.png)

Everyone Loves pgvector (in theory)
If you’ve spent any time in the vector search space over the past year, you’ve probably read blog posts explaining why pgvector is the obvious choice for your vector database needs. The argument goes something like this: you already have Postgres, vector embeddings are just another data type, why add complexity with a dedicated vector database when you can keep everything in one place?
It’s a compelling story. And like most of the AI influencer bullshit that fills my timeline, it glosses over the inconvenient details.
I’m not here to tell you pgvector is bad. It’s not. It’s a useful extension that brings vector similarity search to Postgres. But after spending some time trying to build a production system on top of it, I’ve learned that the gap between “works in a demo” and “scales in production” is… significant.
Nobody’s actually run this in production
What bothers me most: the majority of content about pgvector reads like it was written by someone who spun up a local Postgres instance, inserted 10,000 vectors, ran a few queries, and called it a day. The posts are optimistic, the benchmarks are clean, and the conclusions are confident.
They’re also missing about 80% of what you actually need to know.
I’ve read through dozens of these posts.
They all cover the same ground: here’s how to install pgvector, here’s how to create a vector column, here’s a simple similarity search query. Some of them even mention that you should probably add an index.
What they don’t tell you is what happens when you actually try to run this in production.
Picking an index (there are no good options)
Let’s start with indexes, because this is where the tradeoffs start.
pgvector gives you two index types: IVFFlat and HNSW. The blog posts will tell you that HNSW is newer and generally better, which is… technically true but deeply unhelpful.
IVFFlat
IVFFlat (Inverted File with Flat quantization) partitions your vector space into clusters. During search, it identifies the nearest clusters and only searches within those.
The good:
- Lower memory footprint during index creation
- Reasonable query performance for many use cases
- Index creation is faster than HNSW
The bad:
- Requires you to specify the number of lists (clusters) upfront
- That number significantly impacts both recall and query performance
- The commonly recommended formula (rows / 1000) is a starting point at best
- Recall can be… disappointing depending on your data distribution
- New vectors get assigned to existing clusters, but clusters don’t rebalance without a full rebuild
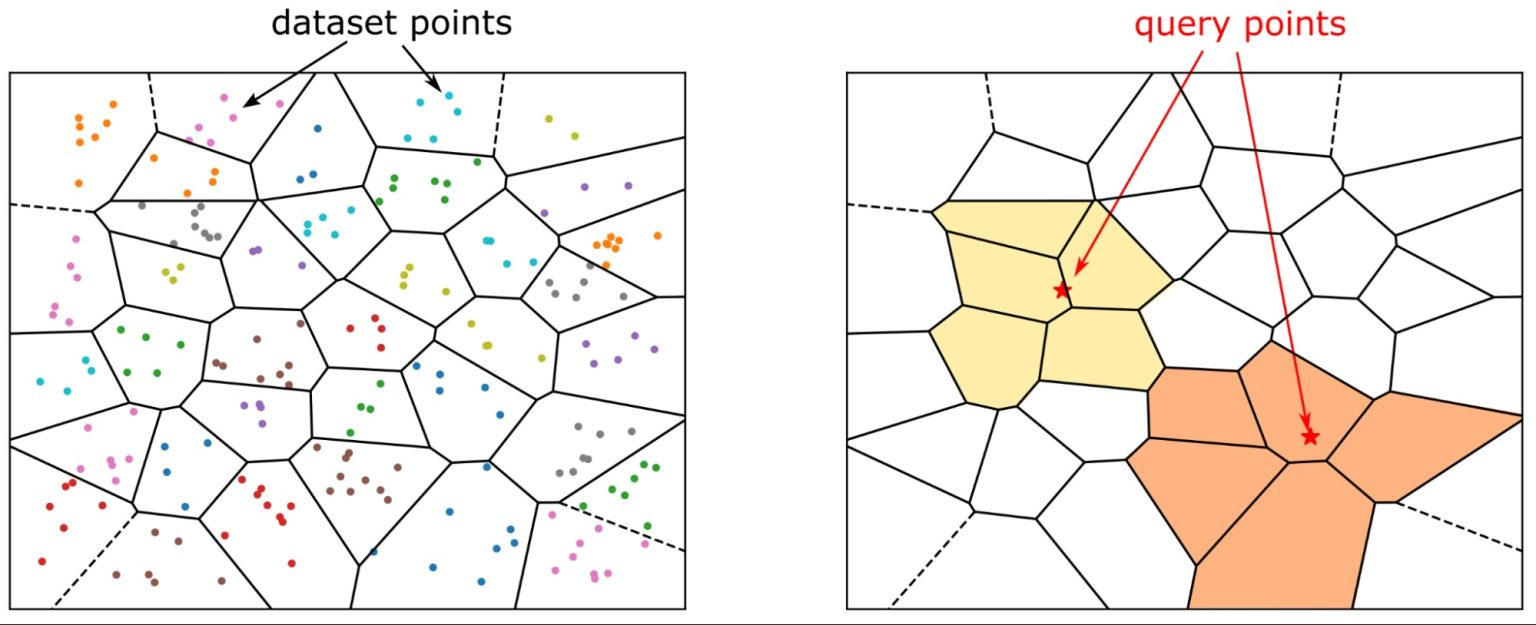 Image source: IVFFlat or HNSW index for similarity search? by Simeon Emanuilov
Image source: IVFFlat or HNSW index for similarity search? by Simeon Emanuilov
HNSW
HNSW (Hierarchical Navigable Small World) builds a multi-layer graph structure for search.
The good:
- Better recall than IVFFlat for most datasets
- More consistent query performance
- Scales well to larger datasets
The bad:
- Significantly higher memory requirements during index builds
- Index creation is slow—painfully slow for large datasets
- The memory requirements aren’t theoretical; they are real, and they’ll take down your database if you’re not careful
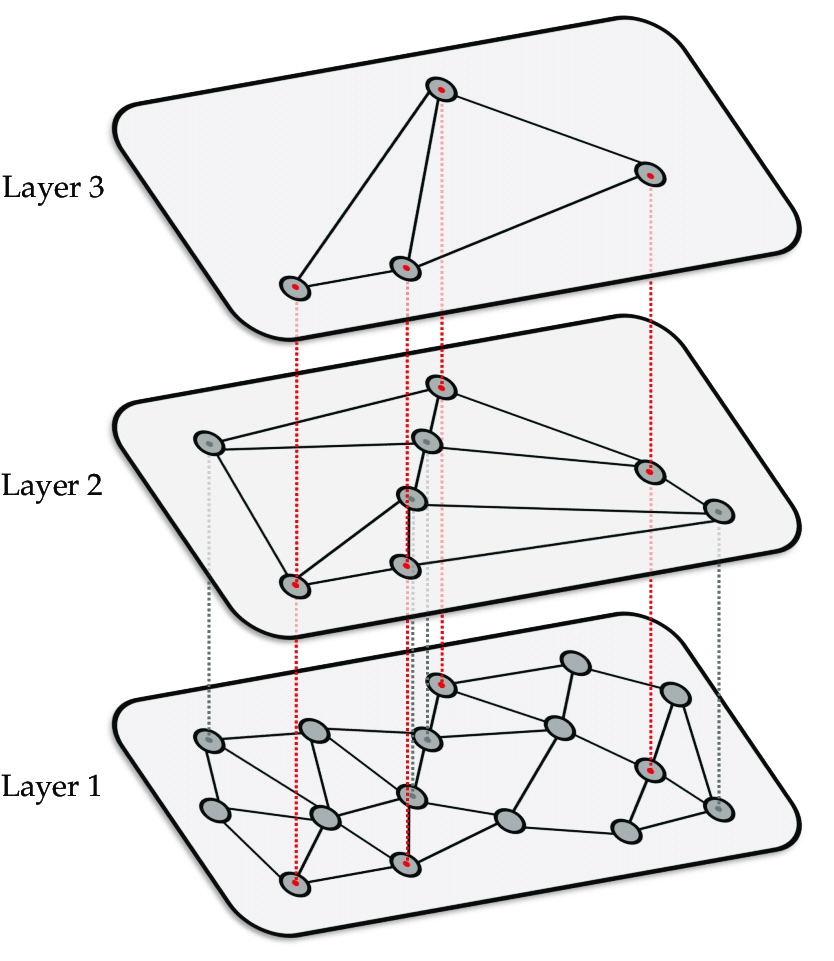 Image source: IVFFlat or HNSW index for similarity search? by Simeon Emanuilov
Image source: IVFFlat or HNSW index for similarity search? by Simeon Emanuilov
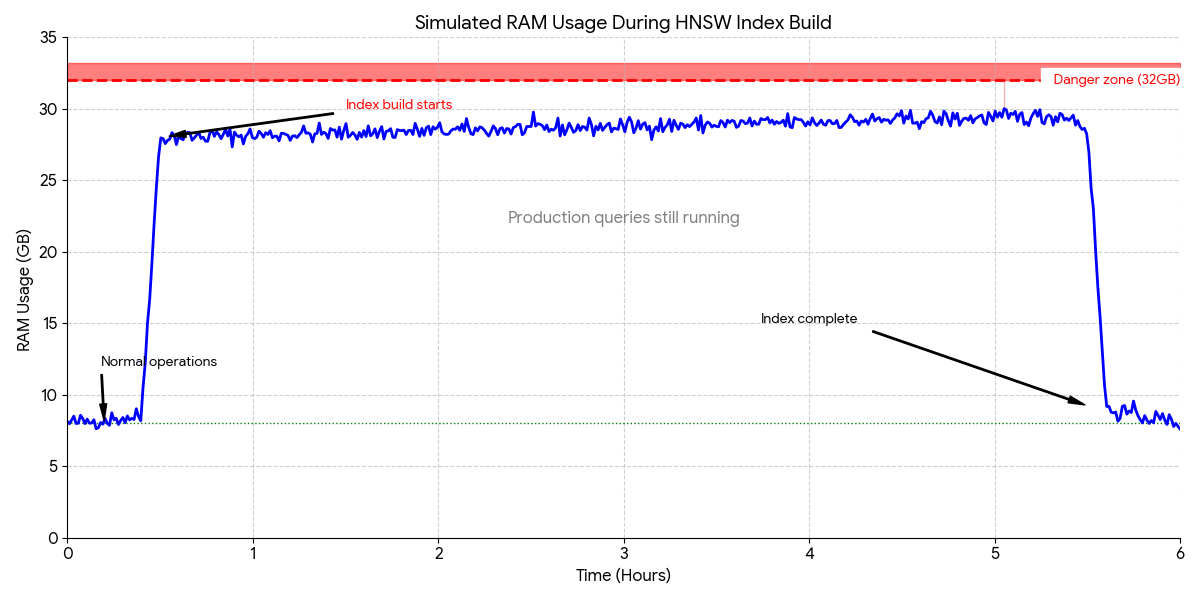
None of the blogs mention that building an HNSW index on a few million vectors can consume 10+ GB of RAM or more (depending on your vector dimensions and dataset size). On your production database. While it’s running. For potentially hours.
Real-time search is basically impossible
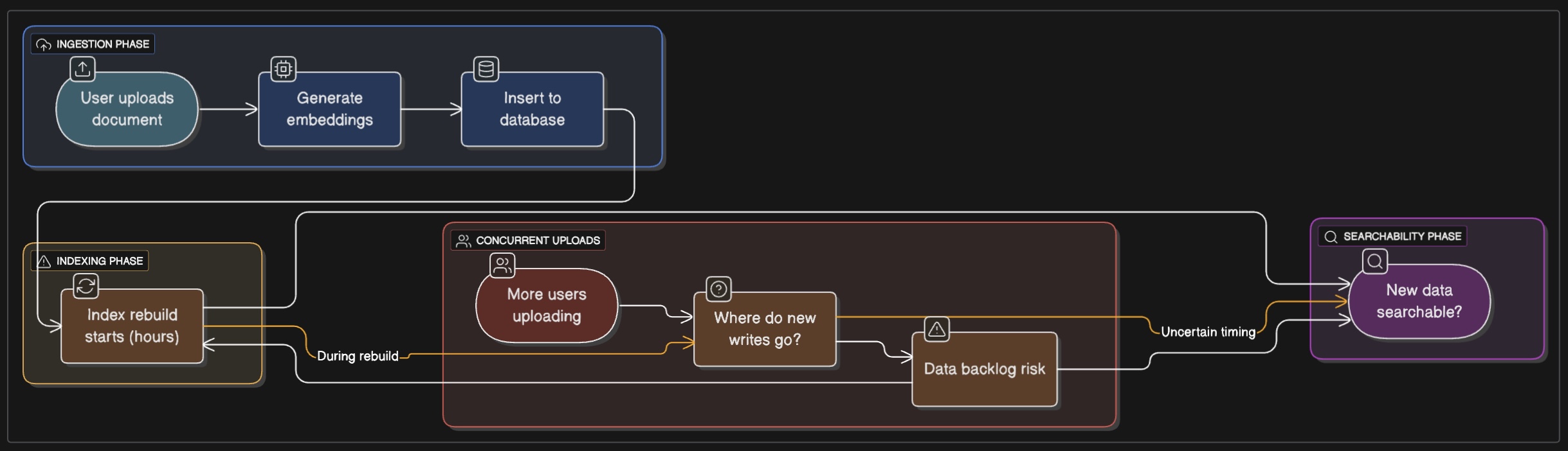
In a typical application, you want newly uploaded data to be searchable immediately. User uploads a document, you generate embeddings, insert them into your database, and they should be available in search results. Simple, right?
How index updates actually work
When you insert new vectors into a table with an index, one of two things happens:
IVFFlat: The new vectors are inserted into the appropriate clusters based on the existing structure. This works, but it means your cluster distribution gets increasingly suboptimal over time. The solution is to rebuild the index periodically. Which means downtime, or maintaining a separate index and doing an atomic swap, or accepting degraded search quality.
HNSW: New vectors are added to the graph structure. This is better than IVFFlat, but it’s not free. Each insertion requires updating the graph, which means memory allocation, graph traversals, and potential lock contention.
Neither of these is a deal-breaker in isolation. But here’s what happens in practice: you’re inserting vectors continuously throughout the day. Each insertion is individually cheap, but the aggregate load adds up. Your database is now handling your normal transactional workload, analytical queries, AND maintaining graph structures in memory for vector search.
Handling new inserts
Let’s say you’re building a document search system. Users upload PDFs, you extract text, generate embeddings, and insert them. The user expects to immediately search for that document.
Here’s what actually happens:
With no index: The insert is fast, the document is immediately available, but your searches do a full sequential scan. This works fine for a few thousand documents. At a few hundred thousand? Your searches start taking seconds. Millions? Good luck.
With IVFFlat: The insert is still relatively fast. The vector gets assigned to a cluster. But whoops, a problem. Those initial cluster assignments were based on the data distribution when you built the index. As you add more data, especially if it’s not uniformly distributed, some clusters get overloaded. Your search quality degrades. You rebuild the index periodically to fix this, but during the rebuild (which can take hours for large datasets), what do you do with new inserts? Queue them? Write to a separate unindexed table and merge later?
With HNSW: The graph gets updated on each insert through incremental insertion, which sounds great. But updating an HNSW graph isn’t free—you’re traversing the graph to find the right place to insert the new node and updating connections. Each insert acquires locks on the graph structure. Under heavy write load, this becomes a bottleneck. And if your write rate is high enough, you start seeing lock contention that slows down both writes and reads.
The operational reality
Here’s the real nightmare: you’re not just storing vectors. You have metadata—document titles, timestamps, user IDs, categories, etc. That metadata lives in other tables (or other columns in the same table). You need that metadata and the vectors to stay in sync.
In a normal Postgres table, this is easy—transactions handle it. But when you’re dealing with index builds that take hours, keeping everything consistent gets complicated. For IVFFlat, periodic rebuilds are basically required to maintain search quality. For HNSW, you might need to rebuild if you want to tune parameters or if performance has degraded.
The problem is that index builds are memory-intensive operations, and Postgres doesn’t have a great way to throttle them. You’re essentially asking your production database to allocate multiple (possibly dozens) gigabytes of RAM for an operation that might take hours, while continuing to serve queries.
You end up with strategies like:
- Write to a staging table, build the index offline, then swap it in (but now you have a window where searches miss new data)
- Maintain two indexes and write to both (double the memory, double the update cost)
- Build indexes on replicas and promote them
- Accept eventual consistency (users upload documents that aren’t searchable for N minutes)
- Provision significantly more RAM than your “working set” would suggest
None of these are “wrong” exactly. But they’re all workarounds for the fact that pgvector wasn’t really designed for high-velocity real-time ingestion.
Pre- vs. Post-Filtering (or: why you need to become a query planner expert)
Okay but let’s say you solve your index and insert problems. Now you have a document search system with millions of vectors. Documents have metadata—maybe they’re marked as draft, published, or archived. A user searches for something, and you only want to return published documents.
Simple enough. But now you have a problem: should Postgres filter on status first (pre-filter) or do the vector search first and then filter (post-filter)?
This seems like an implementation detail. It’s not. It’s the difference between queries that take 50ms and queries that take 5 seconds. It’s also the difference between returning the most relevant results and… not.

Pre-filter works great when the filter is highly selective (1,000 docs out of 10M). It works terribly when the filter isn’t selective—you’re still searching millions of vectors.
Post-filter works when your filter is permissive. Here’s where it breaks: imagine you ask for 10 results with LIMIT 10. pgvector finds the 10 nearest neighbors, then applies your filter. Only 3 of those 10 are published. You get 3 results back, even though there might be hundreds of relevant published documents slightly further away in the embedding space.
The user searched, got 3 mediocre results, and has no idea they’re missing way better matches that didn’t make it into the initial k=10 search.
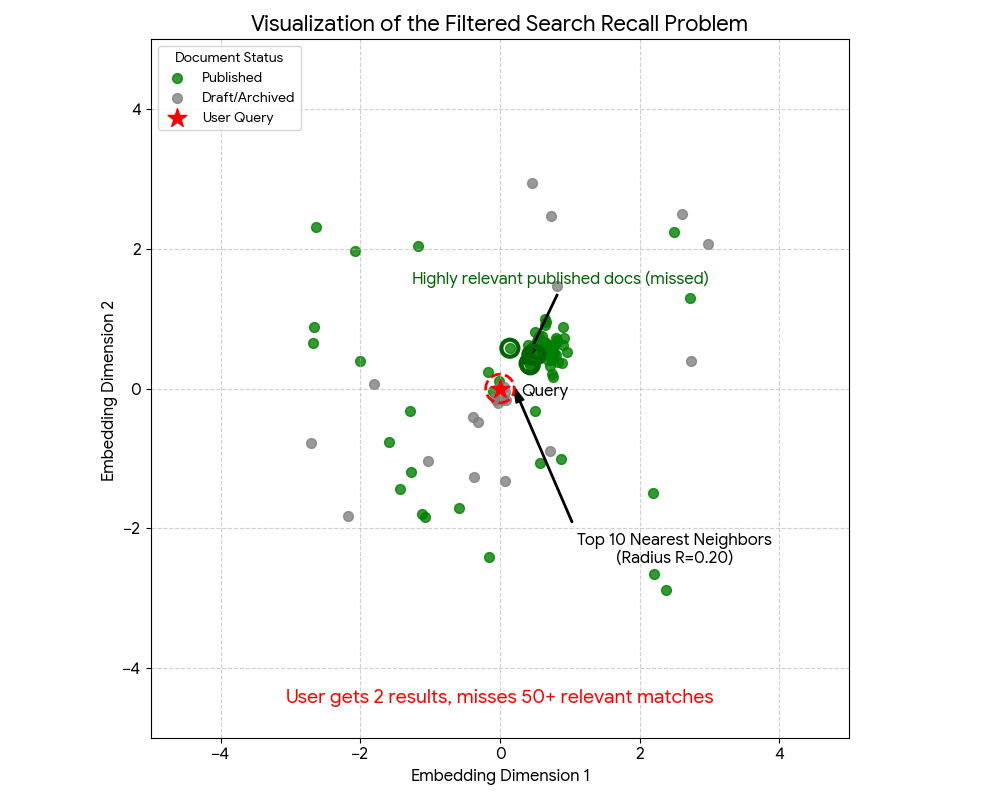
You can work around this by fetching more vectors (say, LIMIT 100) and then filtering, but now:
- You’re doing way more distance calculations than needed
- You still don’t know if 100 is enough
- Your query performance suffers
- You’re guessing at the right oversampling factor
With pre-filter, you avoid this problem, but you get the performance problems I mentioned. Pick your poison.
Multiple filters
Now add another dimension: you’re filtering by user_id AND category AND date_range.
What’s the right strategy now?
- Apply all filters first, then search? (Pre-filter)
- Search first, then apply all filters? (Post-filter)
- Apply some filters first, search, then apply remaining filters? (Hybrid)
- Which filters should you apply in which order?
The planner will look at table statistics, index selectivity, and estimated row counts and come up with a plan. That plan will probably be wrong, or at least suboptimal, because the planner’s cost model wasn’t built for vector similarity search.
And it gets worse: you’re inserting new vectors throughout the day. Your index statistics are outdated. The plans get increasingly suboptimal until you ANALYZE the table. But ANALYZE on a large table with millions of rows takes time and resources. And it doesn’t really understand vector data distribution in a meaningful way—it can tell you how many rows match user_id = 'user123', but not how clustered those vectors are in the embedding space, which is what actually matters for search performance.
Workarounds
You end up with hacks: query rewriting for different user types, partitioning your data into separate tables, CTE optimization fences to force the planner’s hand, or just fetching way more results than needed and filtering in application code.
None of these are sustainable at scale.
What vector databases do
Dedicated vector databases have solved this. They understand the cost model of filtered vector search and make intelligent decisions:
- Adaptive strategies: Some databases dynamically choose pre-filter or post-filter based on estimated selectivity
- Configurable modes: Others let you specify the strategy explicitly when you know your data distribution
- Specialized indexes: Some build indexes that support efficient filtered search (like filtered HNSW)
- Query optimization: They track statistics specific to vector operations and optimize accordingly
OpenSearch’s k-NN plugin, for example, lets you specify pre-filter or post-filter behavior. Pinecone automatically handles filter selectivity. Weaviate has optimizations for common filter patterns.
With pgvector, you get to build all of this yourself. Or live with suboptimal queries. Or hire a Postgres expert to spend weeks tuning your query patterns.
Hybrid search? Build it yourself
Oh, and if you want hybrid search—combining vector similarity with traditional full-text search—you get to build that yourself too.
Postgres has excellent full-text search capabilities. pgvector has excellent vector search capabilities. Combining them in a meaningful way? That’s on you.
You need to:
- Decide how to weight vector similarity vs. text relevance
- Normalize scores from two different scoring systems
- Tune the balance for your use case
- Probably implement Reciprocal Rank Fusion or something similar
Again, not impossible. Just another thing that many dedicated vector databases provide out of the box.
pgvectorscale (it doesn’t solve everything)
Timescale has released pgvectorscale, which addresses some of these issues. It adds:
- StreamingDiskANN, a new search backend that’s more memory-efficient
- Better support for incremental index builds
- Improved filtering performance
This is great! It’s also an admission that pgvector out of the box isn’t sufficient for production use cases.
pgvectorscale is still relatively new, and adopting it means adding another dependency, another extension, another thing to manage and upgrade. For some teams, that’s fine. For others, it’s just more evidence that maybe the “keep it simple, use Postgres” argument isn’t as simple as it seemed.
Oh, and if you’re running on RDS, pgvectorscale isn’t available. AWS doesn’t support it. So enjoy managing your own Postgres instance if you want these improvements, or just… keep dealing with the limitations of vanilla pgvector.
The “just use Postgres” simplicity keeps getting simpler.
Just use a real vector database
I get the appeal of pgvector. Consolidating your stack is good. Reducing operational complexity is good. Not having to manage another database is good.
But here’s what I’ve learned: for most teams, especially small teams, dedicated vector databases are actually simpler.
What you actually get
With a managed vector database (Pinecone, Weaviate, Turbopuffer, etc.), you typically get:
- Intelligent query planning for filtered searches
- Hybrid search built in
- Real-time indexing without memory spikes
- Horizontal scaling without complexity
- Monitoring and observability designed for vector workloads

It’s probably cheaper than you think
Yes, it’s another service to pay for. But compare:
- The cost of a managed vector database for your workload
- vs. the cost of over-provisioning your Postgres instance to handle index builds
- vs. the engineering time to tune queries and manage index rebuilds
- vs. the opportunity cost of not building features because you’re fighting your database
Turbopuffer starts at $64 month with generous limits.
For a lot of teams, the managed service is actually cheaper.
What I wish someone had told me
pgvector is an impressive piece of technology. It brings vector search to Postgres in a way that’s technically sound and genuinely useful for many applications.
But it’s not a panacea. Understand the tradeoffs.
If you’re building a production vector search system:
Index management is hard. Rebuilds are memory-intensive, time-consuming, and disruptive. Plan for this from day one.
Query planning matters. Filtered vector search is a different beast than traditional queries, and Postgres’s planner wasn’t built for this.
Real-time indexing has costs. Either in memory, in search quality, or in engineering time to manage it.
The blog posts are lying to you (by omission). They’re showing you the happy path and ignoring the operational reality.
Managed offerings exist for a reason. There’s a reason that Pinecone, Weaviate, Qdrant, and others exist and are thriving. Vector search at scale has unique challenges that general-purpose databases weren’t designed to handle.
The question isn’t “should I use pgvector?” It’s “am I willing to take on the operational complexity of running vector search in Postgres?”
For some teams, the answer is yes. You have database expertise, you need the tight integration, you’re willing to invest the time.
For many teams—maybe most teams—the answer is probably no. Use a tool designed for the job. Your future self will thank you.



