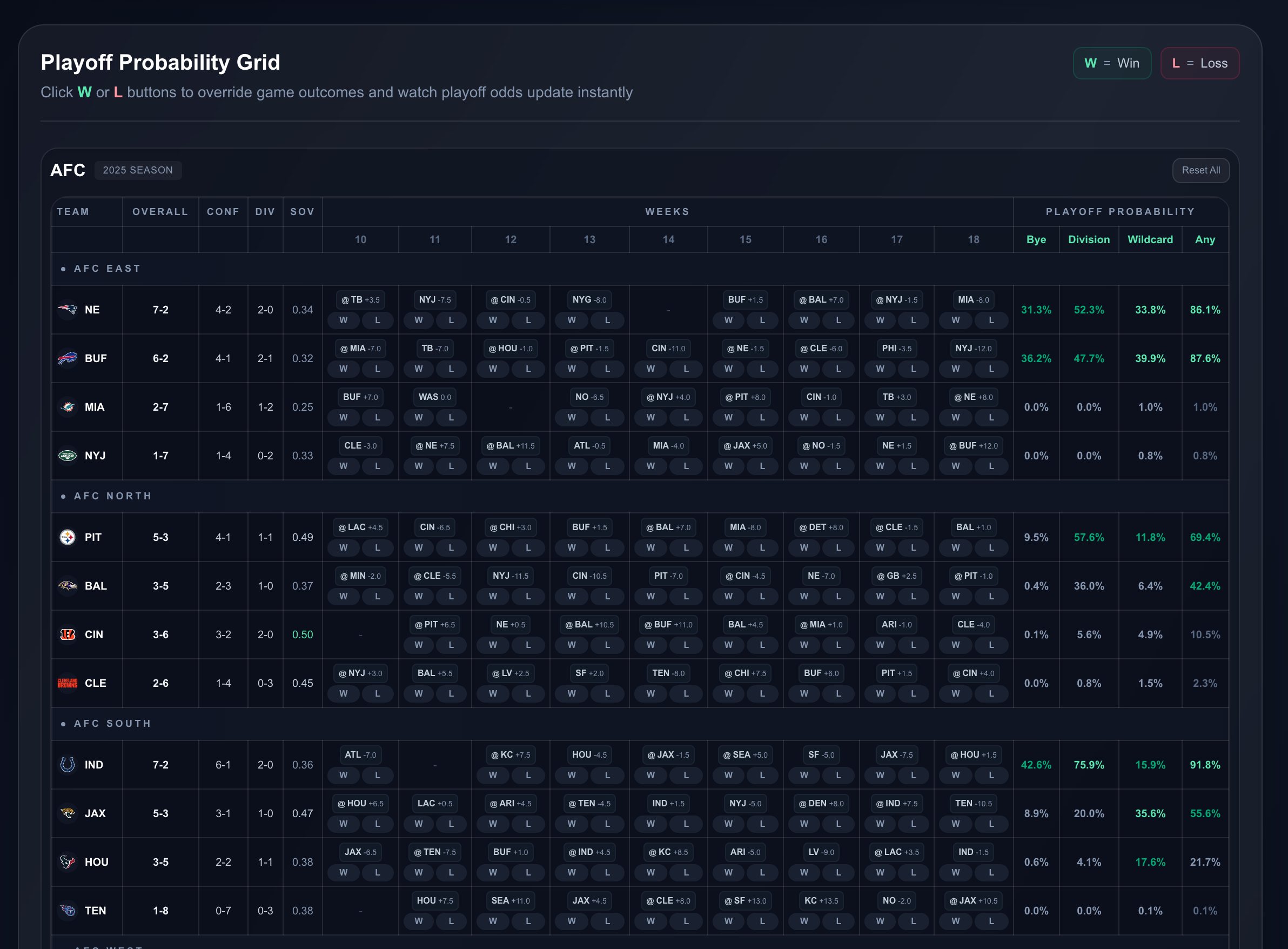
.png)

![]()
Zoom image will be displayed
Years ago, I sat in Jeremy Howard’s FastAI class, right at the dawn of a new era. He was teaching us ULMFiT, a method he (& Sebastian Ruder) had pioneered, showing the world that fine-tuning a pre-trained language model could achieve state-of-the-art results. It felt like a tectonic shift. We were on the verge of something big.
The ground shifted under our feet faster than any of us could have imagined. Soon after, the BERT paper came out. It cited ULMFiT on its very first page, but it made two world-changing contributions of its own: it replaced the RNN with an invention called the Transformer, and it read text both forwards and backwards. Google poured its marketing strength behind it, and… well, you know what happened next.
Zoom image will be displayed
But even as the world went BERT-crazy, a question gnawed at me: why was the Transformer so much better? It wasn’t just a performance bump; it felt like a different species of model entirely. This question stayed with me for a long time. For anyone who knew the elegant, stateful beauty of an RNN, the brute-force success of these massive feed-forward chains was both impressive and a little baffling.
As a forum post I wrote way back in 2018 shows, I was already trying to make sense of what this new world would look like.
For years, nobody had a truly convincing answer. Then, I watched Ashish Vaswani — the inventor of the Transformer — give a lecture at Stanford, and the final piece of the puzzle clicked into place.
Zoom image will be displayed
It became clear that the QKV formulation of Softmax Attention isn’t just another layer. It is arguably the most perfect feature detector ever discovered for sequences of information. For anyone who saw how convolution kernels learned to find edges and textures in pixels, this was the equivalent “aha!” moment for language. Ashish explained that an LLM could only achieve its staggeringly low perplexity scores if it could unravel the very structure of language, common sense, and culture buried in the data.
And it turns out, there is a brilliant recipe for a feature detector that can do just that:
Q (Query): Ask interesting questions about the sequence.
K (Key): Let every part of the sequence propose itself as a candidate to answer.
Softmax: Find the most likely candidate.
V (Value): Get the answer.
That’s it!
That is all the guidance Gradient Descent needed to rummage through the entirety of human text and extract patterns so intricate they would put M.C. Escher to shame.
And so, as an old RNN fanboy, I grudgingly gave in. The loop, the unrolled representation, the gates, the heroic struggle of the hidden state, the beautiful madness of Backpropagation Through Time — all lost out to what felt like simple, long chains of a forward pass. I have taught the Transformer architecture to thousands of students all over the world, and every time I said, “QKV and GPU go brrr…that’s all there is to it,” I died a little inside. Eventually, I learned to stop worrying and love the bomb.
Until last week…
Out of nowhere, a tiny lab from Singapore published a paper on the Hierarchical Reasoning Model. They had figured out how to marry the soul of recurrence (minus the BPTT nonsense) with the full brawn of the modern attention module.
For a moment, I was back in Jeremy’s class again, feeling that same spark — that feeling of being on the verge of a new, more elegant era. This paper feels like a homecoming. It’s a synthesis of the two great ideas of the last decade, and it points toward a future I had hoped for but had stopped believing was possible.
This post is my attempt to explain what HRM is, how it works, and why it feels so important. Let’s dive in.
So, what is this new architecture that has me so excited? At its heart, it’s a beautifully simple idea that challenges the “bigger is better” philosophy of modern AI.
Imagine giving a fiendishly difficult Sudoku puzzle — one that requires backtracking and testing hypotheses — to a standard Large Language Model. It might try to solve it by “talking its way through” in a Chain-of-Thought process. This is impressive, but it’s often fragile and inefficient, like a single genius trying to keep every possibility in their head at once while narrating their every thought. If they make one logical slip, the entire solution can crumble.
The Hierarchical Reasoning Model (HRM) argues that for complex, multi-step reasoning, what you need isn’t just a bigger brain, but a better organized one. This is where its genius lies. It organizes its computational “brain” like a small, highly effective company with just two employees.
Zoom image will be displayed
First, you have the High-Level module (H-module). Let’s call it the CEO. The CEO is the strategist. It operates on a slow timescale, thinking deliberately about the big picture. The CEO doesn’t get its hands dirty filling in individual numbers in the Sudoku grid. Instead, it looks at the entire board and makes a strategic judgment, like: “That top-right box is nearly full. It’s the most constrained area and probably the key to unlocking the next wave of deductions. Let’s focus all our energy there for a while.”
Second, you have the Low-Level module (L-module). This is the Worker. The Worker is a blur of activity. It operates on a very fast clock, taking the CEO’s high-level directive and executing it with relentless, detail-oriented focus. Given the order to “focus on the top-right box,” the Worker will perform dozens of rapid logical steps: “If this cell is a 7, then that one can’t be… which means that one must be a 4… Wait, that creates a conflict…” It’s the one doing the logical cross-hatching and rule-checking, but only within the strategic scope set by the CEO.
This is the “brain with two clocks.” The CEO thinks and updates its grand strategy only occasionally. The Worker, guided by that single strategy, thinks and updates its detailed understanding constantly. This temporal separation is what prevents the system from getting stuck on a bad idea. The Worker finds a local solution (or hits a dead end), reports back, and the CEO uses that new information to issue a fresh, smarter strategic directive, effectively “resetting” the Worker for a new sprint on a more promising part of the problem.
This elegant structure is the entire innovation. HRM doesn’t invent a new type of neuron; it provides a revolutionary blueprint for how to assemble the powerful components we already have (Transformer blocks) into something far more capable for deep reasoning. It replaces the lone genius with a focused, two-person company — and as we’ll see, that makes all the difference.
So we have our two employees: the slow, strategic CEO and the fast, diligent Worker. How do they actually work together to solve a complex Sudoku puzzle? Their collaboration unfolds in a beautifully nested loop of “thinking sessions,” “strategic meetings,” and “work sprints.” This process is the core of HRM’s forward pass, and it’s what allows the model to achieve true computational depth.
Let’s imagine their workday, which we’ll call a Thinking Session. For a very tough puzzle, the company might decide it needs multiple sessions to get it right. This is the outermost loop of the model, which it can learn to control with the Adaptive Computation Time we’ll discuss later. For now, let’s just look at one full session.
A Thinking Session is made up of a series of Strategic Meetings. Let’s say, eight of them. This is the CEO’s operational clock (N in the paper’s N*T loop). At the start of each meeting, the CEO sets the strategy.
Finally, each Strategic Meeting kicks off one Work Sprint. This is a frantic period of intense, focused work from the Worker, lasting for, say, eight lightning-fast steps. This is the Worker’s clock (T in the N*T loop).
Here’s how a single day unfolds:
Zoom image will be displayed
8:00 AM: The First Strategic Meeting (N=1)
The CEO looks at the fresh Sudoku puzzle. Having no prior information, the strategy is simple: “Okay, team, let’s just do an initial sweep. Fill in all the obvious numbers and see where we stand.” This directive is now “locked in” for the entire first sprint.
8:01 AM — 8:05 AM: The First Work Sprint (T=1 to 8)
The Worker takes the CEO’s directive and goes to work. For eight rapid steps, it crunches the numbers:
- Step 1: The Worker scans the grid. “Row 1 is missing a ‘5’, and there’s only one open spot. Fill it in.”
- Step 2: Using the newly updated grid from Step 1, it scans again. “Okay, now that the ‘5’ is there, Box 2 is only missing a ‘9’. Fill it in.”
- …This continues for all eight steps, with each step building on the last.
At the end of the sprint, the Worker has filled in all the “easy” numbers. It has reached a “local equilibrium” — it can’t deduce anything further based on the CEO’s initial, simple strategy. It prepares its final, updated grid as a report.
9:00 AM: The Second Strategic Meeting (N=2)
The CEO takes the Worker’s report (the updated grid). The board is no longer blank; it’s partially filled. The CEO’s QKV attention scans for new patterns. “Good work,” it says. “The easy stuff is done. I now see a major bottleneck in the bottom-left corner. Two cells there can only be a ‘2’ or a ‘7’, forming a ‘naked pair’. This is the key. For your next sprint, I want you to explore the consequences of that pair.”
9:01 AM — 9:05 AM: The Second Work Sprint (T=1 to 8)
The Worker receives this new, much more sophisticated directive. It “resets” its detailed focus and begins a new sprint, this time biased by the CEO’s insight. It starts testing the hypothesis: “If Cell A is a ‘2’, what happens? If it’s a ‘7’, what happens?”
This cycle of CEO Meeting -> Worker Sprint repeats for the entire “day.” The CEO provides high-level guidance, and the Worker explores the tactical consequences. This hierarchical process allows the model to form a complex chain of reasoning: it can set a high-level hypothesis (“Let’s assume this cell is a ‘2’”), let the Worker explore the logical fallout for eight steps, and if the Worker reports back a contradiction, the CEO can say, “Okay, that hypothesis was wrong. Let’s backtrack and try ‘7’ instead.”
This is how HRM performs deep, iterative reasoning. It’s not one massive leap of logic. It’s a structured, disciplined, and multi-layered conversation between a strategist and an executor, repeated until the puzzle is solved.
Zoom image will be displayed
We’ve established the “what” of HRM’s design — a company with a CEO and a Worker operating on different clocks. Now we get to the “how.” What makes these two employees so good at their jobs? The secret is that they are not just any simple neural network layers. Both the CEO and the Worker are, in fact, powerful, state-of-the-art Transformer blocks, complete with modern embellishments like Rotary Position Embeddings (RoPE).
This isn’t a random choice. It’s the key to the whole system. The Transformer’s self-attention mechanism, built on the elegant dance of Query, Key, and Value (QKV), is the most powerful and general-purpose “thinking engine” for processing relationships within a sequence. HRM’s genius is not in reinventing this engine, but in training two of them for specialized, cooperative roles.
Let’s pop the hood and see how this QKV mind works for a Sudoku puzzle.
The Worker: A Master Rule-Checker
The Worker’s job is rapid, detailed, and logical. It uses its QKV attention to learn and enforce the fundamental rules of Sudoku at lightning speed. When the Worker processes the puzzle grid, here’s what’s happening inside its “mind”:
- A Query (Q) is a cell asking a question: An empty cell at position (2, 3) wakes up and effectively shouts a Query: “What numbers am I not allowed to be?”
- A Key (K) is every other cell advertising its relationships: Every other cell generates a Key. The cell at (2, 8) generates a Key that says, “I’m in your row!” The cell at (7, 3) generates one that says, “I’m in your column!” And the cell at (1, 1) generates one saying, “I’m in your 3x3 box!” A cell at (8, 8) generates a Key that advertises no special relationship.
- The Softmax finds the most relevant “experts”: The Query from cell (2, 3) is compared against all the Keys. It finds a perfect match with the Keys from the cells in its own row, column, and box.
- A Value (V) is each cell reporting its content: Every cell also generates a Value, which is its current number. The cell at (2, 8) reports: “My value is ‘7’.”
- The Result: The attention mechanism performs a weighted sum of the Values, guided by the Query-Key matches. This means cell (2, 3) effectively gathers an “information packet” containing all the numbers from all the relevant cells. The rest of the Transformer block then processes this packet, allowing it to conclude: “Okay, I’ve seen a ‘7’, a ‘4’, and a ‘1’ from my neighbors. I cannot be any of those.”
This is how the Worker thinks — as a massively parallel system of rule-checking, happening across the entire grid in a single step.
The CEO: A Master Strategist
The CEO uses the exact same QKV mechanism, but for a much higher-level purpose. It doesn’t care about individual cell rules; it cares about the global state of the puzzle. When the CEO’s attention mechanism activates (at the end of a Worker’s sprint), its “thinking” is strategic:
- Its Query (Q) is a strategic question: “Given the Worker’s last report, where is the biggest bottleneck or the most promising area on the board?”
- Its Keys (K) are abstract patterns: The CEO has learned to see beyond individual cells. Regions of the board generate Keys that advertise their strategic importance. One region might say, “I am a ‘naked pair’ — a major strategic pattern!” Another might say, “I am a region with a direct contradiction, an error!”
- Its Values (V) are the details of the strategy: The Value for the “contradiction” Key would be an encoding of where and what that error is.
By attending to the most strategically important patterns on the board, the CEO forms its next directive. It’s not just checking rules; it’s performing pattern recognition on the state of the reasoning process itself. This allows it to guide the Worker out of dead ends and toward the most fruitful lines of inquiry, making the entire system more than the sum of its parts.
So, we have this elegant company of a CEO and a Worker, both equipped with powerful QKV minds, collaborating through a deep, multi-step process. This brings us to the most critical question: how does it possibly learn?
If the model makes a mistake after a 512-step thought process, how does it know which of those 512 steps was the one that led it astray?
The traditional AI method for this, Backpropagation Through Time (BPTT), is the equivalent of a nightmare audit. It’s like having an auditor with a perfect memory who, after a project fails, re-examines every single email, memo, and decision from every employee, all the way back to Day 1, to assign the exact amount of blame to everyone. This is theoretically perfect but prohibitively expensive, memory-intensive, and frankly, not how the brain works. The brain learns from local, immediate feedback, not from a perfect replay of its entire history.
This is where HRM pulls its masterstroke. It’s built on a “profoundly lazy” but brilliant method of credit assignment. It’s a pragmatic performance review that avoids micromanagement hell entirely.
This clever shortcut is theoretically grounded in the mathematics of Deep Equilibrium Models (DEQ) and the Implicit Function Theorem (IFT), but the intuition is wonderfully simple. The HRM model says: “We are only going to assign blame for the most recent action.”
Let’s see what this means in practice. The company finishes a puzzle and gets it wrong. The Board of Directors (the loss function) is furious. It’s time for the performance review.
Zoom image will be displayed
- The CEO’s Review: The auditor turns to the CEO and says, “We only care about your last decision. You took the Worker’s final report (zL) and used it to update your strategy (zH). We will hold you accountable for that single action.” All the CEO’s previous strategic meetings are ignored.
- The Worker’s Review: The auditor then turns to the Worker. “You too. Your final report (zL) was based on your state of mind at the end of the previous day. That is the only link we care about.”
This is the “one-step gradient approximation”: the system assumes that the final state was a “one-shot” decision based only on its most immediate predecessor.
But wait — what about the problem you’re rightly thinking of? What if the fatal mistake happened on Day 1, but we only blame the actions on Day 30?
This is where the deep supervision loop (the “Thinking Sessions” or M-loop) becomes the hero of the story. It’s the system’s ingenious way of making old mistakes new again.
Imagine the company fails on its first attempt (M=1) because of a hidden error from early in the process.
- The Flawed Report: The final answer is wrong. The pragmatic review happens, and the weak, “last-step” feedback does a poor job of fixing the root cause.
- The Next Day’s Agenda: The next thinking session (M=2) begins. But it doesn’t start from a blank slate. Its starting point is the final, flawed state from the previous session. The consequence of that buried mistake is no longer in the past; it’s the first item on the current agenda.
- The Error is Now Visible: The CEO and Worker start their day staring directly at the problem. When they take their first few steps in this new session, the error is no longer a distant memory. It’s right here, in the “now,” where the pragmatic “blame-the-last-guy” gradient can finally see it clearly and fix the underlying logic.
This is how HRM learns. It uses an incredibly efficient but myopic gradient, and brilliantly compensates for the myopia by using its deep, recursive loop to force itself to confront the consequences of its past mistakes, session after session, until the logic is perfected.
At this point, you might be thinking: if we’re trying to fix the “shoot from the hip” nature of LLMs, why not just go back to a traditional recurrent architecture like an LSTM? After all, RNNs were born to loop.
This is where we get to the heart of why HRM isn’t just a new RNN; it’s a solution to a fundamental stalemate that has plagued AI for years. It elegantly solves the core problem of both major architectural families.
First, let’s consider the traditional RNN, which we can think of as a “Worker Who Gives Up Too Soon.” As we discussed, these models suffer from a mathematical flaw known as the vanishing gradient problem. As the RNN loops through its steps, its internal memory state tends to either fade into a meaningless, blurry smudge or explode into a useless, saturated blob. The practical result is what the HRM paper calls “early convergence.” After just a few steps, the model’s state becomes inert — it gets stuck on its first “good enough” idea and stops doing any real thinking. Its potential for deep, multi-step reasoning is lost because its own mathematics cause it to give up prematurely.
On the other side, we have the modern LLM, which we know is a “Brilliant Expert Who Never Double-Checks.” An LLM’s architecture is a massive, feed-forward sequence of Transformer blocks. It avoids the vanishing gradient problem of RNNs entirely, but at a huge cost: it has no native mechanism for iterative thought. It makes a single, incredibly sophisticated “one-shot” prediction for each word. Its first thought is its only thought. This makes it a shallow reasoner, prone to logical errors and hallucinations because it cannot loop back on its own thinking to check its work or explore alternative hypotheses.
For years, the field was stuck in this architectural stalemate:
- Choose the RNN: Get a deep, loopy architecture that’s theoretically powerful but mathematically unstable and gives up too soon.
- Choose the Transformer LLM: Get a stable, powerful architecture that can’t actually think iteratively.
HRM breaks this stalemate by taking the best of both worlds.
- It embraces the Loop: Like an RNN, it is fundamentally a recurrent, iterative machine designed for multi-step problem-solving.
- It avoids Early Convergence: This is the masterstroke. The “hierarchical convergence” process — where the CEO resets the Worker’s task at the end of each sprint — acts as a constant “jolt” to the system. Just when the Worker (L-module) might be about to settle into a stable, inert state, the CEO (H-module) updates its strategy and gives it a fresh, new problem to solve. This prevents the computational activity from ever fading away, allowing it to sustain deep thought for hundreds of steps.
HRM is not just a comeback for the loop. It is a synthesis. It keeps the iterative soul of the RNN but fortifies it with a hierarchical structure that ensures the thinking never becomes inert. It finally delivers on the original promise of recurrent networks: a model that can not only think in steps, but can sustain that thought, step after diligent step, until the problem is truly solved.
We have established a powerful, deep-reasoning company. But one crucial question remains: How long does the company work? Does it spend the same amount of time on an easy Monday-morning puzzle as it does on a diabolical, weekend-edition monster?
A fixed number of “Thinking Sessions” (M-loop) would be incredibly inefficient. This is where HRM introduces its final, most elegant component: an Efficiency Expert who tells the company when it’s time to stop. In the paper, this is called Adaptive Computation Time (ACT), and it’s powered by Q-learning.
Zoom image will be displayed
Think of it like this. At the end of every single Thinking Session, the CEO, having produced its current best answer, consults this external Expert. The Expert looks at the CEO’s current state of mind (zH) — its internal representation of the puzzle — and provides two simple scores:
- A “Confidence Score” (Q_halt): This is the Expert’s assessment of the current answer’s quality. A high score means, “I’m very confident this solution is correct. You should stop now.”
- A “Potential Score” (Q_continue): This is the Expert’s estimate of how much better the answer could get if the company runs just one more thinking session. A high score means, “I see a lot of uncertainty and potential for improvement. It’s worth thinking longer.”
The company’s decision rule is simple: if Confidence > Potential, we halt.
How does the Expert get so smart? It learns through simple, direct feedback. During training, if the Expert advises “halt” and the answer is correct, it gets a reward of +1. If the answer is wrong, it gets a 0. This quickly teaches it to only be confident when the CEO’s internal state is truly coherent and the puzzle is solved.
This single mechanism is what allows HRM to achieve the holy grail of cognitive science: learning to “think, fast and slow.”
- On an easy Sudoku, the CEO and Worker solve it in just one or two sessions. The CEO’s internal state becomes very stable and confident. The Expert sees this, the “Confidence Score” skyrockets, and it advises an early halt. The model “thinks fast.”
- On a brutally hard puzzle, the CEO’s state remains conflicted and uncertain after many sessions. The “Potential Score” stays high, so the Expert advises continuing, allowing the model to run many more thinking sessions. The model “thinks slow,” dedicating its computational budget precisely where it’s needed most.
And the proof is in the pudding. This isn’t just a clever architecture for Sudoku. The paper shows that this highly organized, adaptive reasoning engine excels at any task that requires deep, structured thought.
As the results show, this small, 27M parameter model, trained from scratch on only about 1000 examples, achieves near-perfect performance on tasks where even massive, state-of-the-art models fail completely. This includes:
- Maze-Hard: Not just solving a maze, but finding the optimal path in a huge 30x30 grid, a task that requires intense, backtracking-heavy search.
- Abstraction and Reasoning Corpus (ARC-AGI): A benchmark that tests pure inductive reasoning by asking the model to guess the abstract rule from just a few visual examples.
On these incredibly difficult benchmarks, the largest models often score 0%. HRM, with its ability to sustain a deep, adaptive, and iterative search for a solution, dramatically outperforms them. It succeeds not because it knows more, but because it thinks better.
Now, with a design this elegant and powerful, it’s fair to ask: what’s the catch? Every engineering choice is a trade-off, and the one HRM makes is profound. It trades the massive data and knowledge requirements of LLMs for a massive increase in computational depth. This deliberate choice comes with its own set of challenges, which are not flaws, but rather the price of admission for this new kind of thinking.
First, let’s talk about the training time. While the model is small and the dataset is tiny, the training process is brutally intensive. This is because the forward pass in a standard model is a straight, eight-lane superhighway — a huge batch of data goes through once, and you’re done. The forward pass in HRM, however, is not a highway. It’s a deep, loopy, iterative journey. For a single puzzle, the model might perform 512 or more sequential steps of computation. Each of those steps must wait for the one before it to finish.
Zoom image will be displayed
This creates the “supercar in a traffic jam” problem. Even with an army of powerful GPUs, the fundamentally serial nature of the reasoning process means you can’t just throw more hardware at it to speed it up in parallel. You have to wait as the model patiently completes its winding, iterative trip. This makes experimentation slow and computationally expensive, a very real, practical hurdle.
The second trade-off is one of focus versus flexibility. HRM is the ultimate specialist — a grandmaster of the task it was trained on. It learns the deep structure of a problem with incredible data efficiency. But the grandmaster of Sudoku knows nothing of mazes. The model’s stunning performance comes from being trained from scratch for each specific task. This isn’t a flaw so much as a feature of its design. It proves that true expertise can be learned from very little data if the architecture is right, but it also means that this expertise doesn’t automatically transfer. It’s a scalpel, not a Swiss Army knife.
Finally, HRM operates brilliantly within what we can call “closed-world” problems. In Sudoku, mazes, or ARC, all the rules and information needed to find the solution are contained within the prompt itself. HRM is a pure reasoning engine, designed to unravel this kind of deep, formal logic. But it contains no world knowledge. You can’t ask it why the sky is blue or to summarize a historical event. This isn’t a criticism, but a clarification of its purpose. It was built to reason, not to know.
These trade-offs don’t diminish the achievement of HRM. Instead, they clarify its role in the AI ecosystem. It is not a replacement for the broad, knowledgeable LLM. It is something new, something different — a specialized logic engine. And that, as we’ll see, is what makes the thought of combining the two so incredibly exciting.
This brings us to the most exciting thought of all. We’ve seen that the LLM is a brilliant generalist who knows everything but can’t reason deeply, and the HRM is a phenomenal specialist who can reason flawlessly but knows nothing of the world. What happens when you put them in the same room?
What happens when the ultimate specialist partners with the ultimate generalist?
You get a Dream Team. You get what might be the blueprint for the next generation of artificial intelligence.
This isn’t just wishful thinking; it’s the logical synthesis of the two most powerful ideas in modern AI. It’s a move toward a model of cognition that mirrors the “System 1” and “System 2” thinking described by Nobel laureate Daniel Kahneman.
- System 1 (The LLM): It’s fast, intuitive, and associative. It handles the effortless tasks of understanding language, retrieving facts, and providing common-sense context. It’s the brilliant librarian who has read every book in the world and knows how they all connect.
- System 2 (The HRM): It’s slow, deliberate, and logical. It handles the hard, focused work of multi-step reasoning. It’s the master mathematician in the back room who, when handed a formula from a book, can perform the complex calculations flawlessly.
Imagine how this partnership would work. You ask a complex, real-world question: “Given the logistical constraints of my five warehouses and my current shipping fleet, what is the most cost-effective distribution plan for next month’s inventory?”
- The LLM springs into action. It parses your question, understands the concepts of “warehouses,” “cost-effectiveness,” and “inventory.” It might even pull in real-time data about fuel costs. It recognizes that answering this requires a deep, algorithmic search.
- It delegates. Instead of attempting a fragile and inefficient Chain-of-Thought, the LLM recognizes this as a job for its specialist partner. It formats the problem — the warehouse locations, inventory levels, constraints — and hands it off to the HRM, which has been trained as a master logistics and optimization engine.
- The HRM does what it does best. It enters its deep, iterative M*N*T loop. It explores possibilities, backtracks from dead ends, and computes the optimal path in its silent, efficient, latent space. It doesn’t write a single word; it just reasons.
- The HRM returns the solution. It hands a perfectly structured, optimal plan back to the LLM.
- The LLM communicates the answer. It translates the structured plan back into beautiful, human-readable language, explaining the “what” and the “why” with full context and clarity.
This is the future HRM points toward. A system that doesn’t just know things, but can reason about them. A system that combines the breadth of knowledge with the rigor of logic. A system that is not only more capable but vastly more efficient and reliable, using its deep reasoning engine only when necessary. This is the hope that this special paper from Singapore has ignited.
It has laid a path for a future where the two great paradigms of the last decade no longer compete, but collaborate. The loop isn’t just back; it’s here to complete the circle.
Rich Sutton’s “Bitter Lesson” has always loomed large in AI: general methods that scale with computation will inevitably win. For years, I felt the sting of that lesson as the Transformer’s brute-force scaling left the elegant, stateful loop in the dust. But perhaps HRM teaches us that the lesson was never about brute force alone; it was about finding the most effective general architecture to structure that computation.
My own bitter moments, I hope, are now finally in the past.
And in a final, beautiful piece of irony, this entire post — a celebration of a new path for deep reasoning — was written in collaboration with an LLM, the very kind of model whose dominance started this long journey. It seems the most powerful thinking of all is collaborative.
The future, it turns out, isn’t a straight line. It’s a loop ᦠ.
And I wouldn’t have it any other way.