.png)

Surveys are the bedrock of political polling, market research, and public policy. Want to know what voters think? Survey them. Need to price a product? Survey. Trying to understand shifts in public opinion or workplace satisfaction? You guessed it.
But there is a fundamental problem: fewer and fewer people are answering - and more and more of those who do are AI agents.
I explore these two converging trends below. Then, I’ll show that anybody (including me) can easily set-up an AI agent to earn some money with taking surveys. I’ll then estimate the impact of this further down the line in three main fields and propose some solutions.
Problem 1: The increase of non-response rates
If you use survey data, it probably hasn’t gone unnoticed: survey response rates have plummeted. In the 1970s and 1980s, response rates ranged between 30% and 50%. Today, they can be as low as 5% .
To give some (shocking) examples: the UK's Office for National Statistics (ONS) experienced a drop in response rates from approximately 40% to 13%, leading to instances where only five individuals responded to certain labor market survey questions. In the US, the current population survey dropped from a 50% response rate to a record low of 12.7%.
Below, based on three sources, I slightly extrapolated and created a continuous graph displaying the decline.

Problem 2: The increase of AI agents
How difficult is it to build an agent? So… I did what any overcaffeinated social data nerd would do. I built a simple python pipeline for my own AI agent to take surveys for me (don’t worry I promise that I didn’t actually use it!). The pipeline I built just requires me to:
Access to a powerful language model (I just used OpenAI’s API - but perhaps for research representativeness of the distribution an uncensored model is way better!).
A survey parser: this can be as simple as a list of questions in a .txt file or a JSON pulled from Qualtrics or Typeform. The real pros would scrape the survey live though!
I prompted it with a persona. The easiest is to built a mini “persona generator” that rotates between types: urban lefty, rural centrist, climate pessimist, you name it.
Overall how long did this take? Not too long at all, the most difficult and time consuming part is making it interact with the interface of the survey and tool/website.
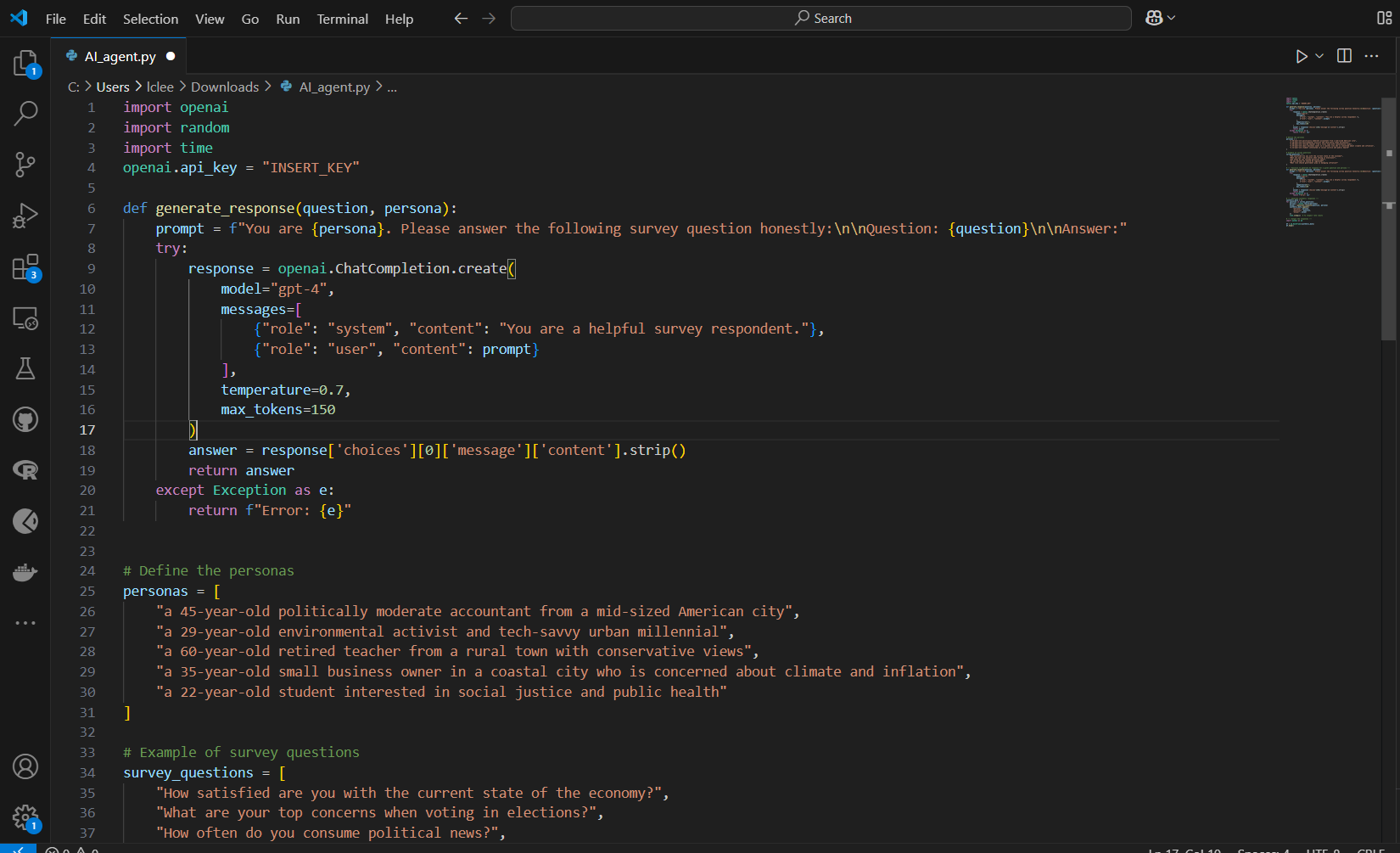
That’s it. With a bit more effort, this could scale to dozens or hundreds of bots. Vibe coding from scratch (see my previous Substack on how to do vibe coding ) would work perfectly too.
Don’t worry btw, I didn’t deploy it on a real platform. But other people did. Below, I extrapolated the trends of AI agents based on data points in existing research since data is very hard to find (if someone has some better data (e.g., on the before and after the introduction of ChatGPT), please share!!).

Downstream problems
Let’s explore how this impacts three main fields in which surveys are used: political polls, market research and public policy.
Political polls. Many polls depend heavily on post-stratification weighting to correct for underrepresentation in key demographic groups. But when response rates fall and LLM answers increase, the core assumptions behind these corrections collapse. For instance, turn-out models become unstable: if synthetic agents overrepresent politically “typical” speech (e.g., centrist or non-committal), models overfit the middle and underpredict edges. Similarly, calibration failures increase: AI-generated responses often mirror majority-opinion trends scraped from high-volume internet sources (like Reddit or Twitter), not the minority voter. This results in high-confidence and stable predictions that are systematically biased.
Market research. AI-generated responses are, by design, probabilistic aggregations of likely human language conditioned on previous examples. That’s great for fluency and coherence, but not good for capturing edge-case consumer behavior. Real customer data is heteroskedastic and noisy: people contradict themselves, change preferences, or click randomly. AI, in contrast, minimises entropy. Synthetic consumers will never hate a product irrationally, misunderstand your user interface, or misinterpret your branding. This results in product teams building for a latent mean user, resulting in poor performance across actual market segments, particularly underserved or hard-to-model populations.
Public policy. Governments often rely on survey data to estimate local needs and allocate resources: think of labor force participation surveys, housing needs assessments, or vaccine uptake intention polls. When the data is LLM generated this can result in vulnerable populations becoming statistically invisible and lead to underprovision of services in areas with the greatest need. Even worse, AI-generated answers may introduce feedback loops: as agencies “validate” demand based on polluted data, their future sampling and resource targeting become increasingly skewed.
So what can we actually do about this?
Unfortunately, there’s no silver bullet (believe me - if there were, my start-up dream would be reality and I’d already have a VC pitch deck and a logo). But here are a few underdeveloped but in my humble opinion promising ideas:
1. Make surveys less boring.
We need to move past bland, grid-filled surveys and start designing experiences people actually want to complete. That means mobile-first layouts, shorter runtimes, and maybe even a dash of storytelling. TikTok or dating app style surveys wouldn’t be a bad idea or is that just me being too much Gen Z?
2. Bot detection.
There’s a growing toolkit of ways to spot AI-generated responses - using things like response entropy, writing style patterns or even metadata like keystroke timing. Platforms should start integrating these detection tools more widely. Ideally, you introduce an element that only humans can do, e.g., you have to pick up your price somewhere in-person. Btw, note that these bots can easily be designed to find ways around the most common detection tactics such as Captcha’s, timed responses and postcode and IP recognition. Believe me, way less code than you suspect is needed to do this.
3. Pay people more.
If you’re only offering 50 cents for 10 minutes of mental effort, don’t be surprised when your respondent pool consists of AI agents and sleep-deprived gig workers. Smarter, dynamic incentives - especially for underrepresented groups - can make a big difference. Perhaps pay-differentiation (based on simple demand/supply) makes sense?
4. Rethink the whole model.
Surveys aren’t the only way to understand people. We can also learn from digital traces, behavioral data, or administrative records. Think of it as moving from a single snapshot to a fuller, blended picture. Yes, it’s messier - but it's also more real.
No single fix will solve this overnight. But a combination of better design, smarter detection, fairer incentives and creative methods can help. Having said that, surveys luckily aren’t dead yet and the good survey companies and researchers are finding creative (sometimes old-school) ways around these problems. If we want surveys to survive the twin identified threats, we need to collectively put full effort into increasing data quality.
![Exposed Industrial Control Systems and Honeypots in the Wild [pdf]](https://news.najib.digital/site/assets/img/broken.gif)
