.png)

“Form and function should be one, joined in a spiritual union” - Frank Lloyd Wright
- Research code: https://github.com/pranavc28/generative-ui
- Dataset: https://huggingface.co/datasets/cfahlgren1/react-code-instructions/
Purpose
This blog explores how I fine-tuned Qwen, Qwen/Qwen3-30B-A3B, an open source model producing React code for a fraction of the cost of any of the top-tier AI research labs. I used Tinker to fine-tune my own LLM, a product released by the team at Thinking Machines Lab.
It did a great job, and produced generally usable React code at a better level that I expected it to from an online dataset.
In this blog, I explain what fine-tuning means, why Generative UI can/should be fine-tuned, and share some of my thoughts on Tinker.
Background
As LLMs progressively become better, it is clear that entire backends, such as search or shopping, can be replaced. What about front ends, or user interfaces?
Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation, but their application to UI development faces unique challenges. Unlike backend logic or algorithmic problems where correctness is clear, front end code must have multiple objectives: syntactic correctness, visual appeal, dynamism, and alignment with user intent.
This brings a critical question: what is “Generative UI,” and why does it require specialized approaches?
Definition of Generative UI
Generative UI can be defined as a conditional generation task:
Given:
- A specification \( S \) (user intent, design requirements, functional specifications)
- A domain \( D \) (React, Vue, HTML/CSS, etc.)
- A set of constraints \( C \) (style guidelines, accessibility requirements, component libraries)
Generate:
A complete code artifact \( A \) that compiles/parses without errors, renders a visual interface matching \( S \), includes appropriate interactivity and state management, follows idiomatic patterns for domain \( D \), and satisfies constraints \( C \).
This differs from algorithmic code completion in crucial ways:
Visual Grounding: The code’s visual output matters as much as its textual content—an interface that compiles but looks broken has failed its purpose.
Context Awareness: Generative UI systems must understand the broader context of UI development: component composition, state flow, event handling, styling approaches, and accessibility considerations.
Dynamic vs static code: Generative UI systems must be more dynamic in nature, given that each user has different intent and purposes thus may prefer their own version of interacting with an app.
In our implementation, we focus on React/TypeScript generation, treating each generation as a mapping from (system_prompt, user_message) → React component code.
Why Fine-Tuning for Generative UI?
Having defined what generative UI is, why can’t off-the-shelf large language models handle this task effectively? Why invest effort in fine-tuning models specifically for UI generation?
- Interactivity and Dynamics: Modern UIs aren’t static displays; they respond to user actions through state management and event handlers. A beautiful-looking component that is not dynamic fails its fundamental purpose in today’s world.
- Visual Appeal: The generated code be visually appealing. Styling, layout, and visual hierarchy matter as much as logical correctness. I trained it on an online dataset. Companies/startups have their own codebases and styles - they should use those.
These requirements suggest that fine-tuning is helpful. But what kind of fine-tuning? Traditional supervised learning or reinforcement learning?
The Supervised Learning Limitation
Traditional supervised fine-tuning trains models on input-output pairs, labeled as positive and negative example. But what if the training data contains suboptimal examples? What if there are multiple valid solutions with different quality levels?
For generative UI, this is problematic. A dataset might contain components with varying levels of completeness, dynamism, and code quality. Supervised learning would learn to imitate both the good and the bad examples similarly.
The Reinforcement Learning Solution
Reinforcement learning, specifically Group Relative Policy Optimization (GRPO), addresses these limitations by defining explicit reward functions that encode preferences. We reward complete code more than truncated outputs, interactive components more than static ones, and idiomatic patterns more than unusual but technically correct alternatives. The model learns through exploration and feedback, discovering better solutions than those in the training data.
This motivates a technical approach: GRPO-based fine-tuning with carefully designed reward functions.
Fine-Tuning with GRPO: Technical Deep Dive
Now that we’ve established why reinforcement learning is necessary for generative UI, let’s examine how it works. This section provides a technical deep dive into Group Relative Policy Optimization and its application to UI code generation.
The Supervised Learning Baseline: A Mathematical Perspective
Supervised learning optimizes a straightforward objective—minimize the cross-entropy loss between predicted and target tokens:
$$\mathcal{L}_{\text{SL}}(\theta) = -\mathbb{E}_{x \sim \mathcal{D}}\left[\sum_{t} \log p_\theta(x_t \mid x_{<t})\right]$$
Where \( \theta \) are model parameters, \( \mathcal{D} \) is the training dataset, \( x_t \) is the token at position \( t \), and \( x_{<t} \) is the context (all previous tokens).
This approach teaches the model to maximize the likelihood of the exact training sequences. It’s simple, stable, and works well when training data represents optimal behavior. However, it has fundamental limitations for UI generation:
- Exposure Bias: During training, the model always sees correct previous tokens; at inference, its own potentially incorrect predictions compound.
- Loss-Evaluation Mismatch: Cross-entropy loss treats all token prediction errors equally, but in UI code, a mismatched brace is far worse than suboptimal variable naming.
- No Exploration: The model can only learn from provided examples, never discovering alternative (potentially better) solutions.
Group Relative Policy Optimization (GRPO)
GRPO is a policy gradient reinforcement learning algorithm specifically designed for LLM fine-tuning. Unlike PPO, which requires a separate value network to estimate advantages, GRPO computes advantages directly from a group of sampled trajectories. Instead of maximizing likelihood of specific sequences, GRPO maximizes expected reward:
$$\mathcal{J}(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}\left[R(\tau)\right]$$
Where:
- \( \pi_\theta \) is the policy (our language model)
- \( \tau \) is a trajectory (generated token sequence)
- \( R(\tau) \) is the total reward
The key innovation of GRPO is group-relative advantage estimation. For each prompt, we sample \( k \) completions and compute advantages relative to the group mean:
$$\hat{A}_i = R(\tau_i) - \frac{1}{k}\sum_{j=1}^{k} R(\tau_j)$$
Where:
- \( \tau_i \) is the \( i \)-th sampled trajectory in the group
- \( R(\tau_i) \) is the reward for trajectory \( i \)
- The group mean \( \frac{1}{k}\sum_{j=1}^{k} R(\tau_j) \) serves as a baseline
The GRPO objective function is:
$$\mathcal{L}^{\text{GRPO}}(\theta) = \mathbb{E}_{x \sim \mathcal{D}} \left[\frac{1}{k}\sum_{i=1}^{k} \hat{A}_i \sum_{t} \log \pi_\theta(y_t^{(i)} \mid x, y_{<t}^{(i)})\right]$$
Where:
- \( x \) is the prompt (user request)
- \( y^{(i)} \) is the \( i \)-th generated completion
- \( \hat{A}_i \) is the advantage for the \( i \)-th sample
Why group-relative advantages? By using the group mean as a baseline, we normalize rewards within each prompt’s context. A reward of +5 might be good for a simple component but poor for a complex one. Group-relative advantages automatically adapt to task difficulty—only completions better than the group average receive positive advantages.
The gradient of this objective is:
$$\nabla_\theta \mathcal{L}^{\text{GRPO}}(\theta) = \mathbb{E}_{x \sim \mathcal{D}} \left[\frac{1}{k}\sum_{i=1}^{k} \hat{A}_i \nabla_\theta \sum_{t} \log \pi_\theta(y_t^{(i)} \mid x, y_{<t}^{(i)})\right]$$
This gradient increases the probability of completions with positive advantages (above group mean) and decreases probability of completions with negative advantages (below group mean). The magnitude of the update is proportional to how much better or worse each completion is relative to the other samples for the same example.
Note, DeepSeek was trained using GRPO.
Why GRPO for Generative UI?
GRPO addresses the limitations of supervised learning in three critical ways:
1. Reward-Based Optimization
We define a reward function that explicitly encodes UI quality:
$$R(\text{code}) = R_{\text{base}} + w_1 R_{\text{complete}} + w_2 R_{\text{valid}} + w_3 R_{\text{interactive}} + w_4 R_{\text{quotes}} - w_5 \text{penalty}_{\text{length}}$$
Where:
- \( R_{\text{complete}} \): Reward for structural completeness (matched braces, proper endings)
- \( R_{\text{valid}} \): Reward for syntactic validity (balanced delimiters, proper exports)
- \( R_{\text{interactive}} \): Reward for interactive features (state hooks, event handlers)
- \( R_{\text{quotes}} \): Reward for balanced quotes and strings
- \( \text{penalty}_{\text{length}} \): Penalty for excessive length deviation from reference
This multi-objective reward function captures the nuanced requirements of UI code that cross-entropy loss cannot express. In general, it also assumes that the model can produce compilable code but is not nuanced to produce output in the formats that we want.
2. Exploration and Discovery
By sampling multiple completions per prompt (\( k \) samples), the model explores the solution space. Good solutions (above the K samples group mean) receive positive advantages, whilst poor solutions (below the K samples group mean) receive negative advantages. Over time, the policy shifts toward generating better code.
The model compares different approaches to the same problem within each batch, learning relative quality rather than absolute scores.
3. Stability Through Group Normalization
The group-relative baseline provides automatic reward normalization. Even if we design reward functions with different scales, the advantages are normalized within each group. This prevents catastrophic policy updates—no single exceptionally high or low reward can dominate training. This is crucial for fine-tuning pre-trained models where we want to adapt behavior, not destroy existing knowledge. Unlike PPO’s clipping mechanism, GRPO achieves stability through statistical normalization rather than hard constraints.
With the theoretical foundation established, we can now turn to the practical implementation details.
Implementation: Asynchronous GRPO Training with Tinker
Algorithm: Asynchronous GRPO Training with Tinker
My implementation follows the standard GRPO training loop with asynchronous sampling and gradient computation:
The key infrastructure challenge was figuring out asynchronous execution. Instead of synchronously sampling one prompt at a time, we launch all sampling requests concurrently, process results as they complete, and overlap computation phases.
Below is an image of the general asynchronous calls that were computed to allow Tinker to work efficiently.

Reward function design
The reward function is compositional:
Group-Relative Advantage Construction
The advantage computation is the heart of GRPO. For each prompt, we sample \( k \) completions, compute their rewards, and calculate group-relative advantages:
This two-stage process first normalizes advantages within each group (comparing the \( k \) samples for a prompt), then assigns the normalized advantage uniformly across all generated tokens. This ensures gradients only flow through generated portions from the LLM, not the fixed prompt context.
Hyperparameter Tuning
- Learning rate: \( 10^{-5} \) (small to prevent catastrophic forgetting)
- Samples per prompt (\( k \)): 4 (group size for advantage computation)
- Epochs: 5 (sufficient for convergence on 600 examples)
- Max generation tokens: 16,000 (React components can be long)
The choice of \( k = 4 \) samples per prompt balances exploration (diversity in the group) with computational efficiency. Larger \( k \) provides more robust baselines but increases sampling cost linearly.
Data Filtering
We filter prompts exceeding 16k tokens during initialization to leave room for generation within the 32k context window. This prevents out-of-memory errors and truncated generations.
Results: Comparing Fine-Tuned vs. Raw Qwen Model
To evaluate the effectiveness of GRPO fine-tuning, I tested both the raw Qwen model and the fine-tuned version on three distinct UI generation tasks: booking a ride interface, a Google search homepage, and a leaderboard display. The following analysis is qualitative, focusing on observable improvements in code structure, completeness, and interactivity rather than quantitative metrics. The differences directly reflect the reward signals defined in our training objective.
Each test case highlights a different aspect of the reward function’s impact on generation quality.
Use Case 1: Ride Booking Interface
Raw Model Performance
The raw model’s output exhibits the most critical failure: Incomplete code generation: the component is truncated mid-function, missing closing braces and return statements.
Fine-Tuned Model Performance
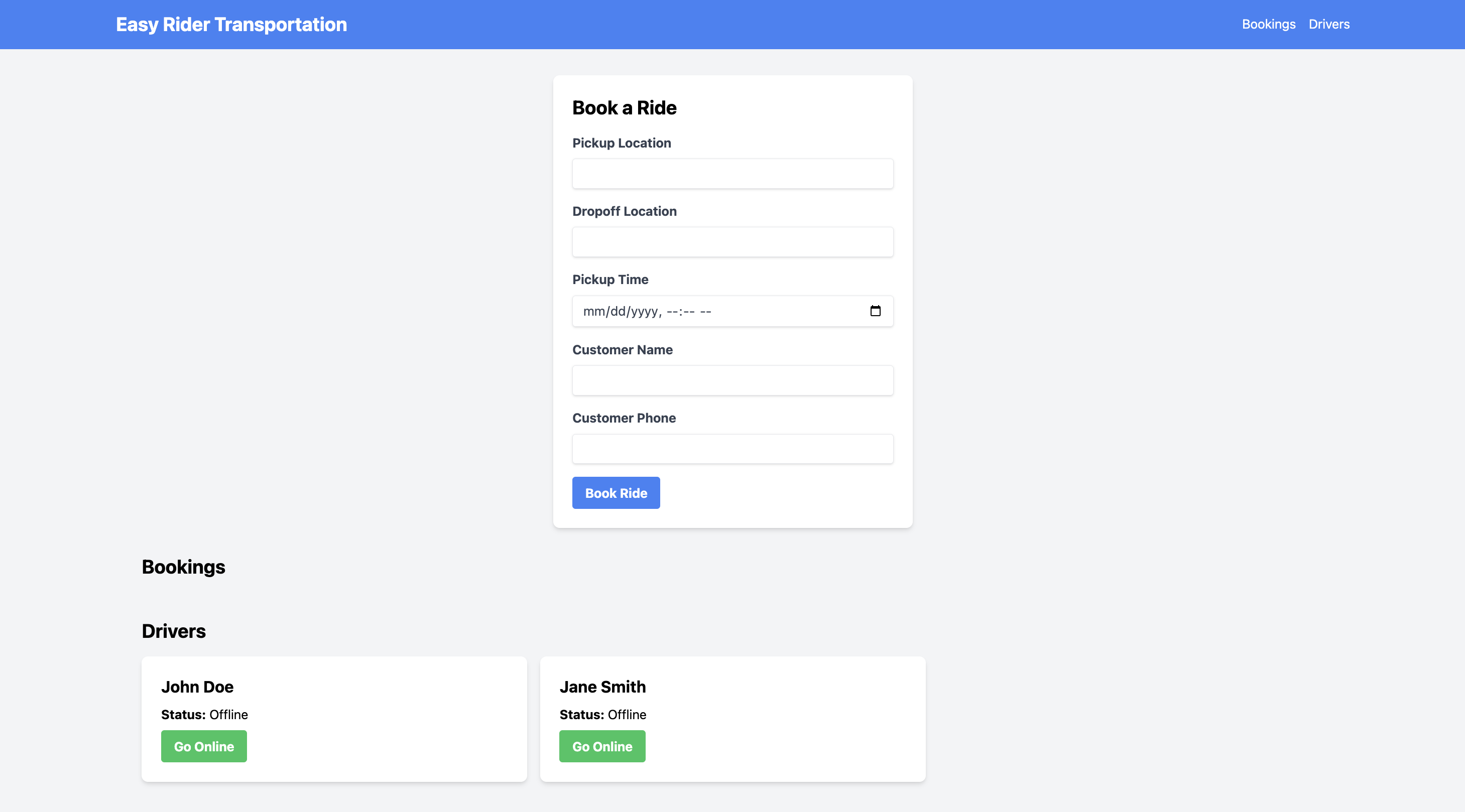
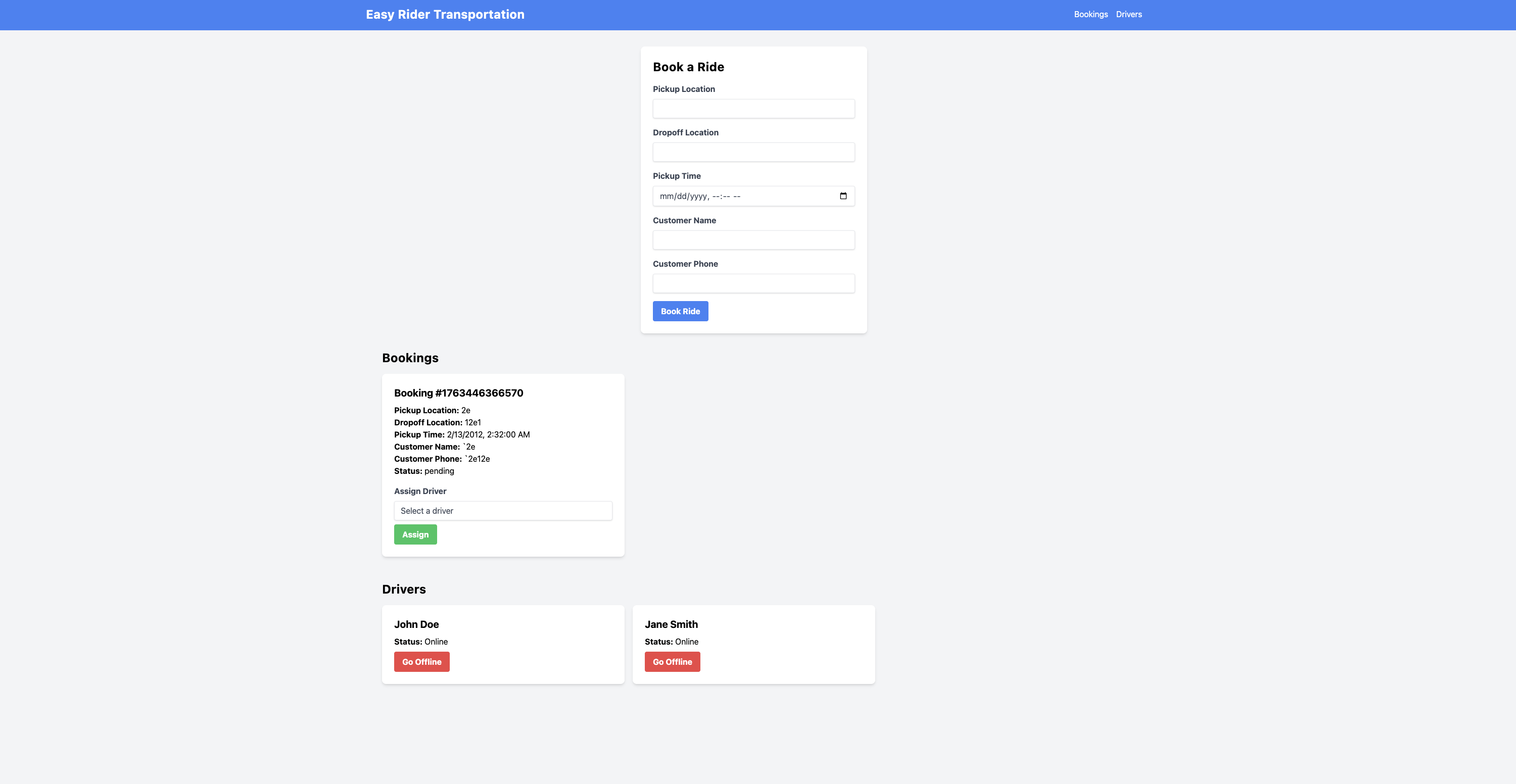
The fine-tuned model demonstrates substantial improvement:
- Structural completeness: Fully formed component with proper exports and matched delimiters
- Rich interactivity: Multiple useState hooks managing ride selection, pickup/dropoff locations, and booking confirmation
- Event handler coverage: onClick handlers for ride type selection, onChange for input fields, onSubmit for booking confirmation
- Conditional rendering: Dynamic UI showing different states (selecting ride, confirming booking, success message)
The fine-tuned model generates not just syntactically correct code, but a functionally complete, interactive booking flow that responds to user actions—exactly what our reward function incentivized. Given the addition of a new computational reward variable for dynamic code, we can see that the LLM picks up on this use case effectively for code generation.
Use Case 2: Google Search Homepage
Raw Model Performance
The raw model produces a basic structure but falls short:
- Limited interactivity: Search input exists but lacks proper state management
- Missing event handlers: No onSubmit handler for search functionality, no onChange for input updates
- Static elements: Buttons and links that don’t respond to user interaction
Fine-Tuned Model Performance
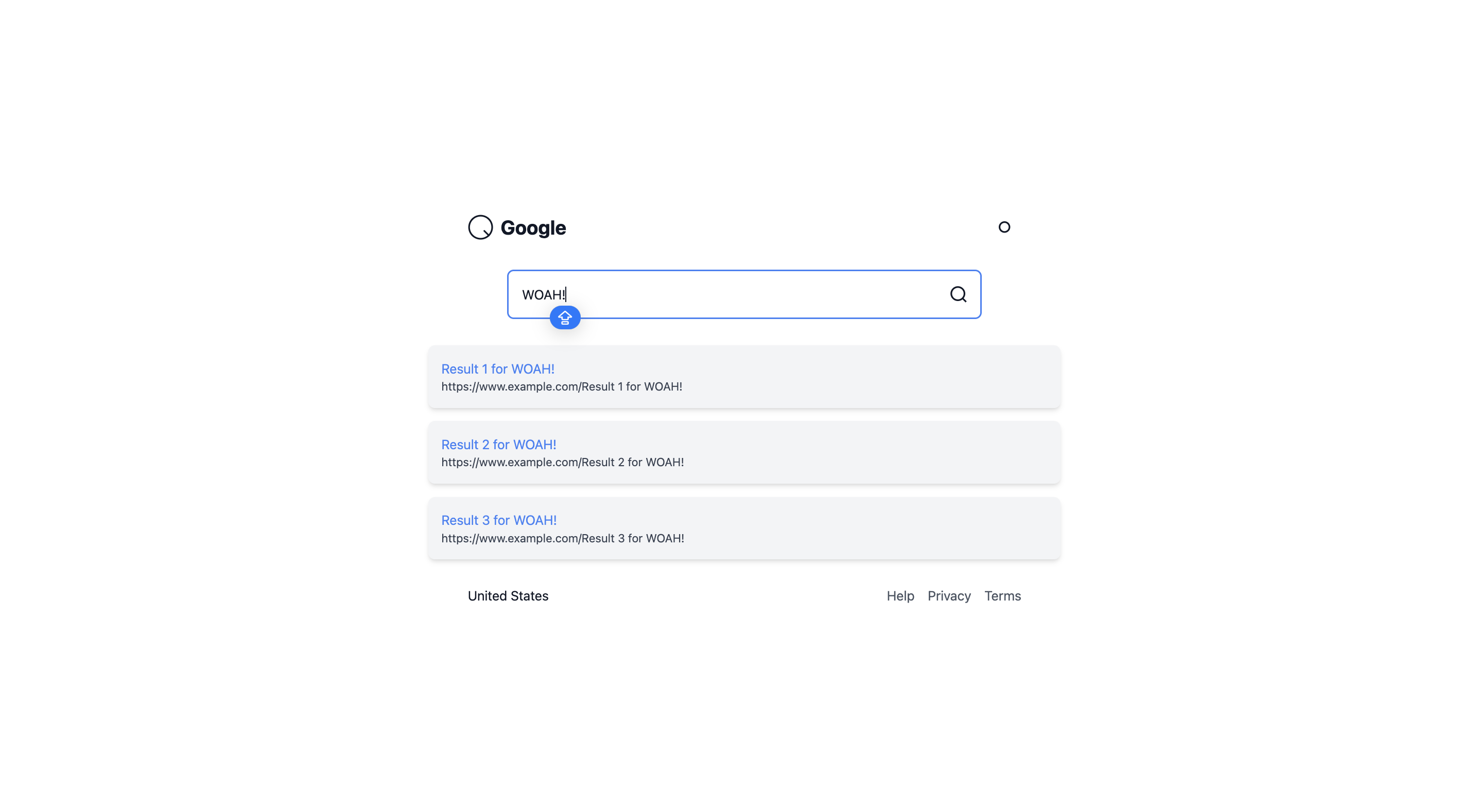
The fine-tuned model excels:
- Complete state management: useState hook managing search query input
- Functional search: Proper form submission with onSubmit handler, and clear search query processing even if the results are hardcoded
- Reactive UI: Input field updates in real-time with onChange handler, controlled component pattern
The reward function’s emphasis on interactivity (\( R_{\text{interactive}} \)) is clearly visible—the fine-tuned model doesn’t just render a static homepage mockup, it generates a functional search interface with proper React patterns.
Use Case 3: Leaderboard Display
Raw Model Performance
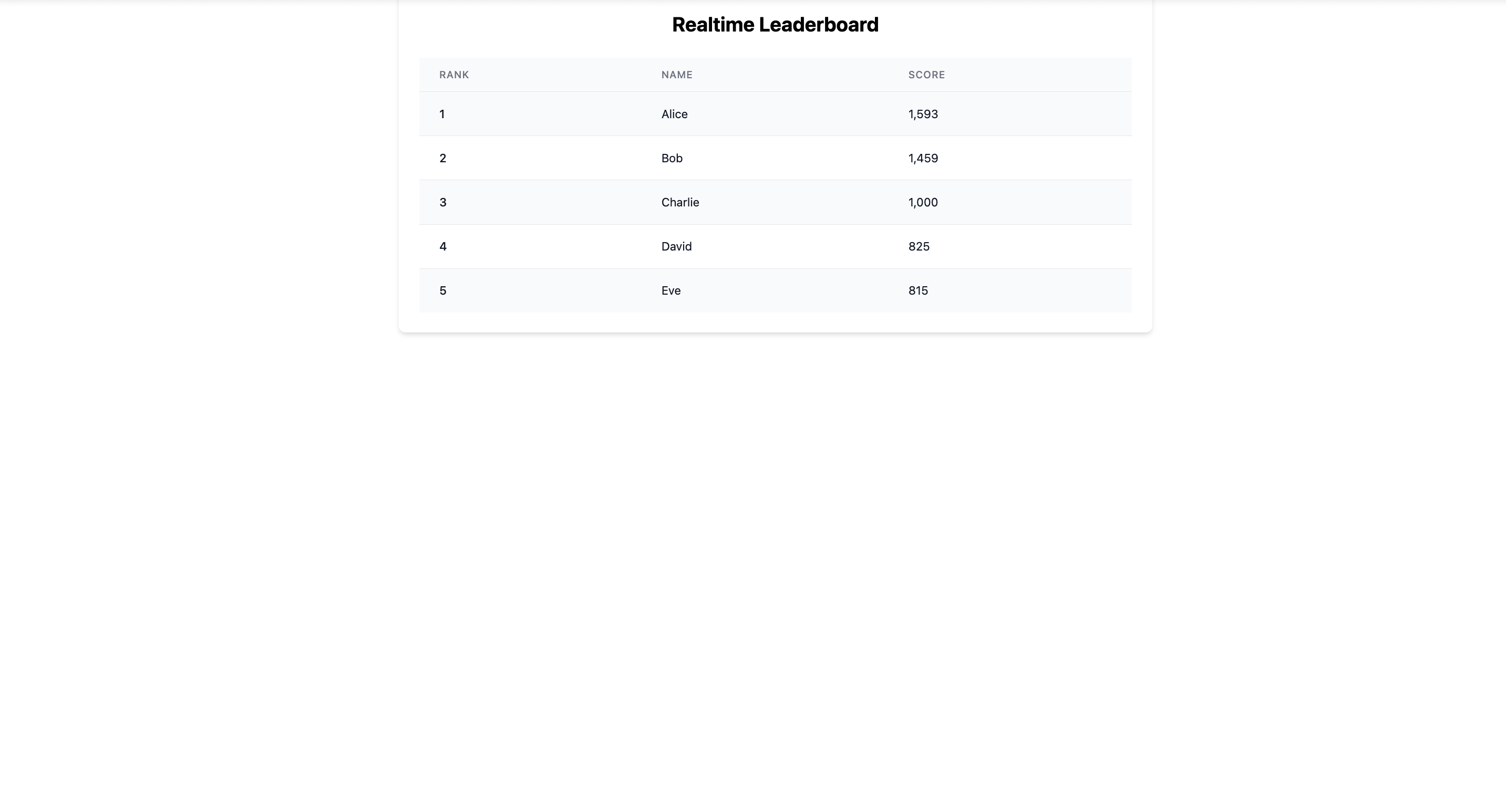
The raw model’s leaderboard suffers from:
- Static data: Hardcoded player list with no dynamic updates or sorting
- Poor data structure: Inconsistent formatting or missing key player attributes
- No interactivity: Unable to filter, sort, or update leaderboard dynamically
Fine-Tuned Model Performance
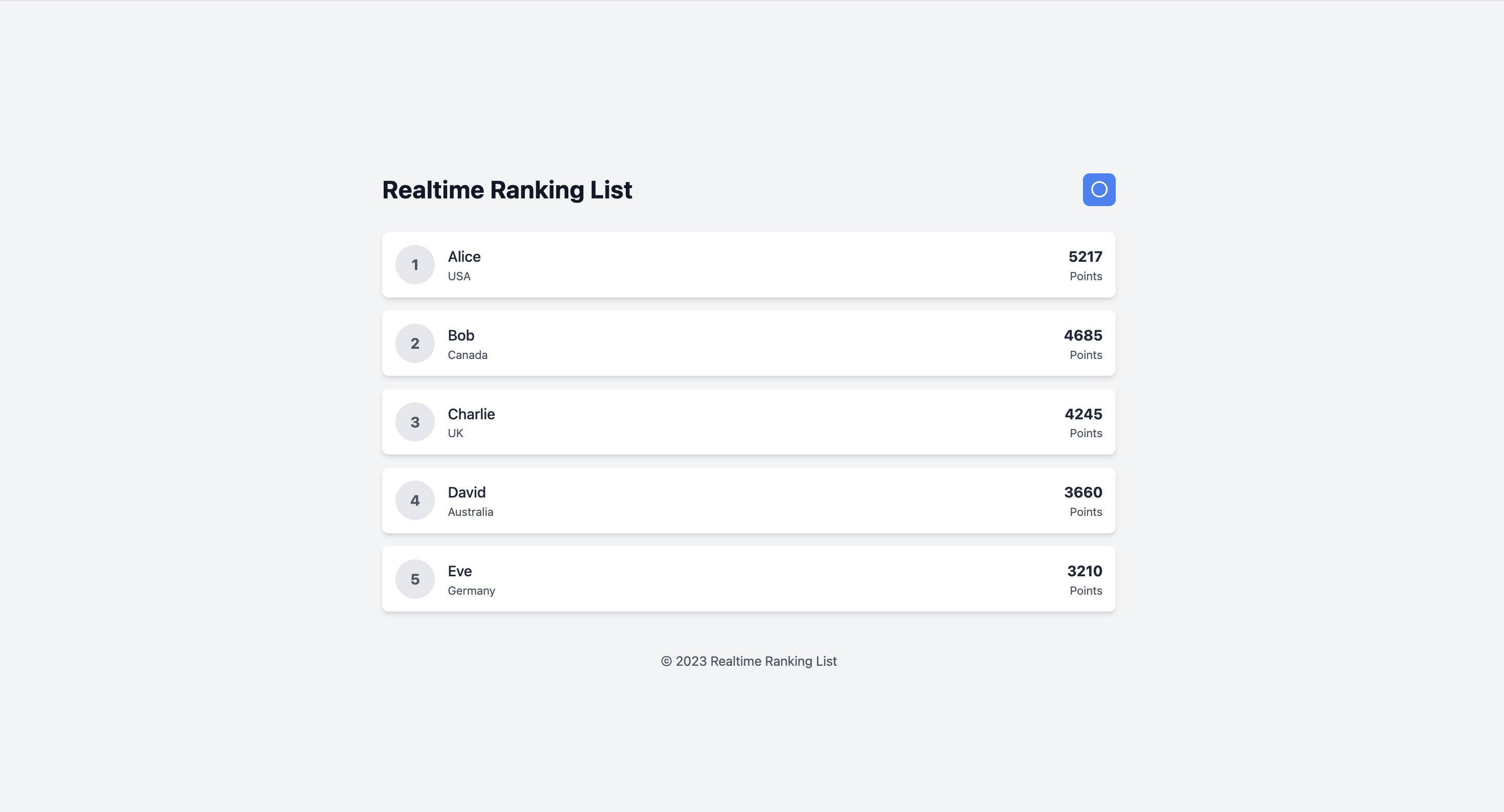
The fine-tuned model generates improved leaderboards with:
- Complete table structure: All rows and columns properly closed, balanced JSX elements
- State-driven rendering: Uses useState to manage leaderboard data, enabling dynamic updates. Also updates leaderboards in realtime as a demo as time progresses.
- Interactive features: Sorting by clicking column headers, filtering by player name, expandable rows for player details
- Proper data mapping: .map() with keys, proper TypeScript typing for player objects
In this case, I was particularly interested in observing how the model generate real-time updates using time-based state changes. This was not something explicitly encoded in the prompt, yet the model inferred from training patterns that dynamic updates would enhance the user experience—demonstrating genuine learned understanding rather than mere template replication.
These qualitative results validate the GRPO approach, but implementing this system revealed important practical considerations about infrastructure and tooling around tinker.
Technical Considerations and Lessons Learned with Tinker
My experience using Tinker for this generative UI fine-tuning project provided valuable insights into distributed reinforcement learning infrastructure and practical considerations for implementing custom training loops at scale.
Key Strengths:
Flexible API for Custom Training Loops: Tinker’s Python-based API allowed me to implement asynchronous GRPO with full control over the training loop. I could define custom reward functions, manage sampling strategies, and orchestrate group-relative advantage computations without being constrained by a rigid framework. This flexibility was essential for implementing the multi-objective reward function targeting UI-specific qualities like completeness, interactivity, and structural validity. The ability to write arbitrary Python code while Tinker handled the distributed execution was the key differentiator.
Managed Infrastructure with Distributed GPU Orchestration: The platform abstracted away the complexity of distributed training across multiple GPUs. I didn’t need to manage NCCL configurations, handle gradient synchronization, or debug multi-node communication failures. Tinker’s infrastructure automatically distributed my sampling requests across available GPUs, collected results asynchronously, and executed gradient updates efficiently. For a researcher focused on algorithm development rather than DevOps, this was invaluable—I could iterate on reward functions and training hyperparameters without worrying about infrastructure scalability.
Efficient LoRA Support for Large Model Fine-Tuning: Training a 30B parameter model like Qwen3-30B-A3B would typically require prohibitive computational resources. Tinker’s native support for Low-Rank Adaptation (LoRA) reduced the trainable parameters by several orders of magnitude, making the fine-tuning feasible on available GPU resources. The training converged in 5 epochs across 600 examples, completing in a reasonable timeframe. Without LoRA support integrated into the platform, this project would have been impractical for individual researchers or small teams.
Technical Challenges and Solutions:
Asynchronous Workflow Optimization: I initially implemented a synchronous pipeline, processing one prompt at a time. This approach became a significant bottleneck, with idle GPU time during sequential operations. After discovering Tinker’s native asynchronous support, I refactored the entire training loop to launch concurrent sampling requests. The lesson here is that understanding the platform’s async capabilities upfront is crucial for performance optimization. It also raised another question, when should one use synchronous sampling? Perhaps Thinking Machine Labs could make that clearer in their guide.
Custom Monitoring Infrastructure: To track training convergence and debug reward function behavior, I needed detailed logging of epoch runs, reward distributions, and sampling efficiency. Tinker’s API didn’t provide built-in monitoring dashboards, so I implemented custom logging that captured per-epoch metrics, advantage distributions, and policy divergence measures. This experience highlighted the importance of observability in RL training—without detailed metrics, diagnosing reward function issues or training instabilities would have been nearly impossible. For production deployments, integrating monitoring tools like Weights & Biases would be essential.
Access Model and Collaboration: Tinker operates in private beta, which required coordination with the Thinking Machines team for access and onboarding. While this provided an opportunity for direct technical support, it also meant that reproducing these results requires similar access arrangements. For teams evaluating fine-tuning platforms, understanding the access model and support structure is important for project planning and timeline estimation.
Future Directions for Reward Function Engineering: One area where additional tooling could provide significant value is automated reward function tuning. In this project, I manually specified weights for completeness, interactivity, and validity rewards (\( w_1 = 7.5 \), \( w_2 = 1.8 \), etc.). These values were determined through iterative experimentation—adjusting weights, observing generated samples, and refining the balance. A platform that could automate this hyperparameter search using techniques like Bayesian optimization or “learned reward functions” would substantially reduce the engineering burden and enable faster convergence to optimal reward specifications.
Until they have something truly native to their platform as a feature, such a reward function optimization, I don’t why I’d use them again compared to competitors like Modal or Unsloth. I got a lot of free credits, which made me excited to give them a try!
Conclusion
The results from fine-tuning Qwen3-30B-A3B demonstrate the potential of open-source models for specialized tasks. These models deliver strong performance at a fraction of the cost of frontier models like GPT-4 or Claude 3.5. This reinforces a broader trend in the AI landscape: specialized, fine-tuned smaller models often outperform general-purpose larger models for well-defined tasks.
Generative UI represents a generational shift in interface development—from manual coding to specification-to-implementation via machine learning. By fine-tuning large language models with GRPO, we can teach models not just to imitate existing code, but to discover and generate high-quality, interactive, complete user interfaces based on exisiting code bases.
Companies no longer have to mentor their front end engineers to build aesthetic front end applications. Simply fine tune an LLM similar to what I did on your exisiting codebase’s reward signals, and ask the model to output code relative to your requirements and styles.

![How to make precise sheet metal parts (photochemical machining) [video]](https://www.youtube.com/img/desktop/supported_browsers/opera.png)

