.png)


Note: apologies for the double-send if you got two of these, I messed something up in the settings!
Let’s be honest with each other: the funding for protein foundation model startups got a little crazy for a moment. EvolutionaryScale got $142M in mid-2024, Latent Labs got $50M in early-2025, Chai Discovery got $70M in mid-2025. And, of course, the giant two: Isomorphic Labs with $600M in funding in early 2025, and Xaira Therapeutics with an insane $1B in funding in mid-2024.
Things have calmed down since then, so I think it’s a good moment to look back at this with some fresh eyes and ask: was any of this a good idea?
It’s become quite common to tell one another that no, obviously not, these were a series of escalating, FOMO-y investments that had basically zero basis in objective reality. I empathize with this viewpoint. Protein models are increasingly recognized as commoditized things, where the open-source stuff is actually quite good, and, even at the private level, there didn’t seem to be a differentiation between one group’s pretrained weights and another’s. If you really squinted, maybe, just maybe, the open-source Boltz-1 was slightly worse than Alphafold3 by a few percentage points in a few domains, but how much does that matter? Surely it’s all within a standard deviation of one another? How could this justify the immense investments needed to train these models?
But this view has also become so universally held that, honestly, it’s getting a little boring. Increasingly, I have grown more and more curious about what actually was the opinion of people who invested into these things. People knock on VC’s a lot, but I have a pretty high opinion of nearly every biotech VC I’ve met, and it’s difficult for me to imagine that it was all irrational. Unfortunately, the articles that VC’s write on why they invested into certain things — including these companies — are nearly always uninformative, mostly vague gesturing at ‘the transformation of biology’. You could look at this and think ‘okay, nobody knows why they invested in this’, but I mostly think the vagueness comes from the fact that they don’t have a strong financial incentive to say what their actual bet is.
So what was the actual reason to put money into these companies? It’s difficult to come up with a coherent narrative, so I’m just going to list a few interesting reasons that are swirling in my head.
The divergence of private and public models being on par with one another may accelerate far faster than anyone thinks, entirely due to being able to afford the dataset necessary to optimize for multiple things at once.
Let’s consider Chai-2’s results from July 2025 as a decent view into how much better the private models are than one open-sourced one—RFDiffusion—for the task of miniprotein design. The results are hindered by a bit due to the fact that the best open-source miniprotein design model—Bindcraft—is not included here. But whatever, let’s pretend RFDiffusion is as good as open-source gets.
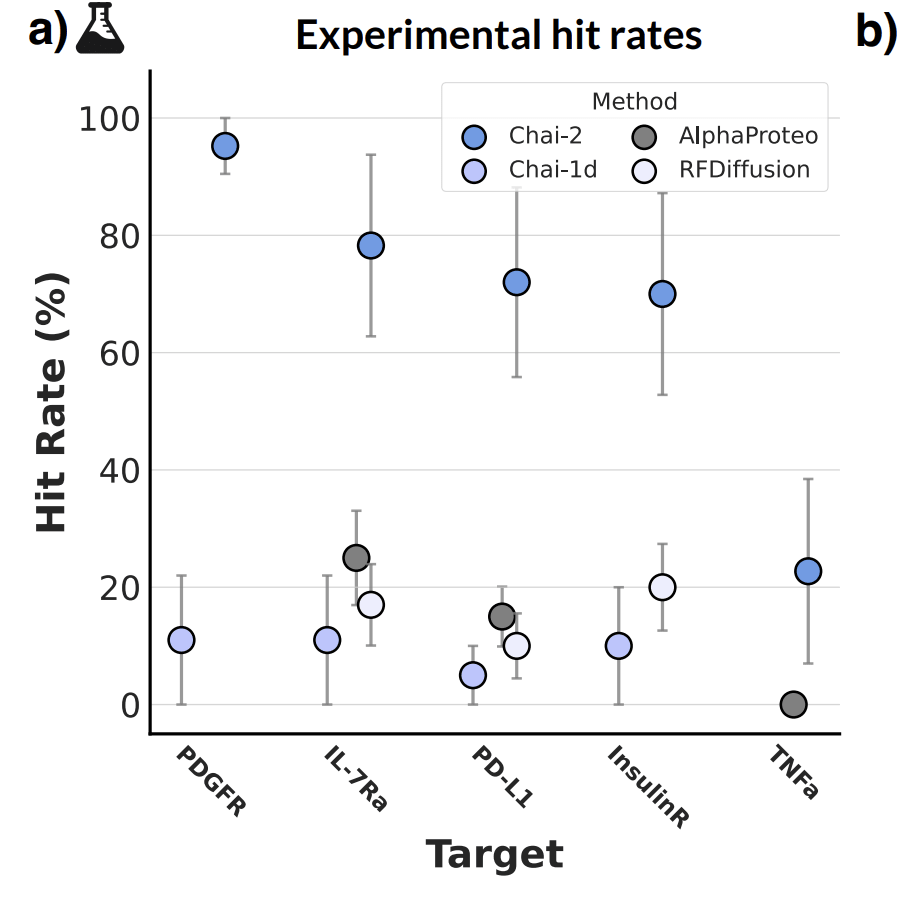
The usual argument at this point is ‘who cares about a 10-20% → 80-100% bump?’, given that these experiments can be run in 96-well plates? Yes, it saves money, but does it unlock dramatically new biology in a way that justifies having a brand new, very expensive model? Probably not!
But I think this is missing the forest for the trees a bit. Binder design is indeed not super interesting (anymore), but it’s worth thinking about what is beyond that. Because, in fact, it is very likely that the real value of these startups may have very little to do with their ability to create binders. Binding is literally just the easiest thing you can do, because the dataset to do it has already been mostly assembled: the PDB. So it’s a good place to start your modeling work. The far more interesting capabilities is in creating binders that also satisfy a bunch of useful biochemical properties.
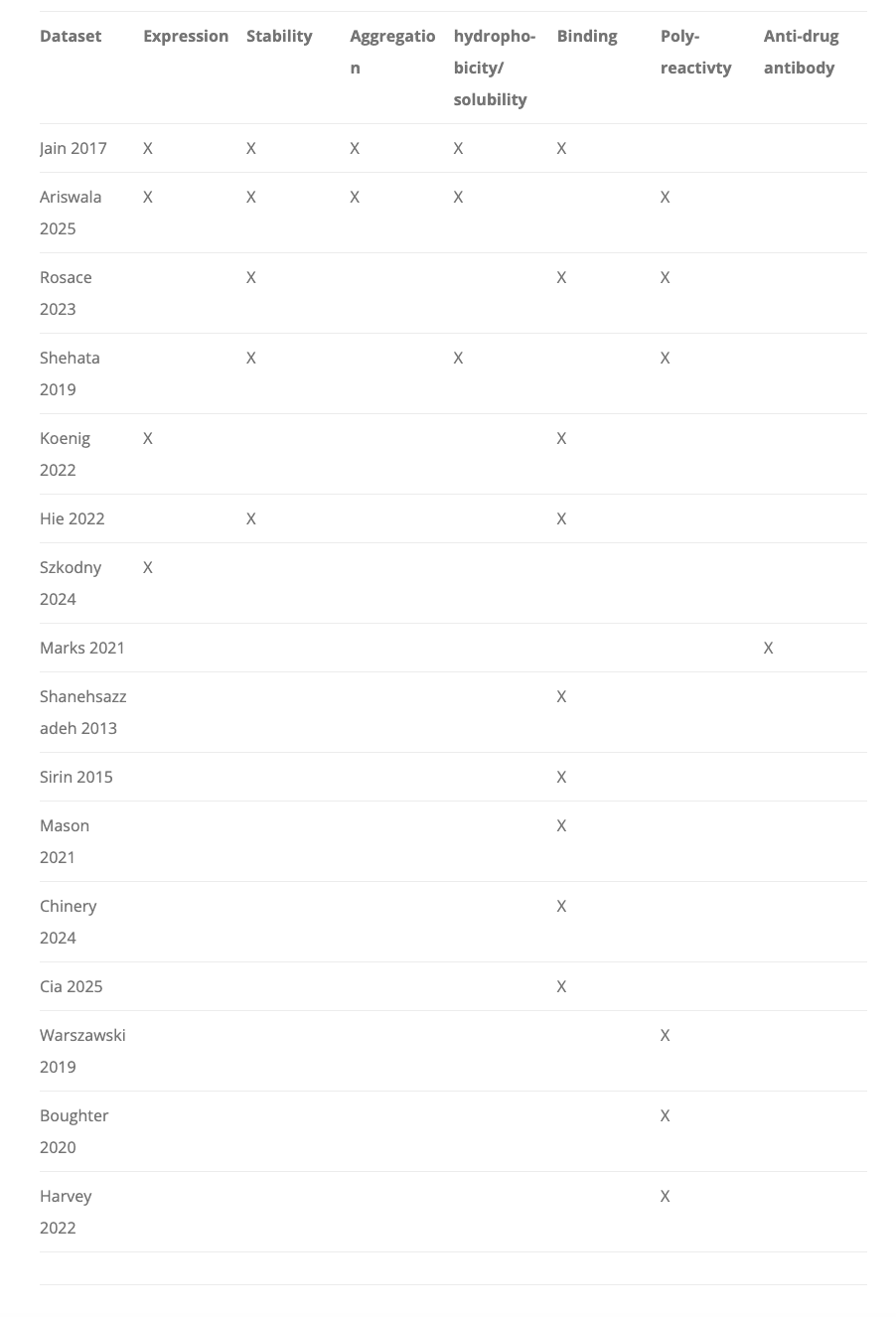
What else is there? To name a few: expression, stability, solubility, immunogenicity, receptor promiscuity, manufacturability, and PK/PD. There are plenty of models for optimizing each of these properties one-at-a-time, but creating something that can jointly optimize all these at once is a taller order. A great recent blog post from the Oxford Protein Informatics group discussed this a little, and you can see the inklings of open-sourced, multi-objective datasets here coming together, but it is still extremely early and limited in size (almost always <1000 antibodies for non-binding datasets).
What if there was a model that could really solve for all these things at once? What interesting things await if you can essentially automate a pretty significant fraction of the chemistry-relevant parts of the preclinical workflow? The literature does imply it is quite significant:
Despite the substantial level of research spending and the growing reliance on outsourcing within the non-clinical domain, to our knowledge very little data exists on the economics of specific non-clinical activities and the comparative cost of internal vs. outsourced support. Andrews, Laurencot and Roy in 2006 reported that the direct cost to conduct specific non-clinical tests for a single compound ran from tens to hundreds of thousands of dollars.
…Ferrandiz, Sussex and Towse in 2012 calculated that the average development costs from first toxicity dose to first human dose for a single compound was $6.5 million (2011$) with the costs ranging from as low as $100,000 to as high as $27 million.6 This wide range suggests many different variables affect the cost of non-clinical development.
This is all perhaps an obvious point, but I think it is worthy of being explicitly called out. I have long felt that existing benchmarks in the biology-ML world have a tendency to ideologically capture people, limiting them to consider only the scope of what is currently measurable. Here, that is binding, but everything else is really important too! And it may be only the Big Players who can afford touching everything else.



