.png)

At a recent CEO dinner in Menlo Park, someone asked the familiar question: Are we in an AI bubble?
One of the dinner guests — a veteran of multiple Silicon Valley cycles — reframed the conversation entirely. Not a bubble, she argued, but a wildfire. The metaphor landed immediately. Wildfires don’t just destroy; they’re essential to ecosystem health. They clear the dense underbrush that chokes out new growth, return nutrients to the soil, and create the conditions for the next generation of forest to thrive.
As I have reflected on the wildfire metaphor, a framework has emerged that revealed something deeper, built on her reframing. It offered a taxonomy for understanding who survives, who burns, and why—with specific metrics that separate the fire-resistant from the flammable.
The first web cycle burned through dot-com exuberance and left behind Google, Amazon, eBay, and PayPal — the hardy survivors of Web 1.0. The next, driven by social and mobile, burned again in 2008–2009, clearing the underbrush for Facebook, Airbnb, Uber, and the offspring of Y Combinator. Both fires followed the same pattern: excessive growth, sudden correction, then renaissance.
Now, with AI, we are once again surrounded by dry brush.
The coming correction won’t be a bubble bursting—it will be a wildfire. And understanding that distinction changes everything about how to survive—and thrive—in what comes next.
When the brush grows too dense, sunlight can’t reach the ground. The plants aren’t competing against the environment — they’re competing against each other for light, water, and nutrients.
That’s what Silicon Valley feels like right now.
Capital is abundant — perhaps too abundant. But talent? That’s the scarce resource. Every promising engineer, designer, or operator is being courted by three, five, ten different AI startups — often chasing the same vertical, whether it’s coding copilots, novel datasets, customer service, legal tech, or marketing automation.
The result is an ecosystem that looks lush from above — green, growing, noisy — but underneath, the soil is dry. It’s hard to grow when everyone’s roots are tangled.
And in that kind of forest, fire isn’t a catastrophe. It’s a correction.
Wildfires don’t just destroy ecosystems — they reshape them. Some species ignite instantly. Others resist the flames. A few depend on the fire to reproduce.
The same is true for startups.
These are the dry grasses and resinous pines of the ecosystem — startups that look vibrant in a season of easy money but have no resistance once the air gets hot.
They include:
AI application wrappers with no proprietary data or distribution
Infrastructure clones in crowded categories — one more LLM gateway, one more vector database
Consumer apps chasing daily active users instead of durable users
They’re fueled by hype and ebullient valuations. When the heat rises — when capital tightens or customers scrutinize ROI — they go up in seconds.
The flammable brush serves a purpose. It attracts capital and talent into the sector. It creates market urgency. And when it burns, it releases those resources back into the soil for hardier species to absorb. The engineers from failed AI wrappers become the senior hires at the companies that survive.
Then there are the succulents, oaks, and redwoods — the incumbents that store moisture and protect their cores.
Thick bark: Strong balance sheets and enduring customer relationships.
Deep roots: Structural product-market fit in cloud, chips, or data infrastructure.
Moisture reserves: Real revenue, diversified businesses, and long-term moats.
Think Apple, Microsoft, Nvidia, Google, Amazon. They will absorb the heat and emerge stronger. When the smoke clears, these giants will stand taller, their bark charred but intact, while the smaller trees around them have burned to ash.
Some plants die back but grow again — manzanita, scrub oak, toyon. In startup terms, these are the pivots and re-foundings that follow a burn.
They’re teams with:
Deep expertise
Underground IP and data assets that survive even if the product doesn’t
A willingness to prune and start over
After the fire, they re-sprout — leaner, smarter, and better adapted to the new terrain.
This is where the real learning happens. A founder who built the wrong product with the right team in 2024 becomes the founder who builds the right product with a battle-tested team in 2027. The failure wasn’t wasted—it was stored underground, like nutrients in roots, waiting for the next season.
Finally come the wildflowers. Their seeds are triggered by heat — they can’t even germinate until the old growth is gone.
These are the founders who start after the crash. They’ll hire from the ashes, build on cheaper infrastructure, and learn from the mistakes of those who burned. LinkedIn in 2002, Stripe in 2010, Slack in 2013 — all fire followers.
The next great AI-native companies — the ones that truly integrate intelligence into workflows rather than just decorating them — will likely emerge here. And critically, the inference layer—where AI models actually run in production—represents the next major battleground. As compute becomes commoditized and agentic tools proliferate, the race won’t be about who trains the biggest models but who can deliver intelligence most efficiently at scale.
Every few decades, Silicon Valley becomes overgrown. Web 1.0 and Web 2.0 both proved the same truth: too much growth chokes itself.
The Web 1.0 crash wasn’t just startups disappearing — it was noise disappearing. The Web 2.0 downturn, driven more by the mortgage crisis than the market itself, followed the same dynamic: overfunded competitors fell away, talent dispersed, and the survivors hired better, moved faster, and built stronger. Savvy companies even used the moment to get leaner, cutting underperformers and upgrading positions from entry-level to executive with hungry refugees from failed competitors.
That redistribution of talent may be the single most powerful outcome of any crash. Many of Google’s best early employees — the architects of what became one of the most durable business models in history — were founders or early employees of failed Web 1.0 startups.
And it wasn’t just talent — it was a particular kind of talent: entrepreneurial, restless, culturally impatient. That DNA shaped Google’s internal ethos — experimental, aggressive, always in beta — and radiated outward into the broader ecosystem for the next 10 to 20 years. The fire didn’t just destroy; it reallocated intelligence and rewired culture.
The 2000 wildfire was a full incineration. Infrastructure overbuild, easy capital, and speculative exuberance burned away nearly all profitless growth stories. Yet what remained were root systems — data centers, fiber optics, and the surviving companies that learned to grow slow and deep.
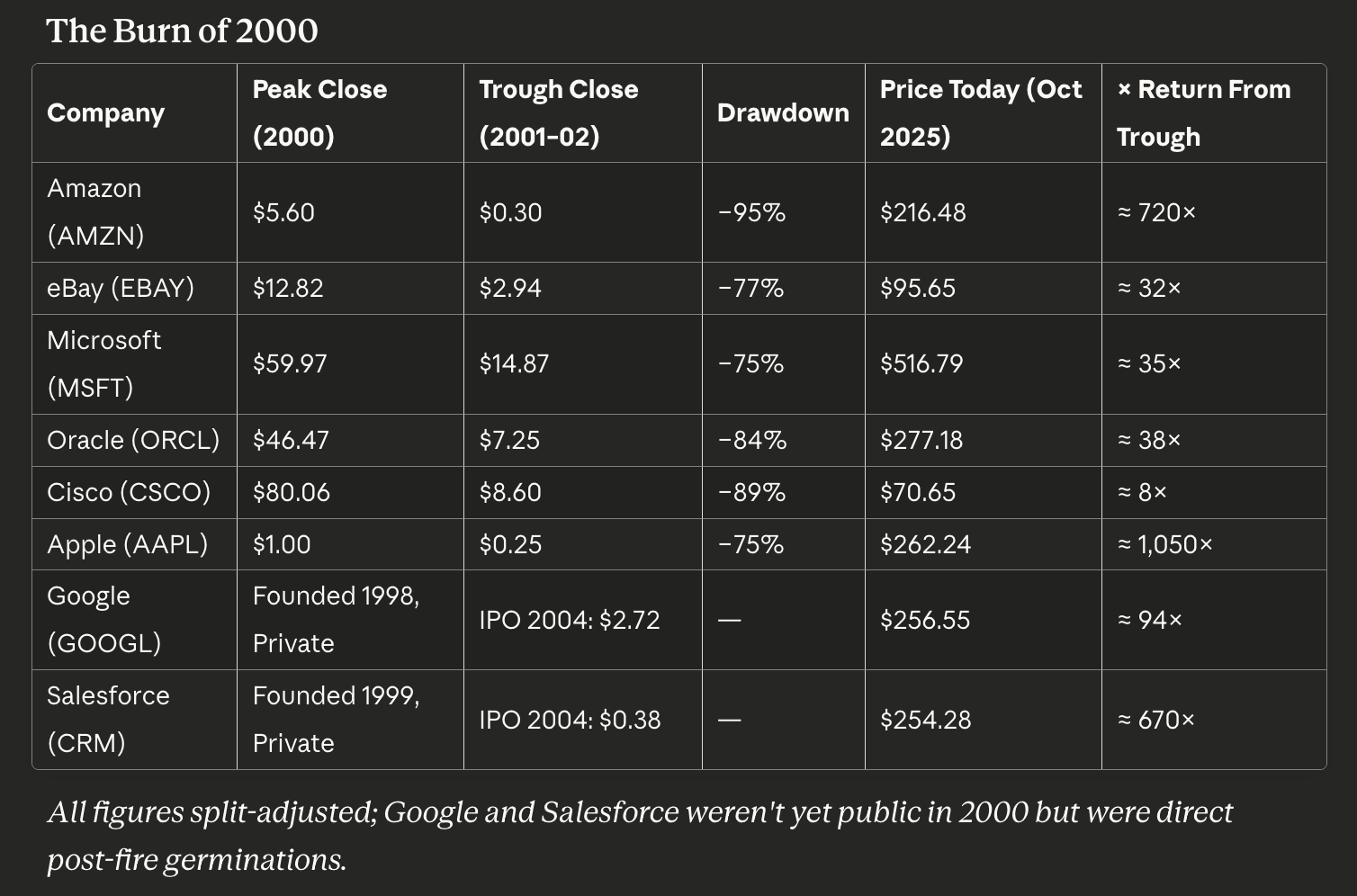
Amazon looked dead — down 95% — but emerged as the spine of digital commerce. eBay stabilized early and became the first profitable platform marketplace. Microsoft and Oracle converted their software monopolies into durable enterprise cashflows. Cisco, scorched by overcapacity, rebuilt slowly as networking became the plumbing for doing business.
By adding Apple, Google, and Salesforce, the story becomes not just one of survival — but succession. Apple didn’t merely survive the fire; it changed the climate for everything that followed. Google sprouted where others burned, fueled by the very engineers and founders whose startups perished in the blaze. Salesforce took advantage of scorched corporate budgets to sell cloud-based flexibility, defining the SaaS model.
During the late 1990s, telecom firms raised roughly $2 trillion in equity and another $600 billion in debt to fuel the “new economy.” Even the stocks that symbolized the mania followed a predictable arc. Intel, Cisco, Microsoft, and Oracle together were worth around $83 billion in 1995; by 2000, their combined market cap had swelled to nearly $2 trillion. Qualcomm rose 2,700% in a single year.
That money paid for over 80 million miles of fiber-optic cable, more than three-quarters of all the digital wiring that had ever been installed in the U.S. up to that point. Then came the collapse.
By 2005, nearly 85% of those cables sat unused, strands of dark fiber buried in the ground — overcapacity born of overconfidence. But the fiber stayed. The servers stayed. The people stayed. And that excess soon became the backbone of modern life. Within just four years of the crash, the cost of bandwidth had fallen by 90%, and the glut of cheap connectivity powered everything that came next: YouTube, Facebook, smartphones, streaming, the cloud.
That’s the paradox of productive bubbles: they destroy value on paper but create infrastructure in reality. When the flames pass, the pipes, the code, and the talent remain — ready for the next generation to use at a fraction of the cost.
The Great Recession sparked a different kind of wildfire. Web 1.0’s flames had consumed speculative infrastructure; Web 2.0’s burned through business models and illusions. Venture funding froze. Advertising budgets evaporated. Credit tightened. Yet the survivors didn’t just withstand the heat — they metabolized it.
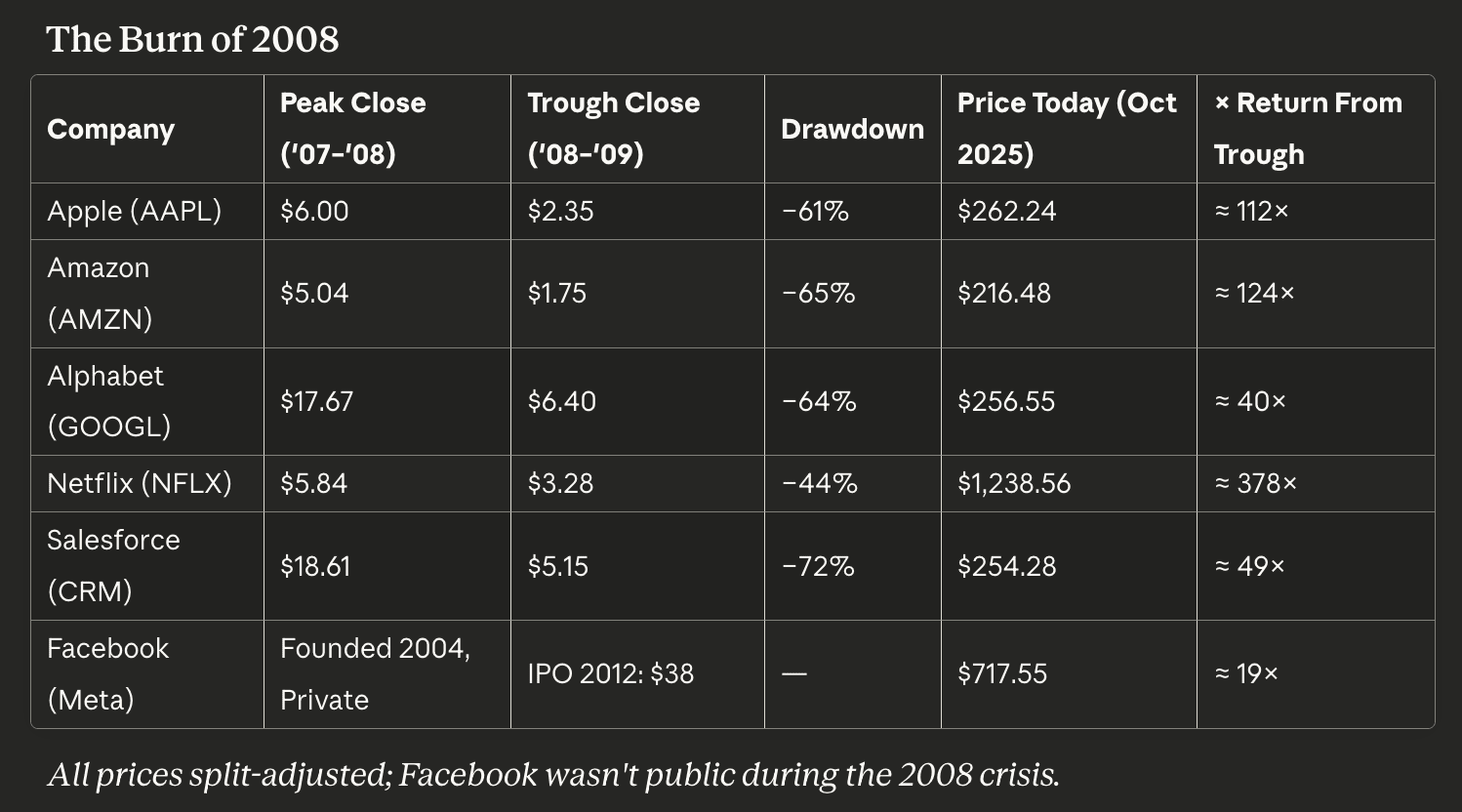
Apple turned adversity into dominance, transforming the iPhone from curiosity into cultural infrastructure. Amazon, having survived the dot-com inferno, emerged as the quiet supplier of the internet’s oxygen — AWS. Netflix reinvented itself for the streaming era, its growth literally running over the fiber laid down by the previous bubble. Salesforce proved that cloud software could thrive when capital budgets died. Google discovered that measurable performance advertising could expand even in recession. And Facebook — a seedling then — would soon root itself in the ashes, nourished by cheap smartphones and surplus bandwidth.
The 2008 fire didn’t just clear space. It selected for companies that could integrate hardware, software, and services into self-sustaining ecosystems. The result wasn’t simply recovery — it was evolution.
This cycle, though, introduces a new kind of fuel — the canopy fire.
In the past, the flames mostly consumed the underbrush: small, overvalued startups. Today, the heat is concentrated in the tallest trees themselves — Nvidia, OpenAI, Microsoft, and a handful of hyperscalers spending staggering sums with each other.
Compute has become both the oxygen and the accelerant of this market. Every dollar of AI demand turns into a dollar for Nvidia, which in turn fuels more investment into model training, which requires still more GPUs — a feedback loop of mutual monetization.
This dynamic has created something closer to an industrial bubble than a speculative one. The capital isn’t scattered across a thousand dot-coms; it’s concentrated in a few massive bilateral relationships, with complex cross-investments that blur the line between genuine deployment and recycled capital.
When the wildfire comes — when AI demand normalizes or capital costs rise — the risk isn’t dozens of failed startups; it’s a temporary collapse in compute utilization. Nvidia’s stock may not burn to ash, but even a modest contraction in GPU orders could expose how dependent the entire ecosystem has become on a few large buyers.
That’s the real canopy problem: when the tallest trees grow too close, their crowns interlock, and when one ignites, the fire spreads horizontally, not just from the ground up.
In Web 1.0, Oracle — the de facto database for all dot-coms — saw a symbolic collapse from $46 to $7 in 2000 before recovering to $79 by the launch of ChatGPT and $277 today. In Web 2.0’s wildfire, Google — the supplier of performance advertising — dropped 64% from $17 to $6 but exploded to $99 with ChatGPT’s launch and has since hit $257. In this cycle, the analog could be Nvidia — not because it lacks fundamentals, but because its customers are all drawing from the same pool of speculative heat, fueled by complex cross-investments that have elicited scrutiny about whether capital is being genuinely deployed or simply recycled.
But here’s where the AI wildfire may prove even more productive than its predecessors: the infrastructure being overbuilt today isn’t just fiber optic cable lying dormant in the ground. It’s compute capacity — the fundamental resource constraining AI innovation right now.
Today’s AI market is brutally supply-constrained. Startups can’t get the GPU allocations they need. Hyperscalers are rationing compute to their best customers. Research labs are queuing for months to train models. The bottleneck isn’t ideas or talent — it’s access to the machinery itself.
This scarcity is driving the current frenzy. Companies are signing multi-billion dollar commitments years in advance, locking in capacity at premium prices, building private data centers, and stockpiling chips like ammunition. The fear isn’t just missing the AI wave — it’s being unable to participate at all because you can’t get your hands on the compute.
But what happens after the fire?
The same pattern that played out with bandwidth in 2000 is setting up to repeat with compute in 2026. Billions of dollars are pouring into GPU clusters, data centers, and power infrastructure. Much of this capacity is being built speculatively — funded by the assumption that AI demand will grow exponentially forever.
But there’s another dynamic accelerating the buildout: a high-stakes game of chicken where no one can afford to blink first. When Microsoft announces a $100 billion data center investment, Google must respond in kind. When OpenAI commits to 10 gigawatts of Nvidia chips, competitors feel compelled to match or exceed that commitment. The fear isn’t just that AI demand might not materialize — it’s that if it does materialize and you haven’t secured capacity, you’ll be locked out of the market entirely.
This creates a dangerous feedback loop. Each massive spending announcement forces competitors to spend more, which drives up the perceived stakes, which justifies even larger commitments. No executive wants to be the one who underinvested in the defining technology of the era. The cost of being wrong by spending too little feels existential; the cost of being wrong by spending too much feels like someone else’s problem — a future quarter’s write-down, not today’s strategic failure.
It’s precisely this dynamic that creates productive bubbles. The rational individual decision (match your competitor’s investment) produces an irrational collective outcome (vast overcapacity). But that overcapacity is what seeds the next forest.
Yet there’s a critical distinction being lost in the bubble debate: not all compute is the same. The market is actually two distinct pools with fundamentally different dynamics.
The first pool is training compute — the massive clusters used to create new AI models. This is where the game of chicken is being played most aggressively. No lab has a principled way of deciding how much to spend; each is simply responding to intelligence about competitors’ commitments. If your rival is spending twice as much, they might pull the future forward by a year. The result is an arms race governed less by market demand than by competitive fear, with Nvidia sitting in the middle as the gleeful arms dealer.
The second pool is inference compute — the infrastructure that runs AI models in production, serving actual users. And here, the dynamics look entirely different.
Society’s demonstrated demand for intelligence is essentially unlimited. Every additional IQ point that can be applied to analyzing data, automating decisions, or improving productivity gets consumed immediately. The constraint isn’t demand — it’s supply. Businesses aren’t asking “do we want AI capabilities?” They’re asking “how much can we get, and how soon?”
As GPUs become commoditized and compute abundance arrives, inference capabilities will become the next major market—especially given growing demand for efficient agentic tools. LLM inference is becoming a massive race. The companies that can deliver intelligence most efficiently, at the lowest cost per token or per decision, will capture disproportionate value. This isn’t about training the biggest model anymore; it’s about running models efficiently at planetary scale.
This is fundamentally different from the dot-com bubble, which was fueled primarily by advertising spend — companies burning cash on Super Bowl commercials to acquire customers they hoped to monetize later. That was speculative demand chasing speculative value.
AI inference demand is directed at improving actual earnings. Companies are deploying intelligence to reduce customer acquisition costs, lower operational expenses, and increase worker productivity. The return isn’t hypothetical; it’s measurable and often immediate.
This suggests the AI “bubble” may have a softer landing than its predecessors. Yes, price-to-earnings ratios look inflated today. But unlike pure speculation, there’s genuine productive capacity being built. If compute costs fall dramatically post-correction while inference demand remains robust — and all evidence suggests it will — companies can simply run their models longer, use more compute-intensive approaches, or deploy intelligence to problems that are economically marginal at today’s prices but viable at tomorrow’s.
In other words: even if we massively overbuild training capacity (which seems likely), the inference side has enough latent demand to absorb the excess. The compute doesn’t sit dark; it gets repurposed from the game of chicken to the productive application of intelligence at scale.
Just as bandwidth costs collapsed by 90% within four years of the dot-com crash, making YouTube and Netflix possible, compute costs could fall dramatically in the aftermath of an AI correction. The same GPU clusters that hyperscalers are rationing today could become commodity infrastructure available to anyone with a credit card.
But here the analogy breaks down in a critical way.
Fiber optic cable has an extraordinarily long useful life — decades of productive capacity once it’s in the ground. The infrastructure built during the dot-com bubble is still carrying packets today, twenty-five years later. That’s what made it such a durable gift to the next generation: the cost was borne once, the value compounded for decades.
GPU clusters are not fiber optic cable.
The useful life of a training cluster is perhaps two to three years before it becomes uncompetitive. Chips depreciate faster than they physically wear out. A three-year-old GPU isn’t broken — it’s just obsolete, overtaken by newer architectures that offer better performance per watt, better memory bandwidth, better interconnects. In economic terms, training compute looks more like an operating expense with a short payback window than a durable capital asset.
This fundamentally changes the post-fire dynamics.
When the bubble bursts and training compute becomes abundant, yes, costs will fall. But fire followers won’t inherit state-of-the-art infrastructure the way Web 2.0 companies inherited fiber. They’ll inherit yesterday’s infrastructure — still functional, but no longer cutting-edge. If you want access to the newest, fastest compute to train competitive models, you’ll still need to pay premium prices to whoever is actively refreshing their clusters.
This creates a different kind of moat than we saw in previous cycles. The companies that survive the fire won’t just benefit from cheaper infrastructure — they’ll benefit from having already paid down the cost of the current generation while competitors are trying to catch up on older hardware. The incumbency advantage isn’t just about having compute; it’s about having the right generation of compute, continuously refreshed.
Inference compute follows different economics — once a model is trained, it can run productively on older hardware for years. But the training side may not produce the same democratization we saw with bandwidth. The fire might clear the brush, but the tallest trees will still control access to sunlight.
Yet focusing solely on compute may mean we’re watching the wrong wildfire.
Some believe the true winner of the AI race — at a national and global level — won’t be the company with the most GPUs or the best models. It will be whoever solves the energy problem.
Compute, after all, is just concentrated electricity. A modern AI data center can consume as much power as a small city. The constraint isn’t silicon; it’s kilowatts. You can manufacture more chips, but you can’t manufacture more energy without fundamental infrastructure — power plants, transmission lines, grid capacity — that takes years or decades to build.
This is where the wildfire metaphor becomes particularly instructive. We’re focused on the compute forest burning and regrowing. But beneath that visible drama, there’s a deeper question: are we building enough energy infrastructure to power the next forest at all?
The dot-com bubble left behind dark fiber that could be lit up instantly when demand returned. But idle data centers without power to run them are just expensive real estate. The real infrastructure deficit may not be compute capacity but energy generation.
If this bubble drives massive investment in power infrastructure — nuclear plants, renewable energy farms, grid modernization, advanced battery storage — that would be a genuinely durable gift to the next half-century. Energy infrastructure, unlike GPUs that become obsolete in five years, compounds in value over decades.
The companies that will dominate the post-fire landscape may not be the ones hoarding compute today. They may be the ones securing energy capacity tomorrow — when every other form of AI infrastructure is abundant except the electricity to run it.
Consider the math: A single large AI training cluster can require 100+ megawatts of continuous power — equivalent to a small city. The United States currently generates about 1,200 gigawatts of electricity total. If AI compute grows at projected rates, it could demand 5-10% of the nation’s entire power generation within a decade.
That’s not a chip problem. That’s a fundamental infrastructure problem.
And unlike fiber optic cable or GPU clusters, power infrastructure can’t be deployed quickly. Nuclear plants take 10-15 years to build. Major transmission lines face decades of regulatory approval. Even large solar farms require 3-5 years from planning to operation.
This means the real constraint on AI—the genuine bottleneck that will determine winners and losers—may already be locked in by decisions being made (or not made) right now about energy infrastructure.
The companies currently spending hundreds of billions on GPUs may discover their limiting factor isn’t compute capacity but the megawatts needed to run it. And the regions that invest heavily in energy infrastructure today will have an insurmountable advantage in hosting AI workloads tomorrow.
The companies prepping themselves to survive scarcity aren’t just stockpiling compute—they’re building root systems deep enough to tap multiple resources: energy contracts locked in for decades, gross retention rates above 120%, margin expansion even as they scale, and infrastructure that can flex between training and inference as market dynamics shift.
But how do we assess fire-resistance in this cycle? Each category of company faces different tests of durability. Understanding these metrics separates genuine ecosystem strength from temporary abundance:

Understanding the Fire Tests:
Foundation model labs face a fundamental question: Can revenue grow faster than compute costs? Training expenses scale exponentially (10x compute ≈ 3x performance), while revenue scales with customer adoption. If a lab spends $100M on compute to generate $50M in revenue, then $300M to generate $120M, the trajectory is fatal. They’re running faster to stand still. Fire-resistant labs show revenue outpacing compute spend—proof that each capability improvement unlocks disproportionate customer value.
Enterprise AI platforms must prove their AI isn’t just marketing veneer. A company showing 95% gross retention but only 12% AI feature adoption means customers stay for the legacy platform (data warehouse, CRM) while ignoring AI add-ons. When capital contracts, these companies get repriced violently—the market realizes they’re infrastructure plays with an AI sticker. True AI platforms show high retention because of high AI adoption, not despite low adoption.
Application layer companies live in a unique trap: building on models they don’t control (OpenAI, Anthropic) creates margin compression, feature parity, and disintermediation risk. The only escape is deep customer embedding. Companies with NRR >120% and CAC payback <12 months have achieved workflow integration—customers expand usage naturally and acquisition costs pay back fast. Those with NRR <100% and payback >18 months are “nice-to-have” features that churn when budgets tighten, requiring continuous capital infusion to grow.
Inference API players face commoditization as GPU oversupply arrives. Revenue per GPU-hour reveals pricing power. A company generating $50/GPU-hour versus $5/GPU-hour has 10x more margin to defend its position through technical optimization, product differentiation, or distribution moats. Inference cost elasticity shows market structure: high elasticity (50% price cut = 500% demand increase) means commodity hell; low elasticity means customers value features beyond raw compute.
Energy and infrastructure firms ultimately control AI’s fundamental constraint. Data center economics flip based on utilization and energy costs. At $0.03/kWh and 85% utilization, effective cost is $0.035/kWh. At $0.08/kWh and 50% utilization, it’s $0.16/kWh—a 4.5x disadvantage. When AI demand crashes post-bubble, facilities with high energy costs cannot lower prices enough to fill capacity. Those with structural energy advantages (hydroelectric, nuclear contracts) can slash prices and still maintain positive margins, filling capacity by absorbing distressed competitors’ customers.
The meta-pattern: Each metric asks the same question from different angles—can you sustain your business model when external capital disappears? Fire-resistant companies have achieved thermodynamic sustainability: each unit of input (capital, compute, energy) generates more than one unit of output (revenue, value, efficiency). They can grow in scarcity. The flammable brush consumes more than it produces, subsidized by abundant capital. When the subsidy ends, they ignite.
This comparative framing reveals who has genuine ecosystem durability versus who’s simply tall because of temporary abundance.
The giant sequoia cannot reproduce without fire. Its cones open only in intense heat. The flames clear the forest floor, allowing seeds to reach mineral soil. The canopy burns back, allowing sunlight through. Without the burn, there is no renewal.
But there’s a deeper truth in the sequoia’s relationship with fire: not all fires serve the tree equally.
For millennia, sequoias thrived with low-intensity ground fires that burned every 10-20 years. These fires were hot enough to open cones and clear undergrowth, but cool enough to leave mature trees unharmed. The sequoia’s thick bark—up to two feet deep—evolved specifically to survive these regular burns.
Then came a century of fire suppression. Without regular burning, fuel built up. Understory trees grew tall. When fires finally came, they burned hotter and higher than sequoias had ever faced.
The Castle Fire of 2020 killed an estimated 10-14% of all mature giant sequoias on Earth. Trees that had survived dozens of fires over 2,000 years died in a single afternoon. The difference? Fire intensity. The accumulated fuel created canopy fires that overwhelmed even the sequoia’s legendary resilience.
Here’s the lesson for Silicon Valley: Regular burns — cyclical corrections, normal bankruptcies, the constant churn of creative destruction — are healthy. They clear brush, release resources, and allow new growth. But if we suppress all burning for too long, if we bail out every overvalued company and prop up every failing business model, we don’t prevent the fire. We just make the eventual burn catastrophic.
The sequoia also teaches us about time horizons. These trees take centuries to reach their full height. Even mature sequoias that survive a fire need decades to fully recover their canopy. It’s still hard to tell which trees—even those that seem mature today—will continue growing versus which have already peaked. The true giants are those that spent generations building root systems deep enough to tap water sources others can’t reach, developing bark thick enough to withstand heat others can’t survive.
The goal isn’t to prevent fires but to maintain their rhythm. Small, regular burns prevent devastating conflagrations. The worst outcome isn’t the fire—it’s the policy that postpones all fires until the fuel load becomes explosive.
If this is a bubble, it’s a productive one — a controlled burn rather than a collapse.
But “controlled” doesn’t mean comfortable. The flammable brush will ignite. Capital will evaporate. Valuations will crash. Jobs will disappear. That’s not a failure of the system—it’s the system working as designed.
The test for every founder and investor isn’t whether you can grow in abundance. It’s whether you can withstand scarcity.
When the smoke clears, we’ll see who was succulent and who was tinder — who had bark, and who was resin.
The wildfire is coming. That’s not the problem.
The question is: What kind of plant are you?
And perhaps more importantly: Are you building root systems deep enough—not just to survive this season, but to keep growing through the next decade of scarcity?
Because the real opportunity isn’t in the fire itself. It’s in what continues to grow after—and what entirely new species take root in the ashes.

