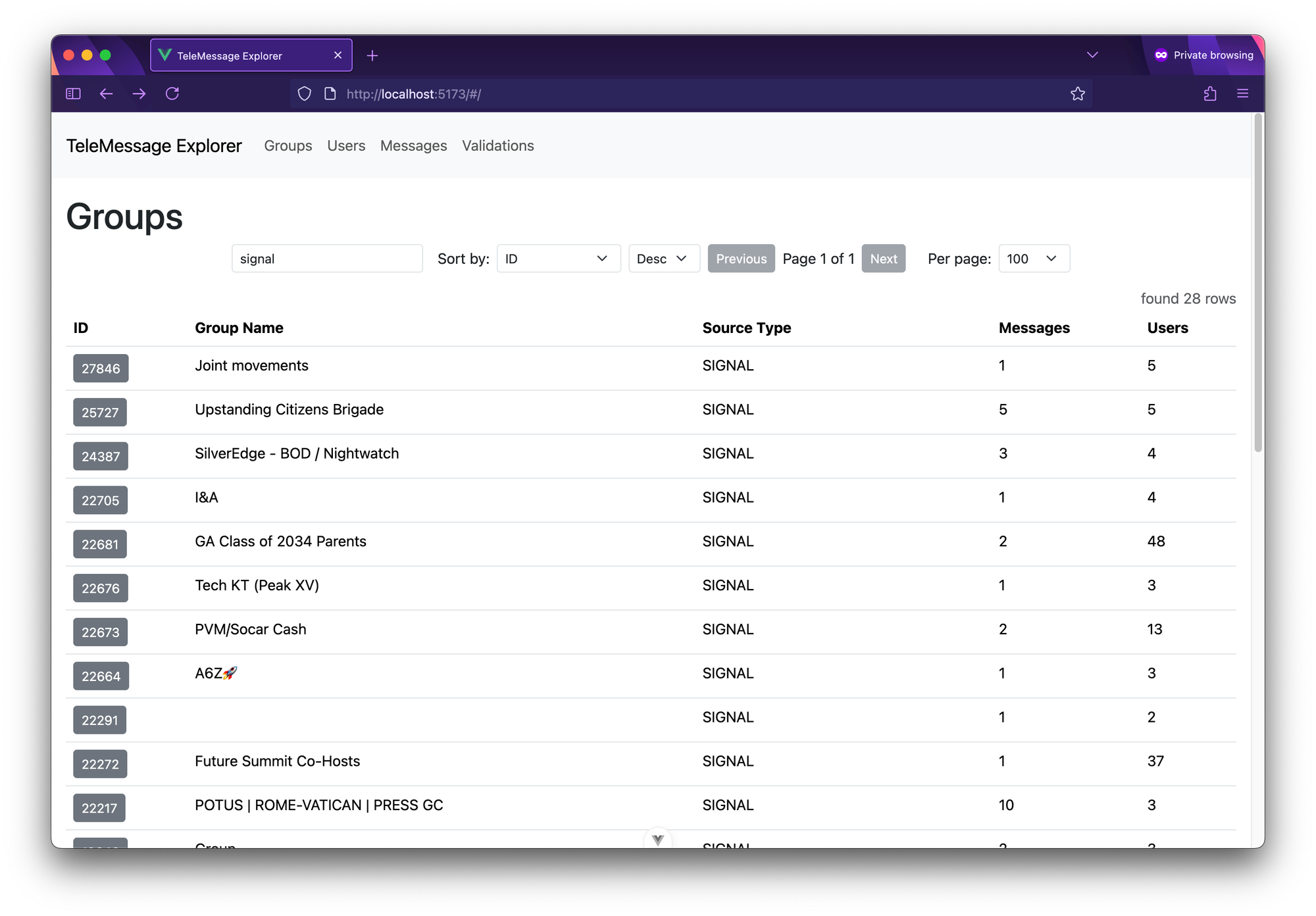 Signal groups.
Signal groups.Each row has an ID column, and the ID itself is a button to go into more detail about that column.
For example, this is what it looks like when I click 22217, the ID for the Signal group called "POTUS | ROME-VATICAN | PRESS GC" – yes, that's POTUS as in "President of the United States":
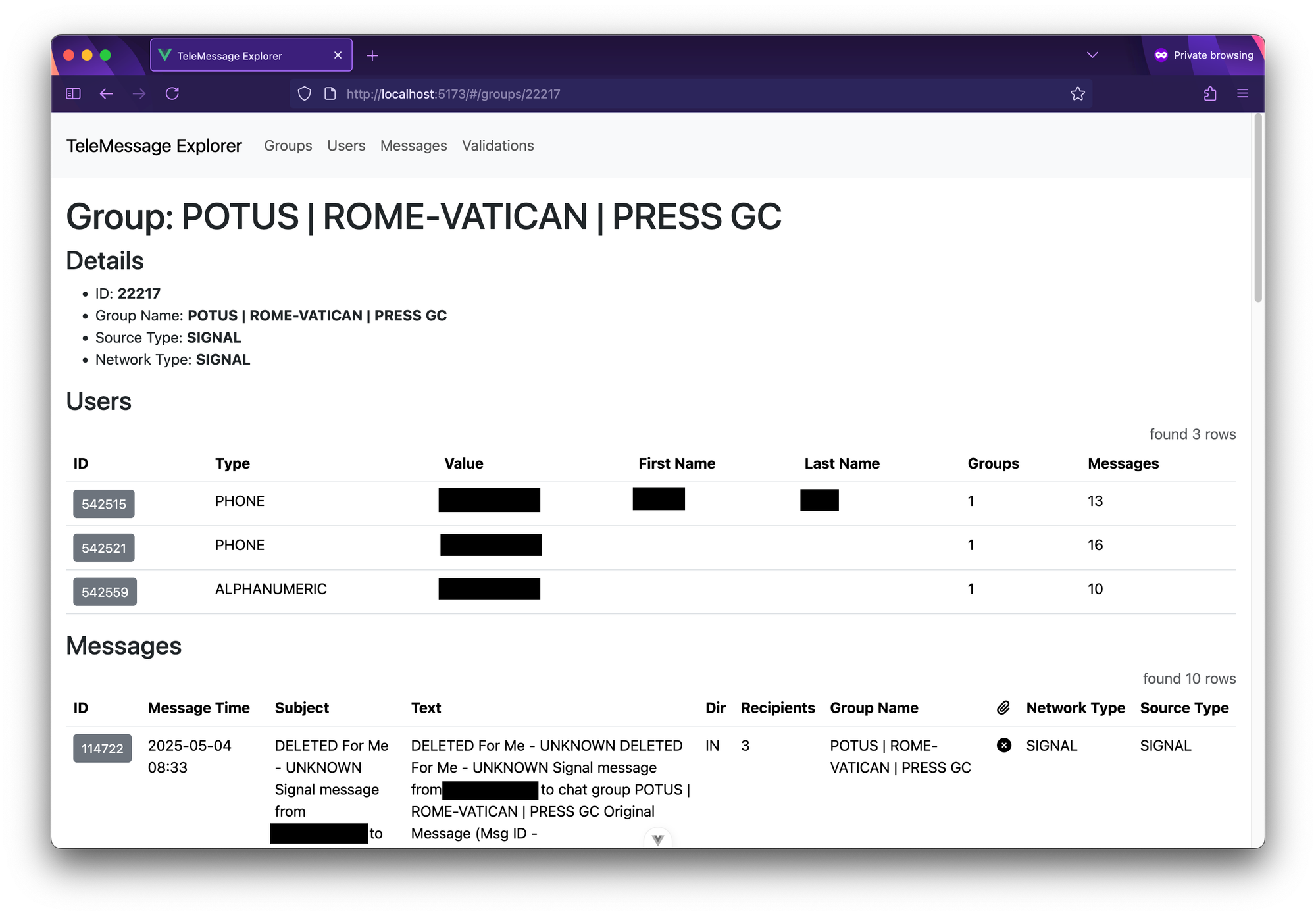 This Signal group has 3 users in it, and 10 messages.
This Signal group has 3 users in it, and 10 messages.The group details page shows you all of the information about that group, along with its list of users and messages. You can click the ID button for each user, or for each message, to get to details about that user or that message.
Here's what happens when I click on the ID button for one of the messages:
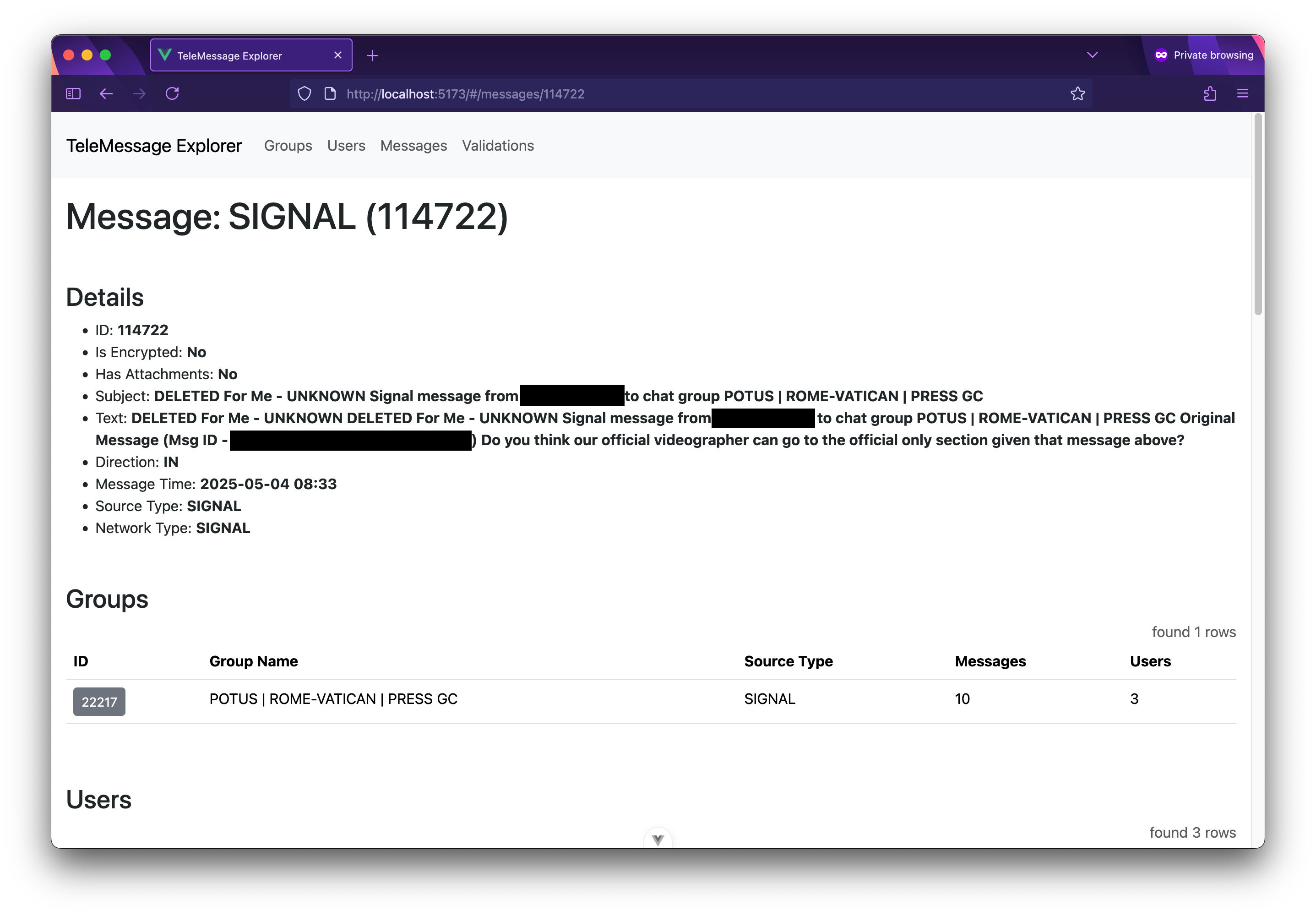 Detail view for this deleted Signal message.
Detail view for this deleted Signal message.The text of this Signal message, which seems to be deleted, extracted from a JSON objects that was found inside a heap dump file, is:
Do you think our official videographer can go to the official only section given that message above?It was sent to this Signal group on May 4 at 8:33 am (I'm not entirely clear which time zone). If you scroll down on the message view, you can see the group and all the users in the group, followed by the JSON object itself – this is helpful to look at, just in case there was a bug in the crunching code or there are details in the JSON that TeleMessage Explorer didn't extract.
Here's the JSON object (lightly redacted) for that message, if you're curious:
{ "body": { "acceptedPayloadIdentifier": "3f9dbce0-a7df-45d7-82c4-f67bd311b8fd", "attachment": null, "ban": null, "callInfo": null, "direction": "IN", "groupData": { "id": "", "name": "POTUS | ROME-VATICAN | PRESS GC", "type": "BROADCAST" }, "groupId": "", "groupMessage": false, "groupName": "POTUS | ROME-VATICAN | PRESS GC", "messageId": "DELETE_FOR_ME-==redacted==", "messageStatus": "NA", "messageTime": 1746372791000, "messageType": "EVENT", "originalMessageData": null, "owner": { "type": "PHONE", "value": "==redacted==" }, "participantEnrichments": {}, "partner": null, "recipients": [ { "type": "PHONE", "value": "==redacted==" }, { "type": "ALPHANUMERIC", "value": "==redacted==" }, { "type": "PHONE", "value": "==redacted==" } ], "sender": { "type": "PHONE", "value": "==redacted==" }, "subUserId": 0, "subject": "DELETED For Me - UNKNOWN Signal message from ==redacted== to chat group POTUS | ROME-VATICAN | PRESS GC", "text": "DELETED For Me - UNKNOWN DELETED For Me - UNKNOWN Signal message from ==redacted== to chat group POTUS | ROME-VATICAN | PRESS GC\n\nOriginal Message (Msg ID - 1745588825737_12028815188_0)\n\nDo you think our official videographer can go to the official only section given that message above?", "textField": { "extractor": { "data": "DELETED For Me - UNKNOWN DELETED For Me - UNKNOWN Signal message from ==redacted== to chat group POTUS | ROME-VATICAN | PRESS GC\n\nOriginal Message (Msg ID - 1745588825737_12028815188_0)\n\nDo you think our official videographer can go to the official only section given that message above?", "typ": "WrapperExt" }, "length": 286 }, "threadID": "tm-357956699", "threadName": null }, "gatewayReceivedDate": 1746372791228, "internalSecurityData": { "internalDecryptionData": { "encryptionType": "DO_NOTHING", "params": {}, "typ": "nothing" }, "version": "0.0.2" }, "kafkafied": true, "networkType": "SIGNAL", "ownerExtClassId": null, "partner": "NONE", "securityContent": null, "sourceService": null, "sourceType": "SIGNAL", "typ": "RawMessage" }Just like I searched groups for "signal", you can also use TeleMessage Explorer to search and filter users and message.
For example, here's a screenshot of me simply searching the messages for the word "trump":
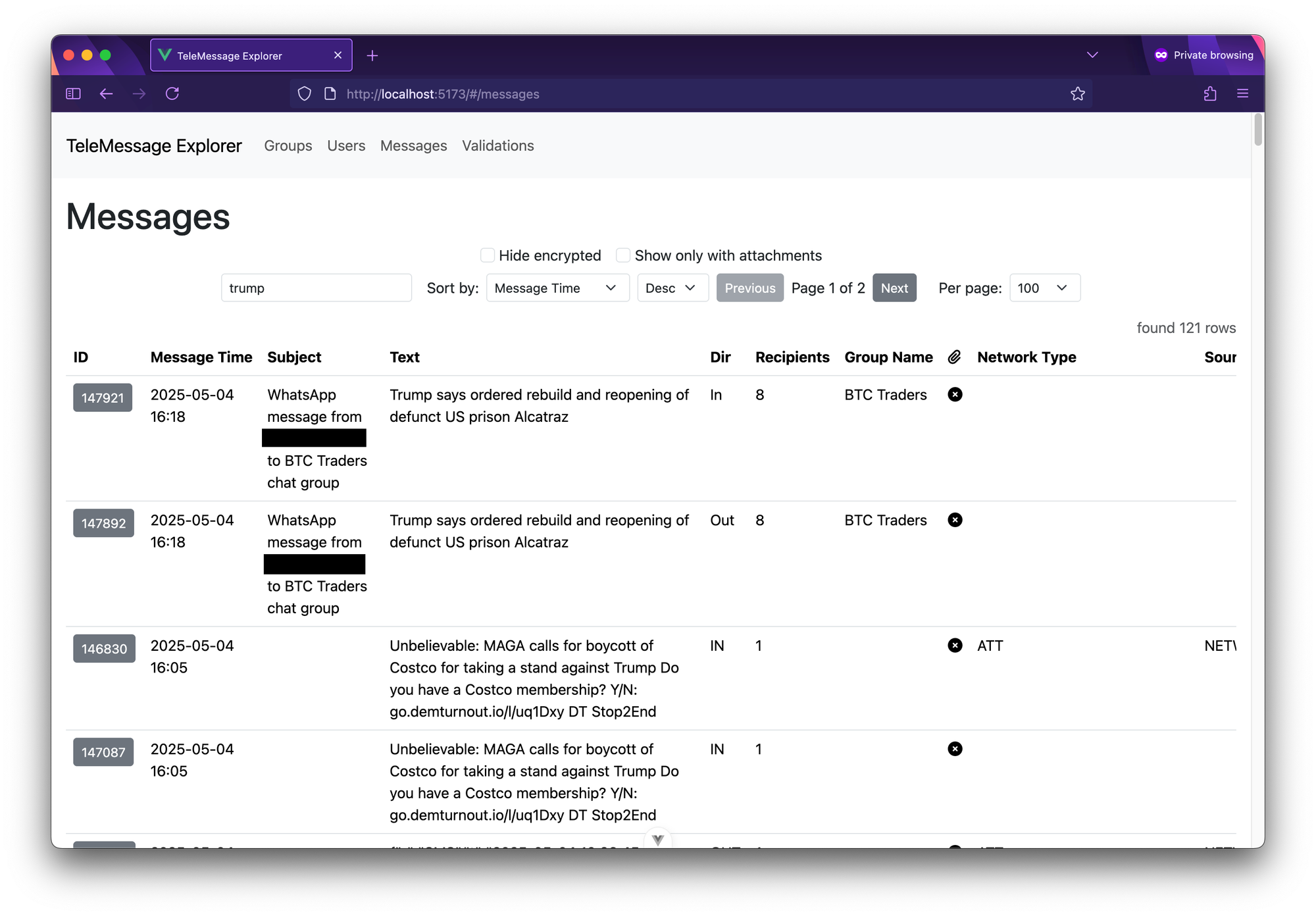 Searching messages for "trump".
Searching messages for "trump".As you can see, there are some duplicates in here. And also as you can see, at least for some customers, TeleMessage collects SMS messages. The bottom two messages says:
Unbelievable: MAGA calls for boycott of Costco for taking a stand against Trump Do you have a Costco membership? Y/N: go.demturnout.io/l/uq1Dxy DT Stop2EndThis is Democratic Party SMS spam, getting collected by TeleMessage.
Some of the messages include attachments that can be downloaded. Here's a WhatsApp message that includes an attachment:
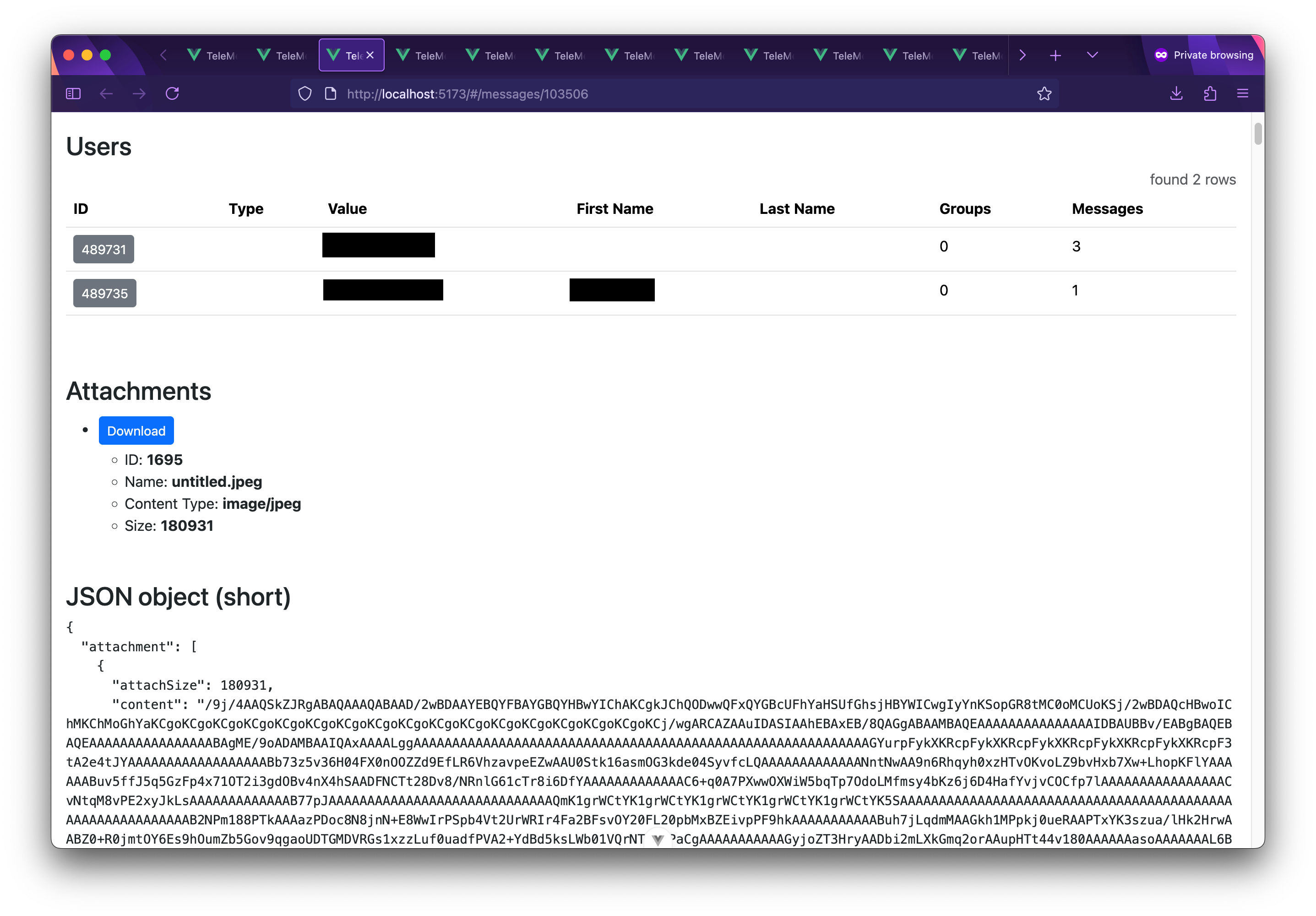 Message with an attachment.
Message with an attachment.As you can see in the JSON object part, the attachment is Base64-encoded, and included directly in the JSON object that was extracted from the heap dump. For messages that have this sort of attachment, TeleMessage Explorer has a download button, which Base64-decodes the attachment and then saves it for you.
This attachment is a screenshot from a Bloomberg article about Saudi Arabia and OPEC+, taken on an iPhone, which also happens to be connected to a 5G network and is tethering internet.
 Attachment extracted from a message.
Attachment extracted from a message.Finally, at the bottom of my recent post that describes hundreds of TeleMessage customers, I explained that I found OAuth2 validation objects in the data, and I used those to make a list of customers.
You can explore these validation objects in TeleMessage Explorer at the Validations nav link at the top. Here's a screenshot of a search of the validation objects for ".gov" :
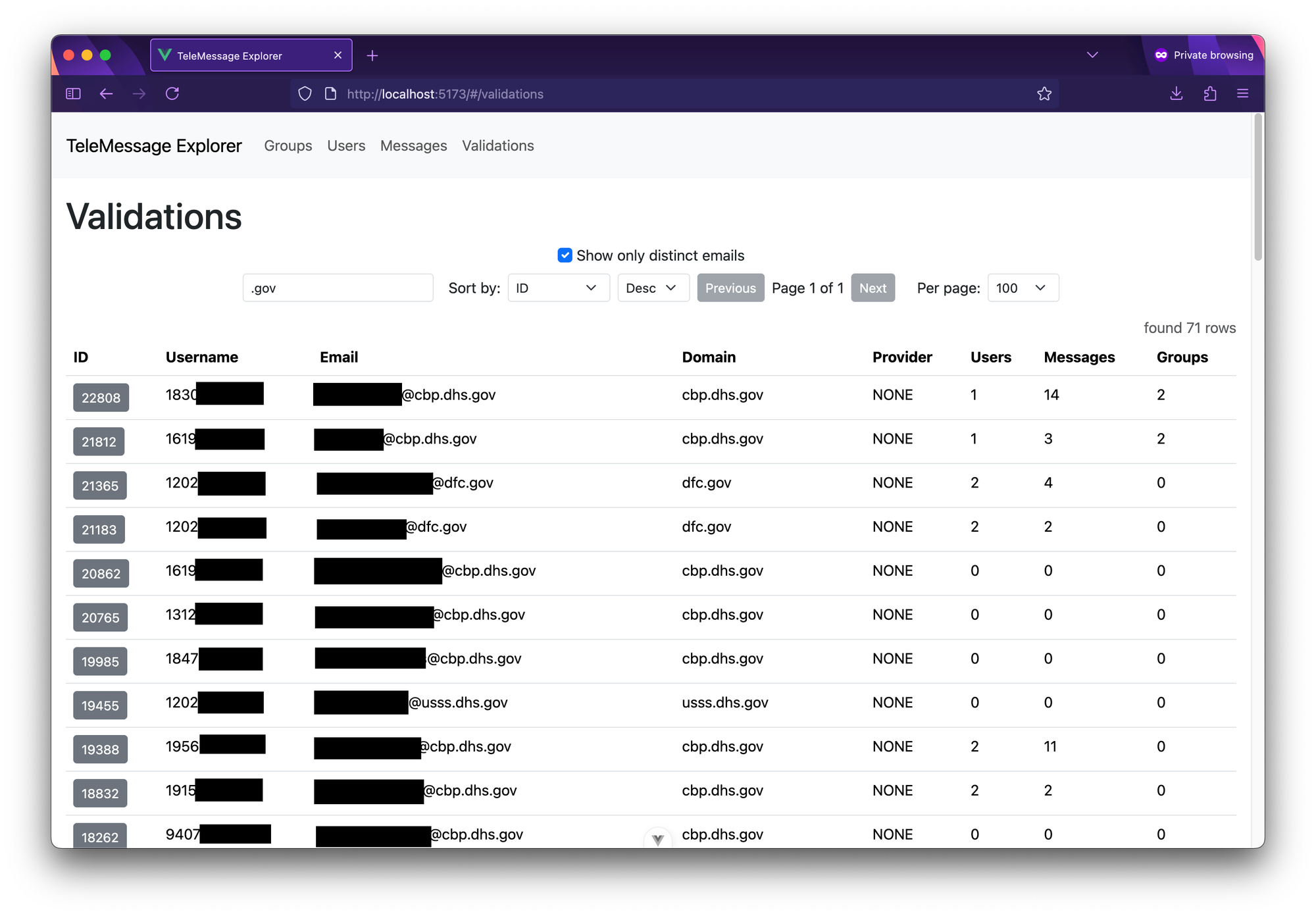 Validation objects search for ".gov".
Validation objects search for ".gov".There are 71 .gov email addresses in the validation objects. The usernames are all phone numbers. If you click the ID of one of these validation messages, it shows you any messages and groups in the dataset associated with that phone number.
Executive Office of the President
By the way, one of those OAuth2 validations is for an email address that has the domain who.eop.gov. The who part is "White House Office," and the eop part is "Executive Office of the President."
I spent some time digging into this particular person based on his work phone number, work email address, and his name, all of which I found in this dataset.
I haven't yet found anything egregious, but here are some of the interesting highlights:
- He's a member of the "POTUS | ROME-VATICAN | PRESS GC" Signal group.
- He's a young white conservative man.
- Last August, before Trump's inauguration, he posted on LinkedIn that he was starting a position at Donald J. Trump For President 2024, Inc.
- Also according to LinkedIn, he got his bachelor degree from the University of Alabama in 2024.
- I found him on Tinder, and it included his birthday. He was born in 2001, and today is his birthday! He just turned 24.
- Someone with his same username has logged 680 hours of Fortnite.
- His Venmo transactions are open, lol.
If you found this interesting, subscribe to get these posts emailed directly to your inbox. If you want to support my work, considering becoming a paid supporter.