.png)

 Diptanu Choudhury
Diptanu Choudhury
May 15, 2025
As LLMs and AI agents take on high-stakes enterprise workflows, one problem keeps surfacing: bad data breaks everything. Even the best models hallucinate or fail when their inputs are fragmented or incomplete. That not only erodes trust, it stalls real-world AI adoption.
In industries like finance and healthcare, a single misread field in a contract or statement can trigger failed automations, bad decisions, or regulatory risk. The documents are dense, varied, and never follow a single reading order. A bank statement, for example, might include metadata, account summaries, transaction tables, and signatures, all structured differently on the same page.
Most ingestion systems still treat documents as one continuous flow, applying uniform parsing logic across the page. End-to-end models struggle with complex layouts (as shown in OCRBench). Pipeline-based systems are modular, but brittle, what works for SEC filings might fail on ACORD forms.
Tensorlake Cloud changes that. It's a fully managed platform that turns messy, unstructured documents into clean, structured data, ready for reasoning, search, automation, and safe use in AI-driven workflows.
Document Ingestion: Parsing with human-like comprehension
To scale AI agents in production, we need ingestion systems that understand that documents are multi-modal, multi-layout, semantically segmented artifacts, and parse them accordingly. And solving layout variability isn’t just about better OCR, it’s about understanding documents the way a person would.
Traditional document parsing pipelines typically rely on either a single, general-purpose model or a rigid sequence of specialized stages (e.g. layout detection, OCR, classification, extraction). While these systems can work on simple, homogenous documents, to achieve accurate parsing and data retrieval, LLMs need structured data grounded in layout understanding and contextual segmentation of complex documents.
Tensorlake’s Document Ingestion API was built from the ground up to do exactly that, using a distributed, dynamic graph of specialized models that collaborate to analyze structure, layout, and content within the context of the full document. Knowing documents have information in many formats (e.g. text, tables, charts, images, formulas), Tensorlake proactively switches between text recognition, table structure understanding, and chart understanding models to parse each segment of the document.
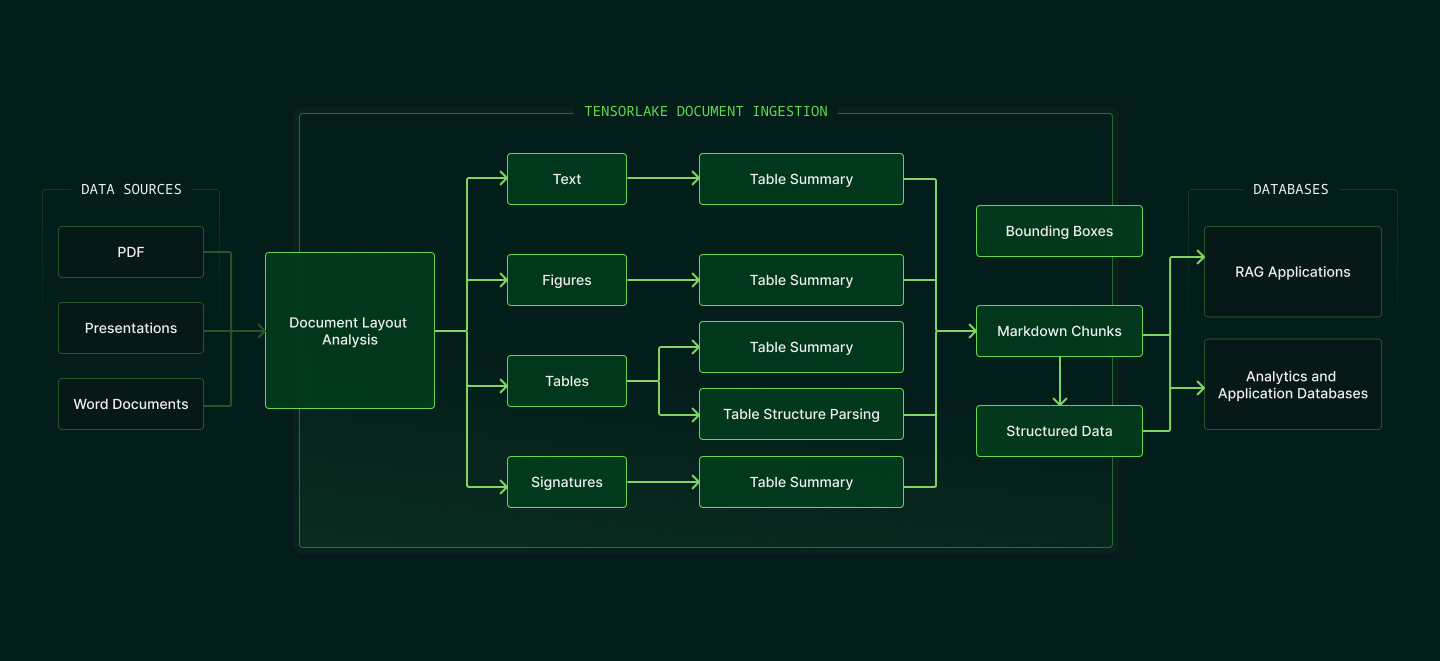
Each document is first deconstructed by a layout-aware model that identifies logical clusters: tables, headers, paragraphs, signatures, and more. Then, specialized parsers are applied to each cluster to extract the right content from the right place, whether it’s a chart, a formula, a checkbox, or a strikethrough clause in a contract.
This approach doesn’t just make parsing more robust. It makes the extracted data more complete, more reliable, and more aligned with how humans interpret meaning. That’s what AI models need to produce relevant, grounded responses. And that’s what makes Tensorlake different.
The result is clean, structured JSON that align to your schema or markdown chunks; ready to be used in RAG pipelines, fine-tuning datasets, search indexes, or downstream decision systems. Whether you’re extracting transactions from bank statements, line items from purchase orders, or application answers from scanned forms, Tensorlake parses them like a person would, yet at scale, and with consistency.
Workflows: Code-first data orchestration
In most real-world applications, ingestion is just the first step. Parsed documents need to be enriched, validated, chunked, embedded, transformed, and then routed into downstream systems like databases, vector stores, analytics engines, or LLMs. Today, building this kind of workflow requires stitching together an orchestration engine like Airflow, a map-reduce compute system like Spark or Ray, plus dashboards, storage, and custom scripts to hold it all together.
Tensorlake replaces all of that with a single orchestration layer. Using our Data Orchestration API, you can define workflows in code, from ingestion through transformation to final output, and deploy them to a fully managed, serverless backend. No Airflow. No Spark. No infrastructure to maintain.
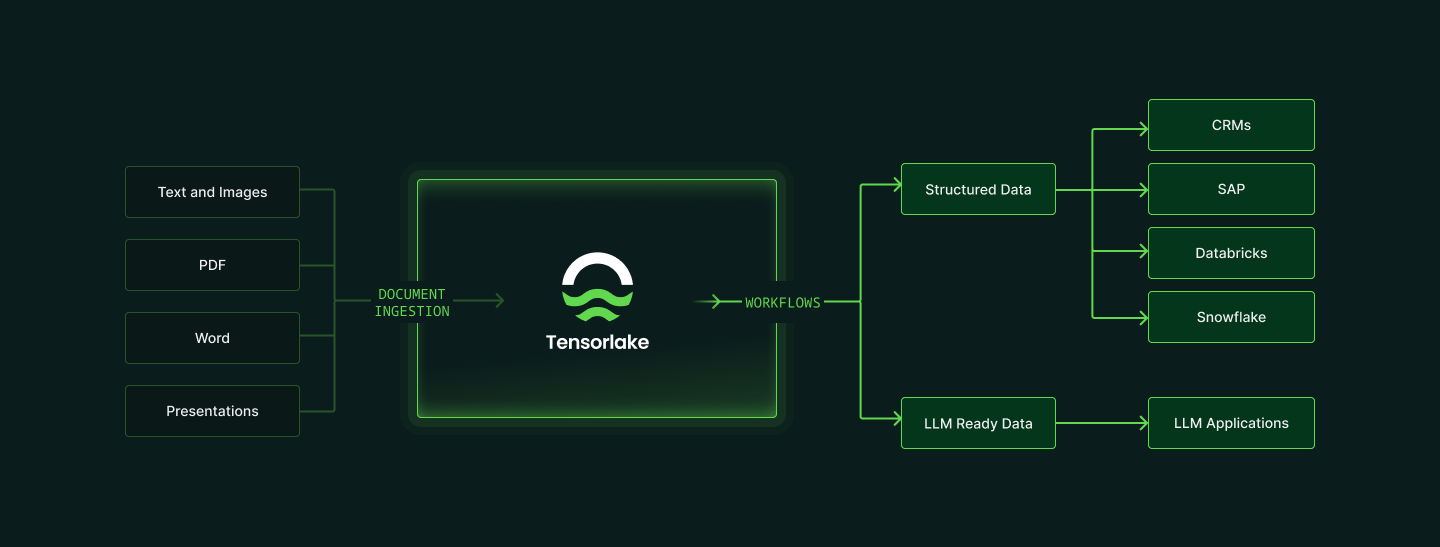
This orchestration engine is backed by Tensorlake’s high-performance compute architecture, built specifically for AI-scale workloads. It dynamically allocates GPU and CPU resources and separates the control and data planes, allowing thousands of documents to be processed concurrently across public cloud or private networks.
Tensorlake guarantees every document is processed without dropped files, silent failures, or patchwork recovery jobs. Your knowledge base, embeddings store, and downstream systems always receive the full, structured dataset.
Tailored intelligence for high-stakes industries
Tensorlake’s core parsing engine is built for complex, high-stakes documents, and it doesn’t stop there. We’ve integrated key features that streamline real-world workflows and eliminate brittle preprocessing logic.
These capabilities aren’t bolted on, they’re native to Tensorlake’s engine. That means less time spent maintaining custom logic, and more time moving from ingestion to insight.
Enterprise ready from day one
Tensorlake is already in production at large financial institutions, healthcare providers, and public utilities - organizations that can't afford dropped fields, missing documents, or hallucinated data. Whether you're processing thousands of regulatory filings a day or verifying signatures on high-value contracts, you need infrastructure that won't compromise on reliability, compliance, or performance.
To that end, Tensorlake supports full VPC deployments and private network execution, and is weeks away from SOC 2 Type II compliance. It integrates natively with enterprise systems like S3, SAP, and SharePoint, and can write structured results directly to your data warehouse or internal systems. For organizations with domain-specific needs, Tensorlake also offers private model fine-tuning and custom schema definitions, giving you full control over accuracy and performance.
Start Building Today
Tensorlake Cloud is now generally available, and getting started takes just a few minutes. Whether you’re working on a proof of concept or rolling out a mission-critical document pipeline, Tensorlake gives you everything you need to go from raw documents to structured, reliable data, without writing brittle parsing code.
Here’s how you can get started:
- Explore the playground: Try out sample documents or upload real documents and see Tensorlake’s parsing engine in action.
- Use the Python SDK: Integrate Tensorlake directly into your stack using our Python SDK.
- Request enterprise onboarding: If you're working on a production use case or need private deployment options, contact us for a tailored onboarding plan.
- Join the community: Connect with the team and other builders in our Slack community.
With Tensorlake, your AI workflows don’t start with patchy data, they start with a rock-solid foundation. Let’s build something that lasts.



