.png)

In the past two series (Second Brain, PhiloAgents), we also provided the podcast version of the article to offer multiple ways to consume the content.
Help us with quick feedback to let us know if we should keep going with the format!
Thanks! Back to the article.
Architecting data pipelines for AI systems
AI builders bootcamp
The tech stack used to architect production-ready AI agents
AI engineers must understand this to build any successful system:
(Especially when working with RAG, LLMs, or agent-based apps)
How to architect data pipelines.
We all know data is the lifeblood of the systems we build.
You can have the most advanced algorithms, but without clean data, you're just spinning your wheels.
To understand how data pipelines for LLM apps should look, let’s architect one that powers our Second Brain AI Assistant.

Here are the core components:
Data sources can be many things - Notion, crawled links, custom APIs... you name it.
In this case, we'll use Notion’s API to collect personal data, extract all the links, and standardize everything into Markdown format.
Why Markdown?
Because the internet is full of it. Thus, LLMs are heavily trained using this format and know how to work with it.
To replicate steps down the line, we make a snapshot of the raw data into a data lake like S3.
This is where the magic happens. After collecting the data, we perform several transformations:
Download the Notion docs from S3
Load them in memory into Pydantic objects (content + metadata)
Crawl all the links inside the Notion docs (when building the AI assistant, we want to generate answers based on the content of the links as well → this is where the power of our lists of saved resources kicks in)
Compute a quality score per document using a combination of heuristics and LLMs (as LLM calls are expensive, you first want to squeeze the most out of it using heuristics)
Store all the documents and the quality score inside a document database (with this, we can compute statistics and filter documents down the line based on our needs)
For our setup, we’ve used MongoDB: a Swiss knife to store our unstructured documents and, later on, the embeddings for RAG.
We can think about it as part of our logical feature store.
To keep everything organized and maintainable, we use ZenML.
This helps us easily manage, version, and deploy our offline data pipelines.
Takeaway:
Architecting and managing these pipelines is crucial for creating LLM/RAG systems.
If you're an AI/ML engineer stepping into the GenAI world, get comfortable building and managing data pipelines that crawl unstructured data and process it for LLMs.
(Yes! Along with the 1000+ things you must know, AI Engineers must also dig into data engineering.)
Want to see how to do this?
Check out Lesson 2 from the Second Brain AI Assistant course ↓
Ever wanted to start building your next AI project idea, but felt overwhelmed because of an endless list of buzzwords and tools you thought you had to master, and had no clear way to piece them together?
In that case, you must pay attention to Shaw Talebi’s AI Builders Bootcamp, which starts on June 6th.
The bootcamp’s motto is: “From confusion to confidence, cut through the AI noise by building practical projects.”
Firstly, we recommend Shaw’s bootcamp because we personally know him as a passionate AI engineer, researcher, and entrepreneur. Most importantly, he is a fantastic teacher with 75k+ followers on YouTube and Medium, with incredible patience (vital for a teacher)!
A unique blend you can learn tons from.
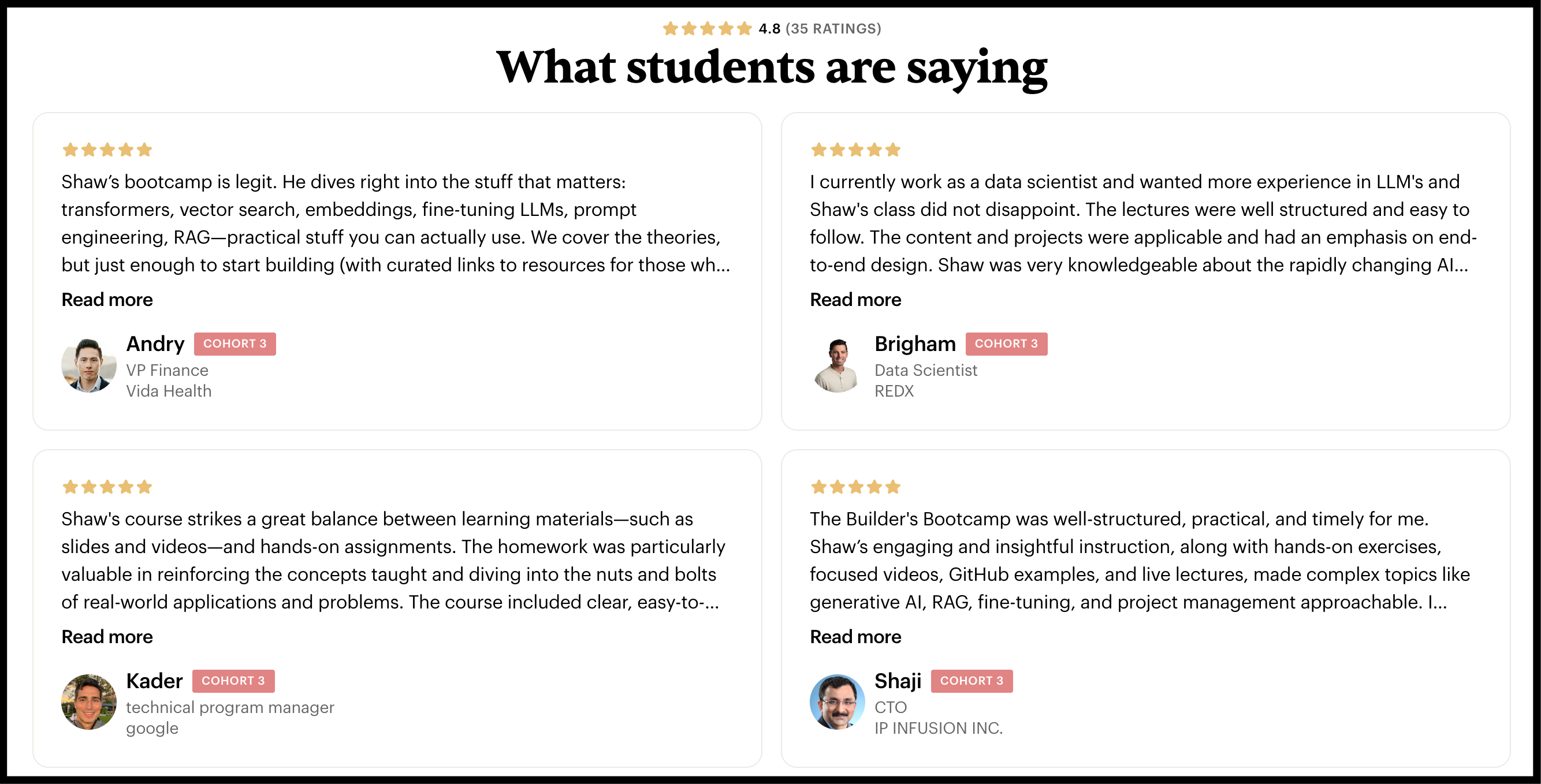
Secondly, we recommend his course because it is not based on tools but on long-lasting principles of learning and building. Here are the core outcomes of the course:
Overwhelmed → clear and confident
Scattered resources → real projects that make AI click
Boring tutorials → engaging, hands-on learning
“I can’t keep up” → “I know what matters”
I need AI skills → actually using them
If you consider enrolling, use code PAUL100 to support us and get $100 off.
(It’s also 100% eligible for company reimbursements)
There’s a lot of hype around AI agents.
But here’s the thing nobody tells you:
The hardest part isn’t building the agent...
It’s stitching together the right tools to make it work in a real system.
In our new PhiloAgents course (collab with
), we set out to build something fun but technically solid:
An interactive village of philosopher NPCs -each powered by real AI agents.
And under the hood?
A full-stack, real-time simulation, built with industry-grade components.

Let me break down the tech stack we used to power it:
1/ LangGraph
The brain of each philosopher agent.
We use it to:
Build the agentic layer
Manage state
Implement RAG pipelines that scale.
2/ Groq (Llama 3.3 70B)
One of the fastest inference APIs we’ve tested.
Helps us stream low-latency responses in real-time - perfect for interactive environments.
3/ MongoDB
Acts as both short-term and long-term memory.
It stores dialogue history, philosopher knowledge bases, and retrieval indexes for contextual grounding.
4/ FastAPI + WebSockets
The backend layer that handles real-time communication between our agents and the game UI.
Enables token-by-token streaming like ChatGPT.
5/ Phaser (JavaScript)
The frontend engine for our game world.
It’s what lets players explore, interact, and chat with thinkers from Plato to Turing - right in the browser.
6/ Opik (by Comet)
Handles prompt versioning, trace monitoring, and evaluation.
We track trace spans, monitor prompts, and benchmark agent performance with automated and human-aligned metrics.
Bonus:
We also built a crawler + chunking + deduplication pipeline.
The purpose is to gather philosophical knowledge from sources like Wikipedia + SEP, embed it, index it, and use it for hybrid RAG.
I usually tell people not to obsess over tools...
But in the agents world...
Choosing the right stack is a survival skill.
That’s why we open-sourced everything.
You’ll find the architecture, lessons, and full repo in the PhiloAgents course.
P.S. If you're building agentic apps and feel overwhelmed by the tool landscape, this stack might save you weeks of frustration.
Start with Lesson 1 ↓
Perks: Exclusive discounts on our recommended learning resources
(books, live courses, self-paced courses and learning platforms).
The LLM Engineer’s Handbook: Our bestseller book on teaching you an end-to-end framework for building production-ready LLM and RAG applications, from data collection to deployment (get up to 20% off using our discount code).
Free open-source courses: Master production AI with our end-to-end open-source courses, which reflect real-world AI projects and cover everything from system architecture to data collection, training and deployment.
If not otherwise stated, all images are created by the author.



