.png)


Back in 2017, I was having lunch with my tech lead in the building's canteen. We got a couple of terrible sandwiches, filled with mayonnaise to the point of overflowing, but it was still better than the 40-degree heat outside.
I had just reached my first career plateau and desperately needed advice.
I was comfortable building monolithic web applications and solving problems that could fit into a medium-sized Digital Ocean droplet, but my work started feeling like more of the same.
I didn't know what to focus on. I felt lost.
“You should study distributed systems. Forget about the flavor-of-the-day frameworks. Go study about the CAP theorem and system design.”
That’s the advice my lead gave me.
I had no idea what it meant, though.
What exactly was a distributed system? How do you design one? Have I worked on one so far? Why was that knowledge so valuable?
I had so many questions, but I didn't want to look dumb, so I mumbled something and kept munching on my sandwich.
When we went back into the office upstairs, I assigned myself the hardest JIRA ticket I could find so I could look busy, and continued to spend the afternoon googling all these questions I mentioned above.
I got thrown into the world of the CAP theorem headfirst.
But I felt like I was missing a step.
Maybe it was my lack of formal education speaking, but my understanding of software was grounded in practicality. Trying to understand more abstract concepts that are not tied to a business problem was difficult, tiring even.
If I could go back, I'd tell myself the following...
If you're anything like me, smacking you with abstract theory and term definitions won't be a good way to start this off. Some backstory helps to ease into a topic.
Let's start by taking a single computer as an example.
Every machine comes with finite storage and computing capabilities, and there's a limit to the amount of work you can do on it. You can upgrade its hardware, buy a bigger disk, a faster CPU - but this comes with diminishing returns.
If you've got a giant 10TB database, you can only improve its speed so much by beefing it up with resources.
When you execute a search query, it will have to sift through enormous quantities of data, even if it only needs a subset of it.
To optimize that database, you can split the data across multiple servers based on some criteria. Separating the load between multiple machines will make your operations a lot faster than adding more memory to one of them.
To the outside world, it's still a single data store. You will get a request to store data, but where exactly it gets put is up to you - you have multiple servers that need to communicate and replicate data between one another.
You've got yourself a distributed system.
Other times, you may need to add more machines to your application by necessity.
If you're a financial company that's processing payments, you need to communicate with other companies' systems to complete a transaction.
In this scenario, you're not managing those extra machines yourself, but that payment process is not happening inside the boundaries of your application. You need to verify the card, check for fraud using a partner's API, and then transfer the funds.
You also need to plan for errors.
What happens if you transfer the customer's money, but your application fails and you don't give them what they paid for?
You've got yourself a distributed system.
When the journalists in a media corporation are writing an article, they store their drafts in a CMS like WordPress. But when they publish it, this content needs to be transformed and denormalized so it's faster to retrieve.
For that, you'll need a separate database that’s optimized for fast reads.
You'll need a workflow that transforms every article and stores it. You'll also need to plan for failure again - what happens if a transformation fails? How will this content get republished?
Again, you've got yourself a distributed system.
To the outside world, though, these applications look like one single product.
The fact that there are so many moving bits and pieces underneath, and they're working across multiple machines, is an implementation detail that only the developers are aware of.
When I say "single machine" that can be a bit misleading today. Even if all the components run on the same physical hardware, if they communicate by sending messages over a network instead of sharing memory directly, they behave like a distributed system. Some issues are much less severe when they're running inside the same box, but they're still present.
Every distributed system has the following qualities:
Its components operate concurrently
Its components fail independently
Its components do not share a global clock
The DynamoDB database is a distributed system. Kafka is a distributed system. To us, they look like one component that we interface with, but internally, they are made of multiple different parts that are communicating, replicating, and transferring data.
I can continue thinking of examples, but you get the point. There's a limit to the work you can do on a single machine, so we build systems that have many of them.
But the problem comes when these components need to communicate over the network.
Programming is challenging enough when we're dealing with a single computer, but at least it gives us a sense of safety.
Your code is predictable when everything is running in memory.
While there's a non-zero chance that a function call can fail due to a CPU hop failure, if that ever happens to you, you should quit what you're doing and buy a lottery ticket.
The problems in your application are usually caused by incorrect or unpredictable behavior.
You may have left an uncaught error bubble up, or you may have tried to access an index of an array that doesn't exist. Stack overflows don't happen out of nowhere too - you must have written that recursion wrong.
But when two machines need to communicate over the network, this makes the whole application less predictable.
We don't know how long a network request will take. We don't know whether the machine on the other side is turned on. We don't know if something along the way may make our request fail.
Communicating over the network is unreliable - that's the biggest problem in distributed systems.
A function call that happened in memory now needs to happen over the wire, and even the most resilient network in the world can't give you 100% guarantee that someone won't trip over the cable.
We're not planning around CPU hop failures because they're statistically insignificant. But communication over the network can fail often enough that we need to consider it, plan around it, and implement safety mechanisms.
Sometimes it may not even be the network's fault.
If the service you’re communicating with has failed or is unresponsive, you need to have a plan for what to do. When I’m writing a function, I rely on the fact that CPU hop failures don’t happen.
But your system design strategy can't be that network-related failures don’t occur.
You need to figure out how to make a product that works over an unreliable network, and that's why working on such projects is so challenging - it's not just a matter of catching an error.
If you need to replicate data between two systems, an error means they will drift apart. This no longer impacts just the current operation. It impacts the whole product.
If your application is storing data in a database, but you're replicating it in Elasticsearch, a failure to store it there means that people won't see it in their search results.
This is not just a matter of retrying an error - you need to redesign your system around the possibility of this replication error happening.
Nowadays, even simple products usually have multiple components.
A web application that has a React UI, a REST API, and a database is technically a distributed system because its parts operate concurrently, and they fail independently.
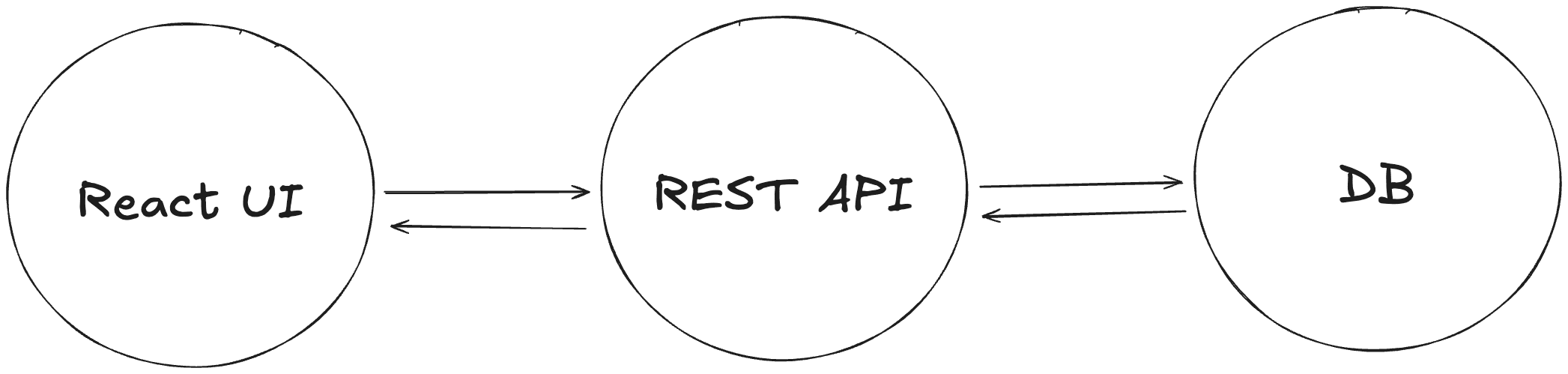
If the UI is broken, the REST API can still accept requests from other clients.
If the REST API fails over, the UI can still display an error screen and instruct the users to wait.
If the database fails, the REST API can still return an empty response to the UI and, again, display an error message.
However, it's a very, very simple one, and it doesn't have most of the problems that actually make these systems challenging. We’re not replicating data here, and we’re not worried about keeping it in sync.
Let's imagine that this same application needs a new feature. It will allow users to upload a file, then it will parse that file and store its contents in a database so it can visualize them.
It's a relatively simple implementation:
You have a place in the UI where people can drop their files
An endpoint that handles these uploads and parses them
A table in the database that stores the data
But how would this change if I told you that this file can be 10 GB large?
How would it change if I told you that thousands of users can be uploading files concurrently?
The complexity has grown beyond what a single machine can do.
Solving this problem is not just a matter of throwing more resources - you need to redesign the whole application.
Our product can now handle these large files, but it's become a lot more complex.
Supporting this scale means that what was a simple synchronous operation has now become asynchronous and involves more components - object storage, events, and workers.
Processing a 10GB file means we won’t be building a request-response workflow. We will either need to poll the API or get notified by it when the file is processed successfully.
The need for distributed systems comes with scale.
If your problem can be solved with a single process running on a single machine, then by all means, this is the better way to do it. The problems of scale are sometimes only solvable by a distributed system, but this comes at the cost of higher complexity.
Scale can come in different forms.
When a company grows, it hires more engineers who require more autonomy. And if Conway’s Law continues to hold up, this means that as your organization grows, so does the architecture of your product.
The larger it is, the more distribution problems you will face.
You will start using external services as well. You can buy a 3rd party solution to a problem, but if you’ve got the network between you and that software, you’re still dealing with that complexity.
The higher the scale, the more you're relying on the network, but that network is inherently unreliable, and that's the root of all our problems.
It didn't take me a long time to realize that sometimes you can't create a mental model of the distributed system the same way you can with smaller applications.
I’ve seen teams that own ~50 services running in production, communicating with each other and other teams’ services.
Even if you know how your part of the system’s working, you don’t know what the others are doing. You don’t know what they’re deploying and when. No one does. No one can keep a detailed picture of a large company’s architecture in their head.
Sometimes it's not even possible to run the entire thing locally.
This was a big cultural shock to me because I was used to setting up the monolith and having the whole product running.
Suddenly, I owned only a fraction of the entire system. To actually see how they integrate with the rest of the services (which may be owned by other teams), I had to deploy it and see how it behaves.
This requires a level of abstract thinking that I wasn’t used to.
Scale doesn’t come for free.
I was used to the cost of new features being paid in lines of code - more functions, more classes, more modules. But in a distributed system, every component you add has a purely monetary cost at the end of the month.
Yes, we can take care of 10 GB file uploads, but the additional infrastructure that we need to provision will cost something.
More users and more engineers usually mean good business (or at least good funding), so the companies building these systems have the means to support them.
But I had to start making sensible financial decisions.
People asked me how much things would cost.
And I had no idea.
Over-engineering in the context of a single service meant code-level complexity. Over-engineering a distributed system means money gets poured down the drain.
A forgotten experiment in a single service usually results in a hanging PR that no one looks at.
The same in the context of a distributed system means hanging infrastructure that we pay for but don't use, and it’s not uncommon for large companies to pay insane amounts of money for unused AWS resources.
Almost a decade later, that lunch was a pivotal point in my career.
Who knows how much time I would've spent gliding on the surface of software engineering, jumping from framework to framework, happy that I learned another tool’s API.
Distributed systems gave me a long-term niche that I can study and explore. An evergreen topic in what’s usually a pretty dynamic field.
All thriving businesses face the problems of scale sooner or later.
You may be building web applications. You may be building AI agents. The problems of distribution are inevitable, and your expertise will inevitably be needed.