.png)


Designing software is a process of constantly raising and solving questions. When designers face a requirement, they generate many questions, among which is a seemingly simple but fundamental one: "Where should the business logic (complexity) go?" Each time a new feature is introduced into a project, the increase in total complexity is almost certain, but how to distribute this complexity among modules can vary greatly.
For example, in software with a "client/server" architecture, engineers may find that a feature can be implemented mainly on either the server or the client side. These decisions directly affect the division of labor, development efficiency, and functional extensibility.
In such scenarios, a common design strategy is "thin client, thick server," where "thin/thick" refers to the amount of responsibility each component bears. In a "thin client" design, the server handles the main business logic, keeping the client as simple as possible.
Now, let's explore how the "thin client" concept is applied in real-world software through the story of the kubectl apply command.
A story of kubectl apply
As the most popular container orchestration system today, one of Kubernetes's most well-known designs is its declarative resource configuration feature. In short, people describe the desired state of an application in a YAML file, execute kubectl apply, and Kubernetes follows the description to run the application.
For example, here is a simple Deployment resource description for an Nginx application:
# test_nginx.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment annotations: the_app_name: nginx # *a simple annotation* spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9After executing kubectl apply on this file, you can see nginx-deployment running normally in the cluster after a short wait. If you want to make any adjustments to this resource later, simply modify the test_nginx.yaml file and re-execute the apply command.
Now, let's conduct a small experiment to gain a deeper understanding of the capabilities of the kubectl apply command.
First, use kubectl get to view the resource definitions in the cluster:
❯ kubectl get deploy -o yaml apiVersion: v1 items: - apiVersion: apps/v1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "1" kubectl.kubernetes.io/last-applied-configuration: ... the_app_name: nginx # defined in the YAML file # ... Omitted ...Pay special attention to the annotations section of this resource.
Tip: annotations are a common Kubernetes resource field that stores useful system information. They use a key-value pair structure and can be simply viewed as a dictionary in Python or map[string]string in Go.
As you can see, the annotation item the_app_name: nginx, previously defined in the test_nginx.yaml file, appears correctly in the resource. Additionally, there are some new entries in the annotation field, such as deployment.kubernetes.io/revision. These entries were not defined in the YAML file, but rather were added by Kubernetes system components, such as the "Deployment Controller", after the resource was submitted. These entries can be collectively classified as "system annotations."
Next, we will modify the test_nginx.yaml file by changing the annotation the_app_name to the_name_of_app.
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment annotations: # Deleted:the_app_name: nginx the_name_of_app: nginx # ...After re-executing the kubectl apply command and checking the resource definitions in the cluster:
❯ kubectl get deploy -o yaml apiVersion: v1 items: - apiVersion: apps/v1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "1" kubectl.kubernetes.io/last-applied-configuration: ... the_name_of_app: nginx # ...You will see that the changes have taken effect and that the annotation field the_app_name has been replaced by the_name_of_app.
Reviewing the entire "apply -> modify -> reapply" process, you will find it very intuitive. However, upon further reflection, you'll discover that there's more to it than meets the eye.
For example, during the last execution of the apply command, the YAML received by the Kubernetes server contained only one annotation key, the_name_of_app, with no additional information. Yet the server chose to use it to replace the_app_name rather than adding a new annotation key. Why is that? Also, how does the server avoid "system annotations" when updating the annotations field?
All of this is thanks to the implementation of kubectl apply.
Client-Side Apply
As mentioned earlier, the purpose of the kubectl apply command is to apply a resource definition to the cluster. However, it does not completely replace the server's resource with the local definition, which would affect system annotations. Nor does it simply apply a crude patch, which would not recognize that the old annotation the_app_name should be deleted.
To meet user expectations, kubectl apply uses a method similar to "smart patching." Specifically, every time the apply command is executed, the kubectl client reads three sets of data:
- The resource definition in the local file (test_nginx.yaml)
- The complete resource definition that was last applied to the server (obtained from the system annotation kubectl.kubernetes.io/last-applied-configuration)
- The currently active resource definition on the server (the content seen with kubectl get ...).
The client uses these data and an algorithm called "3-way merge" to generate the most logically appropriate resource patch object. Using the earlier small experiment as an example, the steps are as follows:
- The client reads the resource definition from the server.
- The client reads the resource definition from the local file and finds the annotation the_name_of_app: nginx.
- The client retrieves the last resource definition applied to the server and finds the annotation the_app_name: nginx.
- Based on these three sets of data, kubectl generates the most logically appropriate PATCH object: {"the_app_name": null, "the_name_of_app": "nginx"} -- Remove the old and add the new.
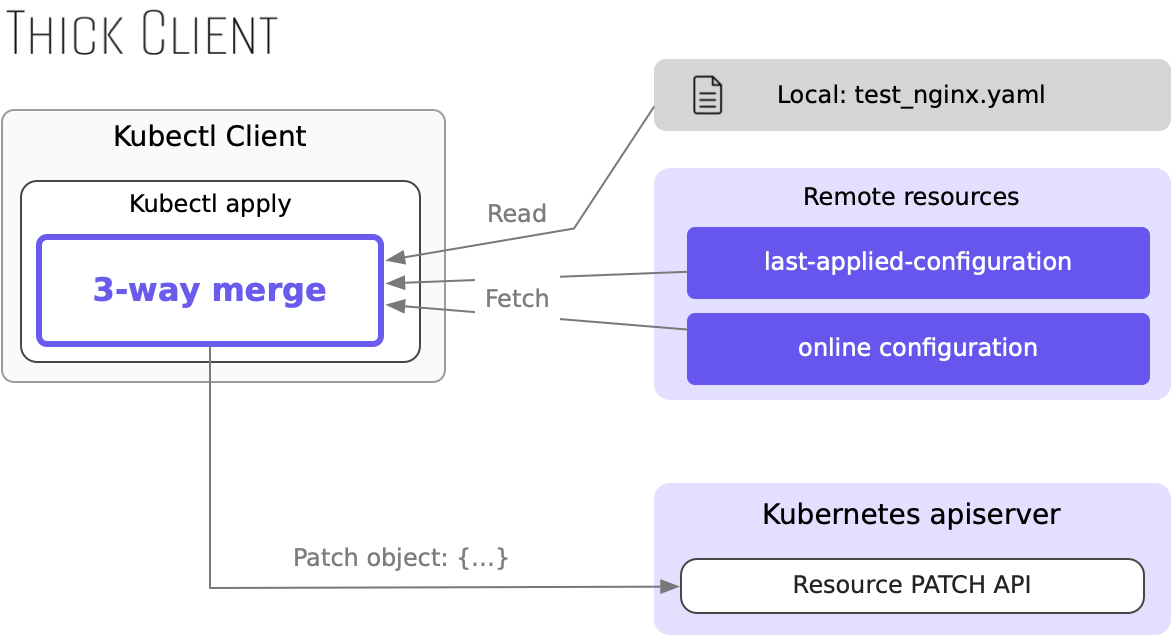
thick client and thin server: client-side apply
Since the entire process is primarily carried out on the client side, the server only provides basic read and write API support. This working mode of kubectl apply is also known as "client-side apply."
Limitations of Client-Side Apply
As demonstrated earlier, client-side apply meets user needs well. However, over time, more and more people have discovered the limitations of this model. Most notably, it has a weak conflict resolution capability.
Once a resource is submitted to the Kubernetes cluster, many modifiers may come into play, such as CLI tools, system controllers, and third-party operators, that can modify the resource definition in their preferred way. Let's use the previous Deployment as a simple demonstration.
In the nginx-deployment Deployment resource definition, the number of replicas is set to 1; therefore, after executing kubectl apply, the actual number of running replicas in the cluster is also 1.
❯ kubectl get deploy/nginx-deployment NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 1/1 1 1 24hSuppose another person comes in and skips the local YAML file. That person uses the kubectl edit command to change the number of replicas to 2:
# Second modifier: kubectl edit ❯ kubectl edit deploy/nginx-deployment # Change the replicas field to 2 and save. # The change takes effect, and the number of replicas becomes 2. ❯ kubectl get deploy/nginx-deployment NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 2/2 2 2 24hFinally, when you return to kubectl apply and re-execute kubectl apply -f test_nginx.yaml without realizing that the number of replicas has changed, it immediately reverts to 1.
This means that kubectl apply directly resets the changes made by the second person regarding the replicas. It cannot detect or manage conflicts involving multiple modifications, which results in the loss of other people's changes.
Beyond poor conflict handling, client-side apply has other issues. For instance, although the apply command is powerful, it is mostly implemented within kubectl, making it specific to kubectl. Other clients wishing to perform similar operations must implement a "3-way merge" algorithm themselves, which is costly.
Due to these issues, the community proposed a project improvement named "Apply" in March 2018: KEP-555. This proposal designed a new implementation for kubectl apply: server-side apply.
Server-Side Apply
In one sentence, we could summarize server-side apply as transforming "apply" from a client-side function into a built-in server feature. Users can invoke the "apply" algorithm to apply a resource definition by initiating an API request. This approach brings many clear benefits.
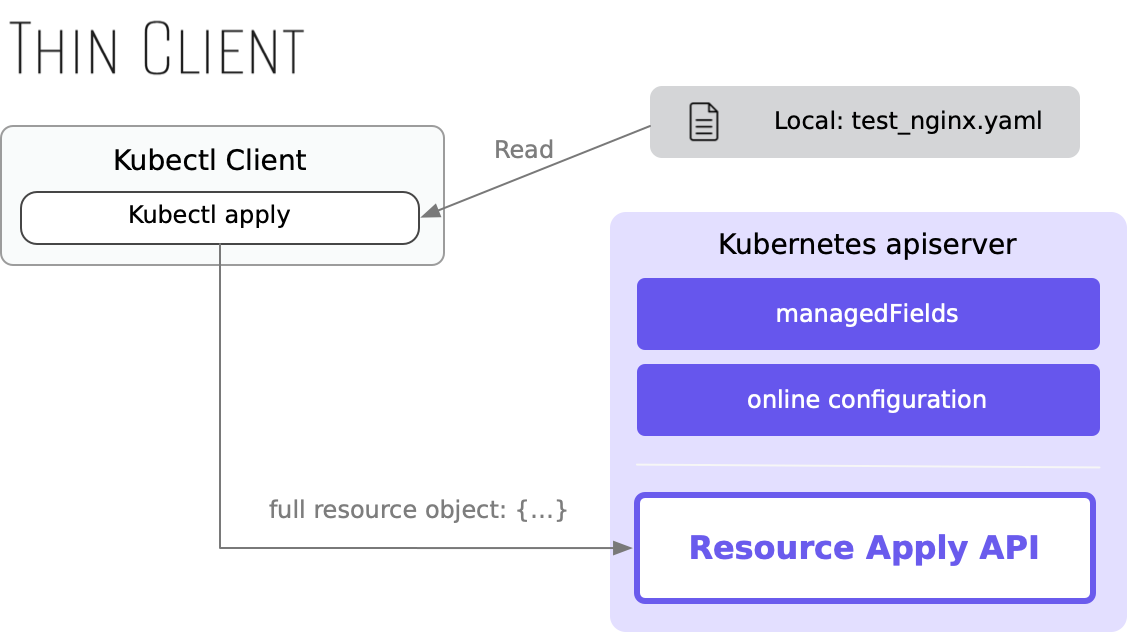
thin client and thick server: server-side apply
Firstly, kubectl becomes simpler as it no longer needs to perform complex "3-way merge" locally. Instead, it can simply send the local resource to the apply API. In addition, any third-party scripts and services can easily use the apply feature for resource modification, which is extremely convenient.
Secondly, server-side apply greatly enhances the ability to detect conflicts in scenarios where multiple parties are making modifications.
With client-side apply, Kubernetes saves the complete data of the last applied data using the system annotation kubectl.kubernetes.io/last-applied-configuration, generating "smart patches" that help avoid conflicts.
In contrast, server-side apply uses a more comprehensive conflict resolution model. It records the modifier of each field of the resource in the system field managedFields. Based on the data in managedFields, the server can quickly identify each scenario where data conflicts may occur, providing users with necessary information to prevent unexpected data overwrites.
For example, with server-side apply, when executing the last apply command in the previous section, the server would immediately notify the user of a data conflict error:
❯ kubectl apply --server-side -f test_nginx.yaml error: Apply failed with 1 conflict: conflict with "kubectl-edit" using apps/v1: .spec.replicas Please review the fields above--they currently have other managers. Here # ...At this time, the user can either force-write the data or relinquish control of the conflicting field by deleting it. In any case, server-side apply gives users the opportunity to handle conflicts easily.
Summary
By shifting logic from the client to the server, Kubernetes's apply functionality gains better conflict-handling capabilities and becomes more user-friendly. In this new design, the CLI kubectl becomes thiner while the server-side apiserver becomes thicker.
If you want to learn more about kubectl apply, you can read the following documents:
Software Design Suggestions
Whether a client is thick or thin depends on the responsibilities it undertakes; neither is inherently superior, only more suitable for different scenarios. Should you choose a thick or thin client? In most cases, the answer is clear because many functions naturally suit a particular implementation. For example, global search is typically a "thin client, thick server" solution because it relies on all the data in the server's database.
The challenging part arises when the answer isn't clear or is ambiguous. How do we choose the most appropriate strategy then? Here are some of my suggestions:
1. Take advantage of the server's ability to offer zero-cost reuse and real-time updates.
Looking at the evolution of kubectl apply, we observe that "server-side apply" offers an advantage over "client-side apply" by easily supporting various clients. Server-side apply is accessible not only through the kubectl tool but also via a simple curl command, as it requires no local processing, just the initiation of a standard HTTP request.
Therefore, when deciding between a "thin client" and a "thick client," ask yourself: Is this feature likely (or needs) to be used by multiple different clients? If the answer is yes, a "thin client" may be the better choice.
In addition to zero-cost reuse, another advantage of implementing functions on the server side is that changes can reach users in real-time.
In many scenarios, such as mobile app development, releasing a new client version requires multiple levels of review, which prevents real-time updates to users. In such cases, a "thin client, thick server" design offers significant advantages. Need to change functionality? Just update the server code or configuration.
2. Don't Overload the Server with Client Customization Needs
As Confucius said in The Analects: "Excess is as bad as deficiency." In some cases, if we focus too much on creating a "thin client" by placing all complexity on the server, it can lead to unnecessary bloating and poor design.
Now, let's change the topic and use a barbecue restaurant as an example instead of software.
Barbecue Restaurant Story: How to Season?
A new barbecue restaurant has opened on Design Second Road in Software City, featuring a wide variety of barbecue flavors.
To cater to different customer tastes, the restaurant offers flavors like sweet and spicy, salty and sweet, sour and spicy, and more. Following the "customer first" principle, the restaurant adopted a kitchen seasoning strategy: Customers indicate their desired flavor when ordering, and the kitchen seasons the meat accordingly. Initially, this approach was very popular.
A month later, as the business grew and attracted customers from everywhere, the kitchen realized they needed to prepare dozens of different flavors daily, which was overwhelming.
To solve this problem, the owner, Raymond, thought of a clever solution: let customers season the meat themselves. Various condiments, such as chili, ketchup, pepper salt, and soy sauce were placed on each table. The kitchen only handled the basic preparation of the meat (seasoning with a bit of salt). Customers could then add whatever flavors they liked.
After switching to this model, the pressure on the kitchen was relieved, and the restaurant's operational efficiency improved significantly.
Identifying the Overload Risk of Server-Side Complexity
In a client/server architecture, similar to "seasoning meat," some functions are naturally closer to users and clients, specifically customized demands for different users and clients.
If the server consistently treats all users and clients equally by striving to meet their customization needs, it may become overloaded due to excessive complexity, despite being beneficial for the clients, which can make future maintenance challenging.
Therefore, during software development, developers should recognize this risk. Ideally, if a function is inherently associated with the client and different clients have unique customization needs, the server should provide only basic functionality and allow the client to handle more of the customization logic. This avoids overstepping its role.
3. The client's computing power is a unique quality resource.
In terms of available computing resources, the server and client are fundamentally different:
- Server: Possesses strong and centralized computing power, but is generally more expensive per unit and is separated from users by the client;
- Client: Directly connects with users but has limited computing capacity; each user typically has a dedicated client—individually weak but numerous in quantity
How do these characteristics influence software design? Let’s explore this through the story of the barbecue restaurant.
Barbecue Restaurant Story: Who Will Barbecue?
In addition to offering a wide variety of flavors, the barbecue restaurant on Design Second Road has another ace up its sleeve: service staff cooks the barbecue for you. Once the meat is brought to the table, the servers handle all the necessary barbecuing tasks, including cutting, spreading, flipping, and oiling the meat, while customers don't have to lift a finger.
Like the "kitchen seasoning," this server-assisted barbecue model worked very well during the first month after opening. However, owner Raymond soon found it to be unsustainable. To ensure the efficiency of the "server-assisted barbecue" service, the restaurant needed to assign a full-time barbecuing server to each table. This led to soaring personnel costs, resulting in financial losses.
After several days of worry, Raymond came up with a seemingly brilliant idea: "Why not let each customer do it themselves?"
The next day, the barbecue restaurant switched to a self-service model. Every dining customer now had to cook their own barbecue, with no service staff to assist. Consequently, the restaurant no longer needed to hire a large number of servers and quickly turned profitable.
Leveraging the Client's Unique Resources
Using software design as an analogy, the changes at the barbecue restaurant represent a shift from a "thin client" to a "thick client":
- "Service staff cooks the barbecue" = "thin client": Barbecuing requires labor, mainly performed by the restaurant's staff (server-side resources);
- "Customer self-service barbecue" = "thick client": The labor required for barbecuing is no longer borne by the restaurant (server-side) but by each customer (client-side);
- As clients, customers inherently possess the ability to barbecue themselves. The "thick client" design effectively utilizes this ability, distributing the restaurant's (server-side) barbecue needs to the clients (customers).
In summary, unlike the server-side, the client-side has unique quality resources (computational and storage capacities) that naturally exhibit horizontal scalability as user numbers grow. If software can effectively leverage these resources and adopt a "thick client" design, it can often achieve unexpected success.
Drawbacks of "Self-Service Barbecue"
Returning to the barbecue restaurant, when "service staff cooks the barbecue" became "self-service barbecue," expenses decreased, but the overall dining experience changed dramatically.
If "service staff cooks the barbecue" provides a standardized service, always ensuring customers eat perfectly cooked food, the dining experience brought by "self-service barbecue" is actually anti-standardized and uneven. Some customers skilled at barbecuing may indeed enjoy delicious meat, but those less adept might end up having a night spoiled by burnt flavors.
This reveals an important fact: unlike the server-side, the client-side is inherently uneven and unreliable. Due to their varying resources, different clients may offer vastly different user experiences. In some fields, such as video games, the unreliability of the client side becomes a significant consideration in software design.
Conclusion
Beginning with the history of kubectl apply, this article briefly introduces the concept of "thick/thin clients" in software design. At the end, I've summarized some related suggestions for software design. I hope you find these useful.
Bonus Information
While server-side apply is excellent, it still hasn't become the default for kubectl apply. As of now, users must explicitly use the --server-side option to activate server-side apply.
The stable version of server-side apply was released in August 2021, making it four years old. The fact that changing a client's default behavior hasn't been achieved in this time highlights the immense challenges involved in maintaining a massive piece of software like Kubernetes.
Related discussion: kubectl: Use Server-Side-Apply by default · Issue #3805 · kubernetes/enhancements
Cover image: Photo by Isaac N.C. on Unsplash
![Carding, Sabotage and Survival: A Darknet Market Veteran's Story – Godman666 [video]](https://www.youtube.com/img/desktop/supported_browsers/chrome.png)

