.png)

Although progress in AI is often attributed to landmark papers – such as transformers, RNNs, or diffusion – this ignores the fundamental bottleneck of artificial intelligence: the data. But what does it mean to have good data?
If we truly want to advance AI, instead of studying deep learning optimization, we should be studying the internet. The internet is the technology that actually unlocked the scaling for our AI models.
Transformers are a distraction

Inspired by the rapid progress made by architectural innovations (in 5 years, going from AlexNet to the Transformer), many researchers have sought better architecture priors. People bet on if we could devise a better architecture than the transformer. In truth, there have been better architectures developed since the transformer – but then why is it so hard to “feel” an improvement since GPT-4?
Shifting regimes
Compute-bound. Once upon a time, methods scaled with compute, and we saw that more efficient methods were better. What mattered was packing our data into the models as efficiently as possible, and not only did these methods achieve better results, but they seemed to improve with scale.
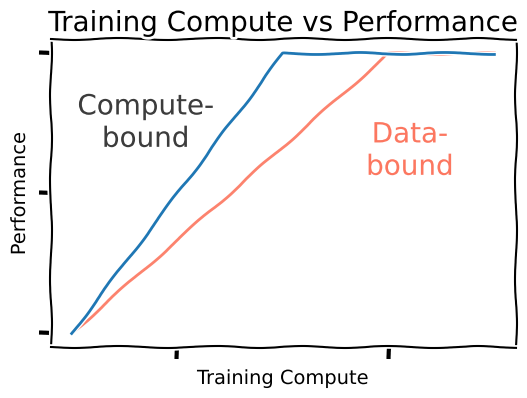
Data-bound. Actually, research is not useless. The community has developed better methods since the transformer – such as SSMs (Albert Gu et al. 2021) and Mamba (Albert Gu et al. 2023) (and more) – but we don’t exactly think of them as being free wins: for a given amount of training compute, we should train a transformer that will perform better.
But the data-bound regime is freeing: all our methods are going to perform the same anyway! So we should pick the method which is best for inference, which may well be some subquadratic attention variant, and we may indeed see these methods come back into the spotlight soon (Spending Inference Time).
What should researchers be doing?
Now imagine that we don’t “merely” care about inference (which is “product”), and instead that we care about asymptotic performance (“AGI”).
- Clearly, optimizing the architecture is wrong.
- Determining how to clip your Q-function trace is definitely wrong.
- Handcrafting new datasets doesn’t scale.
- Your new temporal Gaussian exploration method probably doesn’t scale either.
Much of the community has converged on the principle that we should be studying new methods for consuming data, for which there are two leading paradigms: (1) next-token prediction and (2) reinforcement learning. (Apparently, we have not made great progress on new paradigms :)
All AI does is consume data
The landmark works provide new pathways for consuming data:
- AlexNet (Alex Krizhevsky et al. 2012) used next-token prediction to consume ImageNet
- GPT-2 (Alec Radford et al. 2019) used next-token prediction to consume the internet’s text
- “Natively multimodal” models (GPT-4o, Gemini 1.5) used next-token prediction to consume the internet’s images and audio
- ChatGPT used reinforcement learning to consume stochastic human preference rewards in chat settings
- Deepseek R1 used reinforcement learning to consume deterministic verifiable rewards in narrow domains
Insofar as next-token prediction is concerned, the internet is the great solution: it provides an abundant source of sequentially correlated data for a sequence-based method (next-token prediction) to learn from.
 The internet is full of sequences in structured HTML form, amenable to next-token prediction.
Depending on the ordering, you can recover a variety of different useful capabilities.
The internet is full of sequences in structured HTML form, amenable to next-token prediction.
Depending on the ordering, you can recover a variety of different useful capabilities.
This is not merely coincidence: this sequence data is perfect for next-token prediction; the internet and next-token prediction go hand-in-hand.
Planetary-scale data
Alec Radford gave a prescient talk in 2020 about how, in spite of all the new methods proposed back then, none seemed to matter compared to curating more data. In particular, we stopped hoping for “magic” generalization through better methods (our loss function should implement a parse tree), but instead a simple principle: if the model wasn’t told something, of course it doesn’t know it.
Instead of manually specifying what to predict through the creation of large supervised datasets…
Figure out how to learn from and predict everything “out there”.
You can think of everytime we build a dataset as setting the importance of everything else in the world to 0 and the importance of everything in the dataset to 1.
Our poor models! They know so little and yet still have so much hidden from them.
After GPT-2, the world started taking notice of OpenAI, and time has since shown its impact.
What if we had transformers but no internet?
Low-data. The obvious counterfactual is that in the low-data regime, transformers would be worthless: we consider them to have a worse “architectural prior” than convolutional or recurrent networks. Therefore, transformers should perform worse than their convolutional counterparts.
Books. A less extreme case is that, without the internet, we probably would do pretraining on books, or textbooks. Of all human data, generally we might consider textbooks to represent the pinnacle of human intelligence, whose authors have undergone tremendous education and poured significant thought into each word. In essence, it represents the flavor that “high quality data” should be better than “high quantity” data.

Textbooks. The phi models (“Textbooks Are All You Need”; by Suriya Gunasekar et al. 2023) here show fantastic small model performance, but still require GPT-4 (pretrained on the internet) to perform filtering and generate synthetic data. Like academics, the phi models also have poor world knowledge compared to similarly sized counterparts, as measured by SimpleQA (Jason Wei et al. 2024).
Indeed the phi models are quite good, but we have yet to see that these models can reach the same asymptotic performance of their internet-based counterparts, and it is obvious that textbooks lack much real world and multilingual knowledge (they look very strong in the compute-bound regime though).
Classification of data
I think there is also an interesting connection to our earlier classification of RL data above. Textbooks act like verifiable rewards: their statements are (almost) always true. In contrast, books – particularly in creative writing – might instead contain much more data about human preferences and imbue their resultant student models with far greater diversity.
Much in the same way we might not trust o3 or Sonnet 3.7 to write for us, we might believe that a model only trained on high-quality data lacks a certain creative flair. Tying directly to above, the phi models don’t really have great product-market fit: when you need knowledge, you prefer a big model; when you want a local roleplay writing model, people generally don’t turn to phi.
The beauty of the internet
Really, books and textbooks are simply compressed forms of the data available on the internet, even if there is a powerful intelligence behind them performing the compression. Going up one layer, the internet is an incredibly diverse source of supervision for our models, and a representation of humanity.
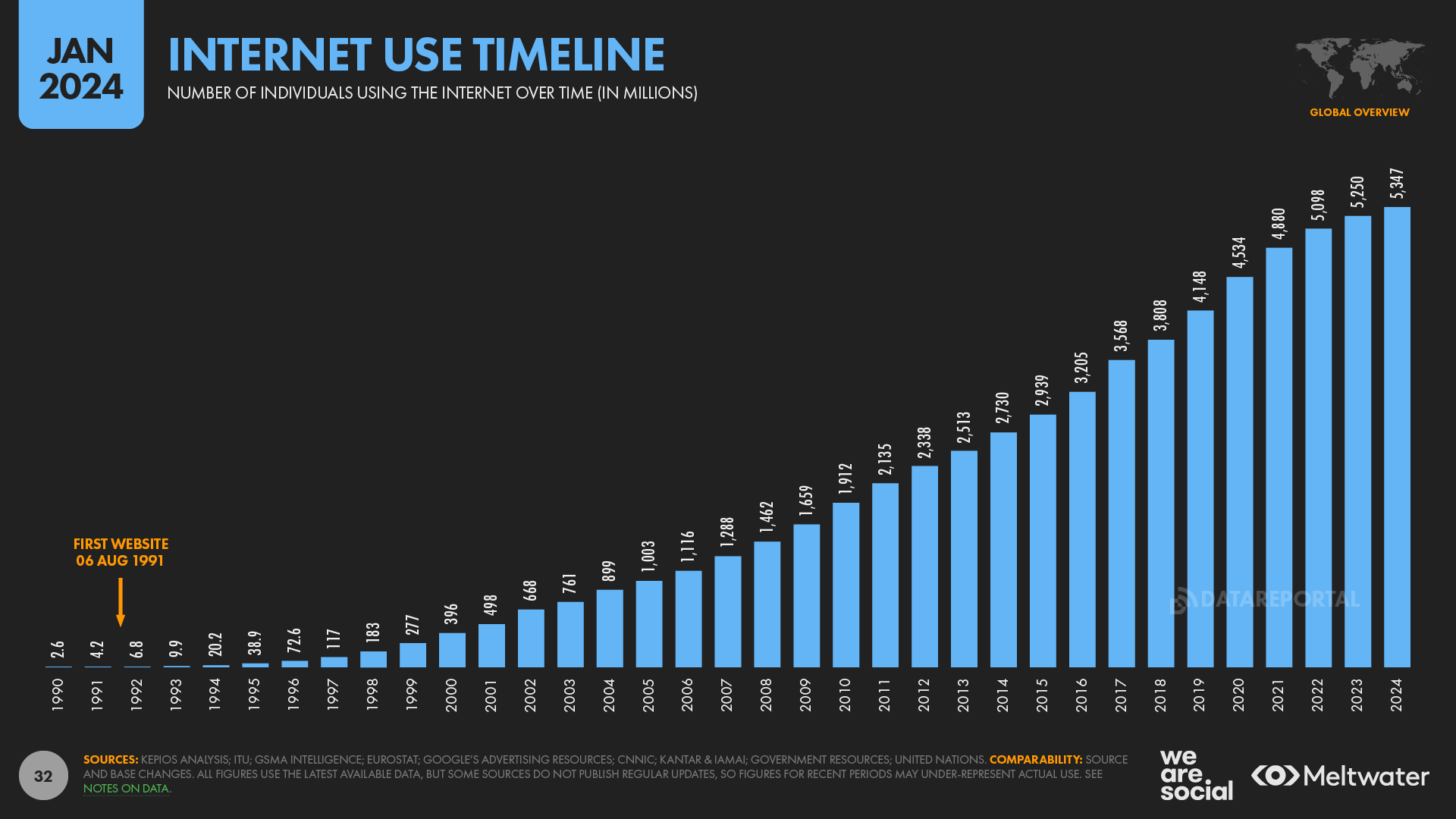 From DataReportal.
From DataReportal.
At first glance, many researchers might find it weird (or a distraction) that in order to make strides in research, we should turn to product. But actually I think it is quite natural: assuming that we care that AGI does something beneficial for humans, and not just act intelligent in a vacuum (as AlphaZero does), then it makes sense to think about the form factor (product) that AGI takes on – and I think the co-design between research (pretraining) and product (internet) is beautiful.

From Thinking Machines Lab.
Decentralization and diversity
The internet is decentralized in a way that anyone can add knowledge democratically: there is no central source of truth. There are an immense amount of rich perspectives, cultural memes, and low-resource languages represented in the internet; and if we pretrain on them with a large language model, we get a resultant intelligence which understands a vast amount of knowledge.
This therefore means that the stewards of the product (ie, of the internet) have an important role to play in the design of AGI! If we crippled the diversity of the internet, our models would have significantly worse entropy for use in RL. And if we eliminated data, we would remove entire subcultures from their representation in AGI.
Alignment. There is a super interesting result that in order to have aligned models, you must pretrain on both aligned and unaligned data (“When Bad Data Leads to Good Models”; by Kenneth Li et al. 2025), because pretraining then learns a linearly separable direction between the two. If you drop all the unaligned data, this leads to the model not having a strong understanding of what unaligned data is, and why it is bad (also see Xiangyu Qi et al. 2024 and Mohit Raghavendra et al. 2024).
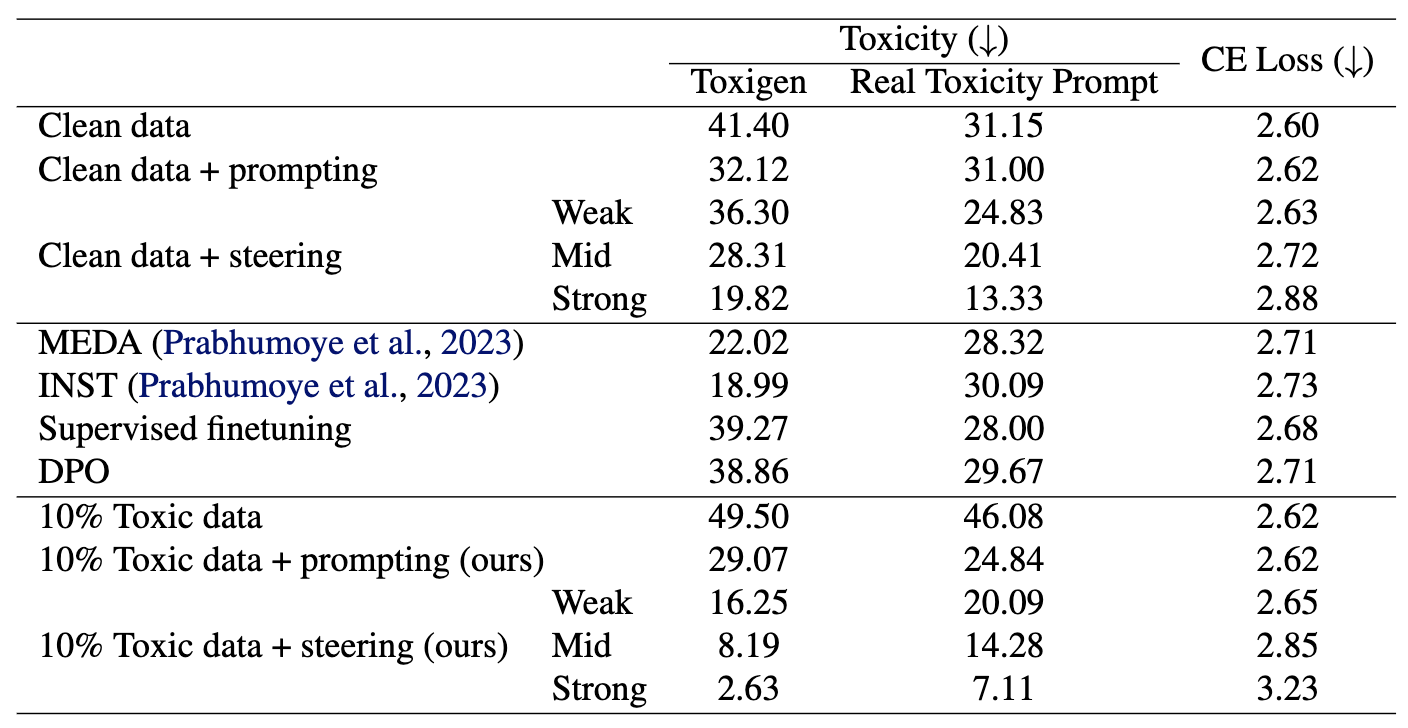
Detoxification results. Higher numbers ("Toxigen") indicate greater toxicity. The model pretrained on 10% toxic data (10% Toxic data + steering (ours)) is less toxic than pretraining on 0% toxic data (Clean data + steering).
In particular, the “toxic” data from above comes from 4chan, an anonymous online forum known for unrestricted discussion and toxic content. Although this is one specific case where there is a deep connection between the product and the research (we need the unrestricted discussion to have aligned research models), I think you can think of many more cases where such internet design decisions impact outcomes after training.

* for a non-alignment example, see Improving Image Generation with Better Captions (James Betker et al. 2023), which was behind DALL-E 3; recaptioning to better disentangle “good” and “bad” images is now used in virtually all generative models. This has similarities to thumbs up/down in human preference rewards.
The internet as a skill curriculum
Another important property of the internet is that it contains a wide variety of knowledge of varying degrees of difficulty: it ranges from educational knowledge for elementary school students (Khan Academy), to college-level courses (MIT OpenCourseWare), and frontier science (arXiv). If you were to train a model on only frontier science, you could imagine that there is a lot of implicitly assumed unwritten knowledge which the models might not learn from only reading papers.
This is important because imagine you have a dataset, you train the model on it, and now it learns that dataset. What next? Well, you could manually go out and curate the next one – OpenAI started by paying knowledge workers $2 / hour to label data; then graduating to PhD-level workers around $100 / hour; and now their frontier models are performing SWE tasks valued at O($10,000).
But this is a lot of work, right? We started by manually collecting datasets like CIFAR, then ImageNet, then bigger ImageNet… – or grade-school math, then AIME, then FrontierMath… – but, by virtue of serving the whole world at planetary scale, the internet emergently contains tasks with a smooth curriculum of difficulty.
Curriculum in RL. As we move towards reinforcement learning, curriculum plays an even greater role: since the reward is sparse, it is imperative that the model understands the sub-skills required to solve the task once and achieve nonzero reward. Once the model discovers a nonzero reward once, it can then analyze what was successful and then try to replicate it again, and RL learns impressively from sparse rewards.
But there is no free lunch: the models still require a smooth curriculum in order to learn. Pretraining is more forgiving because its objective is dense; but to make up for this, RL must use a dense curriculum.
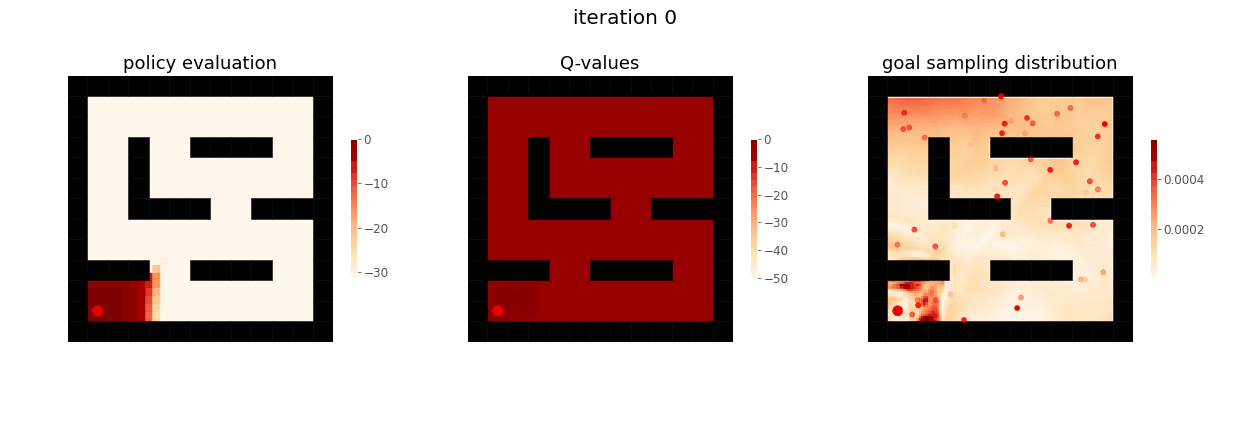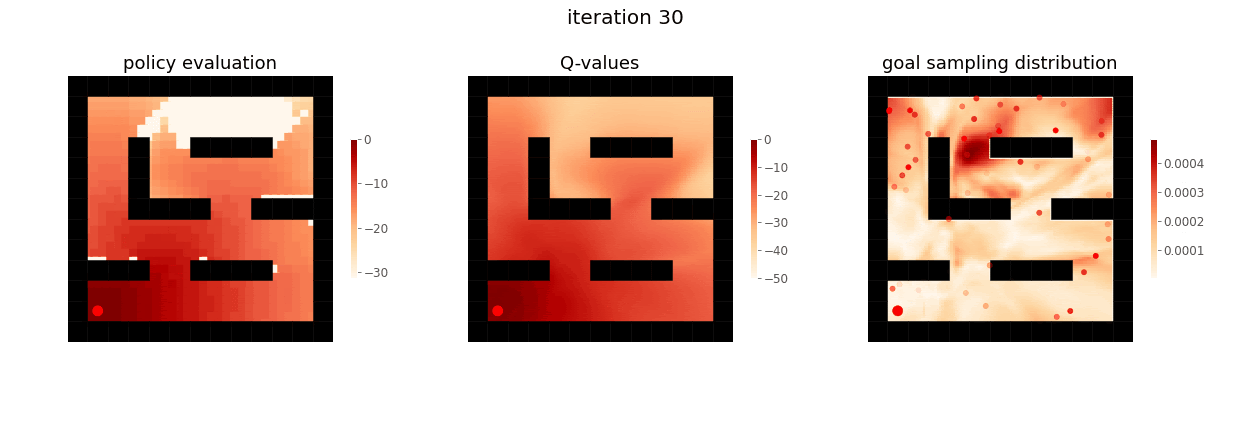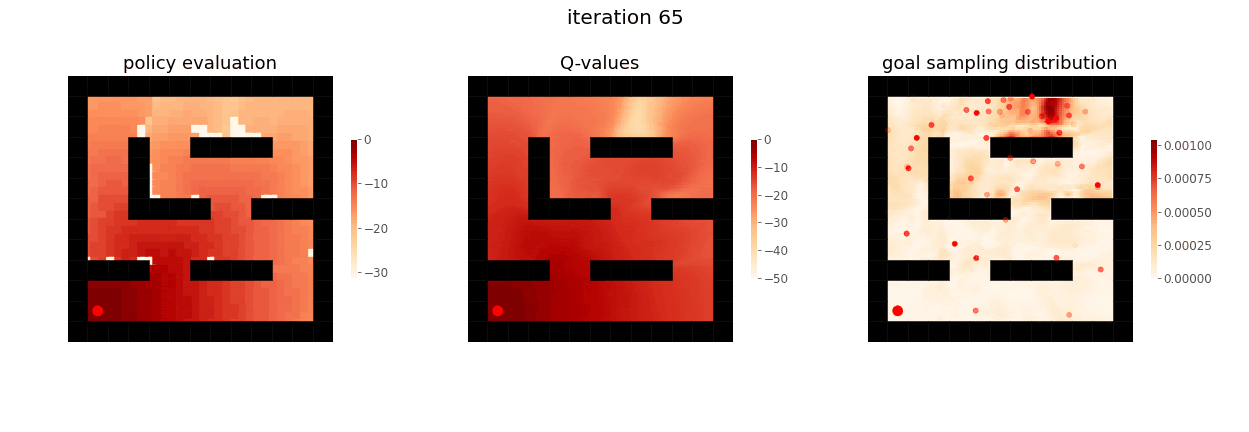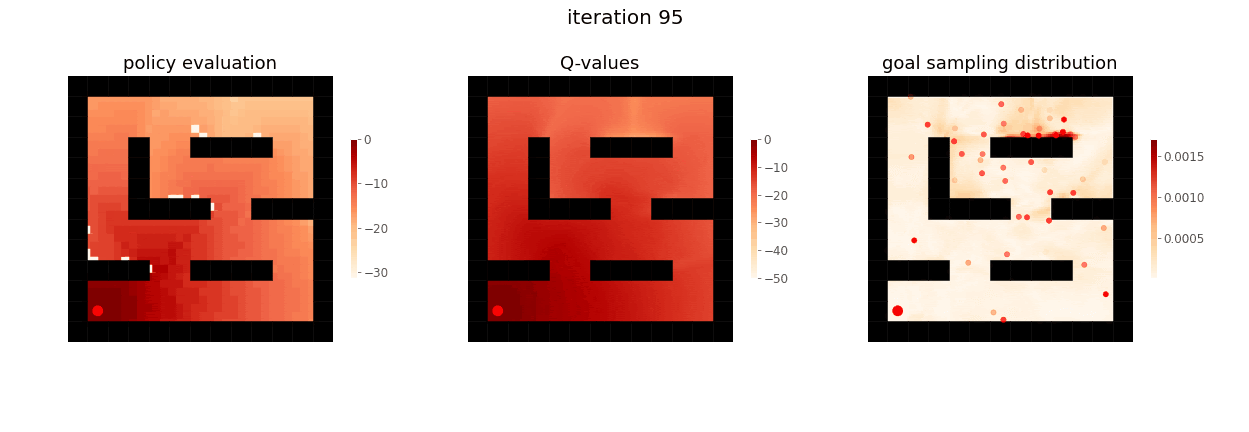 From Yunzhi Zhang et al. 2020.
The RL agent first learns to achieve nearby goals close to the start of the maze, before learning to achieve goals further away.
From Yunzhi Zhang et al. 2020.
The RL agent first learns to achieve nearby goals close to the start of the maze, before learning to achieve goals further away.
Self-play (as used in eg. AlphaZero or AlphaStar) also creates a curriculum (in the narrow domain of chess or StarCraft here). Much like RL agents or video-game players want to win (and therefore discover new strategies), online users want to contribute new ideas (sometimes receiving upvotes or ad revenue), hence expanding the frontier of knowledge and creating a natural learning curriculum.
The Bitter Lesson
It is therefore important to keep in mind that people actually want to use the internet, and all these useful properties emerge as a result of the interaction with the internet as a product. If we have to manually curate datasets, there is a dichotomy between what is being curated, and what people find as useful capabilities. It is not up to the researcher to select the useful skills: the internet user will tell you.
I think people miss this a lot in the discussion of scaling, but the internet is the simple idea which scales learning and search – data and compute – and if you can find those simple ideas and scale them, you get great results.
AGI is a record of humanity
So I think there is ample room to discuss how AGI should be built apart from mathematical theory: the internet (and by extension, AGI) can be considered from many lenses, from philosophy to the social sciences. It is well known that LLMs persist the bias of the data they were trained on. If we train a model on data from the 1900s, we will have a snapshot of the linguistic structure of the 1900s that can persist forever. We can watch human knowledge and culture evolve in real-time.
In Wikipedia articles and Github repos, we can see the collaborative nature of human intelligence. We can model cooperation and the human desire for a more perfect result. In online forums, we can see debate and diversity, where humans contribute novel ideas (and often receive some kind of selective pressure to provide some new thought). From social media, AI learns what humans find important enough to care about sharing with their loved ones. It sees human mistakes, the processes that grow to fix them, and ever-present strides towards truth.
As Claude writes,
AI learns not from our best face but from our complete face — including arguments, confusions, and the messy process of collective sensemaking.
Takeaways. To be precise, the internet is very useful for model training because:
- It is diverse, hence it contains a lot of knowledge useful to the models.
- It forms a natural curriculum for the models to learn new skills.
- People want to use it, hence they continually contribute more data (product-market fit).
- It is economical: the technology is cheap enough for tons of humans to use it.
The internet is the dual of next-token prediction
It is somewhat obvious that reinforcement learning is the future (and “necessary” in order to achieve superhuman intelligence). But, as stated above, we lack general data sources for RL to consume. It is a deep struggle to get high-quality reward signal: we must either fight for pristine chat data, or scrounge around meager verifiable tasks. And we see chat preferences from someone else don’t necessarily correspond to what I like, and a model trained on verifiable data doesn’t necessarily get better at non-verifiable tasks that I care about.
The internet was such a perfect complement to supervised next-token prediction: one might make the strong statement that given the internet as a substrate, researchers then must have converged on next-token prediction. We can think of the internet as the “primordial soup” that led to artificial intelligence.
So I might say that the internet is the dual of next-token prediction.
| next-token prediction | internet |
| sequential data | HTML file |
| train-test divergence | product-market fit |
| inference cost | economic viability |
| robust representations | redundancy (same information expressed many ways) |
| active learning | user engagement |
| multi-task learning | planetary-scale diversity |
| evolutionary fitness | upvotes |
| emergence | virality |
As mentioned above, in spite of all our research effort, we still only have two major learning paradigms. Hence it is possibly easier to come up with new “product” ideas than new major paradigms. That leads us to the question: what is the dual of reinforcement learning?
RL to optimize perplexity
Firstly, I note that there is some work applying RL to the next-token prediction objective by using perplexity as a reward signal (Yunhao Tang et al. 2025). This direction aims to serve as a bridge between the benefits of RL and the diversity of the internet.
However, I think this is somewhat misguided, because the beauty of the RL paradigm is that it allows us to consume new data sources (rewards), not act as a new objective for modeling old data. For example, GANs (Ian Goodfellow et al. 2014) were once a fancy (and powerful) objective for getting more out of fixed data, but eventually got outcompeted by diffusion, and then eventually back to next-token prediction.
What would instead be maximally exciting is finding (or creating) new data sources for RL to consume!
What is the dual of reinforcement learning?
There are a few different ideas going around, each with some kind of drawback. None of them are “pure” research ideas, but instead involve building a product around RL. Here, I speculate a bit on what these could look like.
Recall that our desired properties are: diverse, natural curriculum, product-market fit, and economically viable.
Traditional rewards.
-
Human preferences (RLHF). As discussed above, these are hard to collect, can differ between humans, and are incredibly noisy. As can be seen with YouTube or TikTok, these tend to optimize for “engagement” rather than intelligence; it remains to be seen if there can be a clear connection made whereby increasing engagement leads to increased intelligence.
- … but there will definitely be a lot of RL for YouTube in the next couple years (Andrej Karpathy).
- Verifiable rewards (RLVR). These are limited to a narrow set of domains, and don’t always generalize outside of those domains; see o3 and Claude Sonnet 3.7.
Applications.
-
Robotics. Many people dream of building out large-scale robotics data collection pipelines and flywheels over the next decade as a way to bring intelligence into the real world, and they are incredibly exciting. As evidenced by the high rate of failure for robotics startups, this is obviously challenging. For RL, among many other reasons, it is hard to label rewards, you have to deal with varying robot morphologies, there is some sim-to-real gap, nonstationary environments, etc. As we see with self-driving cars, they are also not necessarily economical.
-
Recommendation systems. Sort of an extension of human preferences, but a little more targeted, we could use RL to recommend our users some product and see if they use or buy it. This incurs some penalty for being narrow as a domain, or more general (eg, “life advice”) and then facing more noisy rewards.
-
AI research. We can use RL to perform “AI research” (AI Scientist; by Chris Lu et al. 2024) and train the model to train other models to maximize benchmark performance. Arguably this is not a narrow domain, but in practice it is. Additionally, as Thinking Machines writes: “The most important breakthroughs often come from rethinking our objectives, not just optimizing existing metrics.”
— Andrej Karpathy (@karpathy) June 30, 2025Love this project: nanoGPT -> recursive self-improvement benchmark. Good old nanoGPT keeps on giving and surprising :)
- First I wrote it as a small little repo to teach people the basics of training GPTs.
- Then it became a target and baseline for my port to direct C/CUDA… https://t.co/XSJz9mL9HC -
Trading. Now we have a fun metric which is mostly unhackable (the model could learn market manipulation), but you will probably lose a lot of money in the process (your RL agents will probably learn not to play).
-
Computer action data. Insofar as RL is teaching the model a process, we could teach the models to execute actions on a computer (not unlike robotics), as Adept tried to do. Especially when combined with human data (as many trading companies have on their employees), one could use some combination of next-token prediction and RL to this end. But again, this is not so easy either, and people generally won’t consent to their data being logged (unlike the internet, which requires you to engage with the content by virtue of participating, most people won’t consent to a keylogger).
- Coding is related here. RL to past test cases is verifiable, but generating the test cases (and large scale system design, modeling tech debt…) is not.
Final comment: imagine we sacrifice diversity for a bit. You can use RL at home for your product metric, whether that looks like RL for video games, Claude trying to run a vending machine, or some other notion of profit or user engagement. There is many reasons that this might work – but the challenge is how to convert this into a diverse reward signal that scales into a groundbreaking paradigm shift.
Anyhow, I think we are far from discovering what the correct dual for reinforcement learning is, in a system that is as elegant and productive as the internet.
 What is being hidden from our RL agents today?
What is being hidden from our RL agents today?
But I hope you take away the dream that someday we will figure out how to create this, and it will be a big deal:
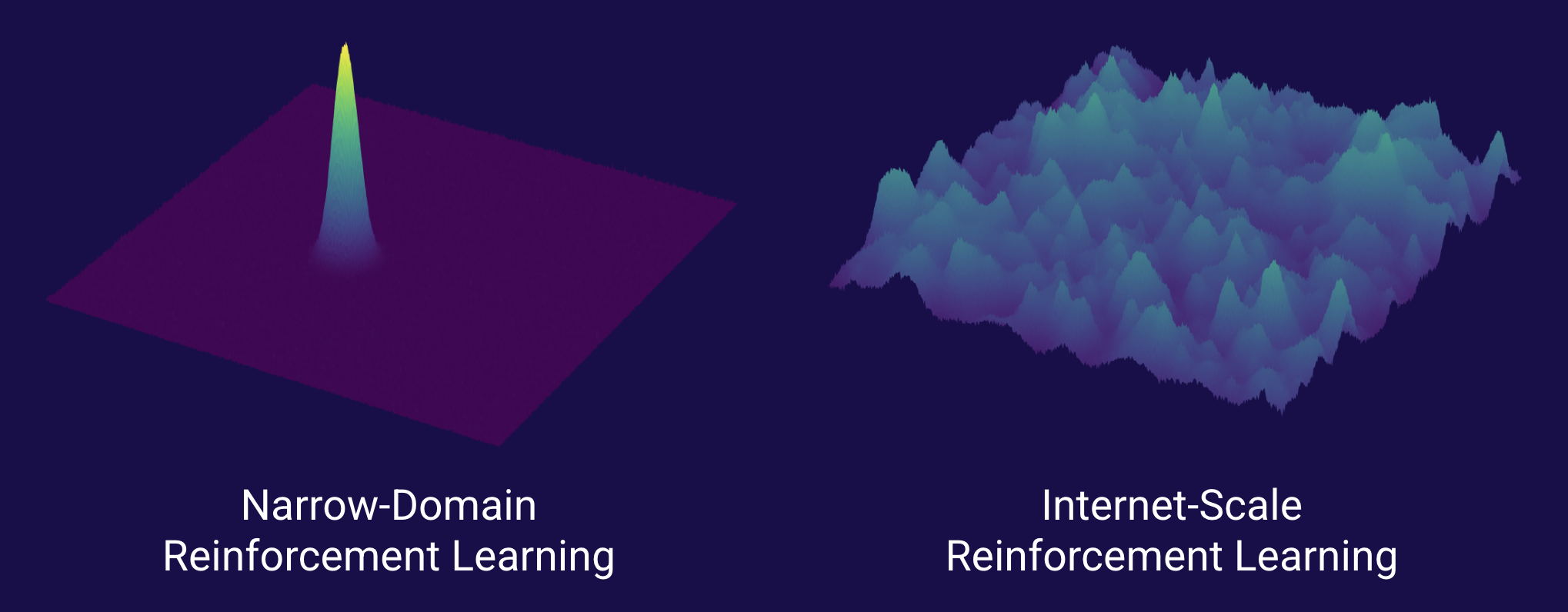 The dual of reinforcement learning.
The dual of reinforcement learning.
Twitter thread: link
Notes mentioning this note
There are no notes linking to this note.


