.png)


What makes a robot a robot? Is it its hardware? Its software? Its sensors?
It can’t be just hardware. We don’t have much use for a hunk of tin that can neither think nor move. It’s not just the software either. Our goal is not to build super-intelligent software systems that can’t interact with the physical world. We can keep going on and on: beautiful LiDAR visualizations with no purpose, a ROS2 system with no subscribers to listen to it.
A robot is the interplay between ALL of these parts. It’s a combination of its hardware, sensors, software, models, firmware, etc., working together at a given time. Or, put another way, a robot is its configuration.
The configuration is a bulky, finicky amalgamation of text files that defines the robot’s behavior. And robots are complex systems. It’s a dense web of many thousands of parameters that control how that code runs: which models to load, how to tune each sensor, what safety limits to enforce. A single misconfiguration of a single parameter can bring the entire system to a halt.
In this blog, we’ll discuss why configurations (also known as configs) are so hard and how Miru is making config management easy for robotics teams.
Let’s jump in!
In practice, configs are runtime parameters that determine how a robot behaves. They aren't hardcoded, which makes the system easily adaptable to different tasks, environments, and hardware. It also avoids modifying application code for every change, no matter how trivial (such as swapping out a camera). For the scope of Miru, we consider these as ‘application configs’.
They’re distinct from ‘system configs’, which control things like the OS, networking, or device permissions. System configs are usually baked into the system image, are more static, and should be carefully changed, as the failure paths include bricking the device.
In robotics, configs are usually stored in text files — YAML, JSON, XML, or robot-specific formats like ROS params and Protocol Buffers (Protobufs). Each format has its quirks, but we won’t get into that here. (If you're curious, stay tuned, we’ll cover it in a future post.)
Almost all of the robot’s application behavior is encapsulated in its config, so the answer to this question could be ‘practically anything’. However, in the spirit of being precise, I’ve broken it down into five groups.

Different robots in the fleet may use different compute boards or end effectors. These variations affect what software runs, what models are supported, and how the robot behaves in production.
Every sensor, camera, LiDAR, and IMU needs calibration. These include intrinsics, extrinsics, and offsets. These values get stored in the config and loaded at runtime.
Models are swapped in and out based on the task, fine-tuned on customer data, or throttled based on hardware limitations.
Whether it’s a meal-prepping robot or one delivering packages, configs define the business logic it needs to know, from ingredients to barcodes.
Teams want to toggle features based on their customer, development environment (dev, beta, prod).
Configs become even gnarlier once you move from a single robot to a production fleet. Now you have uptime requirements, legacy hardware versions, multiple environments, and human operators all interacting with configs in different ways.
Let’s ground this with a simple example.
Suppose we’re deploying intelligent robot arms to two customer sites, Customer X and Customer Y. Some of our robots have the latest GPU, running VLA models. Others are older, CPU-only, and rely on classical computer vision.
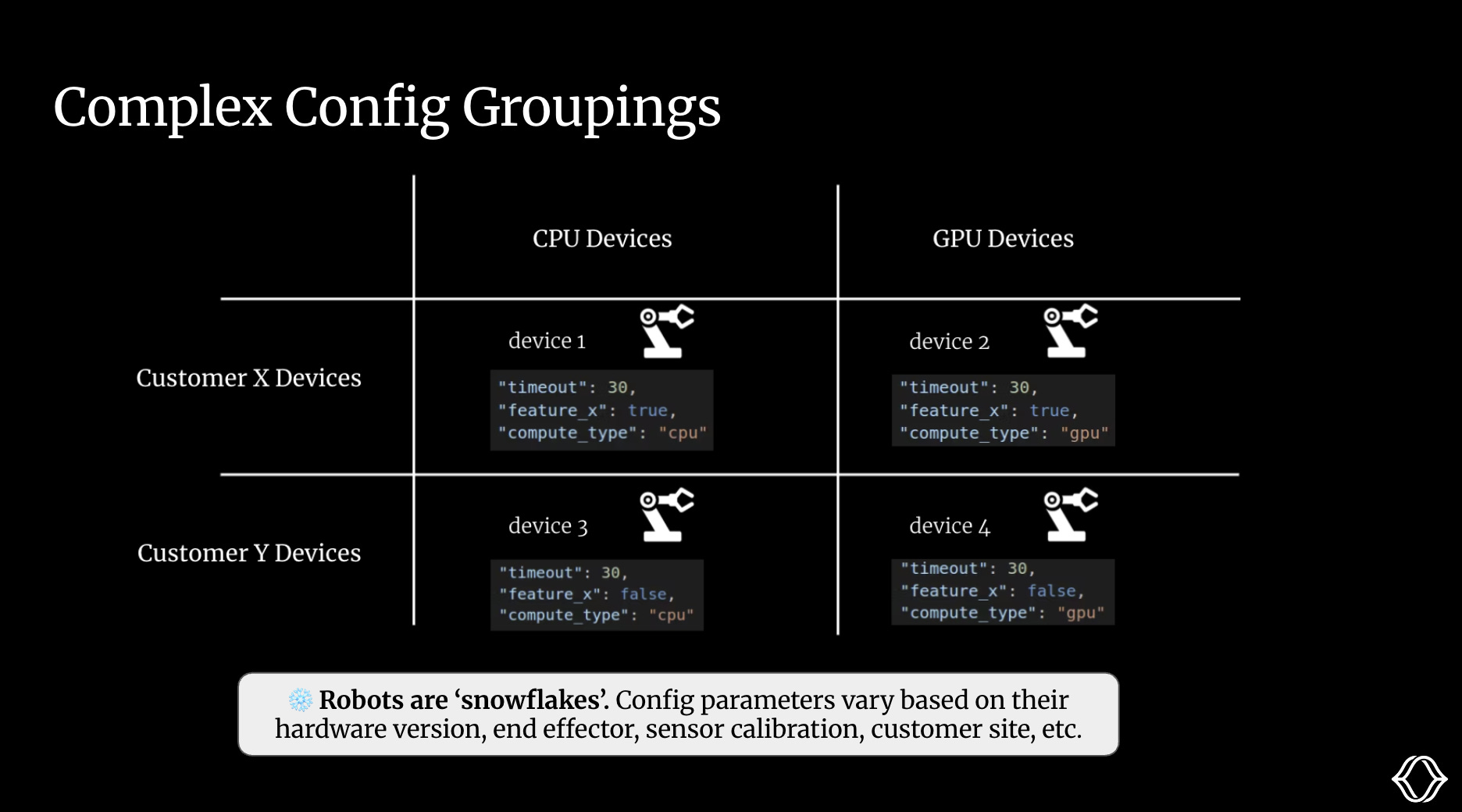
Across a fleet, robots are ‘snowflakes’. Their configs vary based on their attributes, such as hardware version, end effector, sensor calibration, and customer.
These groups often overlap in complex ways: a single customer may have multiple hardware variants, some customers may choose to beta-test early releases, and others may want to stick with the latest stable release for as long as possible.
Due to these overlapping relationships, it can be challenging to define a robot’s configuration and safely update it across the fleet. In practice, this could mean manually scouring thousands of values, editing fields, and taint tracking. And that’s for EACH robot config you want to edit!
Let’s go back to our example with Customer X and Y’s robot arms.
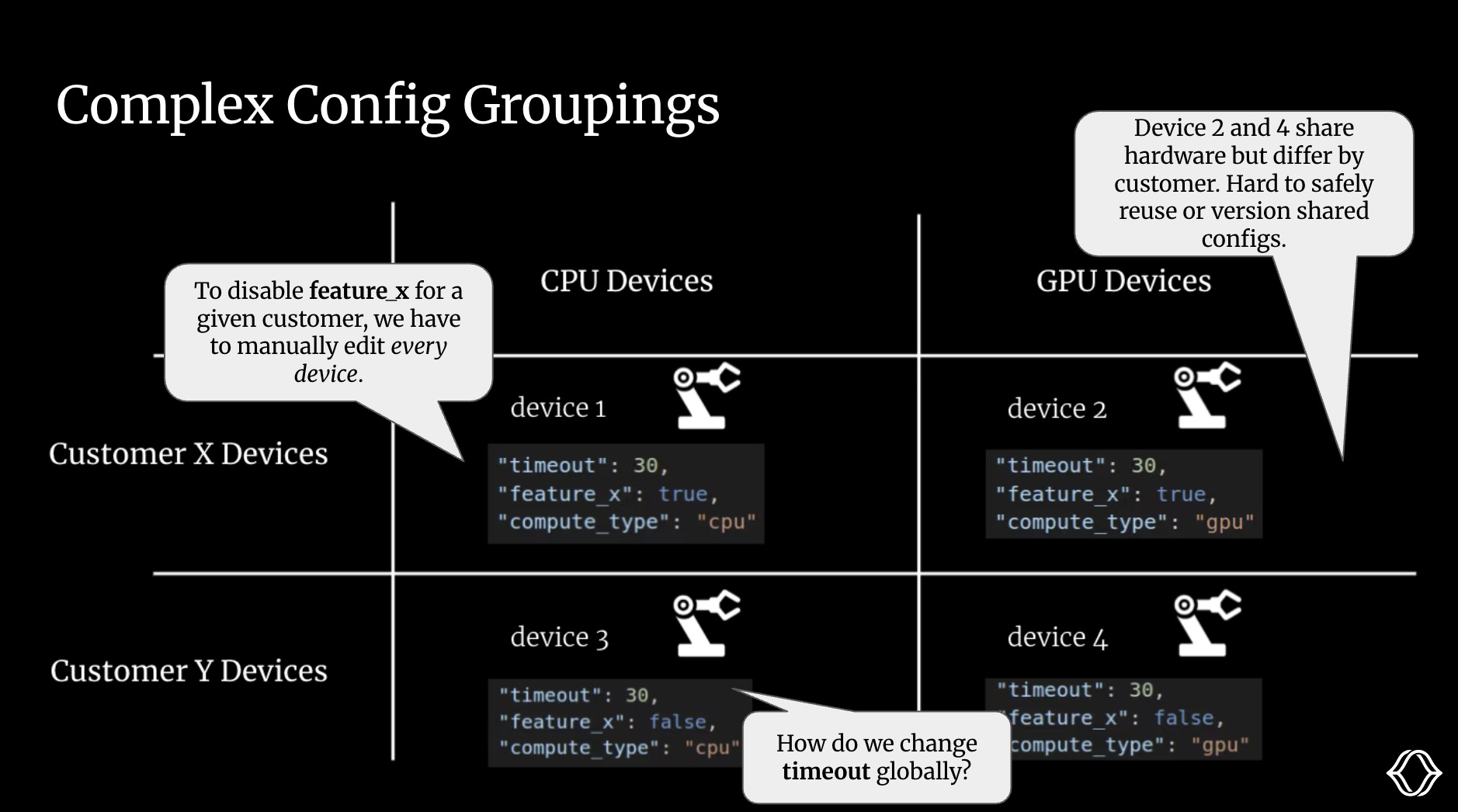
Even for this small matrix of customer/compute types, we face several challenges.
If we want to change a feature for a given customer, we’re forced to edit the config manually.
We can’t reuse sections of configs for a given compute type. The best we can do is copy and paste a file over, but this is a brittle and error-prone process.
We can’t change any configs globally.
And remember, this is just the cross-section for customer/compute type. In reality, we would have many such interdependent cross-sections for our various hardware components, models, and application logic. The groupings are complex and require a thoughtful data model to manage and apply programmatically. Most teams don’t have the luxury of building this themselves and instead make their edits and groupings manually.

A single device can have thousands of config parameters!
As your fleet grows, it becomes prohibitively difficult to manage this manually. From conversations with customers, once you move past ~10 production robots, this becomes a burning problem.

No self-respecting B2B robotics company allows itself to operate without a cavalry of Deployment/Field Engineers ;)
These folks are usually semi-technical (ranging anywhere mechEs and tradespeople, but generally not software savvy) who operate at customer sites, provisioning robots, troubleshooting, and fixing errors. As part of their duties, they frequently interact with configs:
Swap out a sensor? Change a config.
Motor behaving weirdly? Change a config.
Uptime shaky? Enable safety mode (by changing, you guessed it, a config).
Onsite at Customer X and Y, our field engineers SSH into robots and edit YAML files in Vim. They’re supposed to commit these changes back to the cloud, keep version control sane, and not break anything. This almost never happens cleanly.
The result? Misconfigurations, downtime, and a growing burden on infra engineers to trace who changed what, when, and why.
(And yes, we’ve heard firsthand of companies with hundreds of robots deployed across F500 customers whose deployment engineers are using Vim daily to edit configs!!)
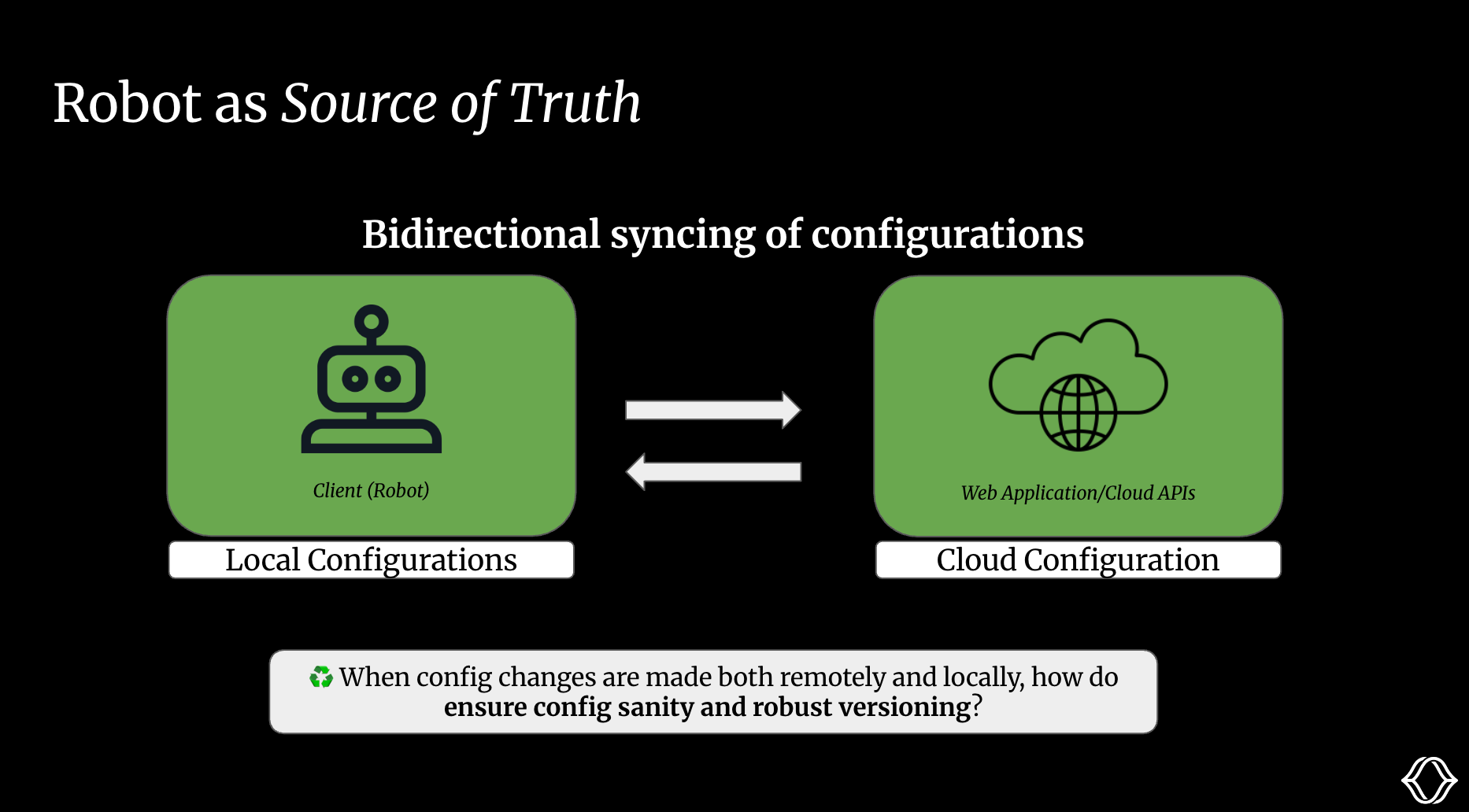
Version control can be a real pain! If our software engineers want to push a new version of a config, they need to ensure it doesn’t cause any breaking changes for our production robots. Conversely, when deployment engineers want to edit configs locally, we want to have visibility into these changes and version these edits as well.
This leads to questions like:
What’s the source of truth?
How can we ensure sanity with our configs when the cloud and local versions differ?
How can we maintain versioning when we make local edits?
These problems don’t just affect a few of our team members. They have knock-on effects throughout the entire org.
They want to skip schemas safely but are currently flying blind. There’s no guarantee a change won’t break a robot in the field. To combat this, they version their robot configs separately in their own git repo! For a fleet of 100 robots, that’s 100 separate repos that need tending to. They know it’s an imperfect solution, but if the fleet is scaling fast, they often have no other choice.
QA depends on configs to run integration tests and system validation. Without types and constraints, they’re stuck chasing bugs caused by typos and invalid values.
They want to experiment: swap in a new model, toggle a safety parameter, test a feature on just a few robots. But to do that, they have to SSH into each robot and manually change the configs. It's tedious and error-prone.
Whether it’s a meal-prepping robot or one delivering packages, configs define the business logic it needs to know, from ingredients to barcodes.
And at the end of the chain, it’s the customer who suffers. Misconfigurations and slow release cycles result in downtime, missed service-level agreements (SLAs), and a suboptimal customer experience.
Back to our example, this means that Customer X and Y churn halfway through their contract, leaving our team stuck holding the bag!
Now that we’ve explored the challenges of config management, we’ll present a high-level overview of how Miru helps engineering teams manage, version, and deploy configs to their robots.
We’ll start with a diagram of the user flow and then zoom in to different parts of the Miru application.
If you’d rather watch a demo, feel free to check out this video.
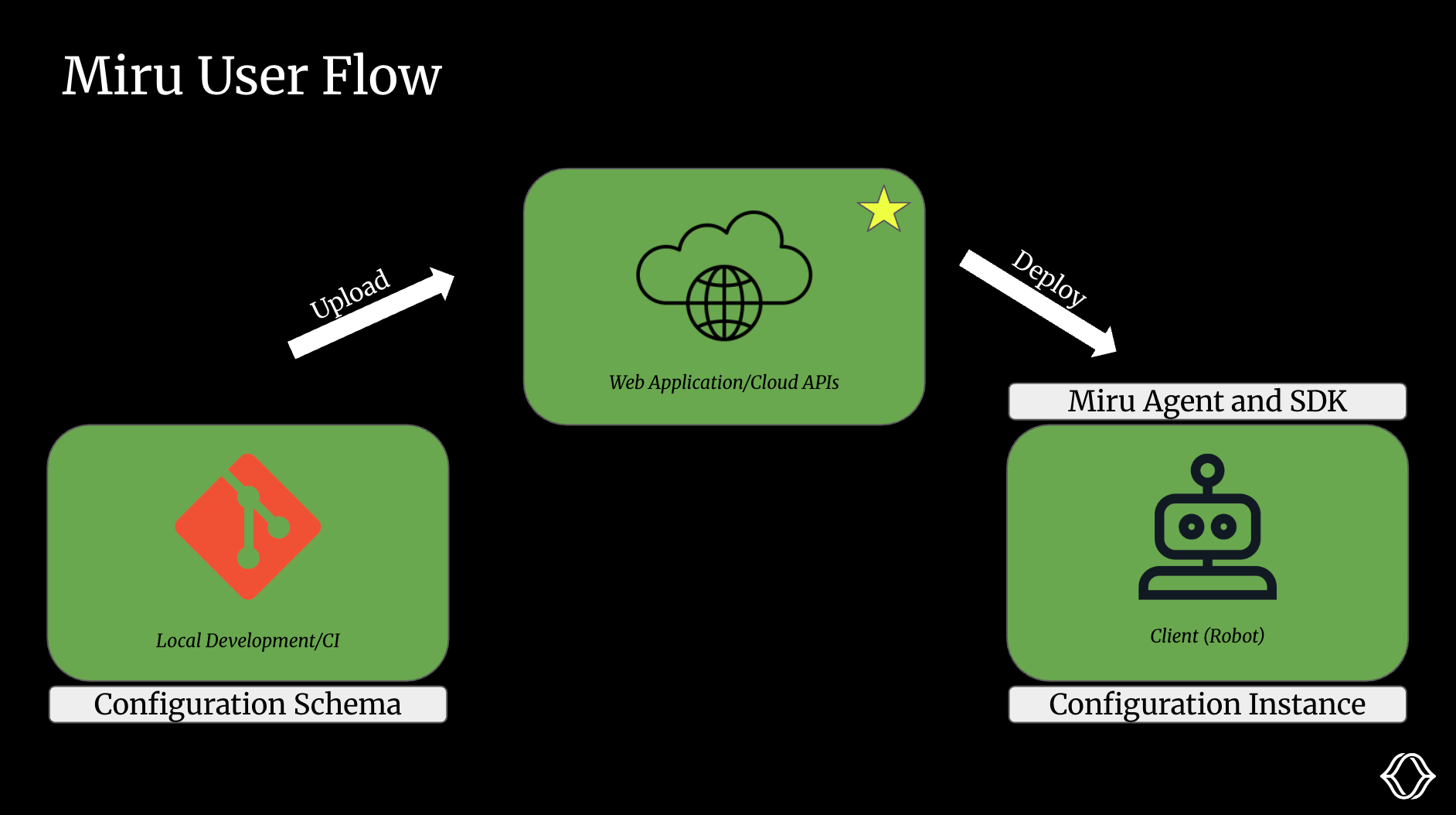
We’ll start by walking through the user flow at a high level:
You begin by iterating on your config schema locally. Once you're happy with the changes, you push the new schema version to Miru using the CLI. This is typically done as part of your continuous integration (CI) pipeline.
In the Miru dashboard, you define config values and set up logic for overrides (more on this later). Miru then renders these into a final config instance.
On the robot, the Miru Agent pulls the appropriate config instance from the cloud. The SDK (C++, Rust, Python) exposes the config instance to your application.
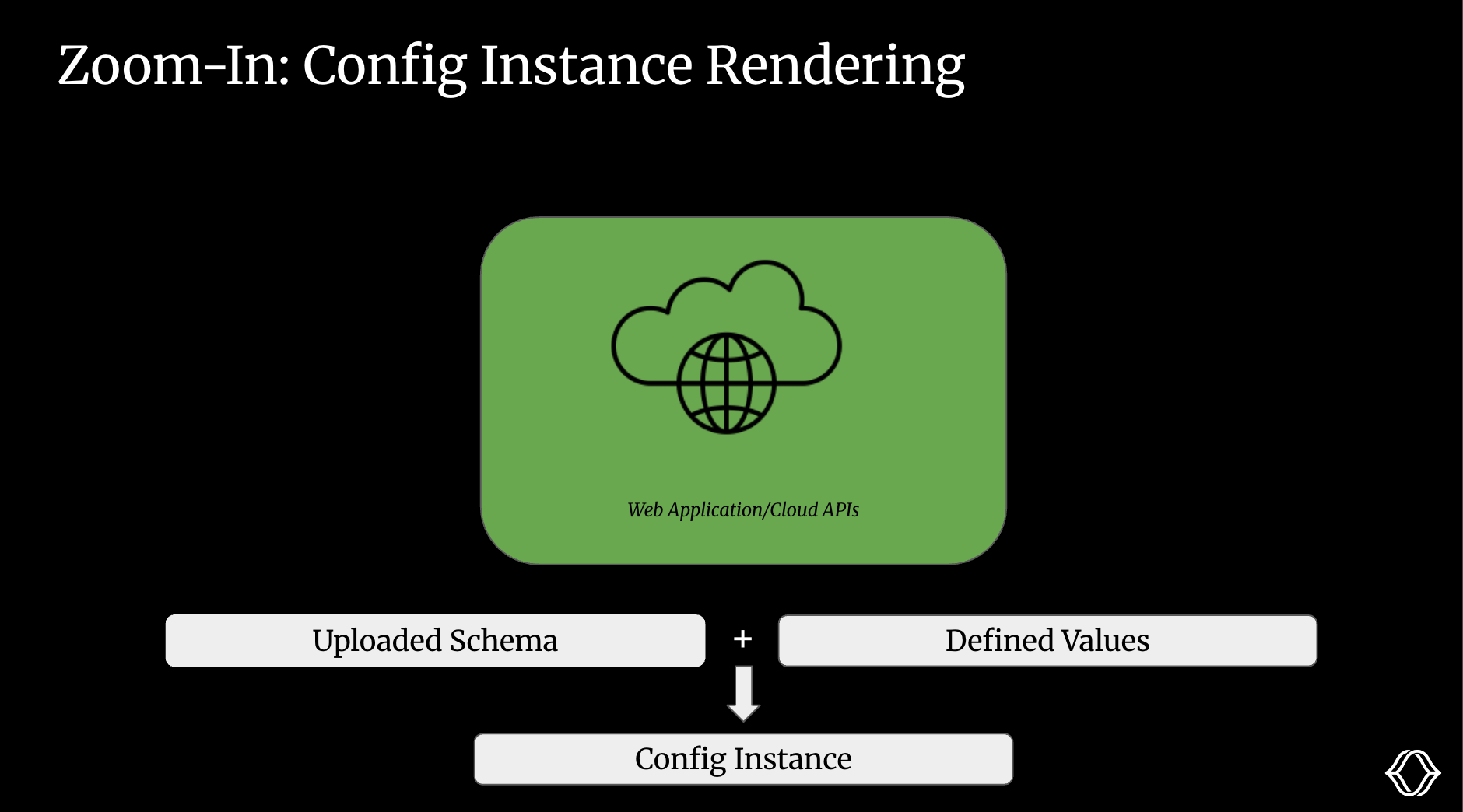
In the old world, teams manually edited config values on a per-robot basis using a text editor. With Miru, that’s no longer necessary.
You define config values in the cloud, set up override logic, and let Miru apply those values at scale across your fleet.
This process is called rendering. It combines a schema with config values to produce a final, device-specific output: a config instance.
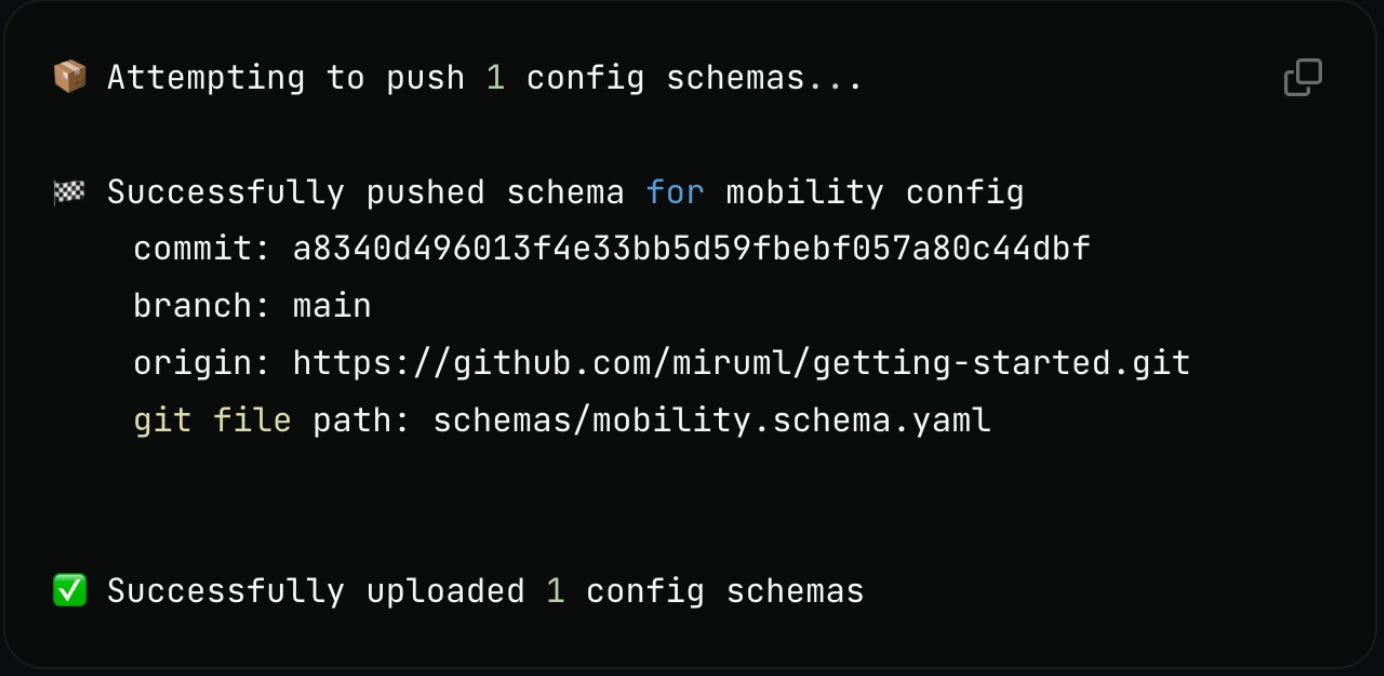
Miru requires you to define a schema for every config. This schema enforces types, value constraints, and structure. We don’t want a misformatted, vanilla YAML to break our robot!
When you're ready to publish a new version of your schema, run miru schema push. It uploads the schema to Miru and extracts Git metadata, such as the commit hash and branch, to track the version history. Most teams run this in CI.
Critically, Miru does not have access to your application code / Git repository. Application code is sacred, and we want to give users full confidence that their IP is protected.
Once the schema has been uploaded to the cloud, it’s time to define our config values!
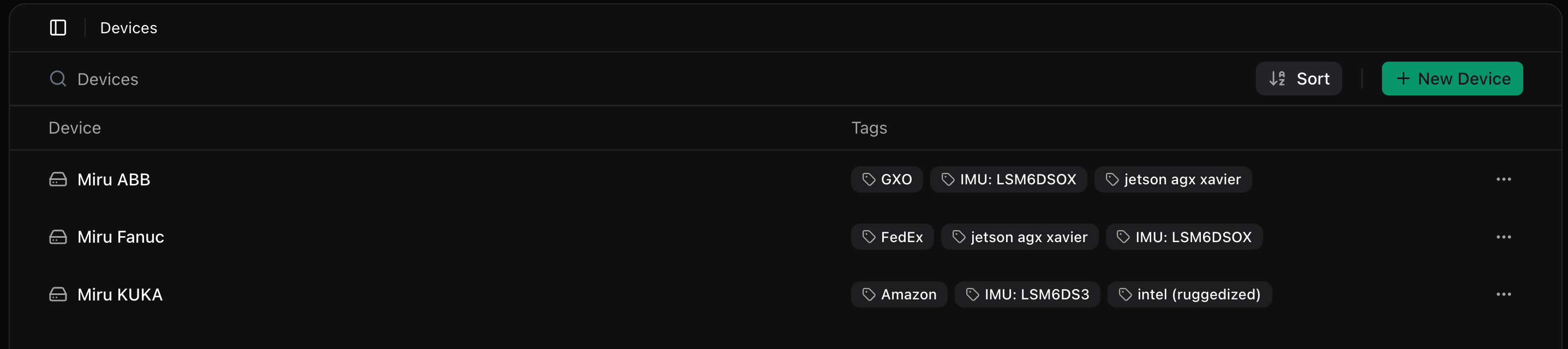
Miru utilizes a tagging system to define configuration data for our devices. We attach various tags to our devices, and these tags have metadata (as shown below) that define our configuration values.
This allows us to define configuration data across our fleet of devices in a scalable manner.
For example, the ‘Amazon’ tag has this metadata associated with it that defines its location, priority_level, robot_speed_limit, and safety_mode_enabled.
In the rendering step, this metadata is used to create our configuration instance.
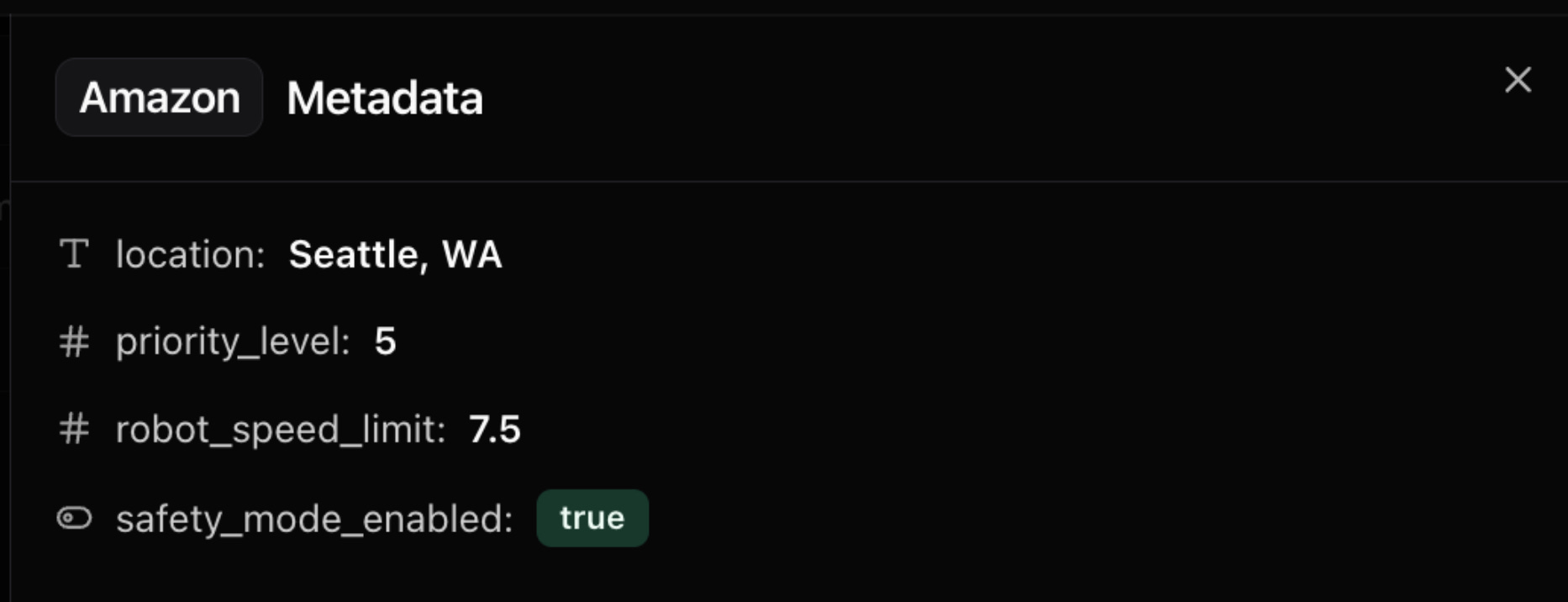
Tags are just instances of a tag type. Each tag type has its own schema, which defines the metadata each tag can contain.
For example, a Customer tag type might include Amazon, FedEx, and GXO. A Compute tag type might include Jetson Orin Nano or Raspberry Pi 4. You can also tag by environment (beta, prod), end-effector, location, or anything else you care about.
These tags are a flexible construct and allow your team to shape them based on the nuances of your fleet.
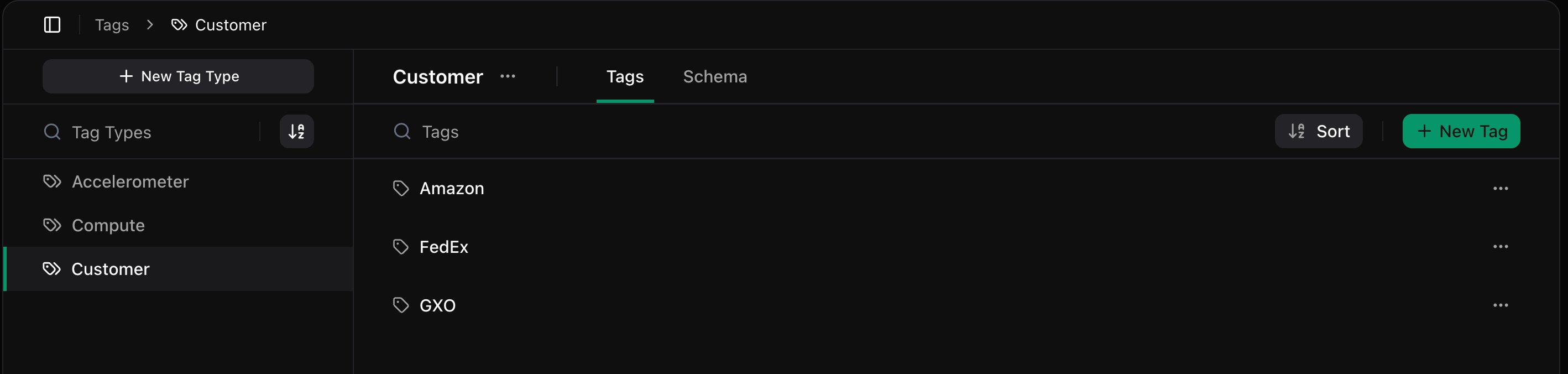
Once you've uploaded your config schema and defined tag-based values, it's time to render the config instance.
Rendering combines:
The schema (which defines the structure and defaults)
The tags assigned to a robot
The override layers defined in Miru
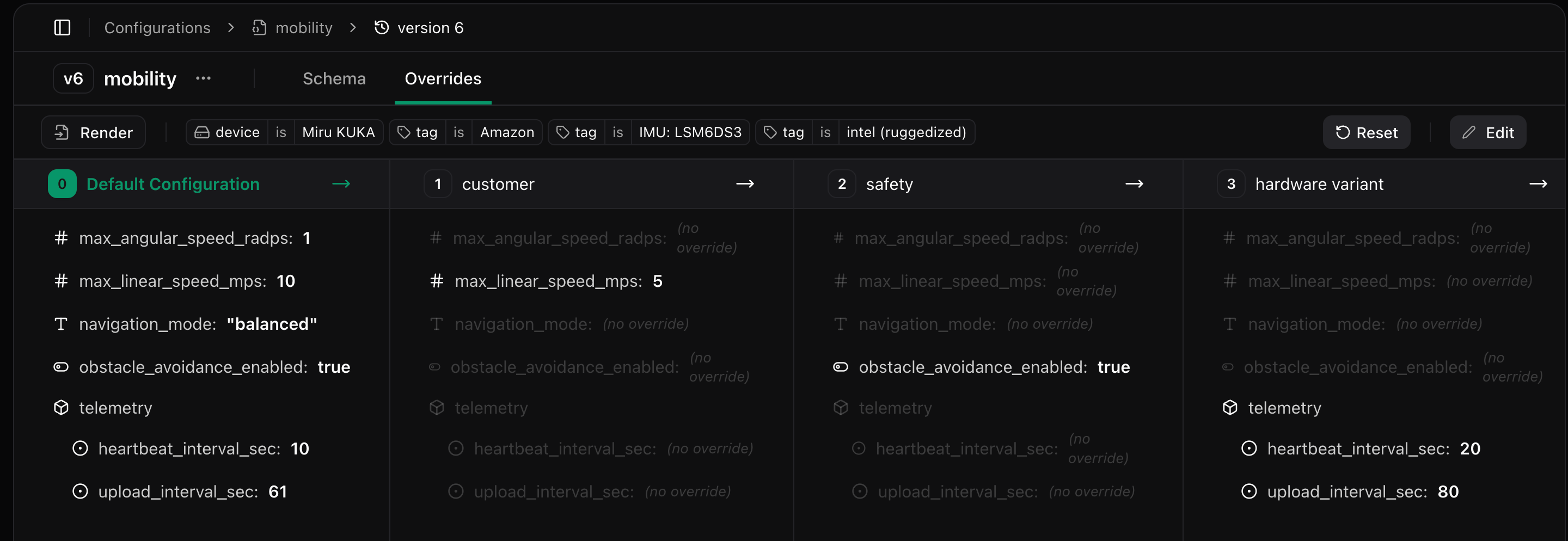
Each override layer is a named policy that pulls values from a specific tag type. For example, you might create override layers named Customer, Hardware Variant, or Safety Mode, each of which references a field in one of your tag types.
Overrides are applied in order—later layers take precedence over earlier ones. So if Safety Mode overrides max_linear_speed_mps, it will replace the value set by the Customer or Hardware Variant layers.
The result is a config instance: a concrete, validated config tailored to that robot’s tags and safe to deploy.
Once a config instance is rendered, it’s ready to be pulled down to the robot.
On the device, the Miru Agent runs as a lightweight systemd service. It uses a pull-based model to fetch the correct config instance from the cloud, identified by the device’s ID, the config schema hash, and the config type slug.
The agent is designed to be resilient. It handles flaky networks and unexpected reboots by caching the most recent config locally, so your robot can keep running even if it’s offline.
The Miru SDK connects to the agent via a Unix socket and exposes the config instance to your application as a typed object. You can fetch values directly using your preferred language. Currently, we support C++, with Rust and Python SDKs coming soon.
In this blog, we walked through the challenges of configs in robotics and how Miru makes this easy for production fleets.
If your team is struggling with this problem, please reach out! We’d love to help. If you’re interested in learning more about our architectural decisions or have any general questions, we’d love to hear from you as well!
And lastly, if you’re feeling adventurous, why not try it yourself? (Docs | App)