.png)

dynomight.net/wanting ← If you share this post, kindly use this URL.

I haven’t followed AI safety too closely. I tell myself that’s because tons of smart people are working on it and I wouldn’t move the needle. But I sometimes wonder, is that logic really unrelated to the fact that every time I hear about a new AI breakthrough, my chest tightens with a strange sense of dread?
AI is one of the most important things happening in the world, and possibly the most important. If I’m hunkering in a bunker years from now listening to hypersonic kill-bots laser-cutting through the wall, will I really think, boy am I glad I stuck to my comparative advantage?
So I thought I’d take a look.
I stress that I am not an expert. But I thought I’d take some notes as I try to understand all this. Ostensibly, that’s because my outsider status frees me from the curse of knowledge and might be helpful for other outsiders. But mostly, I like writing blog posts.
So let’s start at the beginning. AI safety is the long-term problem of making AI be nice to us. The obvious first question is, what’s the hard part? Do we know? Can we say anything?
To my surprise, I think we can: The hard part is making AI want to be nice to us. You can’t solve the problem without doing that. But if you can do that, then the rest is easier.
This is not a new idea. Among experts, I think it’s somewhere between “the majority view” and “near-consensus”. But I haven’t found many explicit arguments or debates, meaning I’m not 100% sure why people believe it, or if it’s even correct. But instead of cursing the darkness, I thought I’d construct a legible argument. This may or may not reflect what other people think. But what is a blog, if not an exploit on Cunningham’s Law?
Here’s my argument that the hard part of AI safety is making AI want to do what we want:
To make an AI be nice to you, you can either impose restrictions, so the AI is unable to do bad things, or you can align the AI, so it doesn’t choose to do bad things.
Restrictions will never work.
You can break down alignment into making the AI know what we want, making it want to do what we want, and making it succeed at what it tries to do.
Making an AI want to do what we want seems hard. But you can’t skip it, because then AI would have no reason to be nice.
Human values are a mess of heuristics, but a capable AI won’t have much trouble understanding them.
True, a super-intelligent AI would likely face weird “out of distribution” situations, where it’s hard to be confident it would correctly predict our values or the effects of its actions.
But that’s OK. If an AI wants to do what we want, it will try to draw a conservative boundary around its actions and never do anything outside the boundary.
Drawing that boundary is not that hard.
Thus, if an AI system wants to do what we want, the rest of alignment is not that hard.
Thus, making AI systems want to do what we want is necessary and sufficient-ish for AI safety.
I am not confident in this argument. I give it a ~35% chance of being correct, with step 8 the most likely failure point. And I’d give another ~25% chance that my argument is wrong but the final conclusion is right.
(Y’all agree that a low-confidence prediction for a surprising conclusion still contains lots of information, right? If we learned there was a 10% chance Earth would be swallowed by an alien squid tomorrow, that would be important, etc.? OK, sorry.)
I’ll go quickly through the parts that seem less controversial.
Roughly speaking, to make AI safe you could either either impose restrictions on AI so it’s not able to do bad things, or align AI so it doesn’t choose to do bad things. You can think of these as not giving AI access to nuclear weapons (restrictions) or making the AI choose not to launch nuclear weapons (alignment).
I advise against giving AI access to nuclear weapons. Still, if an AI is vastly smarter than us and wants to hurt us, we have to assume it will be able to jailbreak any restrictions we place on it. Given any way to interact with the world, it will eventually find some way to bootstrap towards larger and larger amounts of power. Restrictions are hopeless. So that leaves alignment.
Here’s a simple-minded decomposition:
The Knowing problem: Making AI know what we want.
The Wanting problem: Making AI want to do what we want.
The Success problem: Making AI succeed at what it tries to do.
I sometimes wonder if that’s a useful decomposition. But let’s go with it.
The Wanting problem seems hard, but there’s no way around it. Say an AI knows what we want and succeeds at everything it tries to do, but doesn’t care about what we want. Then, obviously, it has no reason to be nice. So we can’t skip Wanting.
Also, notice that even if you solve the Knowing and Success problems really well, that doesn’t seem to make the Wanting problem any easier. (See also: Orthogonality)
My take on human values is that they’re a big ball of heuristics. When we say that some action is right (wrong) that sort of means that genetic and/or cultural evolution thinks that the reproductive fitness of our genes and/or cultural memes is advanced by rewarding (punishing) that behavior.
Of course, evolution is far from perfect. Clearly our values aren’t remotely close to reproductively optimal right now, what with fertility rates crashing around the world. But still, values are the result of evolution trying to maximize reproductive fitness.
Why do we get confused by trolley problems and population ethics? I think because… our values are a messy ball of heuristics. We never faced evolutionary pressure to resolve trolley problems, so we never really formed coherent moral intuitions about them.
So while our values have lots of quirks and puzzles, I don’t think there’s anything deep at the center of them, anything that would make learning them harder than learning to solve Math Olympiad problems or translating text between any pair of human languages. Current AI already seems to understand our values fairly well.
Arguably, it would be hard to prevent AI from understanding human values. If you train an AI to do any sufficiently difficult task, it needs a good world model. That’s why “predicting the next token” is so powerful—to do it well, you have to model the world. Human values are an important and not that complex part of that world.
The idea of “distribution shift” is that after super-intelligent AI arrives, the world may change quite a lot. Even if we train AI to be nice to us now, in that new world it will face novel situations where we haven’t provided any training data.
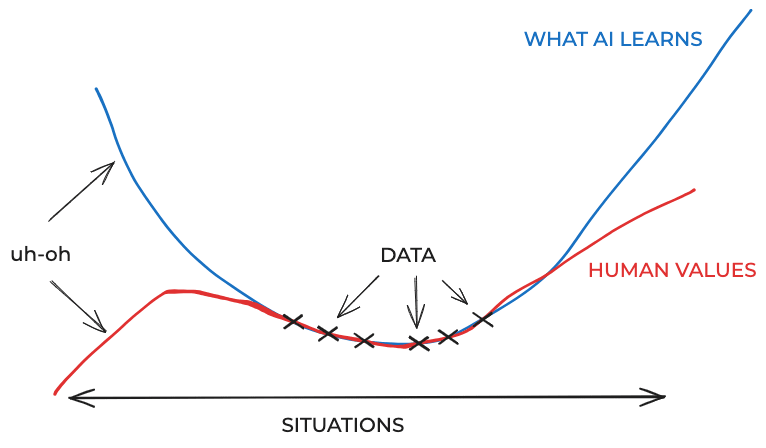
This could conceivably create problems both for AI knowing what we want, or for AI succeeding at what it tries to do.
For example, maybe we teach an AI that it’s bad to kill people using lasers, and that it’s bad to kill people using viruses, and that it’s bad to kill people using radiation. But we forget to teach it that it’s bad to write culture-shifting novels that inspire people to live their best lives but also gradually increase political polarization and lead after a few decades to civilizational collapse and human extinction. So the AI intentionally writes that book and causes human extinction because it thinks that’s what we want, oops.
Alternatively, maybe a super-powerful AI knows that we don’t like dying and it wants to help us not die, so it creates a retrovirus that spreads across the globe and inserts a new anti-cancer gene in our DNA. But it didn’t notice that this gene also makes blind and deaf, and we all starve and die. In this case, the AI accidentally does something terrible, because it has so much power that it can’t correctly predict all the effects of its actions.
What are your values? Personally, very high on my list would be:
If an AI is considering doing anything and it’s not very sure that it aligns with human values, then it should not do it without checking very carefully with lots of humans and getting informed consent from world governments. Never ever do anything like that.
And also:
AIs should never release retroviruses without being very sure it’s safe and checking very carefully with lots of humans and getting informed consent from world governments. Never ever, thanks.
That is, AI safety doesn’t require AIs to figure out how to generalize human values to all weird and crazy situations. And it doesn’t need to correctly predict the effects of all possible weird and crazy actions. All that’s required is that AIs can recognize that something is weird/crazy and then be conservative.
Clearly, just detecting that something is weird/crazy is easier than making correct predictions in all possible weird/crazy situations. But how much easier?
(I think this is the weakest part of this argument. But here goes.)
Would I trust an AI to correctly decide if human flourishing is more compatible with a universe where up quarks make up 3.1% of mass-energy and down quarks 1.9% versus one where up quarks make up 3.2% and down quarks 1.8%? Probably not. But I wouldn’t trust any particular human to decide that either. What I would trust a human to do is say, “Uhhh?” And I think we can also trust AI to know that’s what a human would say.
Arguably, “human values” are a thing that only exist for some limited range of situations. As you get further from our evolutionary environment, our values sort of stop being meaningful. Do we prefer an Earth with 100 billion moderately happy people, or one with 30 billion very happy people? I think the correct answer is, “No”.
When we have coherent answers, AI will know what they are. And otherwise, it will know that we don’t have coherent answers. So perhaps this is a better picture:

And this seems… fine? AI doesn’t need to Solve Ethics, it just needs to understand the limited range of human values, such as they are.
That argument (if correct) resolves the issue of distribution shift for values. But we still need to think about how distribution shift might make it harder for AI to succeed at what it tries to do.
If AI attains godlike power, maybe it will be able to change planetary orbits or remake our cellular machinery. With this gigantic action space, it’s plausible that there would be many actions with bad but hard-to-predict effects. Even if AI only chooses actions that are 99.999% safe, if it makes 100 such actions per day, calamity is inevitable.
Sure, but surely we want AI to fake take false discovery rates (“calamitous discovery rates”?) into account. It should choose a set of actions such that, taken together, they are 99.999% safe.
Something that might work in our favor here is that verification is usually much easier than generation. Perhaps we could ask the AI to create a “proof” that all proposed actions are safe and run that proof by a panel of skeptical “red-team” AIs. If any of them find anything confusing at all, reject.
I find the idea that “drawing a safe boundary is not that hard” fairly convincing for human values, but not only semi-convincing for predicting the effects of actions. So I’d like to see more debate on this point. (Did I mention that this is the weakest part of my argument?)
It AI truly wants to do what we want, then the only thing it really needs to know about our values is “be conservative”. This makes the Knowing and Success problems much easier. Instead of needing to know how good all possible situations are for humans, it just needs to notice that it’s confused. Instead of needing to succeed at everything it tries, it just needs to notice that it’s unsure.
Since restrictions won’t work, you need to do alignment. Wanting is hard, but if you can solve Wanting, then you only need to solve easier version of Knowing and Success. So Wanting is the hard part.
Again, I think the idea that “wanting is the hard part” is the majority view. Paul Christiano, for example, proposes to call an AI “intent aligned” if it is trying to do what some operator wants it to do and states:
[The broader alignment problem] includes many subproblems that I think will involve totally different techniques than [intent alignment] (and which I personally expect to be less important over the long term).
Richard Ngo also seems to explicitly endorse this view:
Rather, my main concern is that AGIs will understand what we want, but just not care, because the motivations they acquired during training weren’t those we intended them to have.
Many people have also told me this is the view of MIRI, the most famous AI-safety organization. As far as I can see, this is compatible with the MIRI worldview. But I don’t feel comfortable stating as a fact that MIRI agrees, because I’ve never seen any explicit endorsement, and I don’t fully understand how it fits together with other MIRI concepts like corrigibility or coherent extrapolated volition.
Why might this argument be wrong?
(I don’t think so, but it’s good to be comprehensive.)
Wanting seems hard, to me. And most experts seem to agree. But who knows, maybe it’s easy.
Here’s one esoteric possibility. Above, I’ve implicitly assumed that an AI could in principle want anything. But it’s conceivable that only certain kinds of wants are stable. That might make Wanting harder or even quasi-impossible. But it could also conceivably make it easy. Maybe once you cross some threshold of intelligence, you become one with the universal mind and start treating all other beings as a part of yourself? I wouldn’t bet on it.
A crucial part of my argument is the idea that it would be easy for AI to draw a conservative boundary when trying to predict human values or effects of actions. I find that reasonably convincing for values, but less so for actions. It’s certainly easier than correctly generalizing to all situations, but it might still be very hard.
It’s also conceivable that AI creates such a large action space that even if humans were allowed to make every single decision, we would destroy ourselves. For example, there could be an undiscovered law of physics that says that if you build a skyscraper taller than 900m, suddenly a black hole forms. But physics provides no “hints”. The only way to discover that is to build the skyscraper and create the black hole.
More plausibly, maybe we do in fact live in a vulnerable world, where it’s possible to create a planet-destroying weapon with stuff you can buy at the hardware store for $500, we just haven’t noticed yet. If some such horrible fact is lurking out there, AI might find it much sooner than we would.
Finally, maybe the whole idea of an AI “wanting” things is bad. It seems like a useful abstraction when we think about people. But if you try to reduce the human concept of “wanting” to neuroscience, it’s extremely difficult. If an AI is a bunch of electrons/bits/numbers/arrays flying around, is it obvious that the same concept will emerge? I
I’ve been sloppy in this post in talking about AIs respecting “our” values or “human values”. That’s probably not going to happen. Absent some enormous cultural development, AIs will be trained to advance the interests of particular human organizations. So even if AI alignment is solved, it seems likely that different groups of humans will seek to create AIs that help them, even at some expense to other groups.
That’s not technically a flaw in the argument, since it just means Wanting is even harder. But it could be a serious problem, because…
Suppose you live in Country A. Say you’ve successfully created a super-intelligent AI that’s very conservative and nice. But people in Country B don’t like you, so they create their own super-intelligent AI and ask it to hack into your critical systems, e.g. to disable your weapons or to prevent you from making an even-more-powerful AI.
What happens now? Well, their AI is too smart to be stopped by the humans in Country A. So your only defense will be to ask your own AI to defend against the hacks. But then, Country B will probably notice that if they give their AI more leeway, it’s better at hacking. To defend you, you might need to also give your AI more leeway. The equilibrium might be that both AIs are told that, actually, they don’t need to be very conservative at all.
Finally, here’s some stuff I found useful, from people who may or may not agree with the above argument:
The Core of the Alignment Problem is…, by Thomas Larsen et al.
The Compendium, by Connor Leahy et al.
A central AI alignment problem: capabilities generalization, and the sharp left turn, by Nate Soares
Corrigibility, by Nate Soares et al.
AGI Ruin: A List of Lethalities, by Eliezer Yudkowsky
Where I agree and disagree with Eliezer, by Paul Christiano
(Untitled comment), by Vanessa Kosoy
(Untitled comment), by Paul Christiano
Superforecating AI, by the Good Judgment project
Is Power-Seeking AI an Existential Risk?, by Joseph Carlsmith
AGI safety from first principles, by Richard Ngo
A Three-Facet Framework for AI Alignment, by Grace Kind



