.png)

note: i’m kinda tired of the “levered beta” metaphor, i have one more topic i want to cover on this topic related to cognition, and then i’ll go back to my normal writing

imagine you start a company knowing that consumers won't pay more than $20/month. fine, you think, classic vc playbook - charge at cost, sacrifice margins for growth. you've done the math on cac, ltv, all that. but here's where it gets interesting: you've seen the a16z chart showing llm costs dropping 10x every year.
so you think: i'll break even today at $20/month, and when models get 10x cheaper next year, boom - 90% margins. the losses are temporary. the profits are inevitable.
it’s so simple a VC associate could understand it:
year 1: break even at $20/month
year 2: 90% margins as compute drops 10x
year 3: yacht shopping
it’s an understandable strategy: "the cost of LLM inference has dropped by a factor of 3 every 6 months, we’ll be fine”
but after 18 months, margins are about as negative as they’ve ever been… windsurf’s been sold for parts, and claude code has had to roll back their original unlimited $200/mo tier this week.
companies are still bleeding. the models got cheaper - gpt-3.5 costs 10x less than it used to. but somehow the margins got worse, not better.
something doesn't add up?
gpt-3.5 is 10x cheaper than it was. it's also as desirable as a flip phone at an iphone launch.
when a new model is released as the SOTA, 99% of the demand immediatley shifts over to it. consumers expect this of their products as well.
now look at the actual pricing history of frontier models, the ones that 99% of the demand is for at any given time:
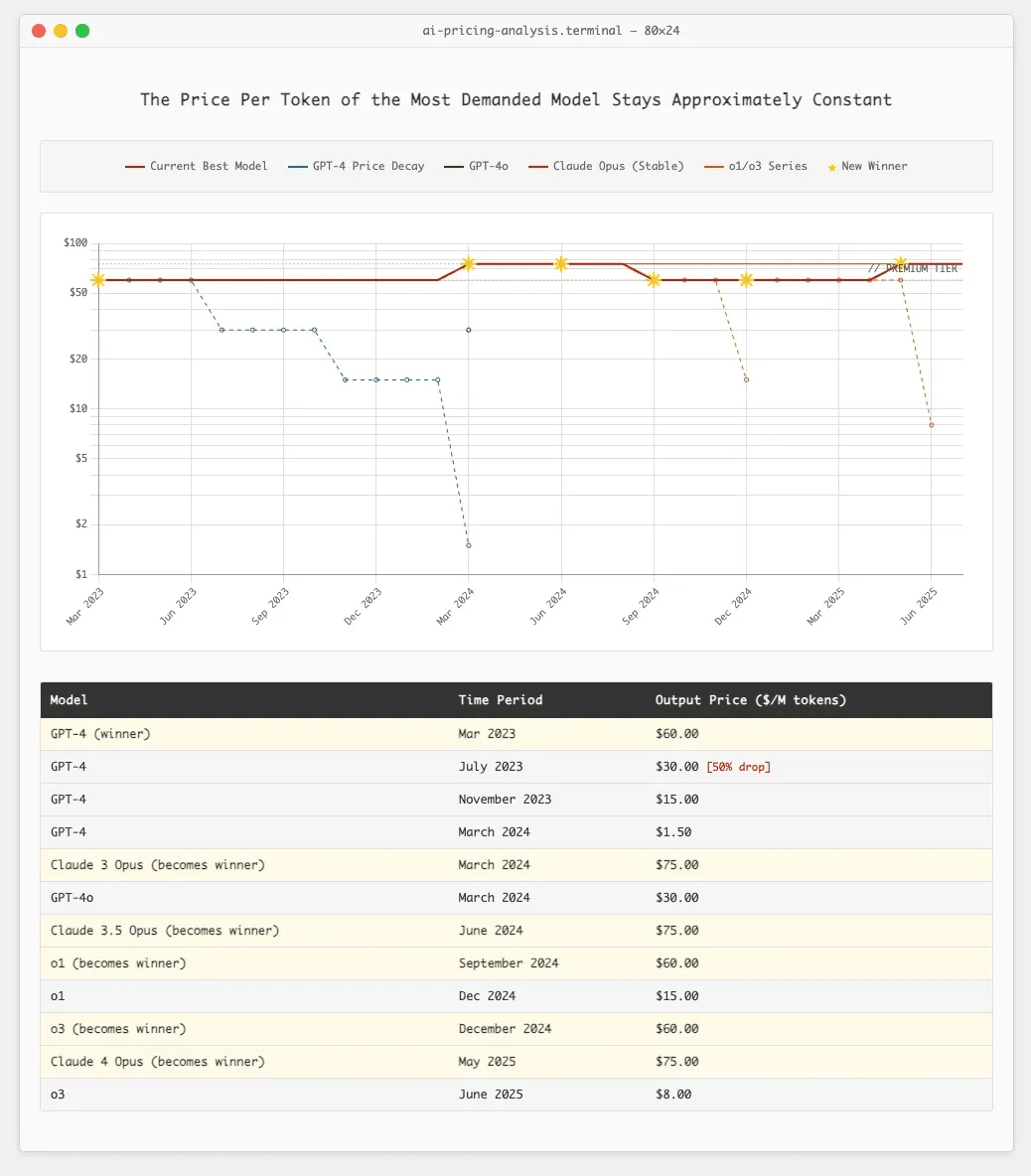
notice something?
when gpt-4 launched at $60, everyone used it despite gpt-3.5 (the previous SOTA) being 26x cheaper.
when claude 3 opus launched at $60, people switched despite gpt-4 getting price cuts.
the 10x cost reduction is real, but only for models that might as well be running on a commodore 64.
so this is the first faulty pillar of the “costs will drop” strategy: demand exists for "the best language model," period. and the best model always costs about the same, because that's what the edge of inference costs today.
saying "this car is so much cheaper now!" while pointing at a 1995 honda civic misses the point. sure, that specific car is cheaper. but the 2025 toyota camry MSRPs at $30K.
when you're spending time with an ai—whether coding, writing, or thinking—you always max out on quality. nobody opens claude and thinks, "you know what? let me use the shitty version to save my boss some money." we're cognitively greedy creatures. we want the best brain we can get, especially if we’re balancing the other side with our time.
"okay, but that's still manageable, right? we just stay at breakeven forever?"
oh, sweet summer child.
while it's true each generation of frontier model didn't get more expensive per token, something else happened. something worse. the number of tokens they consumed went absolutely nuclear.
chatgpt used to reply to a one sentence question with a one sentence reply. now deep research will spend 3 minutes planning, and 20 minutes reading, and another 5 minutes re-writing a report for you while o3 will just run for 20-minutes to answer “hello there”.
the explosion of rl and test-time compute has resulted in something nobody saw coming: the length of a task that ai can complete has been doubling every six months. what used to return 1,000 tokens is now returning 100,000.
the math gets genuinely insane when you extrapolate:
today, a 20-minute "deep research" run costs about $1. by 2027, we'll have agents that can run for 24 hours straight without losing the plot… combine that with the static price of the frontier? that’s a $4320 run. per day. per user. with the ability to run multiple asynchronously.
once we can deploy agents to run workloads for 24 hours asynchronously, we won't be giving them one instruction and waiting for feedback. we'll be scheduling them in batches. entire fleets of ai workers, attacking problems in parallel, burning tokens like it's 1999.
obviously - and i cannot stress this enough - a $20/month subscription cannot even support a user making a single $1 deep research run a day. but that's exactly what we're racing toward. every improvement in model capability is an improvement in how much compute they can meaningfully consume at a time
it's like building a more fuel-efficient engine, then using the efficiency gains to build a monster truck. sure, you're getting more miles per gallon. you're also using 50x more gallons.
this is the short squeeze that forced windsurf to get margin called [insert thing] — and any “flat rate subscription + useful token intensive” business model startup is looking down the barrel of.
claude code's max-unlimited experiment was the most sophisticated attempt at weathering this storm we've seen. they tried every trick in the book and still got obliterated.
their playbook was genuinely clever:
1. charge 10x the price point
$200/month when cursor charges $20. start with more buffer before the bleeding begins.
2. auto-scale models based on load
switch from opus ($75/m tokens) to sonnet ($15/m) when things get heavy. optimize with haiku for reading. like aws autoscaling, but for brains.
they almost certainly built this behavior directly into the model weights, which is a paradigm shift we’ll probably see a lot more of
3. offload processing to user machines
why spin up your own sandboxes when users have perfectly good cpus sitting idle?
and despite all this engineering brilliance, token consumption still went supernova.
ten. billion. tokens. that's 12,500 copies of war and peace. in a month.
how? even at 10-minute runs, how does someone drive 10b tokens?
turns out 10-20 minute continuous runs are just long enough for people to discover the for loop. once you decouple token consumption from human time-in-app, physics takes over. set claude on a task. have it check its work. refactor. optimize. repeat until bankruptcy.
users became api orchestrators running 24/7 code transformation engines on anthropic's dime. the evolution from chat to agent happened overnight. 1000x increase in consumption. phase transition, not gradual change.
so anthropic rolled back unlimited. they could've tried $2000/month, but the lesson isn't that they didn't charge enough, it’s that there’s no way to offer unlimited usage in this new world under any subscription model.
it's that there is no flat subscription price that works in this new world.
the math has fundamentally broken.
this leaves everyone else in an impossible position.
every ai company knows usage-based pricing would save them. they also know it would kill them. while you're being responsible with $0.01/1k tokens, your vc-funded competitor offers unlimited for $20/month.
guess where users go?
classic prisoner's dilemma:
everyone charges usage-based → sustainable industry
everyone charges flat-rate → race to the bottom
you charge usage, others charge flat → you die alone
you charge flat, others charge usage → you win (then die later)
so everyone defects. everyone subsidizes power users. everyone posts hockey stick growth charts. everyone eventually posts "important pricing updates."
cursor, lovable, replit - they all know the math. they chose growth today, profits tomorrow, bankruptcy eventually but that's the next ceo's problem.
honestly? probably right. in a land grab, market share beats margins. as long as vcs keep writing checks to paper over unit economics...
ask jasper what happens when the music stops.
is it even possible to avoid the token short squeeze?
recently cognition has been rumored to be raising at $15b, while externally they haven’t even reported $100m arr [i’d guess it’s closer to $50m]. this contrasts with the $10b valuation that cursor raised on at $500m arr with a much steeper curve. more than eight times the revenue, two-thirds the valuation. what do vcs know about cognition that we don't? they're both ai agents that write code. has cognition figured out a way out of the death spiral? [more on this next time I guess]
there are three ways out:
1. usage-based pricing from day one
no subsidies. no "acquire now, monetize later." just honest economics. sounds great in theory.
except show me the consumer usage-based ai company that's exploding. consumers hate metered billing. they'd rather overpay for unlimited than get surprised by a bill. every successful consumer subscription - netflix, spotify, chatgpt - is flat rate. the moment you add a meter, growth dies.
2. insane switching costs ⇒ high margins
this is what devins all in on. they’ve recently announced their citi and goldman sachs parterships, deploying devin to 40,000 software engineers at each company. at $20/mo this is a $10M project, but here’s a question: would you rather have $10M of ARR from goldman sachs or $500m from prosumer devleopers?
the answer is obvious: six-month implementations, compliance reviews, security audits, procurement hell mean that that goldman sachs revenue is hard to win — but once you win it it’s impossible to churn. you only get those contracts if the singular decision maker at the bank is staking their reputation on you — and everyone will do everything they can to make it work.
this is also why the largest software companies outside of the hyperscalers are all system-of-record companies that sell to those exact personas [CRM / ERP / EHRs]. they also all make 80-90% margins because the harder it is to churn, the less price sensitive your buyer is.
by the time a competitor shows up, you're so deep in the bureaucracy that switching would require another six-month sales cycle. it's not that you can't leave. it's that your cfo would rather die than go through another vendor evaluation.
3. vertical integration ⇒ make money on the infra
this is replit’s game: bundle the coding agent with your application hosting, database management, deployment monitoring, logging, etc. lose money on every token, but capture value at every single other layer of the stack for this new generation of developers… just look at how vertically integrated replit is
use ai as a loss leader to drive consumption of aws-competitive services. you're not selling inference. you're selling everything else, and inference is just marketing spend.
the genius is that code generation naturally creates demand for hosting. every app needs somewhere to run. every database needs management. every deployment needs monitoring. let openai and anthropic race inference to zero while you own everything else.
the companies still playing flat-rate-grow-at-all-costs? dead companies walking. they just have very expensive funerals scheduled for q4.
i keep seeing founders point to the "models will be 10x cheaper next year!" like it’s a life raft. sure. and your users will expect 20x more from them. the goalpost is sprinting away from you.
remember windsurf? they couldn’t figure out a way to manueveur out bc of the pressure that cursor put on their p&l. even anthropic with the most vertically integrated application layer on the planet can’t make a flat subscription with unlimited usage work.
while the summary from “levered beta is all you need“: which is that being early beats being smart, is still true, being early w/o a plan also means you’re getting to the graveyard first. there's no google writing $2.4b checks for negative margin businesses. there's no "we'll figure it out later" when later means your aws bill is larger than your revenue.
so how do you build a business in this world? the short answer is be a neocloud — which is the title of my next thing.
but at least the models will be 10x cheaper next year.
thank you to mark hay, ben mains, nikunj kothari, bryan bischof, andy jiang, vedika jain, and aman kishore for reading drafts of this



