.png)

A journey from simple curiosity to 977 tickets per second
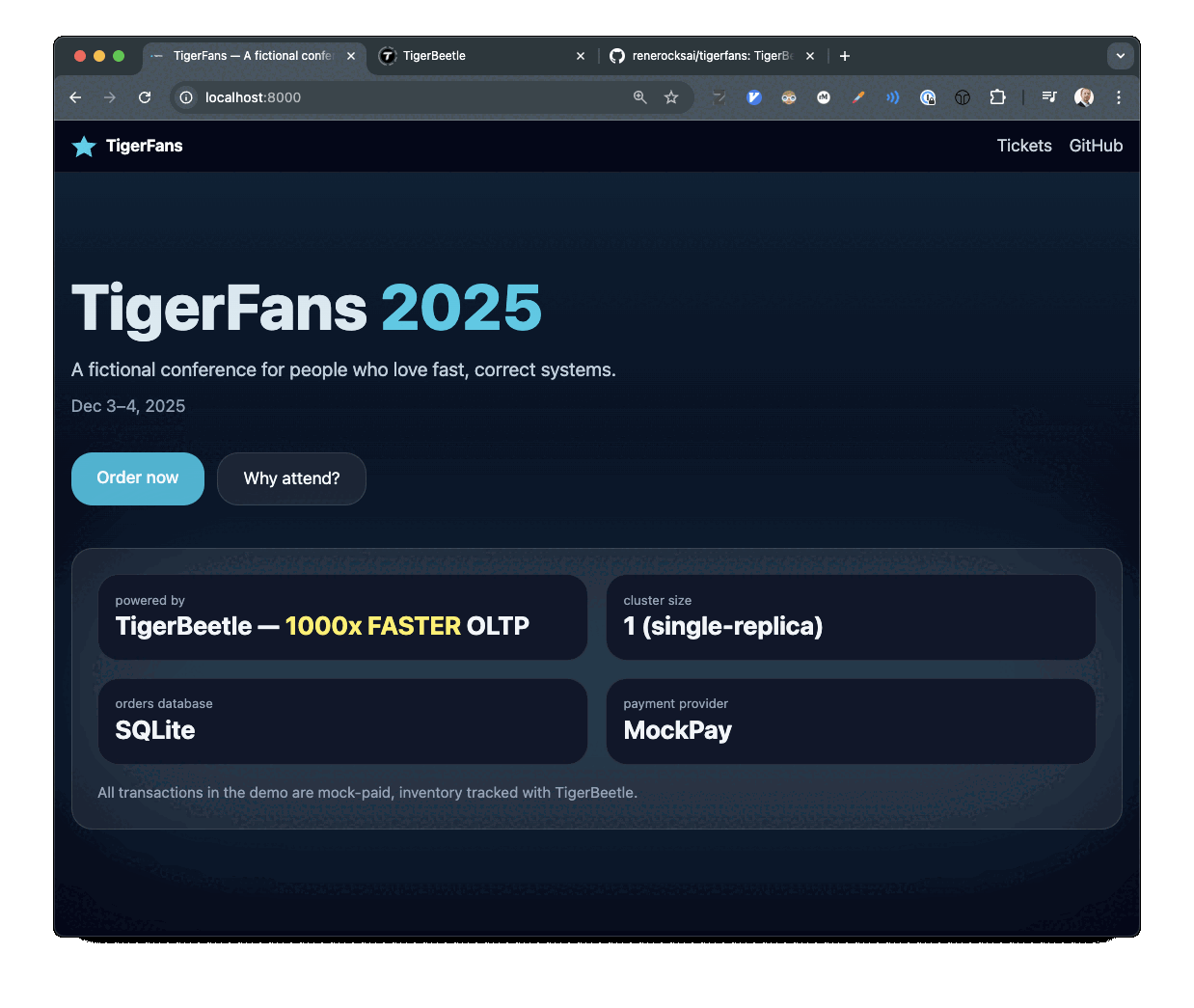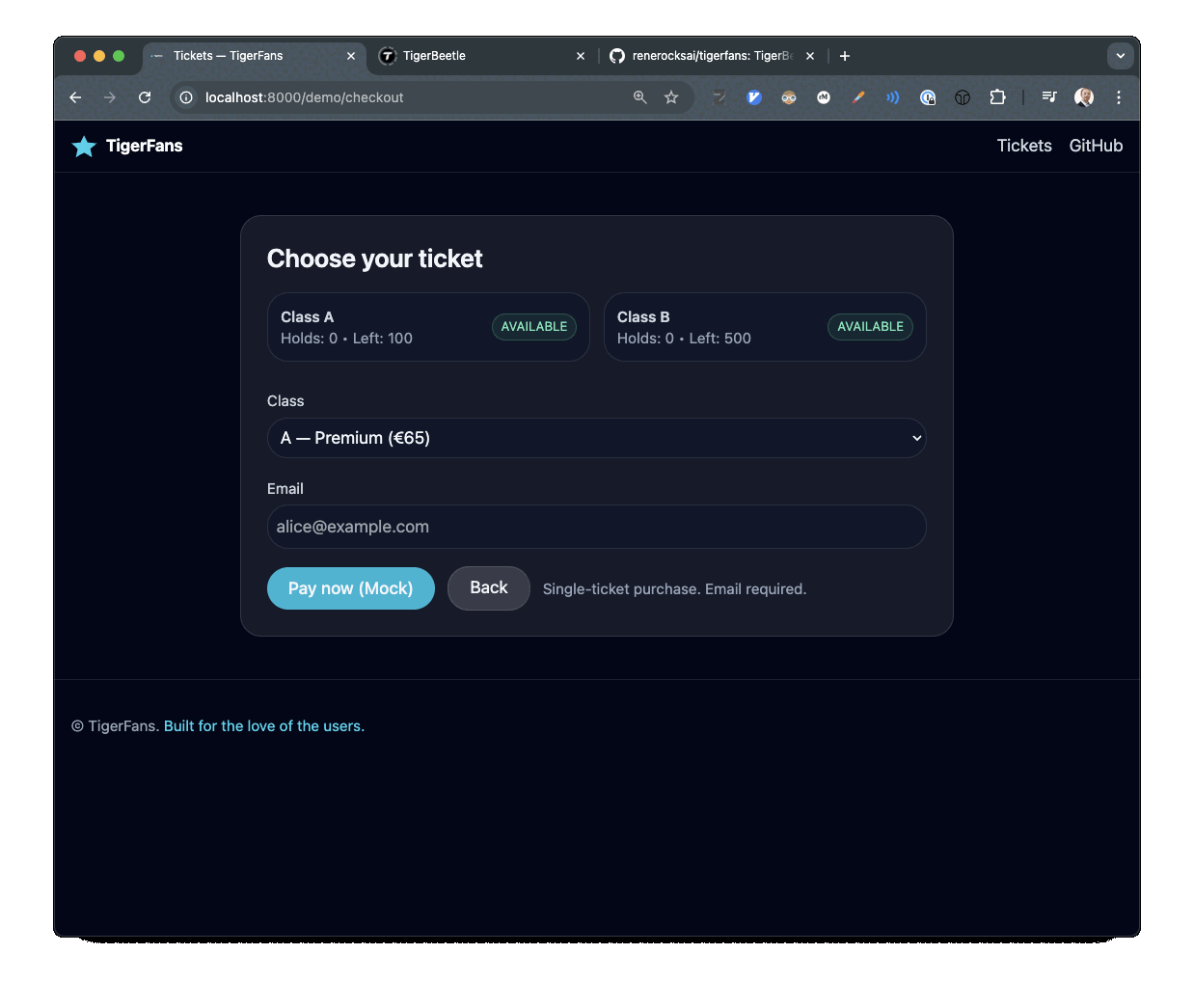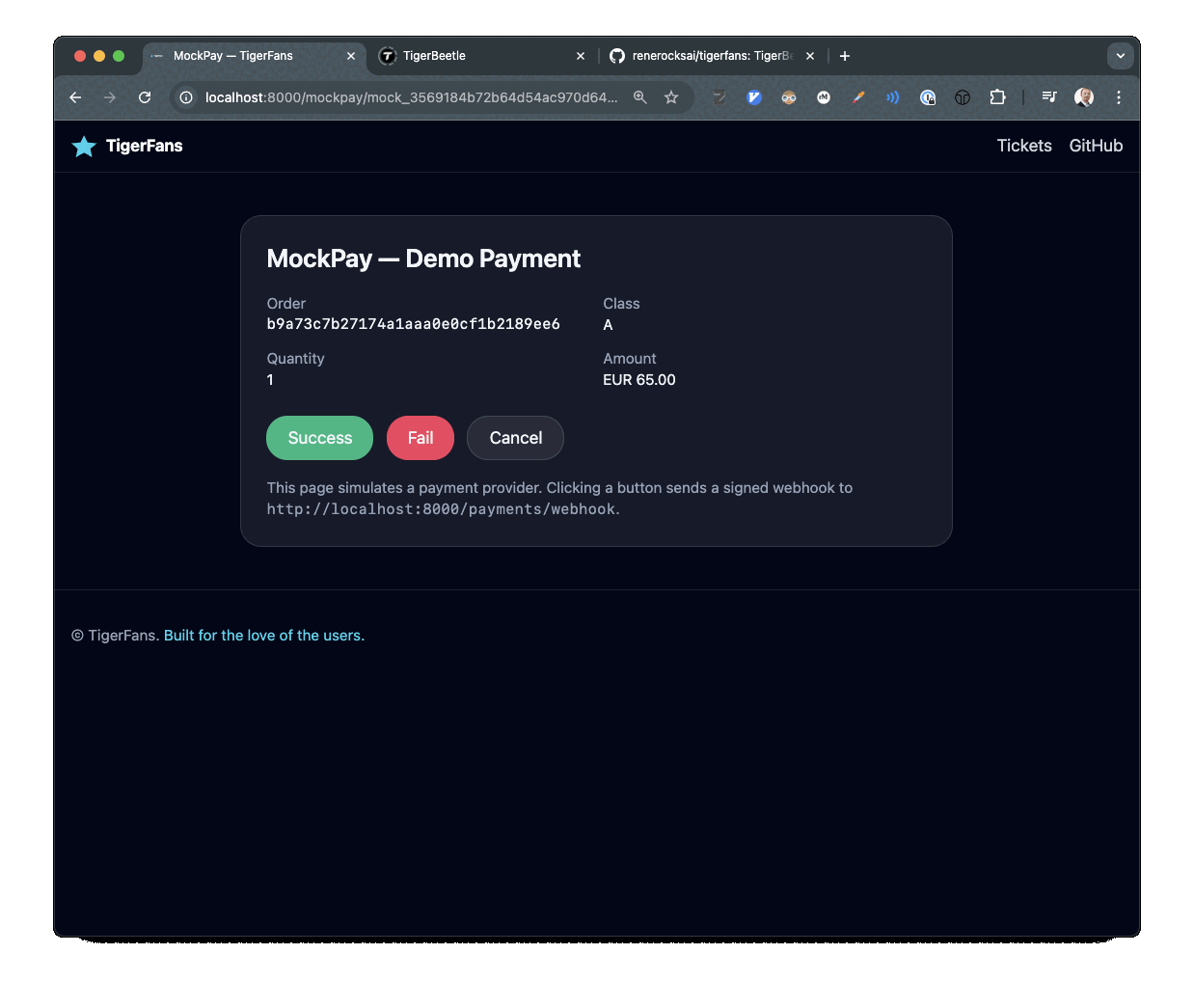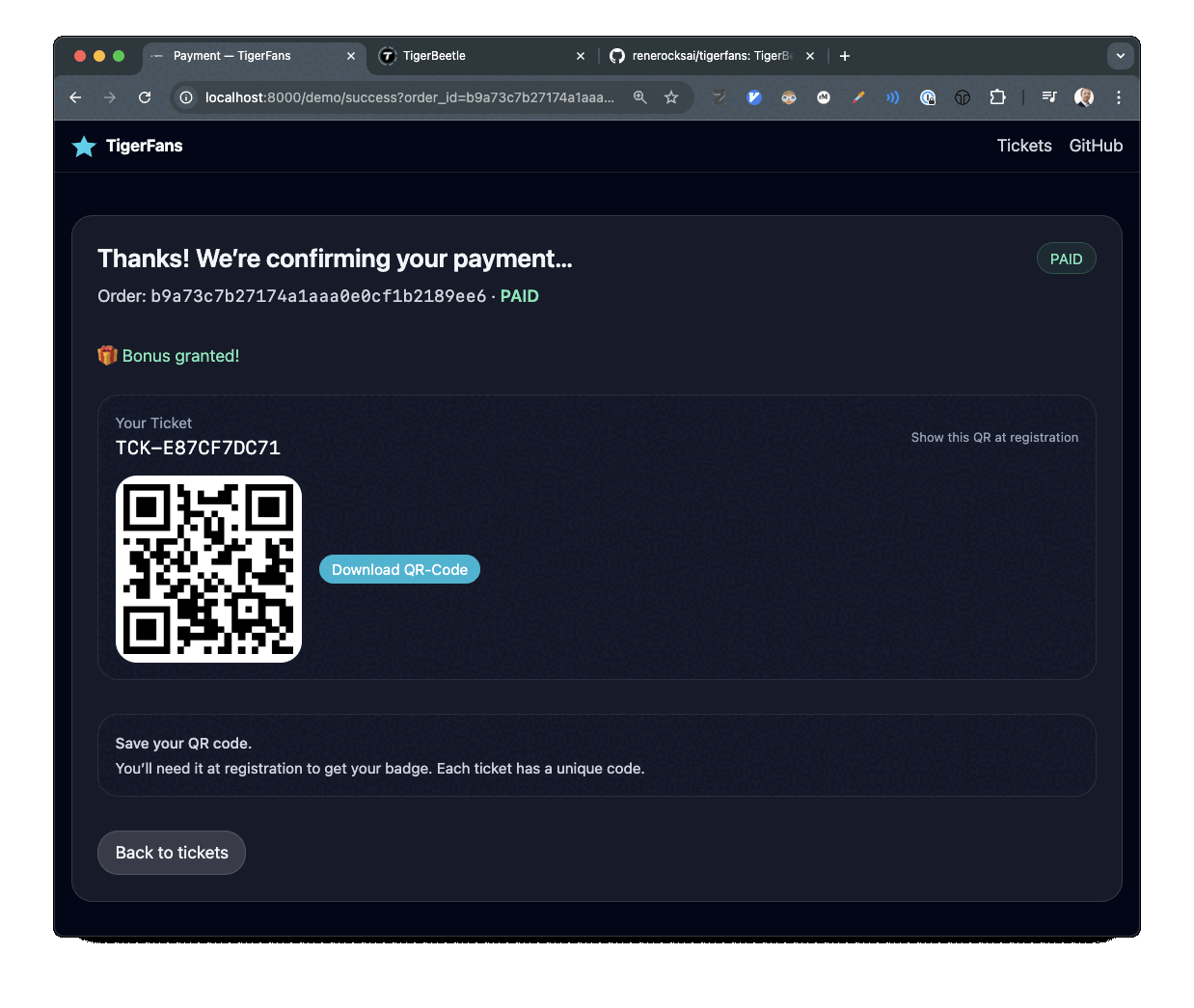 TigerFans demo showing ticket checkout and payment flow
TigerFans demo showing ticket checkout and payment flow
What Started Everything
That was Joran Dirk Greef’s response when someone on Twitter asked how you’d build a ticketing solution for an Oasis-scale concert—hundreds of thousands of people flooding your website at once, where you need to guarantee no ticket gets sold twice and everyone who pays gets a ticket. Joran is the CEO and founder of TigerBeetle.
He was right. Everyone who knows TigerBeetle would give the same advice. TigerBeetle is a financial transactions database designed for exactly this kind of problem: counting resources with absolute correctness under extreme load.
But I wanted to understand the concrete implementation. Not just conceptually—I needed to see the actual code.
How do you model ticket transactions as financial transactions? What does the account structure look like? How do the transfers flow through a realistic booking system with payment providers? What about pending reservations that timeout? What about idempotency when webhooks retry?
The best way to learn: build it myself.
So I built it. Three days later, I had a working demo. What started as an educational project became a 19-day optimization journey that pushed the system to 977 ticket reservations per second—15x faster than the Oasis baseline. All in Python.
Building It: The HOW
The goal was clear: build a working demo that answers the HOW question. Not a toy example—a realistic booking flow with all the messy complexities of real payment systems.
The first challenge: TigerBeetle isn’t a general-purpose database. It’s a financial transactions database. That means it forces you to think in double-entry accounting primitives—accounts, transfers, debits, and credits.
So the question became: how do you model tickets as financial transactions?
Think about how banks handle money. They use double-entry bookkeeping—a system that’s been used for hundreds of years because it provides built-in error detection and perfect audit trails. Every transaction affects at least two accounts: one is debited, another is credited. Debits always equal credits, so the system is always balanced and errors are immediately obvious.
TigerBeetle demanded we do the same with tickets.
For each resource—Class A tickets, Class B tickets, those limited-edition t-shirts—we set up three TigerBeetle accounts: an Operator account that holds all available inventory, a Budget account that represents what’s available to sell, and a Spent account for consumed inventory.
First, we initialize by funding the Budget account from the Operator account:
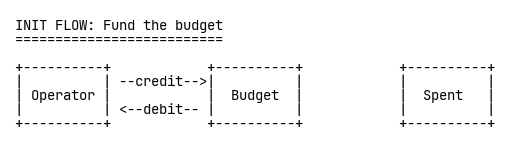
When someone starts checkout, we create a pending transfer from Budget to Spent with a five-minute timeout. The crucial part: TigerBeetle’s DEBITS_MUST_NOT_EXCEED_CREDITS constraint flag. This makes overselling architecturally impossible—not prevented through careful programming, but impossible by design. The database enforces correctness.
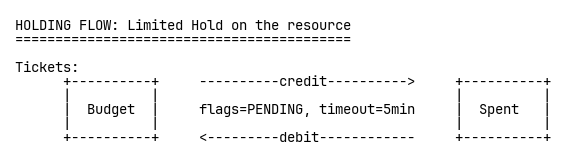
When payment succeeds, we post the pending transfer to make it permanent:
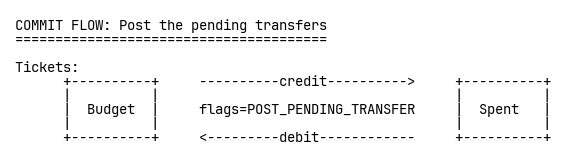
When payment fails or times out, we void the transfer. It just vanishes. No cleanup jobs, no race conditions, perfect audit trail.
The demo stack was deliberately simple. FastAPI—the Python async web framework—because it’s quick to build and easy to understand. SQLite because that’s one less process to manage. TigerBeetle in dev mode. And MockPay—a simulated payment provider that mimicked the real webhook flow you’d get from Stripe or similar.
I wrote the code, built the UI, documented the account model. Everything worked. The two-phase checkout flow with webhooks, the pending reservations that auto-expire, the whole thing.
You can try the live demo yourself at tigerfans.io — it’s still running, complete with the MockPay simulator.
Mission accomplished. I understood the HOW.
Reaching Out to TigerBeetle
Before sharing the demo with the world, I wanted to show it to Joran and the TigerBeetle team first. The email I sent was careful:
“Before sharing it with the world, (posting about it), I wanted to show it to you. I don’t want to spread ‘anti-patterns’.”
After all, I had made it all up. Maybe there is a better, more accounting-like, way of modeling tickets with TigerBeetle. I didn’t want my educational project become a bad example.
Joran was traveling, stuck dealing with flight delays somewhere, but he took the time to reply. The response was warm and encouraging. Rafael Batiati, one of TigerBeetle’s core developers, joined in with a note of caution: people would inevitably start benchmarking it once released. Oh. Right. Thinking about it, they probably would.
But then Joran turned it into a friendly challenge. He mentioned the Oasis ticket sale—approximately 1.4 million tickets over six hours, or roughly 65 tickets per second. Then came the kicker: “It would be pretty sweet if you could do better than six hours.”
That number—65 tickets per second—became my new baseline.
Performance Journey
What started as an educational demo shifted into something else entirely. The patterns were proven. The implementation was correct. But now a different question emerged: how many hidden inefficiencies could we eliminate?
Not the fundamental stuff—Python is Python, and there’s only so fast an interpreted language can go. But the bottlenecks we could actually fix. The architectural inefficiencies. How well could we really utilize TigerBeetle?
 Performance progression for ticket reservations from 115 to 977 ops/s
Performance progression for ticket reservations from 115 to 977 ops/s
Initial Infrastructure Upgrades
To prepare for performance testing, I needed to eliminate database bottlenecks. SQLite’s blocking I/O would serialize request handling in FastAPI’s event loop, while PostgreSQL’s async drivers would allow true concurrent processing. So I switched from SQLite to PostgreSQL.
This meant upgrading the infrastructure—from a tiny 2-vCPU spot instance to a proper c7g.xlarge EC2 machine with 4 vCPUs and 8GB of RAM. PostgreSQL runs as its own process, so I wanted one vCPU for the OS, one for the HTTP workers, one for the database—with room to experiment with multiple workers later.
I also optimized the SQL queries, tuned transaction handling, and threw in uvloop for a faster event loop to have a good baseline for performance tests.
The result: 115 tickets per second. Better than the Oasis baseline.
I sent the numbers to Joran with a bit of playful humor: “We already redefined TPS as tickets per second. Why not redefine big O notation as big Oasis notation? O(1) = 65 TPS. We’re currently at ~O(1.7).”
Joran’s response was encouraging as always, but also included a reality check: “I was surprised the TPS is so low. It should be at least approximately 10K.”
Ten thousand. We were at 115.
TigerBeetle is famous for its >1000X performance. It’s built for this. So why was the whole system so sluggish?
Understanding the Bottleneck
I sat down and drew out the complete sequence diagram. Every API request, every database roundtrip, every operation. The exercise was revealing:
Checkout flow:
- Browser → Server (ticket class, email)
- Server → TigerBeetle: Create PENDING transfers
- Server → PostgreSQL: INSERT Order + PaymentSession
- Server → Browser: Redirect to MockPay
Webhook flow (payment confirmation):
- MockPay → Server: Payment succeeded
- Server → PostgreSQL: Check idempotency
- Server → TigerBeetle: POST pending transfers
- Server → PostgreSQL: BEGIN TX, INSERT idempotency keys, UPDATE order, COMMIT TX
Every single API request was hitting PostgreSQL 2-4 times. PostgreSQL was in the critical path. Always.
To understand the bottleneck better, I split the measurements into two phases:
- Phase 1: Checkout/Reservations (create holds, save sessions)
- Phase 2: Payment Confirmations/Webhooks (commit/cancel, persist orders)
The results confirmed the problem:
- Phase 1 (Reservations): ~150 ops/s
- Phase 2 (Webhooks): ~130 ops/s
PostgreSQL was slow in BOTH phases. It was the bottleneck everywhere.
The Redis Experiment
After seeing PostgreSQL as the bottleneck in both phases, I started questioning our architecture. Do we even need a relational database when we don’t really do anything relational in it? We’re basically just storing orders and idempotency keys.
I implemented Redis as a complete DATABASE_URL replacement. The system now supported three swappable backends: SQLite, PostgreSQL, or Redis. It was the same interface, just different storage. I replaced ALL of PostgreSQL with Redis—not just sessions, but everything.
I ran the benchmarks with Redis in everysec fsync mode—balancing performance with some durability.
The results were impressive:
- Phase 1 (Reservations): 930 ops/s (6x improvement!)
- Phase 2 (Webhooks): 450 ops/s (3.4x improvement!)
The numbers were exciting. But there was a problem: Redis in everysec mode could lose up to 1 second of orders on crash. The faster Redis gets, the worse this becomes. I had replaced ALL of PostgreSQL with Redis, including the durable orders. That’s not acceptable, even for a demo.
I sent the impressive benchmark results (and the durability concern) to Rafael.
Rafael’s Hot/Cold Path Compromise
Rafael’s response brought the architectural insight that would transform the system. He appreciated the detailed benchmarks but cautioned against gambling with durability even for a demo. His insight: separate ephemeral session data from durable order records.
This was the hot/cold path insight—a compromise between my speed experiment and proper durability. Instead of replacing ALL of PostgreSQL with Redis (which sacrificed durability), use Redis ONLY for payment sessions (hot path), NOT for orders (cold path).
Payment sessions are ephemeral. They only matter for a few minutes while the user is paying. Once payment succeeds or fails, we don’t need the session anymore. Same with idempotency keys—temporary deduplication data that prevents double-charging when webhooks retry.
But orders? Those need to be durable forever. We need PostgreSQL for that.
The insight was brilliant: not all data needs immediate durability!
What a great idea!
Any crash or abandoned cart would eventually get reverted by TigerBeetle’s timeout mechanism. In a real application, if a webhook callback is not found in Redis or already expired in TigerBeetle, you’d reverse the payment with the payment gateway.
The architecture clicked into place:
- Hot path (reservations): TigerBeetle + Redis (in-memory, fast)
- Cold path (confirmed payments): TigerBeetle + PostgreSQL (durable, slower)
Correct Hot/Cold Implementation
I rebuilt the system with the correct separation: Redis for payment sessions, TigerBeetle for accounting, PostgreSQL for durable orders.
The hot path became truly hot—Redis and TigerBeetle handling every request. PostgreSQL only gets written to when payment actually succeeds. Failed checkouts never touch the database at all.
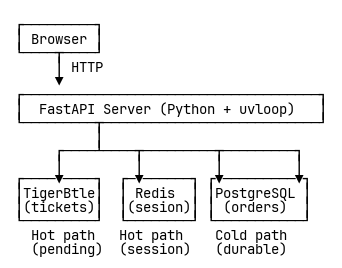
The impact was immediate. Throughput jumped to 865 tickets per second. Moving PostgreSQL out of the critical path unlocked massive performance gains.
This was the working hot/cold architecture—fast where it needed to be fast, durable where it needed to be durable.
Three Configuration Levels
With the hot/cold architecture working, Joran suggested something interesting: could we show “the before and after”? What if we used PostgreSQL for everything? What if we were smart and just added Redis? People would want to see what TigerBeetle actually makes possible.
He was right. The progression itself would tell the story—showing exactly where the performance gains came from, while also checking our assumptions about what was actually slow. As Mark Twain said: “It isn’t what you don’t know that gets you; it’s what you know for sure that just ain’t so.” Unchecked assumptions are silent killers.
This required restructuring the code to support swappable backends, allowing fair comparisons between configurations.
I built three distinct configurations:
- Level 1 (PG Only): PostgreSQL for everything—sessions, accounting, orders
- Level 2 (PG + Redis): Redis for sessions, PostgreSQL for accounting and orders
- Level 3 (TB + Redis): Redis for sessions, TigerBeetle for accounting, PostgreSQL for orders
The refactoring itself cleaned up some inefficiencies—Level 3 maintained its strong performance.
The results told a clear story:
- Level 1: 175 ops/s (reservations), 34 ops/s (webhooks)
- Level 2: 263 ops/s (1.5x better), 245 ops/s (7.3x better!)
- Level 3: 900 ops/s (5.1x vs L1), 313 ops/s (9.3x vs L1)
TigerBeetle speeds up everything.
Comprehensive Testing Infrastructure
With the 3-level comparison structure in place, I built comprehensive testing infrastructure to understand exactly where time was being spent.
I had already split measurements into two phases earlier (during the bottleneck investigation):
- Phase 1: Checkout/Reservations (create holds, save sessions)
- Phase 2: Payment Confirmations/Webhooks (commit/cancel, persist orders)
Now I added isolated endpoints that measured just the core TigerBeetle operations: raw checkout (just the reservation accounting), raw webhook (just the commit accounting). Strip away everything else and see what TigerBeetle itself could do.
But I wanted more. The HTTP request timings were real-world relevant, but they didn’t show POTENTIAL. If, hypothetically, PostgreSQL took 4ms, Redis 2ms, TigerBeetle 1ms, and you had 2 operations per request, you’d see a 2x speedup when switching from PostgreSQL+Redis to TigerBeetle+Redis—when TigerBeetle was actually 4x faster. The Redis offset would hide the true speed in this hypothetical.
The solution: instrument transaction times inside the server. Query them after tests complete. Compare actual operation times, not just request-to-response latency.
Then I built TigerBench—an interactive visualization showing the complete progression across three configurations:
- Level 1 (PG Only): PostgreSQL for everything—sessions, accounting, orders
- Level 2 (PG + Redis): Redis for sessions, PostgreSQL for accounting and orders
- Level 3 (TB + Redis): Redis for sessions, TigerBeetle for accounting, PostgreSQL for orders
The page shows both phases, both isolated operations, all the timings broken down by component. You can see exactly where the time goes in each configuration.
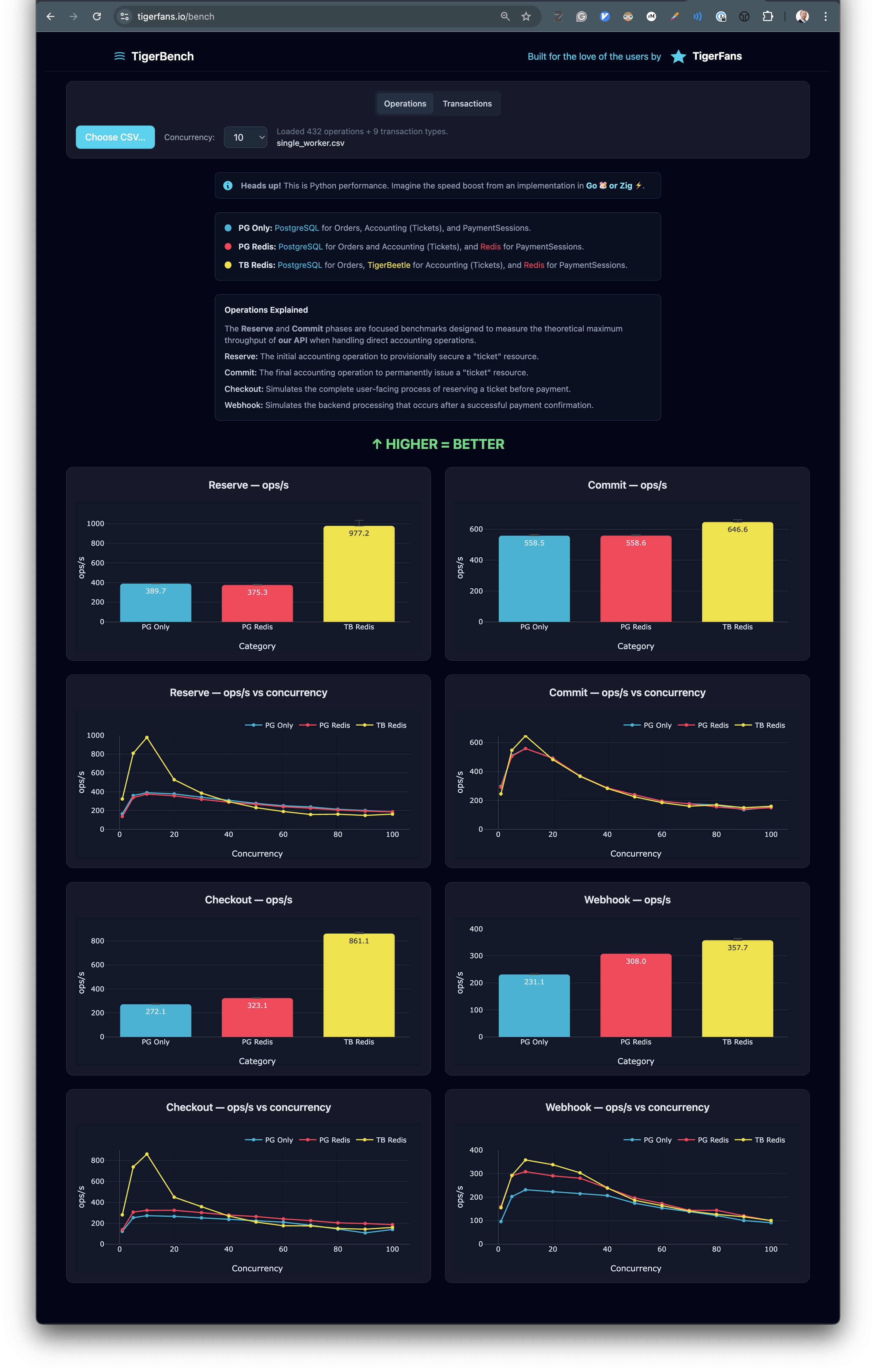 TigerBench visualization showing performance comparison across three configurations
TigerBench visualization showing performance comparison across three configurations
You can explore it yourself: tigerfans.io/bench
Discovering the Batching Problem
Then I added more instrumentation to see what was actually happening inside TigerBeetle calls. The numbers told a strange story: we were sending TigerBeetle batches of size 1.
One transfer per request. Every single time.
TigerBeetle has an interface created for batching. Yet I was using it with many concurrent requests, each creating a batch size of 1.
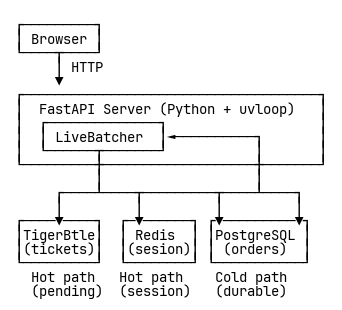
But TigerBeetle can handle 8190 operations per request. That’s where its performance shines. Yet FastAPI’s request-oriented design means every await fires off immediately, creating an interface impedance mismatch. We’re flying a 747 to deliver individual passengers.
The solution was a custom batching layer—the LiveBatcher. It sits between the application and TigerBeetle, collecting concurrent requests as they arrive and packing them into efficient batches. While a batch is being processed, new requests queue up. When processing completes, queued requests are immediately packed and sent, continuously chaining to keep the pipeline full.
Result: batch sizes averaging 5-6 transfers. Throughput jumped to 977 reservations per second—15x faster than the Oasis baseline.
I added the batching metrics to TigerBench too—you can see the batch size distributions across different concurrency levels, watch how batching efficiency changes the performance curve.
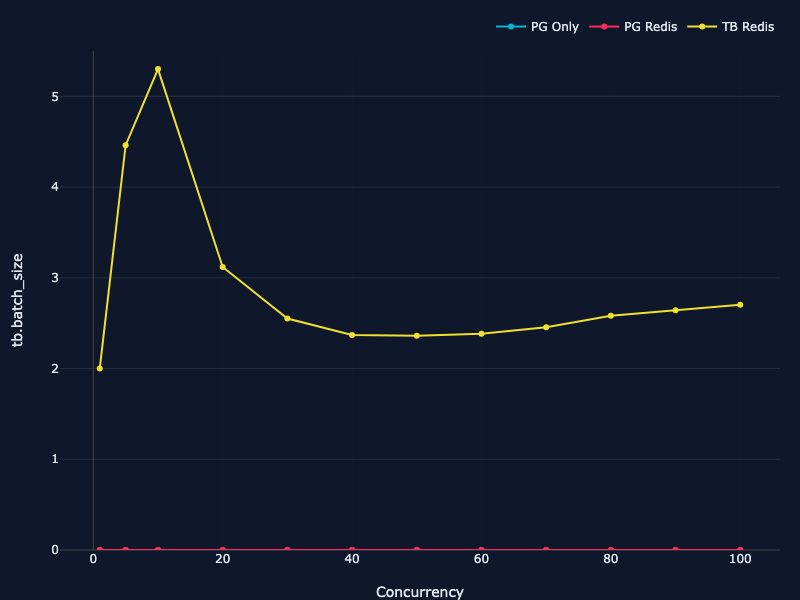 Line chart showing TigerBeetle batch size distribution across concurrency levels
Line chart showing TigerBeetle batch size distribution across concurrency levels
When More Is Less
Then came the most counter-intuitive discovery of the entire project.
For this test, I upgraded to c7g.2xlarge (8 vCPU, 16 GB RAM).
I tried running with multiple workers. Standard practice, right? Eight CPUs, so run multiple workers. Utilize all the cores.
The hypothesis: more workers = more throughput?
Result: NO.
Testing 1,000 reservations:
- 1 worker: 977 ops/s, average batch size 5.3
- 2 workers: 966 ops/s (1% slower), average batch size 3.9
- 3 workers: 770 ops/s (21% slower!), average batch size 2.9
The measurements were clear, but they made no sense. Until I understood what was happening.
Multiple workers fragment batches across event loops. The load balancer sends request 1 to worker 1, request 2 to worker 2, request 3 to worker 3. Each worker’s batcher only sees a fraction of the concurrent load. Smaller batches. And since TigerBeetle processes those batches sequentially anyway, the fragmentation doesn’t buy us parallelism—just overhead.
When batching efficiency is critical, consolidation beats parallelism. It’s Amdahl’s Law in action.
 Single worker vs multi-worker batch fragmentation
Single worker vs multi-worker batch fragmentation
Final Performance Results
After weeks of iteration and measurement, the system hit 977 ticket reservations per second. Fifteen times faster than the Oasis baseline. All in Python.
Median latency: 11 milliseconds. Even at the 99th percentile, requests completed in 26 milliseconds. The batch sizes averaged 5-6 transfers—not close to TigerBeetle’s theoretical optimum, but good enough to unlock real performance.
The limiting factor was clear: Python’s event loop overhead, about 5 milliseconds per request. That’s 45% of the total time. Even with infinitely fast TigerBeetle, you can’t get much faster without ditching Python.
But that was the point. If it works this well with Python’s overhead, the architecture is sound.
TigerBeetle Ticket Challenge
The recipe is proven. This implementation—in Python, with all its overhead—achieves 977 reservations per second. The architecture is documented, the patterns are explained, the lessons are captured.
Imagine this same architecture in Go, where removing Python’s 5ms overhead could yield 10-30x better throughput. Or in Zig, where manual optimization might push it to 50-100x faster.
The TTC challenge is simple: Build your version, any language, any stack, and share your results. Let’s see how fast ticketing can be when TigerBeetle’s batch-oriented design meets systems programming languages.
Resources available:
- Live demo: tigerfans.io
- TigerBench visualization: tigerfans.io/bench
- Source code: github.com/renerocksai/tigerfans
- Technical deep-dives on all four patterns (see menu at the end)
- Reproducible benchmarks
Gratitude
Thank you to Joran Dirk Greef for creating TigerBeetle, for the “benchmark would be nice” challenge that started the optimization journey, and for being so encouraging throughout.
Thank you to Rafael Batiati for the crucial hot/cold path compromise, the perfect balance of speed and durability, the deep code reviews, and diving into TigerBeetle’s Python batching behavior to help unlock the final performance tier.
Thank you to the entire TigerBeetle team for building an amazing database and being so generous with their knowledge.
As the final commit message said:
“I had the time of my life working on this 😊!”
Sometimes the best projects aren’t the ones you plan. They’re the ones that grab you, challenge you, teach you, and refuse to let go until you’ve explored every corner, answered every question, and squeezed every last drop of insight from the problem.
Related Documents
Overview: Executive Summary
Technical Details:
- Resource Modeling with Double-Entry Accounting
- Hot/Cold Path Architecture
- Auto-Batching
- The Single-Worker Paradox
- Amdahl’s Law Analysis
Resources:


