.png)

Sam Altman says he wants to “create a factory that can produce a gigawatt of new AI infrastructure every week.”
What would it take to make this vision happen? Is it even physically feasible in the first place? What would it mean for different energy sources, upstream CAPEX in everything from fabs to gas turbine factories, and for US vs China competition?
These are not simple questions to answer. We wrote this blog post to teach ourselves more about them. We were surprised by some of the things we learned.
With a single year of earnings in 2025, Nvidia could cover the last 3 years of TSMC’s ENTIRE CapEx.
TSMC has done a total of $150B of CapEx over the last 5 years. This has gone towards many things, including building the entire 5nm and 3nm nodes (launched in 2020 and 2022 respectively) and the advanced packaging that Nvidia now uses to make datacenter chips. With only 20% of TSMC capacity, Nvidia has generated $100B in earnings.
Suppose TSMC nodes depreciate over 5 years - this is enormously conservative (newly built leading edge fabs are profitable for more than 5 years). That would mean that in 2025, NVIDIA will turn around $6B in depreciated TSMC Capex value into $200B in revenue.
Further up the supply chain, a single year of NVIDIA’s revenue almost matched the past 25 years of total R&D and capex from the five largest semiconductor equipment companies combined, including ASML, Applied Materials, Tokyo Electron...
We think this situation is best described as a ‘fab capex’ overhang.
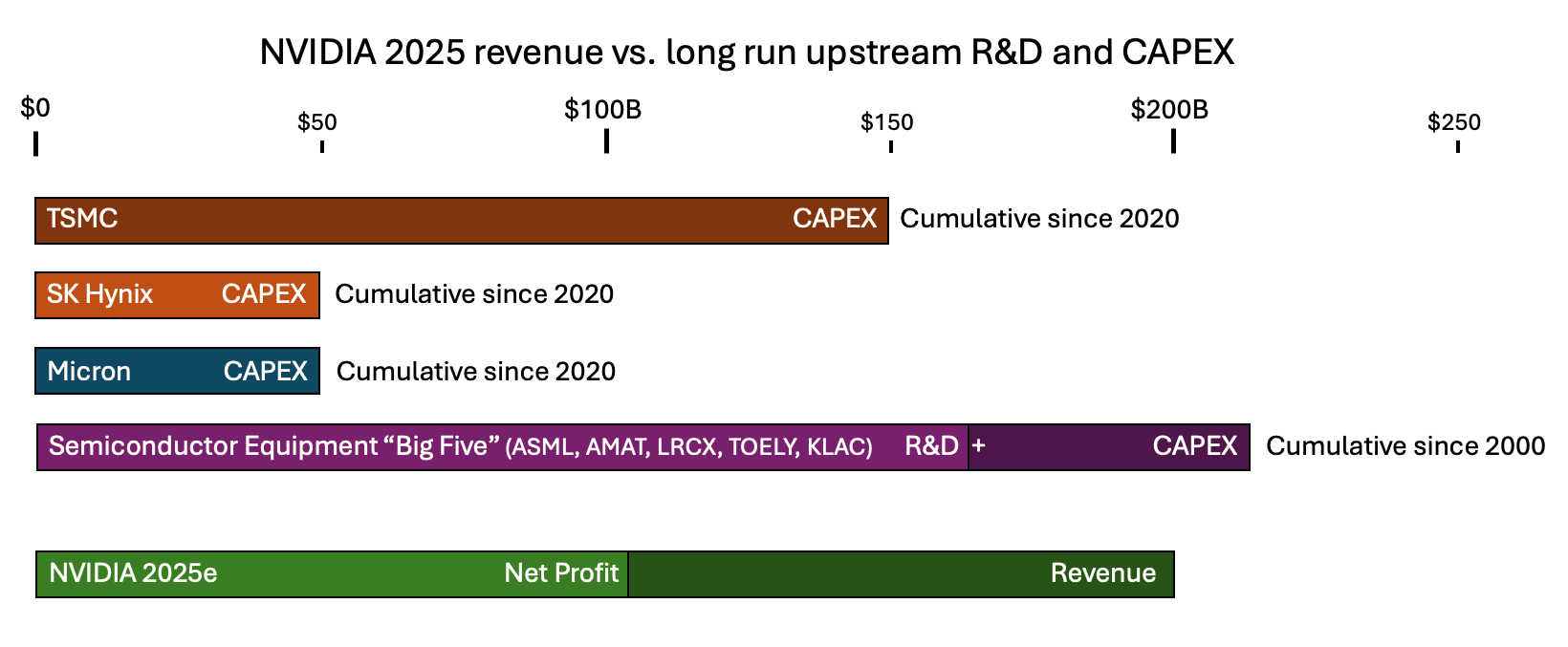
The reason we’re emphasizing this point is that if you were to naively speculate about what would be the first upstream component to constrain long term AI CapEx growth, you wouldn’t talk about copper wires or transformers - you’d start with the most complicated things that humans have ever made - which are the fabs that make semiconductors. We were stunned to learn that the cost to build these fabs pales in comparison to how much people are already willing to pay for AI hardware!
Nvidia could literally subsidize entire new fab nodes if they wanted to. We don’t think they will actually directly do this (or will they, wink wink, Intel deal) but this shows how much of a ‘fab capex’ overhang there is.
For the last two decades, datacenter construction basically co-opted the power infrastructure left over from US deindustrialization. One person we talked to in the industry said that until recently, every single data center had a story. Google’s first operated data center was across a former aluminum plant. The hyperscalers are used to repurposing the power equipment from old steel mills and automotive factories.
This is honestly a compelling ode to capitalism. As soon as one sector became more relevant, America was quickly and efficiently able to co-opt the previous one’s carcass. But now we are in a different regime. Not only are hyperscalers building new data centers at a much bigger scale than before, they are building them from scratch, and competing for the same inputs with each other - not least of which is skilled labor.
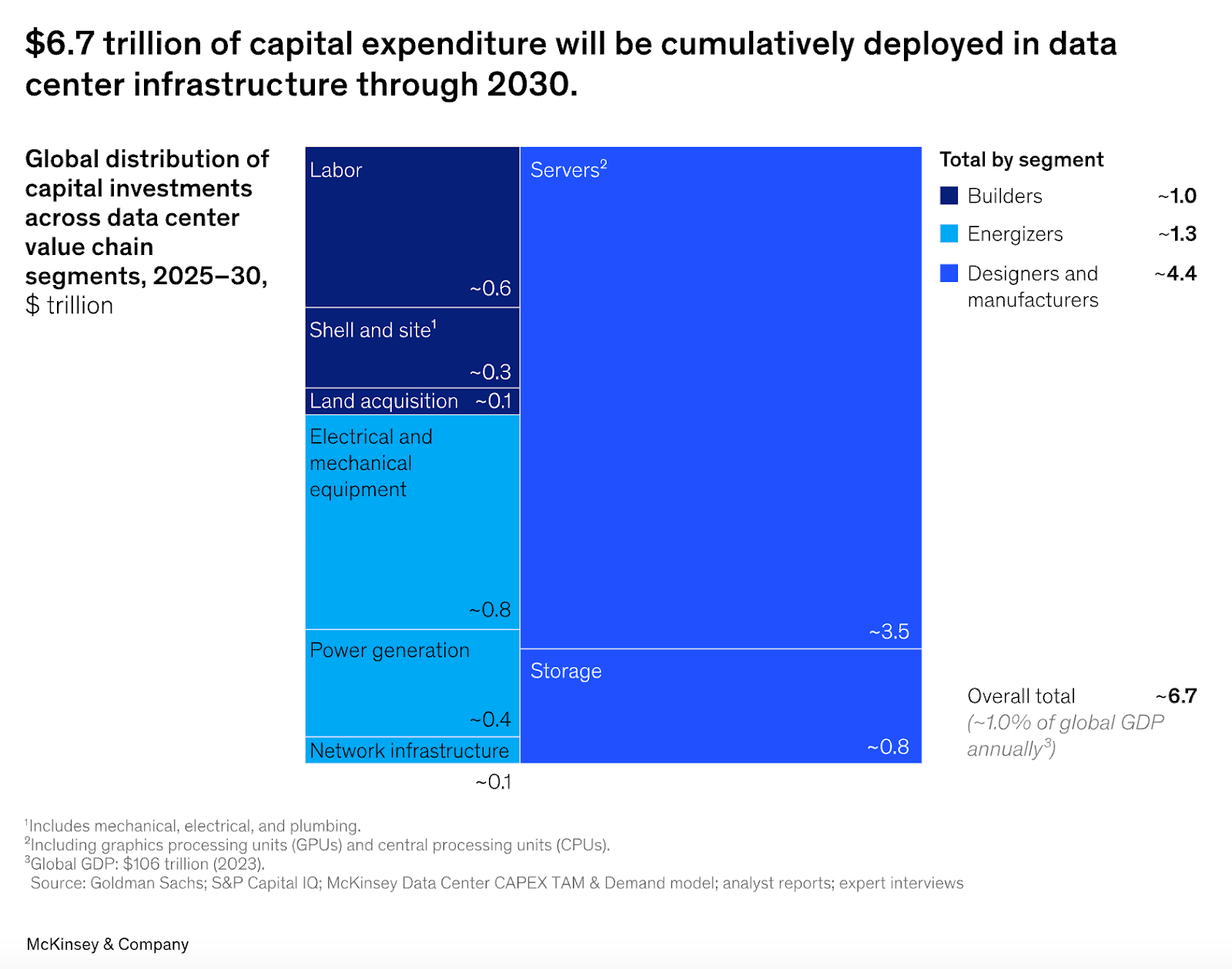
For you to deploy $2 trillion of AI CapEx a year, someone else needs to be producing $2 trillion worth of all the other datacenter components, not just the chips. The people upstream to the datacenters - the companies producing everything from copper wire to turbines to transformers and switchgear - would need to build more factories.
The problem is that those factories have to be amortized over a many decade lifespan. At usual margins, those factories are only worth building if this AI demand lasts for 10-30 years.
The companies building those factories are not AGI pilled - they’re decades old industrials running low margin businesses which have been burned by many previous swings in demand. In the early 2000s, electricity demand seemed set to explode, so gas turbine manufactures like GE, Siemens, and others massively expanded manufacturing capacity. Then demand collapsed, leaving them with huge (almost bankrupting) overcapacity.
If there’s a financial overhang not just for fabs, but also for other datacenter components, could hyperscalers simply pay higher margins to accelerate capacity expansion? Especially given that chips are currently 60-70% of datacenter CapEx, the hyperscalers might just tell the companies which are building the other 30% not to worry about long run demand: “We’ll make you whole with just a couple of years of outrageous margins.”
The largest gas turbine manufacturers (GE Vernova, Siemens Energy, and Mitsubishi Electric) are expecting to make $100B from gas turbines over the next 5 years. That corresponds to around 100GW of generation capacity. These companies are doing a combined CapEx of around $5B/yr across all their divisions.
If the hyperscalers were willing to pay $200B instead of $100B for this 100GW of generation (for example, to incentivize faster delivery), they’d effectively be covering 20 years of these turbine manufacturers’ entire CapEx (at current rates).
To build 100 GW of datacenters, the hyperscalers are going to have to invest many trillions of dollars anyways. Power generation is only about 7% of a datacenter’s cost. If natural gas ends up being the fastest way to scale generation, then doubling the cost of generation to 14% in order to make sure the power comes online fast enough might be easily worth it.
We think a similar dynamic is probably true for most of the components in a data center. Do not underrate the elasticity of supply.
Labor might actually end up being the most acute shortage - we can’t simply stamp out more workers (at least, not yet).
The 1.2 GW Stargate facility in Abilene has a workforce of over 5,000 people. Of course, there will be greater efficiencies as we scale this up, but naively that looks like 417,000 people to build 100 GW. And that’s on the low end of 2030 AI power consumption estimates. We’re gonna need stadiums full of electricians, heavy equipment operators, ironworkers, HVAC technicians,... you name it.
For reference, there’s 800K electricians and 8 million construction workers in the US. We hear that this labor pool is aging fast, but at least over the next few years, it seems like reallocation and big salary offers should be able to ameliorate the labor bottleneck.
Anthropic and OpenAI’s combined AI CapEx per year (being done indirectly, mostly by Amazon and Microsoft in 2025) seems to be around $100B.
Revenues for OpenAI and Anthropic have been 3xing a year for the past 2 years. Together, they are on track to earn $20B in 2025.
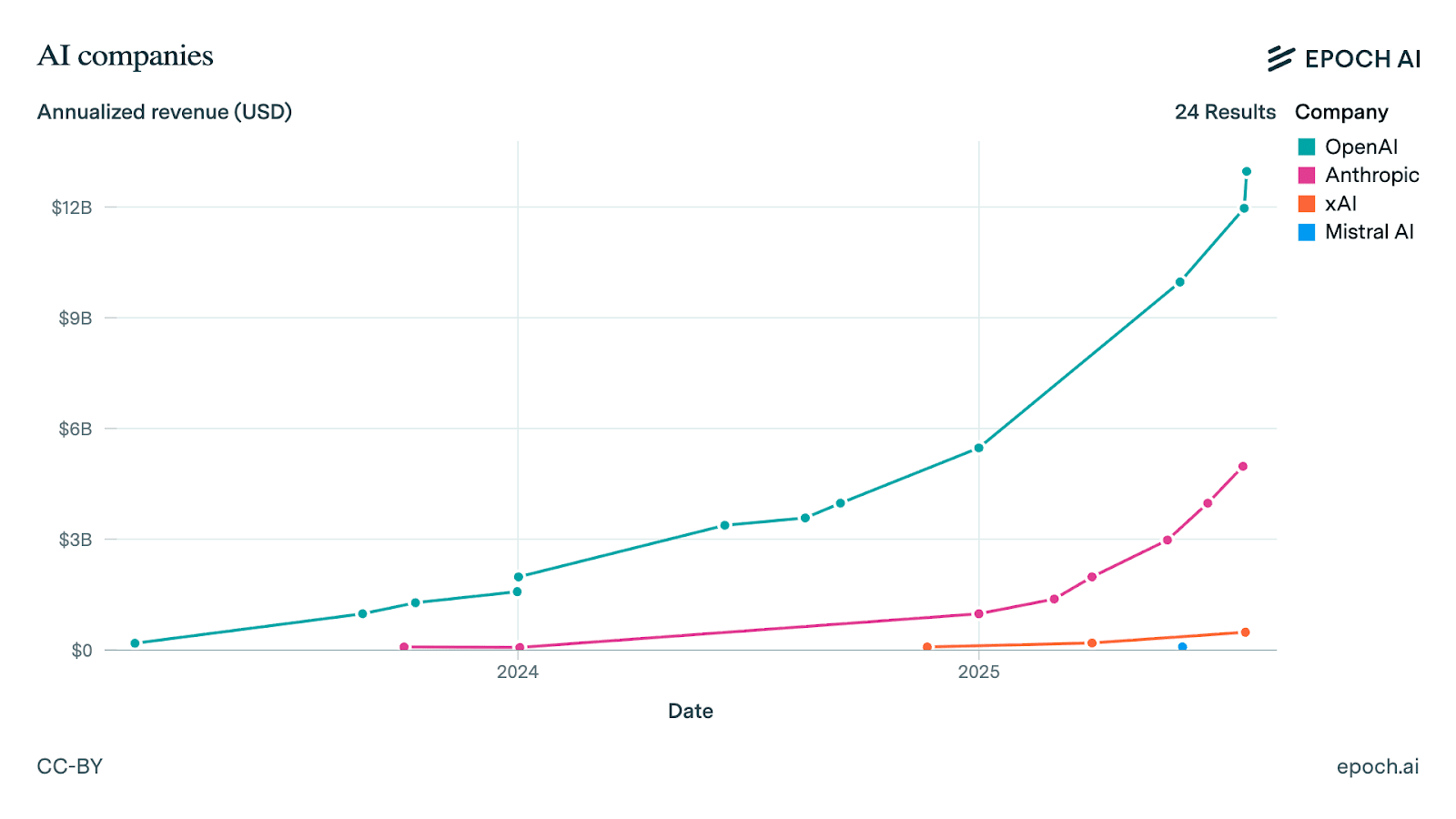
This means they’re spending 5 times as much on CapEx as they’re earning in revenue. This will probably change over time - more mature industries usually have CapEx less than sales. But AI is really fast growing, so it makes sense to keep investing more than you’re making right now.
Currently, America’s AI CapEx is $400B/year. For AI to not be a bubble in the short term, the datacenters currently being built right now need to generate $400B in revenue over the next three years. Why three years? Because that’s the time it takes for GPUs to depreciate, and GPUs are most of the CapEx for these data centers.How much money will AI make in a few years?
Google, Facebook, etc. have already shown us that if you can make a product which is modestly useful to billions of people, you can generate $100s of billions in revenue a year (Google+Meta make $400B/yr from ads alone).
OpenAI is approaching 1 billion, unmonetized free users, and we think a $12B to $100B revenue scale up is plausible just from their current products (e.g., see this vision: GPT-5 Set the Stage for Ad Monetization and the SuperApp). The question lies more in whether they can make a GPT-6 (or other products) in 3-5 years time that looks promising and economically useful enough to bring them into the $400B+ revenue range.
Of course, questions of revenue ultimately come down to your timelines. If AI truly lives up to its promise, then it’s in the reference class (at the very least) of white-collar wages, which are $10s of trillions of dollars a year.
Do you think that AI models will be able to do much of what a software engineer does by the end of a decade? If the 27M Software engineers worldwide are all on super charged $1000/month AI agent plans that double their productivity (for 10-20% of their salary), that would be $324B revenue already.
It takes about two years to build a new GW+ datacenter—and that’s before factoring in time to debug new chip generations. This means if you want to deploy 2 trillion in capex in 2030, you need to plan that out in 2028. At current trends in perf/watt and perf/$, $2T corresponds to roughly 66 GW of AI datacenter capacity.
For the last few years, hyperscalers and labs have consistently wanted more compute than they had previously made plans to develop. If the hyperscalers are planning for a 30% CAGR over the next 5 years and instead end up wanting to average 40% (hitting $2T capex in 2030) that’s a 20GW gap they’ll have to close in 2030 relative to the long term plans.
Elon (who didn’t even have an AI company during the time in which a traditional hyperscaler would have had to precommit to building capacity) solved his constraints by doing insane things. It’s unclear whether mere mortals can assemble 60 GW of greenfield capacity when they’d only planned for 30 or 40 GW.
If AI demand continues outpacing advance planning, there will be enormous pressure to compress datacenter construction timelines. The question is: what does this mean for energy sources and datacenter design? Some energy sources have much longer lead times than others, and some datacenter designs are more amenable to rapid deployment.
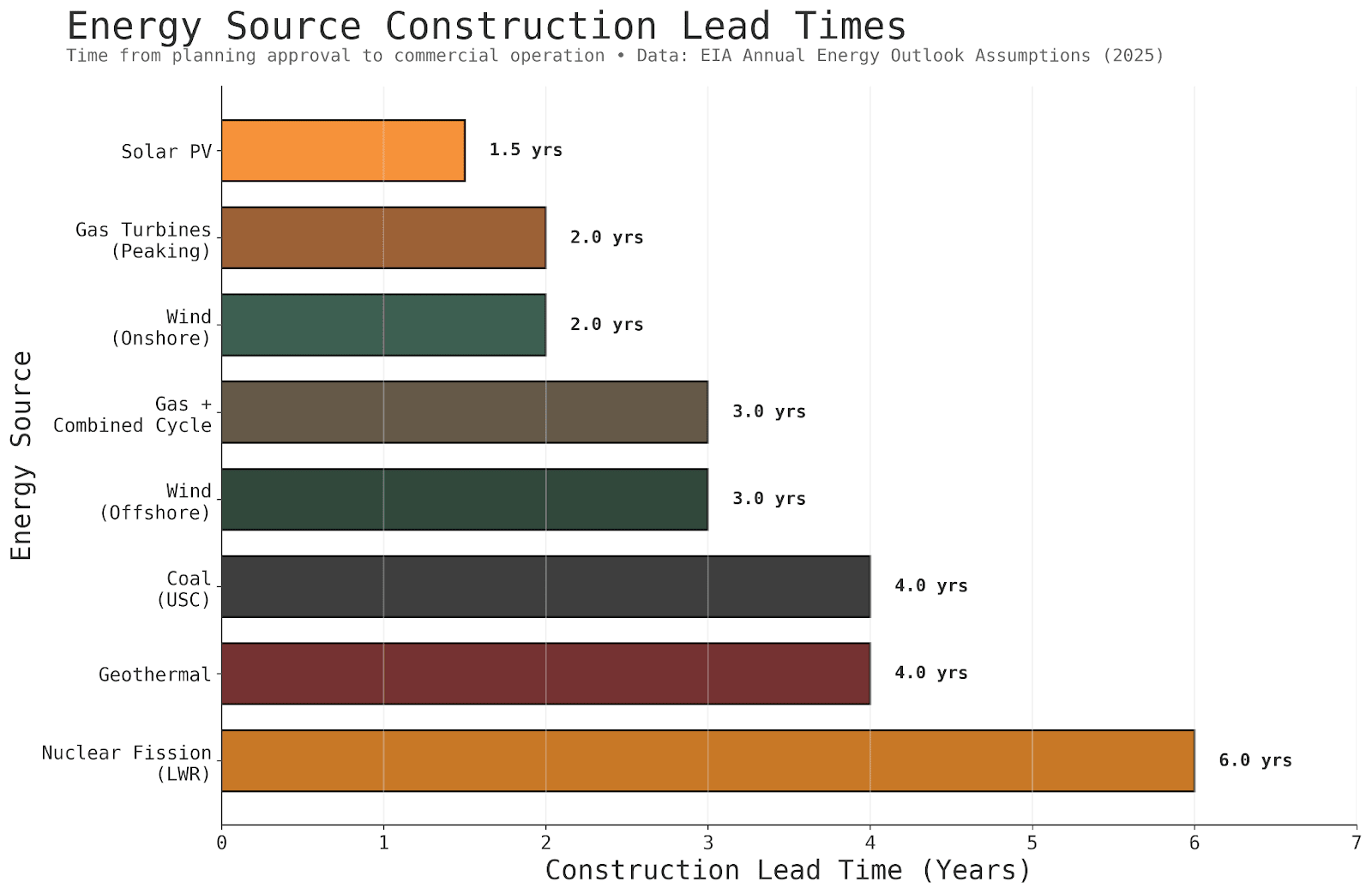
Chips overwhelm everything else in the total cost of ownership of a datacenter. This is because 1. Chips are really expensive, and 2. The data center shell can be depreciated over 12-20 years, whereas the chips are fully depreciated (and have to be replaced) every 3 years.
So in terms of choosing an energy source, you can see very clearly what the order of priority should be.
Lead times - Every month that the shell is not set up is a month that the chips (which are the overwhelming majority of your cost) aren’t being used.
Non chip CapEx - Much more expensive than electricity OpEx over a 3 year period.
Electricity OpEx
So you can see why natural gas, for example, is much preferred over current nuclear reactors. Nuclear has extremely low op-ex, but has extremely long lead times and high CapEx. Natural gas may not be renewable, but you can just set up a couple dozen gas turbines next to the datacenter, and get your chips whirring fast.
Solar panels themselves are very cheap, but can be expensive to levelize across night + seasons. If you’re going pure solar, you have to build a bunch of overcapacity (4-7 GW solar capacity for 1 GW data center due to typical 15-25% capacity factor) and add a ton of batteries. Otherwise, you’re risking your expensive chips sitting idle during winter or at night.
Solar farms also have a massive land footprint, and require massive labor for installation – good luck hiring 30,000 people to lay out 20,000 acres of solar panels and batteries across the desert in order to power a single 1 GW datacenter. The largest solar park in the world is currently the Gonghe Talatan Solar Park. It generates enough electricity for around 3 GW of smoothed continuous power - but this requires 15 GW peak capacity - meaning 7.2 million solar panels - that’s the area of seven Manhattans.
Aside from lead times and costs, you could ask the question: which energy source is physically plentiful enough to supply this demand? The answer, it turns out, is literally all of them. The theoretical limits of any of the energy sources mentioned are orders of magnitude higher than what is needed for even the most explosive end of decade AI scenarios.
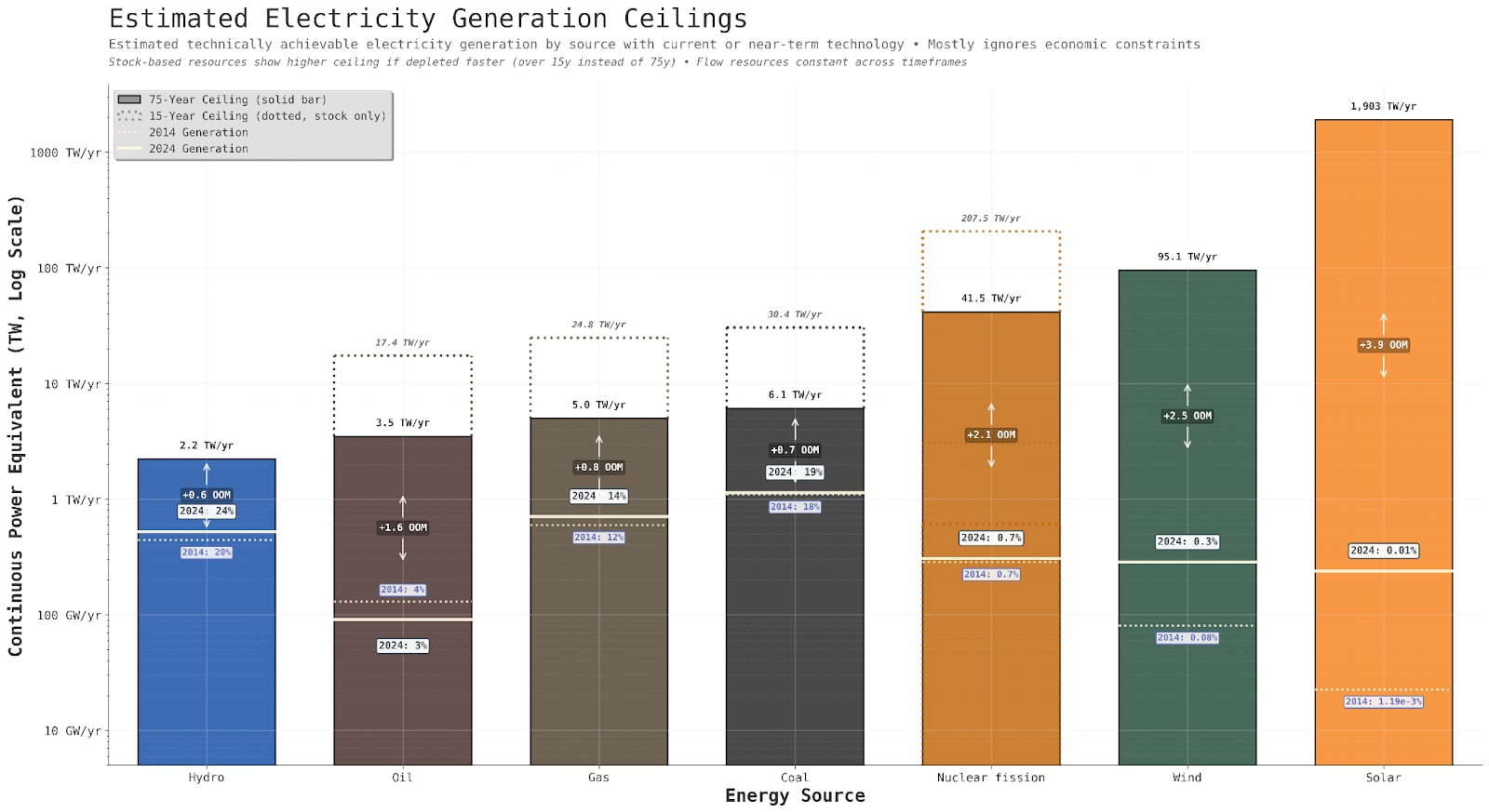
A key question is whether datacenters will go “off-grid”—generating power on-site rather than connecting to the utility grid. Some of the largest datacenters are already doing this, e.g., Meta’s Orion or XAI’s Colossus.
Why would datacenters want to make power themselves rather than relying on the grid? They’re trying to get around interconnection delays. Connecting large new electricity sources to the grid now takes over 5 years.
For 20+ years, US electricity consumption has been either flat or growing slowly. Grid operators are now expecting huge increases in demand from AI datacenters, manufacturing reshoring, and electrification all happening simultaneously.
One potential workaround: a Duke study found that if datacenters agreed to curtail load just 0.25% of the time (roughly 22 hours per year), 76 GW of spare transmission capacity could be made available. Most transmission lines run well below capacity on average—the bottleneck only hits during peak demand.
But even if hyperscalers are able to perfectly capture this 76 GW, that only gets you from 2026-2028 in bullish AI scenarios. After that, either the grid expands or datacenters go off-grid.
What will the distribution of individual datacenter sizes be? Here’s the argument for why we might end up seeing what looks like a thick sprinkle of 100 MW datacenters everywhere:
If you can plop down a medium sized datacenter here and there, you can soak up any excess capacity in the grid. You can do this kind of arb with a 100 MW datacenter, but there’s no local excess capacity in the grid at the scale of 1 or 10 GW - that much power is on the scale of a whole grid itself!
For pretraining like learning, you want to have large contiguous blobs of compute. But already we’re moving to a regime of RL and midtraining, where learning involves a lot of inference. And the ultimate vision here is some kind of continual learning, where models are widely deployed through the economy and learning on the job/from experience. This seems compatible with medium sized datacenters housing 10s of thousands of instances of AIs working, generating revenue, and learning from deployment.
Here’s the other vision. 1-10 GW datacenters, and then inference on device. Basically nothing in between.
If we move to a world with vertically integrated industrial scale production of off-grid datacenters, maybe what you want to do is just buy a really big plot of land, build a big factory on site to stamp out as many individual compute halls and power/cooling/network blocks as possible. You can’t be bothered to build bespoke infrastructure for 100 MW here and there, when your company needs 50 GW total. A good analogy might be how a VC with billions to deploy won’t look at any deal smaller than deca millions.
Today’s datacenter construction resembles building a car in your driveway: the engine ships from Germany, transmission from Japan, harness from Detroit, and a mechanic spends months assembling it all on-site. Each datacenter is custom-built over 1-2 years, with networking, MEP systems, and racks assembled piece by piece.
You’re not getting to a gigawatt per week this way.
Could you have pre-fabricated compute halls? Fully wired racks, cooling systems, power equipment, batteries—assembled in factories and shipped as complete modules. Instead of 18 months of on-site construction, you’re sliding skids into place.
The design space is surprisingly flexible. Liquid cooling enables 500kW-1MW racks but requires totally different plumbing and construction. If solar dominates, maybe you go full DC-to-DC (panels generate DC, chips need DC) and skip all the AC conversion steps. Each design choice cascades into others—power source affects cooling approach affects rack density affects building design.
By the way, if AI turns out to be a bubble and we’re much further from AGI than Silicon Valley thinks, what lasting value gets built? You could tell a story about how the dot-com bubble paved the way for all the value the internet has generated. What’s the equivalent for this AI buildout?
The GPUs—70% of capex—are worthless after 3 years. The buildings and power infrastructure last decades but are overbuilt for non-AI workloads. Perhaps the enduring value is this new industrial capability: the ability to rapidly manufacture and deploy massive compute infrastructure on demand. Like how the dot-com bubble left us with fiber in the ground, maybe an AI bubble leaves us with an industrialized datacenter supply chain and an expanded electric grid.
Crypto actually did this for the current wave of AI. For example, Crusoe - which is helping OpenAI build out Stargate in Abilene - was founded to build Bitcoin mining datacenters on stranded natural gas.
Why doesn’t China just win by default? For every component other than chips which is required for this industrial scale ramp up (solar panels, HV transformers, switchgear, new grid capacity), China is the dominant global manufacturer. China produces 1 TW of solar PV a year, whereas the US produces 20 GW (and even for those, the cells and wafers themselves are manufactured in China, and only the final module is assembled in the US).
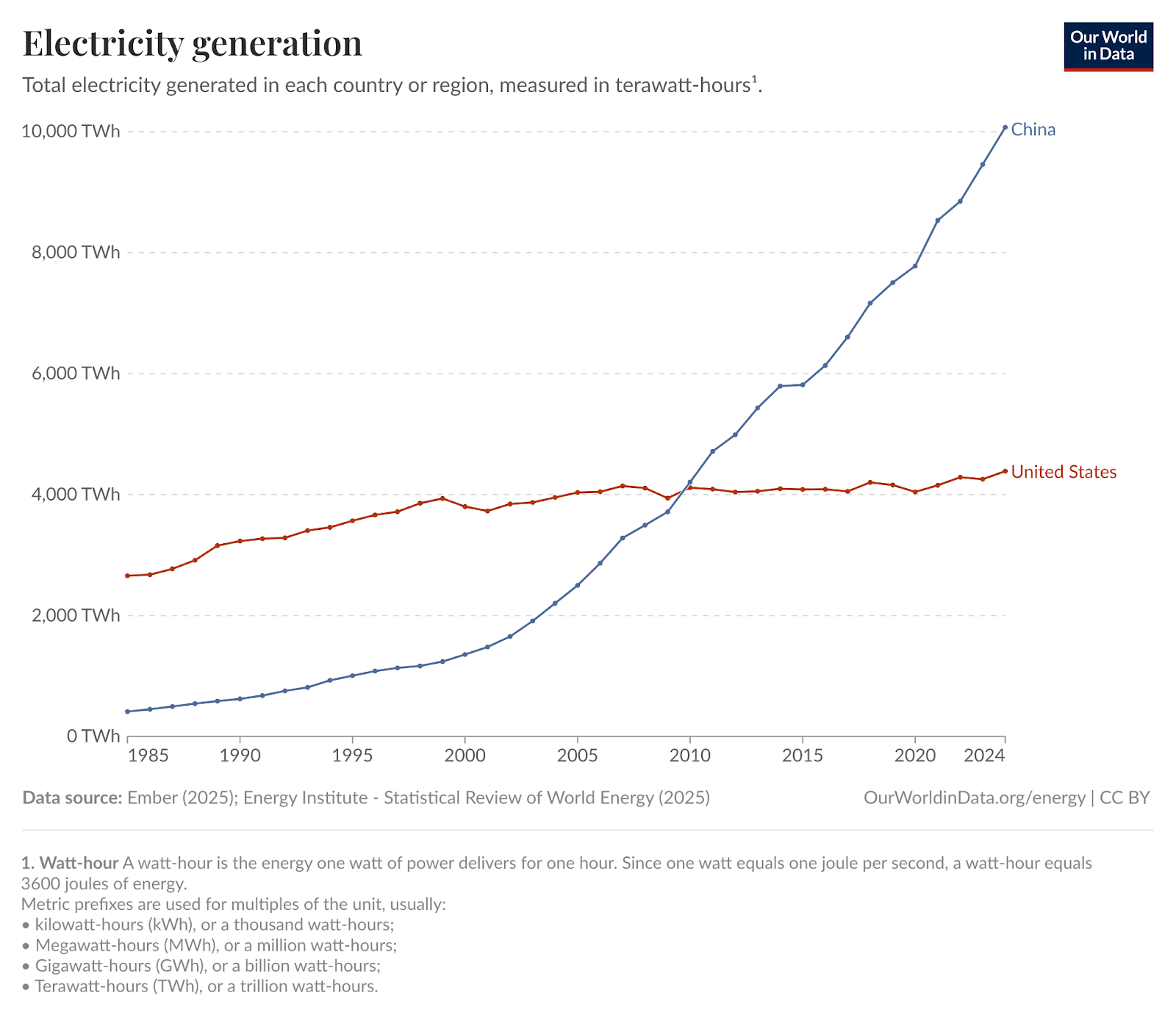
Not only does China generate more than twice the electricity than the US, but that generation has been growing more than 10 times faster than in the US. The reason this is significant is that the power build out can be directed to new datacenter sites. China State Grid could collaborate with Alibaba, Tencent, and Baidu to build capacity where it is most helpful to the AI buildout, and avoid the zero-sum race in the US between different hyperscalers to take over capacity that already exists.
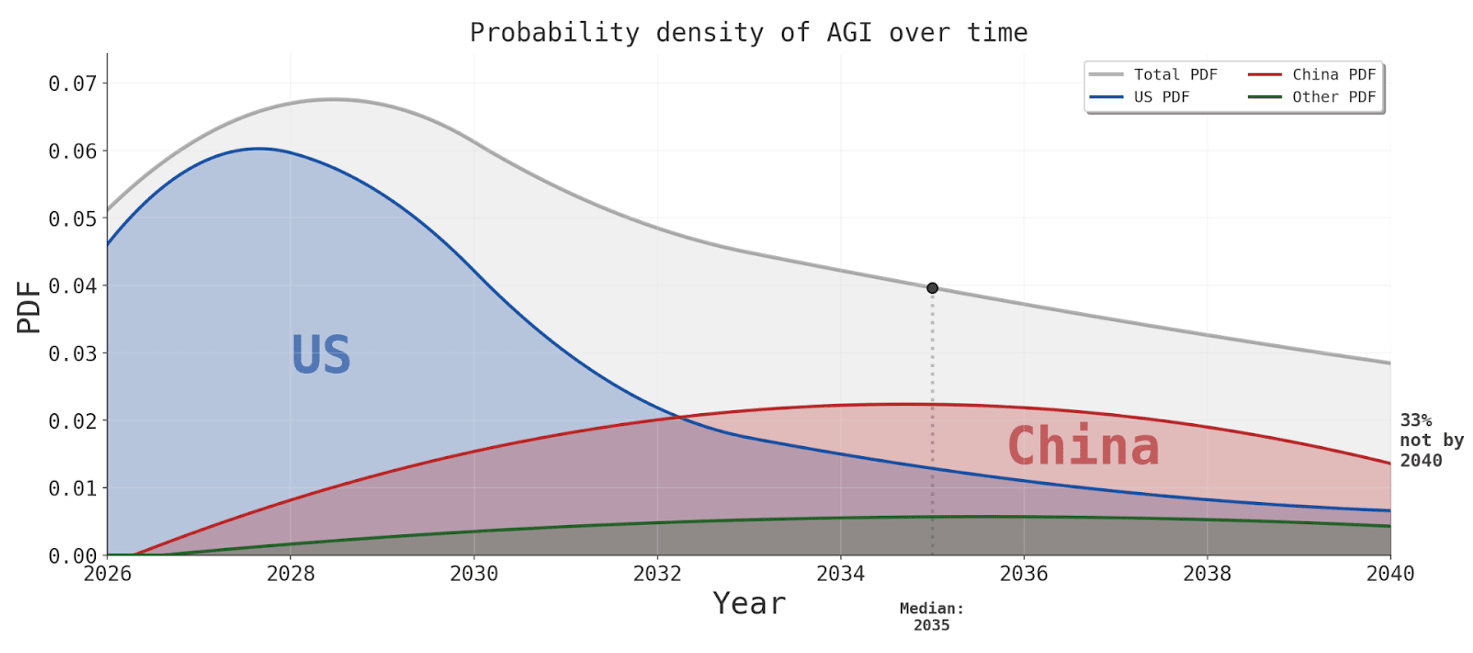
Is China privileged in the long timelines world? SMIC will probably *eventually* catch up to TSMC (and maybe SMEE or SiCarrier to ASML, CXMT and YMTC to SK Hynix and Micron, NAURA and AMEC to Applied Materials, LAM, Tokyo Electron and KLA) - export controls won’t preserve the lead forever. If there’s not a software only intelligence explosion before 2030, and AI just becomes a massive industrial race across the entire supply chain from robotics to solar panels and batteries to steel, then why doesn’t China end up leading? Isn’t China’s differential advantage precisely these kinds of rapid and massive infrastructure build-outs?
Semianalysis projects that China will actually be able to ship fewer chips next year than it did this year, mainly because of domestic HBM production constraints. But we wonder how much that matters in the long to medium term.
GPUs are fully depreciated over 3 years (because new designs and better underlying process nodes make previous generations irrelevant). And lead times on building new datacenters are only a year or two long - datacenter design as a whole might be redone to accommodate industrial scale vertical integration.
All this makes us wonder whether every 3 years, the AI race starts totally fresh. While we might be able to constrain China’s production up till 2028 (or maybe even into the end of the decade with the lithography chokepoint), what’s the story for why this matters 2030 onwards?
In order to get a handle on questions like these, we think it’s really helpful to just put numbers into a spreadsheet. Even if the scenarios are pulled out of your ass, they give you some sense of what would have to be true about the world in which they came to pass. For example, it’s interesting to ask: given trends in hardware price and performance, how much power would $2T CapEx correspond to in 2030? How about $500B?
We decided to chart two different potential trajectories:
Explosive growth, where AI investment grows smoothly and then starts to accelerate on the back of booming economic growth from AI automation (30% GDP growth in 2035).
AI winter, where Investment growth crashes around 2029 and then grows at a smooth 5% annual growth rate from 2032 onwards.
Here’s AI CapEx and AI power up to 2040 in both scenarios:
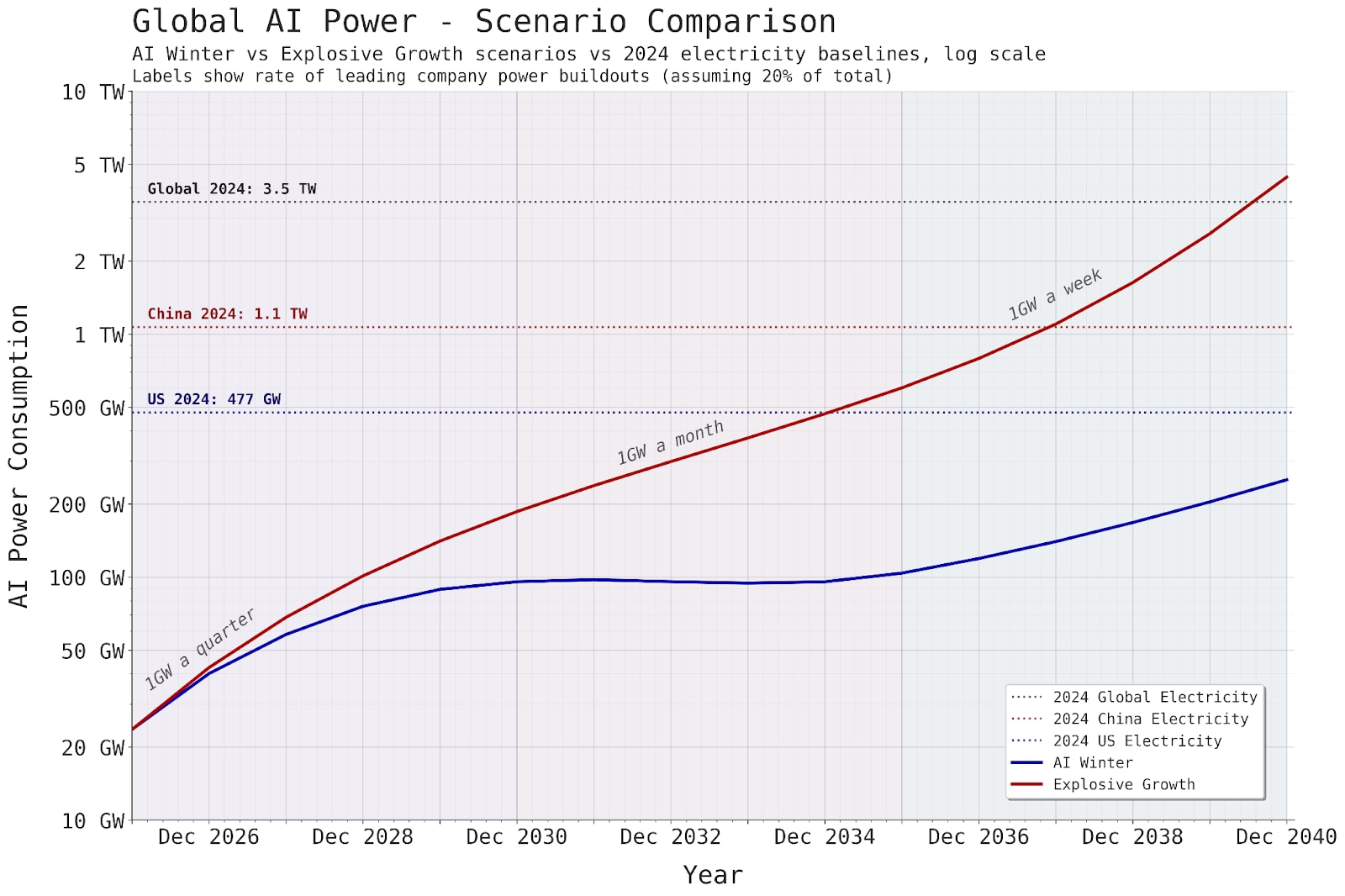
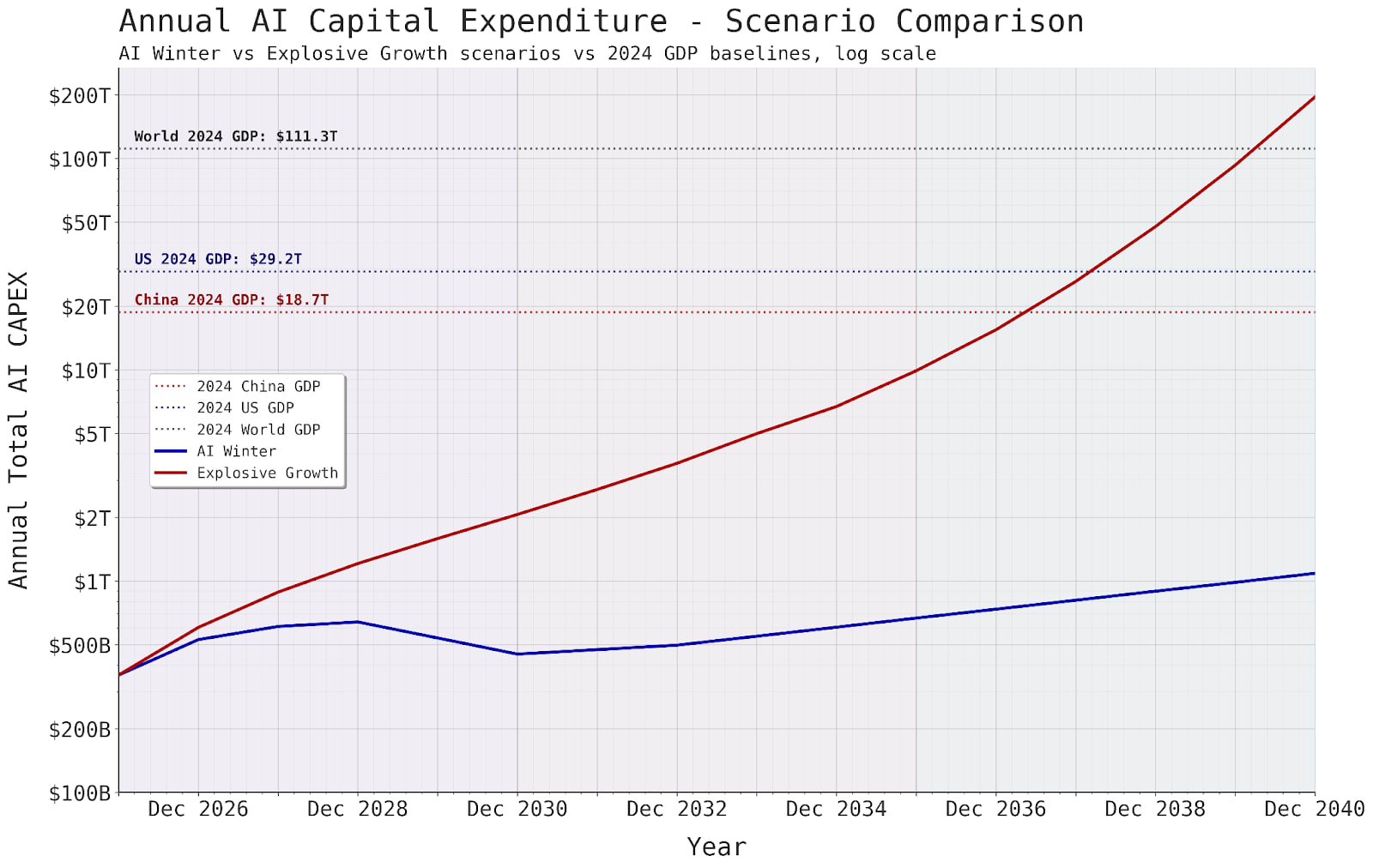
In the explosive growth scenario, Sam Altman’s vision of 1 GW a week for the leading company comes true in 2036. But in that world, global AI power draw would be twice US’s current electricity generation.
We had a lot of fun building and playing around the spreadsheet that led to these scenario projections. You might too.
Romeo and I decided to write this blog post because we had lots of questions about the AI buildout. We’re left with many more questions.
We don’t have any hard conclusions. What we’ve managed to do is assemble some considerations relevant to answering our questions.
There is no one person in the world who is the expert in all of the relevant fields. And even if there was such a person, they wouldn’t have a crystal ball. So we’ve spent a lot of time hoping on calls, reading PDFs, and talking to LLMs.
If you do have more information or thoughts, please reach out to us. We’re eager to learn more.
Romeo is a researcher at AI Futures Project working on writing AI scenarios and recently graduated from Harvard. For their first scenario he focused on compute forecasts – now he’s also thinking about broader economic impacts for a new scenario with longer timelines and a positive vision for governance. If you have expertise in economics and an interest in future AI scenarios, please reach out at [email protected].
Dwarkesh is a podcaster. He’s keen to interview someone really good on all these topics. Reach out at [email protected].



