.png)

A look at an under-discussed style of interpreter used by V8 and Hotspot.
It’s well-known that the fastest programming language runtimes get their speed by having an optimizing JIT compiler, famous examples being V8 and HotSpot.
There’s something less known about their baseline bytecode interpreters (the interpreter that runs code by default before JIT kicks in):
They don’t write their bytecode interpreter in a language like C/C++, but actually in assembly (or some similar low-level IR).
To learn more, I went digging into V8 and HotSpot, then built my own interpreter in this style heavily based on HotSpot’s design (simply because I found their code easiest to read).
HotSpot calls this style of interpeter a “template interpreter” in their source code and documentation, which is how I’ll refer to it in this blog post, but I think a more accurate name may be just “assembly interpreter” or something.
Because at it’s core, it’s really about generating machine code for each bytecode op handler, and creating an instruction dispatch table mapping bytecode opcode -> machine code to execute it.
This lower-level control lets you do interesting things like keep important/hot variables in dedicated registers or using the hardware call-stack instead of simulating the stack.
So in this blog post, I’ll try to explain why this style of bytecode interpreter exists, we’ll go through some implementation details, and finally benchmark it against other more well-known interpreter styles.
We’ll mostly be covering a stack-based interpreter design based on HotSpot’s.
Also this blog post will contain assembly, specifically aarch64 assembly as that is the architecture I am most familiar with.
Why would you want to drop down and write your interpreter in a low-level language like assembly?The first obvious reason is performance.
Compilers usually produce machine code that is faster than what a human could write by hand.
But Mike Pall, author of LuaJIT, famously rewrote LuaJIT’s interpreter in assembly and his rationale was actually that compilers were not so great at optimizing interpreter main loops.
Commonly, a stack-based bytecode interpreter is implemented with the ol’ reliable while-loop + switch-statement:
const Opcode = enum(u8) { // add two integers iadd = 0, // subtract two integers isub = 1, // other ops... }; const STACK_MAX = 1024; var stack: [MAX]i32 = undefined; var stack_top: [*]i32 = &stack[0]; while (true): (pc += 1) { switch (bytecode[pc]) { .add => { const b = pop(); const a = pop(); push(a + b); }, .sub => { const b = pop(); const a = pop(); push(a - b); }, // and other ops... } }But as our interpreters grows in complexity, the code will, in the compiler’s eyes, look like one big giant loop with very complicated control-flow.
This results in the compiler struggling with:
-
keeping hot values in registers
-
distinguishing fast paths from slow paths are, resulting in the slow paths pessimizing the fast paths
You can read more about this here and here.
One thing to keep in mind is this was all said by Mike Pall over 10 years ago. It’s unclear to me how much of this performance gap has been closed by advancements in compilers1.
And Filip Pizlo (author of JSC’s LLInt interpreter, which is written in assembly too) had to say this:
JSC’s interpreter is written in assembly not because of perf but because of the need to share ABI with the JIT
Mike’s wrong, even back then you could write a good interpreter in C or C++, though you’d have to be careful. Modern compilers make it even easier. Only reason not to write in C/C++ is ABI compat with JIT
That may be the stronger reason why high-performance languages runtimes like to write their interpreters in low-level assembly-like languages, and it allows them to play nicely with the JIT.
One thing interpeters with JIT compilation need to think about is how and where they swap in and out of JIT’ed code.
The easiest place for the interpreter to switch into JIT’ed code is at the function boundary: just call into the compiled code.
But what if you have a function which is not called often (so it’s not marked as “hot” and doesn’t get JIT’ed), but has a very hot loop? You’d still want the loop to benefit from JIT.
So On-Stack Replacement (OSR) allows swapping to optimized JIT’ed code in the middle of a function, for example when a hot loop loops around to the next iteration.
Since template interpreters have precise control over their machine code, they can be designed to make this swap efficient.
For example, V8’s Ignition interpreter intentionally shares the same ABI as JIT’ed code, so hopping into JIT’ed code is pretty much just a single jump instruction:
/* v8/src/builtins/x64/builtins-x64.cc */ void Generate_OSREntry(MacroAssembler* masm, Register entry_address) { // Drop the return address on the stack and jump to the OSR entry // point of the function. __ Drop(1); __ jmp(entry_address, /*notrack=*/true); }Hotspot, on the other hand, does not do this and must convert the currently executing interpreter frame into a compiled frame.
By the way OSR works the other way too, it can be used to hop out of some JIT compiled code, commonly used for deoptimization.
A rough sketch of the overall layout of a template interpreter looks like: // `bytecode` is a buffer of bytecode instructions fn run_bytecode(bytecode: []const u8) void { // maps bytecode op -> address of machine code to handle the op var dispatch_table: [OPS_COUNT]usize = std.mem.zeroes([OPS_COUNT]usize); // `code_buffer` is an executable memory region containing the machine code // to run our interpreter const code_buffer: ExecutableMemory = TemplateGenerator.generate( &dispatch_table, ); // run the interpreter! var interpreter = TemplateInterpreter.new( bytecode, code_buffer, &dispatch_table, ); interpreter.run(); }This is a design similar to HotSpot’s, which generates the machine code for each bytecode op at VM startup.
V8, on the other hand, has a separate build-step2 where each bytecode handler is generated using TurboFan into an embedded.S file which V8 then links against.
The structure of generated machine code for each bytecode op looks like this:-
<the instructions to execute the bytecode op>.
-
<the instructions to dispatch to the next bytecode op>.
Let’s first focus on step 2. How do we dispatch to the next bytecode op?
We need to read the next bytecode from the bytecode buffer, then find the address of the code that actually executes this bytecode op, then finally jump to that address.
A dispatch table will let us easily look up the address of a bytecode op’s handler. This can be represented simply as an array indexed by the opcode:
var dispatch_table: [OPS_COUNT]usize = get_dispatch_table(); const addr_for_iadd_op = dispatch_table[Op.iadd];Now I’ll show what the asm will look like to dispatch to the next instruction. I’ll use some fake register names to make it easy to read:
-
rbcp -> the register which holds the pointer to the current bytecode instruction
-
rdispatch -> the register which holds the base address to the dispatch table
step_amount here is how large the bytecode instruction is in bytes.
The dispatch code needs only 3 instructions!
Now let’s talk about what the generated machine code for each bytecode op handler will look like.This will be fairly trivial for most bytecode ops as a fair amount of them will have an analogous CPU instruction (e.g. the add bytecode op can use the CPU’s add instruction).
The next question is: where do values go?
For stack-based interpreters, the answer is fairly obvious: we can use the actual stack, the hardware stack.
There are some nice benefits to doing so:
-
CPUs already have a dedicated SP register we can use.
-
we don’t need to worry about growing the stack: the OS will do it for us3.
-
this can make OSR’ing into JIT’ed code cheaper as mentioned earlier
The stack is also conveniently a place where we can store locals.
Despite being register-based, V8 uses the stack to store registers and locals too4.
So a handler for an iadd bytecode op looks like this in a switch-based bytecode interpreter:
.iadd => { // pop `b` from the stack const b = pop(); // pop `a` from the stack const a = pop(); // push `a + b` onto the stack push(a + b); },What would the asm look like for our template interpreter?
You might do something like this:
; pop a and b, move sp up by 16 bytes ; (note that the stack grows downward and shrinks upward) ldp x9, x10, [sp], #16 ; add them add x11, x10, x9 ; move sp down by 8 bytes, store x11 to it str x11, [sp, #-8]!Which is fine, but we’re actually leaving some performance on the table.
To best illustrate, imagine we had the following bytecode instructions:
const_val_1 incrementThe sequence of events would look like:
-
const_val_1: push 1 onto the stack
-
increment: pop the top of the stack, add 1 to it, then push it back onto the stack
The asm would look like:
;; const_val_1 ; mov 1 into x9 mov x9, #1 ; push it to the stack str x9, [sp], #-8 <dispatch code> ;; increment ; pop from the stack ldr x9, [sp, #8]! ; add 1 add x9, x9, #1 ; push it to the stack str x9, [sp], #-8You’ll notice we push the value of x9 onto the stack only to immediately pop it back onto x9… that’s totally redundant!
This ends up being a fairly common pattern in sequences of bytecode instructions. Is there a way we can avoid it?
There is something we can do to avoid those unnecessary stack pushes and pops.We’ll use a dedicated register to signify the top of the stack. This is a technique employed by HotSpot and V85 (but differently, as V8’s interpreter is register-based).
Since we’re in aarch64 I’m going to choose x0, this is also the register which holds the return value of a function, meaning we can directly move values into it and return.
So the asm we just looked at would instead be this:
;; const_val_1 mov x0, #1 <dispatch code> ;; increment add x0, x0, #1Which is pretty tight and nice. We not only eliminated the redundant loads and stores to the stack, but in this case we eliminated using the stack entirely.
However this won’t apply to every sequence of bytecode instructions.
Let’s say you had these two bytecode instructions:
const_val_1 const_val_2 iaddNaively just replacing push(v) with mov x0, v would cause the first two const_val instructions to overwrite each other:
;; const_val_1 mov x0, #1 <dispatch code> ;; const_val_2 mov x0, #2The best solution would be to have the first const_val instruction actually push to the stack, but let the second one be placed in our dedicated register.
How can we do that?
Here’s how Hotspot gets around this.It works by first noting for each bytecode op:
-
what does it expect to be on the top of the stack? (e.g. what is inside the x0 register?)
-
what does it push to the top of the stack? (e.g. what does it put onto the x0 register)
For example, the iadd instruction expects an integer on the top of the stack, and will push an integer onto the stack. We’ll use this notation to describe this:
int -> iadd -> intNotice that it is slightly different than just the parameters of the op (iadd wants to pop off 2 integers from the stack), this just describes what happens to the top of the stack.
As another example, the const_val op takes no input and leaves an integer on the stack:
void -> const_val_N -> intWe’ll call this the input “top-of-stack state” and the output “top-of-stack state” for each bytecode op. We’ll abbreviate “top-of-stack” to TOS, it would look like this in code:
const TosState = enum(u8) { void = 0, int = 1, };Now we can do something interesting, if we execute a bytecode instruction and the TOS state is not what we expect, we can simply generate more code to make it look the way we want.
Let’s walk through an example:
const_val_1 const_val_2By the time we execute the second const_val instruction, the TOS state is int, but the second const_val wants it to be void.
What do we do? We’ll just take the integer in x0 and put it onto the real stack!
The asm then looks like this:
;; const_val_1 mov x0, #1 <dispatch code> ;; const_val_2 ; store x0 onto the stack str x0, [sp, #-8]! mov x0, #2Now here’s the cool part. If the TOS state is what we expect, we can just skip the str instruction.
This means a bytecode instruction will have multiple entrypoints depending on the TOS state.
To make this work we’ll need to update the dispatch table to be a 2D array:
const dispatch_table: [TOS_COUNT][OPS_COUNT]usize = get_dispatch_table(); const addr = dispatch_table[TosState.int][Opcode.const_val_2];And the generated code for const_val_2:
;; =dispatch_table[TosState.int][Opcode.const_val_2] str x0, [sp, #-8]! ;; =dispatch_table[TosState.void][Opcode.const_val_2] mov x0, #2I added comments to denote that the address of the first line will be stored in dispatch_table[TosState.int][Opcode.iadd] and the second line will be the address stored in dispatch_table[TosState.void][Opcode.iadd].
We can talk all we want about why we think the template interpreter can be faster than a switch-based or direct-threaded approach, but modern CPUs are extraordinarily complex machines with many different types of optimizatons, which makes it hard to actually reason about performance from first-principles.The most illustrative way to compare the performance of these styles of interpreters is to actually benchmark them!
So I built a template interpreter in Rust, then had Claude generate a switch-based and direct-threaded interpreter and a tail-call interpreter, then benchmarked them.
Here are the results:
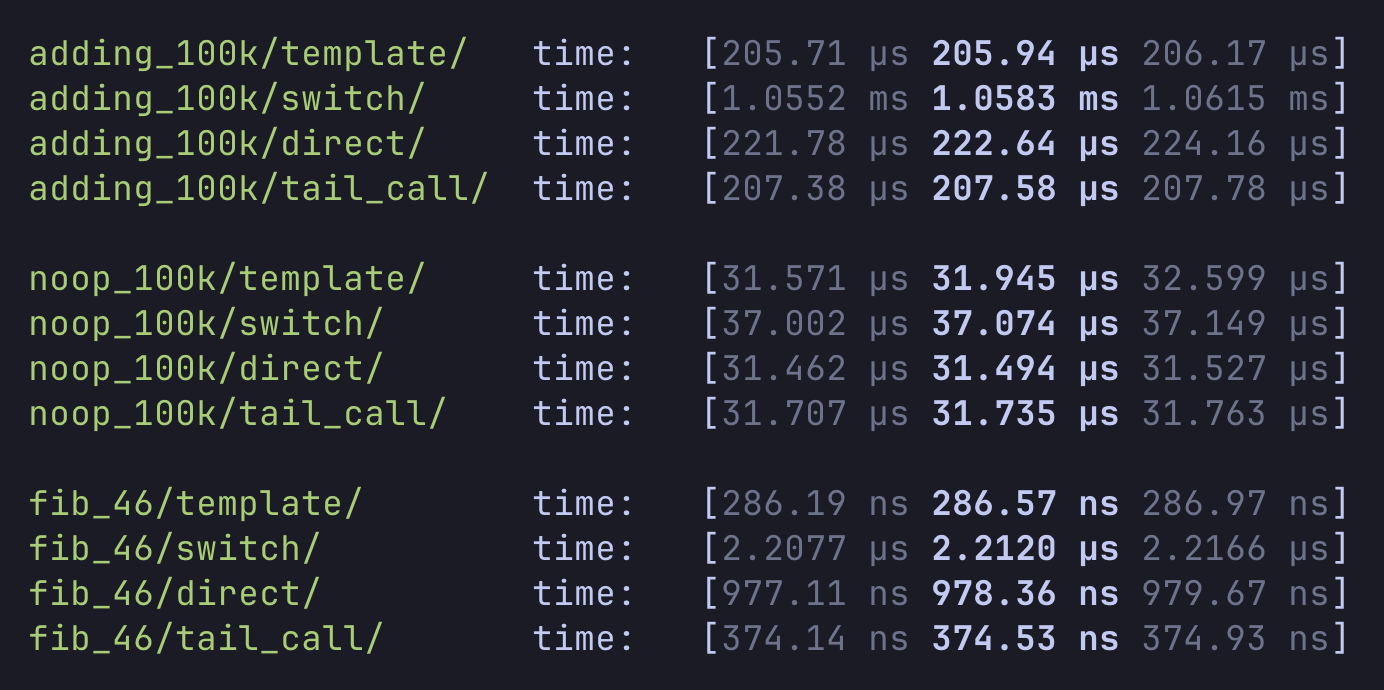
They all run three functions which are designed to bench different things:
-
Adding numbers 100k times: measures dispatch overhead and stack manipulation
-
Running a “noop” instruction 100k times: designed to measure pure dispatch overhead
-
Running fibonacci(46): designed to be a more real program with a combination of arithmetic and branching
From the results we see that the template interpreter is faster in all cases, which is to be expected.
From the noop benchmark, we see that all the interpreters come pretty close together, suggesting that they are fairly equal in terms of instruction dispatch overhead. By looking at the compiler output for the switch and direct-threaded interpreters, I noticed that several hot variables did get pinned to a dedicated register, for example the dispatch table and the pc variables. However, the bytecode handler functions are pretty trivial and not as representative of a real interpreter.
The fibonacci(46) results show the largest performance gap, with the template interpreter being ~2.5x faster than the direct-threaded interpreter. This code uses a lot of getting/setting locals, which the template interpreter may be more suited for because it keeps the top of stack in a dedicated register.
Interestingly, the switch interpreter performed relatively poorly on both the adding and fibonacci benchmark. I think this is due to the compiler generating some suboptimal code6.
Also keep in mind these interpreters are pretty simple and just doing arithmetic and control flow. There’s a lot missing: objects, function calling, etc.
Note that missing from the benchmarks is measuring how the presence of slow-paths affects the performance of the interpreter. In theory, this would lead to the compiler generating worse code.
The most interesting result is how the tail-call interpreter performed pretty competitively with the template interpreter. This notable because a tail-call interpreter is much easier to write than one in asm.
If you want to see the actual code for the four interpreters, check out the repo.
I found this to be a really interesting style of interpreter, had a lot of fun reading the Hotspot and V8 code, and learning some more aarch64 asm along the way.Its main drawback is the high implementation cost. V8 mostly avoids this by building atop its existing optimizing JIT compiler which supports multiple CPU architectures. In Hotspot, there’s about 250k lines of code to support 7 CPU architectures7.
It seems only useful if you want to make OSR jumps cheap from interpreter to JIT and back.
An interpreter style which compilers seem to optimize well, and one that has dramatically less implementation cost, is designing the interpreter to use only tail calls. This would be the style of interpreter I would build today.
Special thanks Max Bernstein’s blog (a great blog if you’re interested in compilers and interpreters) which introduced me to the concept of a “template interpreter” in this post!
Hotspot:

