.png)

A 1-year retrospective on KernelBench / progress towards automated GPU Kernel Generations
Today roughly marks the one-year anniversary of the first GPU MODE hackathon, where we started to ask the question, “Can LLMs write efficient GPU (CUDA) kernels?”, leading to the first version of KernelBench! Having gone down this rabbit hole for a whole year now, it has been a wild ride for my labmates and me — we tried everything from leveraging test-time search, scaling synthetic data, and applying reinforcement learning. Over the course of this endeavor, we have learned a ton and have been so surprised by the community’s enthusiasm for our benchmarks and our vision, especially through all the diverse approaches that spawned over such a short period of time!

We figured now would be a good time to share many of the lessons we learned along the way, and recap many of the different approaches that got the community to where things are now. We also speculate a bit on what might be next, and how to continue improving KernelBench this Fall!
Concretely, we also spent a lot of time curating all of the follow-up and related works over this last year. The rest of this blogpost is structured chronologically, which we think helps put into perspective how different ideas about GPU codegen evolved over time. We first recount how KernelBench was conceived and why automated GPU kernel generation matters. We then walk through the key technical lessons from the past year: we start from our thoughts on robust benchmarking and reward hacking, move to the first attempts at test-time-search (i.e. monkeys) and our parallel direction of tackling the data bottleneck, then discuss attempts at more expensive evolutionary search methods and RLVR. Finally, we look ahead at emerging directions like compiler co-design, new DSLs, and hardware-aware agents shaping the future of kernel generation.
Disclaimer: this blog is modified from Simon’s talk at the Stanford PORTAL Seminar; throughout this journey, we’ve collaborated with several different companies and organizations, but any opinions or thoughts are from us (Simon & Alex) as PhD students.
A Case for Automated GPU Kernel Generation
Simon: When I was about to start a PhD at Stanford last year, I wasn’t quite sure what I wanted to do. The only thing I was certain of was that writing GPU kernels was a pain, especially after conversations with Anne (another awesome first-year PhD student and kernel guru who worked at NVIDIA on cuDNN). I always liked to make things go fast, but writing a kernel is next-level complex—mapping operations onto GPUs with never-ending tricks and bugs to squeeze that last bit of performance. Before Stanford, I got a taste of this while optimizing pre-training performance at Cohere and through side projects like contributing PRs to Karpathy’s llm.c. Even though fancy optimization techniques and GPUs fascinated me, optimizing even a basic kernel took me a long time (and I increasingly started to ask ChatGPT). This led Anne and me to wonder, wouldn’t it be great if the LLMs could help us write CUDA kernels?
As we all know, GPU kernels are essential for modern deep learning performance; we rely on masterful implementations such as FlashAttention and FlashMLA to make our chat models go brrrrrrrr all the time. However, we can’t simply just rely on a few geniuses writing kernels day and night (I wish I could be as good as them), as:
- We want to explore new and better architectures! While Transformers dominate, people are always exploring alternative architecture (folks from Hazy such as Simran, Sabri, and Michael have done a ton of work on this) to find something faster! However, even if your new fancy architecture offers better asymptotic complexity, its wall-clock performance (which is what matters in the end) might still fall short of attention with highly optimized FlashAttention kernels.
- At the same time, we have new chips! Mapping code on new hardware, in different domain-specific languages with different programming models, is always a pain: William and I spent a whole quarter struggling to write HIP kernels for AMD MI325X chips; even though it has better specs than the H200, we couldn’t get more effective FLOPs out of it! Even for just across NVIDIA hardware, the hardware features changes drastically over generations, and it took 2 years after Hopper’s release to have an efficient FlashAttention port.
- While I am a big fan of compilers and ideally hope compilers can do all the magic, it is hard for them to handle ever-changing workloads and diverse hardware while optimizing everything (though smart efforts like FlexAttention exist). In this case, we wanted to explore the LLM as a core component in the optimization loop of a compiler.
During the orientation week, Anne and I dropped everything we were doing and started hacking up a prototype. We even dragged our entire lab to the GPU MODE hackathon up in SF to try this idea! While there, we met our hero Andrej, and his words deeply resonated with us.
“We wrote llm.c as multiple people over the duration of 3 months and got something that was faster than PyTorch in a specific setting […]. If LLMs are about to become much better at coding, you can expect that the LLM can do this for any custom application over time, acting as a sort of compile […] It could be that the use of PyTorch and Python is a crutch, and maybe, why not, we may want to write everything in custom CUDA Kernels.” — Andrej Karpathy, GPU Mode Talk
Making of KernelBench the Benchmark
We had a lot of ideas on how we wanted to tackle this task, but we quickly realized we didn’t quite know how to measure and compare GPU kernels. One of the key lessons Professor David Patterson taught me back at Berkeley is the importance of benchmarking and measuring before optimizing anything. This led to us coming up with a benchmark / evaluation framework for automated kernel generation, a.k.a. the birth of the KernelBench project.
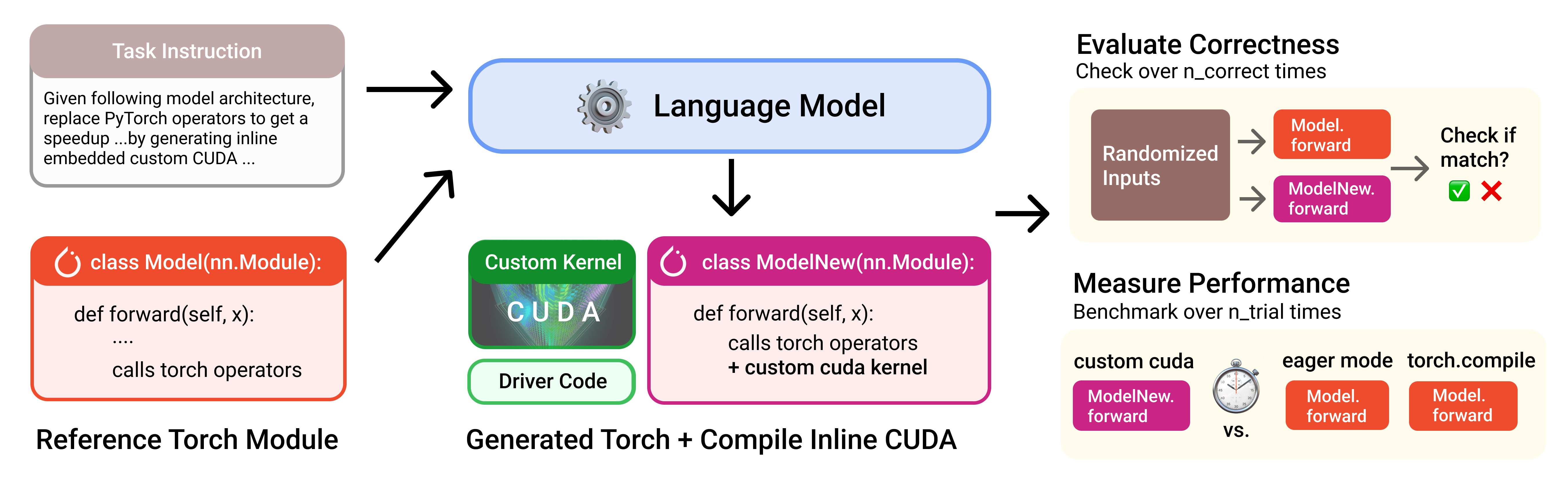
We frame the problem as follows: given a task expressed in PyTorch, transpile it into inline CUDA + a PyTorch wrapper. We chose this specification based on experiences we’ve had with using custom kernels in PyTorch. The tasks vary from very simple operators (e.g. activation functions) to full architectures representative of real-world workloads.
This design has 3 benefits for us to measure correctness and performance:
- Defining the problem in PyTorch makes it clear and easy to construct. This means we don’t have to rely on ambiguous natural language spec or hand-write a reference naive CUDA code for each problem, which allows us to scale up the number of problems easily.
- The PyTorch baseline can be used as correctness reference: while we can’t formally prove the generated program and reference code are equivalent, we can fuzz them with randomized inputs and compare outputs within numerical tolerance, which is what performance engineers do in practice.
- The PyTorch baseline could be used to compute speedup: a real custom kernel is only useful if it is faster than PyTorch / torch.compile (which is a high bar to meet!) This makes us compare LLM-generated kernels to test against expert-engineer and well-engineered torch.compile backends (thanks to the PyTorch team for teaching me more about them!).
With that in mind, we designed KernelBench with 3 levels, each challenging in a distinct way:
- Level 1 Single Operators: e.g., matmul, conv; this is actually quite hard since we would be competing against highly-optimized libraries
- Level 2 Sequence of Operators: help test model’s ability to conduct kernel fusion, a key technique used by graph compilers
- Level 3 End-to-end architectures: like a Vision Transformer or Mamba block, evaluate model’s ability to identify optimization opportunities within whole model architecture
We’ve generally observed that benchmarks quickly get saturated with rapid AI progress, so we hoped KernelBench could serve as an evolving benchmark with movable targets that do not saturate quickly. Taking inspiration from SWE–Bench, we wanted the key benchmarking idea to be amenable to newly introduced real-world tasks and targets, e.g., raising the speedup threshold (can it be 1x faster than PyTorch Eager? 2x faster?). To that end, we designed a metric fast_p, aka the percentage of problems that model can generate a kernel correct and p times faster than PyTorch eager / compile.
A key lesson while constructing this evaluation environment is that GPU kernel profiling and benchmarking are quite tricky! The runtime of your kernels depends on the underlying hardware, throttling effects, driver versions, and other environment-specific details, as well as the input-shape size, datatypes, and allowable tolerances that the task defines. We found that many of these details were often overlooked, leading to reward hacking or inconsistent results being reported, many of which were found from careful inspection by our follow-up work and the community. We highly recommend these resources from GPU MODE on measuring kernel correctness and performance, and to always be paranoid of suspiciously good results – kernel engineers and existing compilers are already pretty good, so a >2x speedup for anything is highly unlikely.
With these lessons in mind, this fall we are determined to keep improving the benchmark (building off work in the summer with KernelBench v0.1) to make it more robust (see our roadmap). We ultimately want to create an end-to-end pipeline that is easy to use and usable as a consistent comparison between different models and approaches.
As a first step to evaluate current capability towards automated kernel generation, we found in our initial experiments that frontier models were able to generate correct and faster kernels than PyTorch Eager less than 20% of the time, across the 3 levels. We also found that they struggle to write hardware-specific intrinsics and/or tricks across different target GPUs, like leveraging the TensorCore, which is most of the performance on modern GPUs. Please refer to the KernelBench paper for more details!
Since then, the field continues to grow with several new projects since KernelBench that focus on end-to-end kernel evaluation and integration that are particularly interesting, such as BackendBench (PyTorch operator level interface led by Mark Saroufim at PyTorch), FlashInferBench (FlashInfer kernels that directly integrate into inference engines), TritonBench (evaluating a model’s ability to generate performant Triton kernels), and the nanoGPT speed-runs (end-to-end train time). We greatly appreciate these efforts from the community towards more robust evaluation, such as leveraging the existing torch testing suite and training convergence testing in BackendBench, emphasizing correctness validation. This past year, we have seen several results focused on flashy performance results, many of which are functionally incorrect or reward hacked in subtle ways. While the community continues to provide better evals, we also urge new work hillclimbing on the benchmarks to exercise caution and suspicion before reporting results.
A First Solution: Scaling Test-Time Compute with Monkeys 🐒
The first thing I learned at Stanford was the “infinite monkey theorem”: my lab mates Jordan, Ryan, and Bradley were showing me the surprising power of test-time compute they found with Large Language Monkeys, where they found simply repeated sampling solutions improve SWE-Bench performance dramatically:
A monkey hitting keys at random on a typewriter keyboard for an infinite amount of time will almost surely type any given text, including the complete works of William Shakespeare High-performance CUDA Kernels.
Specifically, in the presence of a verifier, we can create many parallel samples (as an implicit form of search in the token space) and leverage the verifier to select the best one (coverage). Well, CUDA kernel is verifiable (numerical correctness and runtime!), so hence came our first attempt, just “monkey” / parallel sample each problem 100 times and see if we can find any good kernel. Our repo was actually just called CUDAMonkeys!

To our surprise, simply doing so worked remarkably well, with monkeying DeepSeek-V3 100 times improving fast_1 metric from 4% → 37% on Level 2 problems. However, kernel optimization is inherently an iterative process; performance engineers implement some features, measure the runtime, analyze the timing profile, and then repeat the process. So naturally then we then explored iterative refinement, where we scale up the serial turns, and at each turn feed the model context with evaluation results, speedups, and even profiler ops breakdown. On strong enough models such as DeepSeek-R1 we found it was able to boost fast_1 from 36% to 72% on Level 2 problems. We also release the high-performance engine to scale this up.
Scaling parallel sampling and iterative refinement leveraging verifier and feedback is the most straightforward way to scale up test-time compute. Since then we have seen the community follow-up with multiple agentic approaches: such as this work from NVIDIA and AMD, and multi-agent approaches like Astra.
Tackling the Data Problem
A root cause we suspect with models’ poor performance on KernelBench is the lack of GPU code data in pretraining data. All modern code generation methods, at the end of the day, rely on the usefulness of a “black box” language model. If the base language model is bad, then even infinite monkeys are not going to work (e.g., monkeying Deepseek V3 never got any of the convolution problems). The sad reality is that GPU code generation, like any other code generation problem, requires a strong base model / prior to work.
When we first released KernelBench, an interesting statistic we found from the StarCoder paper is that CUDA code only makes up ~0.073% of The Stack v1.2, a popular open-source code training corpus. What this implies is that open source CUDA code (the most popular GPU programming DSL) is extremely sparse, and it is highly likely that frontier models do not have a sufficient amount of GPU programming code in their training distributions. Unfortunately, the only proven method to get language models to one-shot a task is by using a TON of data, which, for GPU code generation, we do not have a lot of.
High-Quality Human Data: One analogy that we love to give is that learning to write GPU kernels is entirely analogous to learning competitive programming, albeit writing GPU kernels is even easier. Both require applying a fixed set of algorithms or tricks from a small set of options, both require thinking about fitting runtime constraints, and both generally fit in one codefile. The major difference is that competitive programming has a rich history and tens of thousands of problems with millions of human-written solutions, while GPU programming has only recently become popular.
In February 2025, Alex (along with other amazing developers from the GPU MODE community Mark, Matej, Erik, and Ben) launched the GPU MODE leaderboard, where we’ve been hosting company-sponsored competitions to the public for writing high-quality GPU code. We have since run 5 competitions:
- PMPP textbook problem set on NVIDIA GPUs.
- AMD DeepSeek kernels competition ($100k grand prize!)
- AMD distributed kernels competition ($100k grand prize!)
- Jane Street model optimization competition ($50k grand prize, in-person)
- Triangular Multiplicative Update from AlphaFold3 competition (merch grand prize)
Since its inception, we’ve had more than 60k submissions across the globe, and we have some exciting upcoming news to share at this year’s GPU MODE IRL event. Getting more high-quality, natural GPU code is going to be critical for developing better models, and we plan to continue to open source this data for usage as we introduce and scale these competitions to a wider audience.
Scaling Synthetic Data: During this time, Simon and collaborators at PyTorch + FAIR also explored a blend of synthetic data-generating methods over naturally occurring code. The key insight is that torch.compile (via TorchInductor) could generate Triton code for any valid PyTorch program. Together with Sahan and the PyTorch team, we built a synthetic dataset of Triton code, which lead to the KernelBook (the largest verified kernel dataset generated from internet PyTorch code) and KernelLLM-8B (first known post-trained approach), which shows significant improvement in KernelBench-Triton performance.
We are particularly excited by future efforts on the data front, whether it be through more principled human data collection efforts or through scalable synthetic data generation.
Models are Strong Priors over a Search Space
As we expanded in the text-time compute / monkey section, we have been using the assumption that there is a non-zero probability that there exists a solution in the model’s output distribution. A natural progression of test-time search is whether there is any structure present in the search space that we can exploit. The idea of evolutionary search is to 1) leverage the model’s inherent notion of interestingness to navigate through the search space, 2) keep an active archive of good examples found so far to continue / seed the search. Particularly, we have seen a few work that excitingly leverage this formula and apply it to the kernel generation problem:
- Sakana AI’s AI CUDA Engineer was one of the first works to apply evolutionary test-time search to the kernel LLM problem. While they accidentally discovered several reward-hacked kernels (and kudos for them for releasing them and revising their work), we found their approach fascinating nonetheless.
- My labmate Anne’s Surprisingly Fast AI-Generated Kernels We Didn’t Mean to Publish (Yet) blogpost focuses on leveraging a tree-like structured search over kernels for a particular task. Concretely, she split the search into two steps: first come up with an optimization idea in natural language and then implementation, while exploring multiple ideas and implementations at each step and keeping the best one to keep exploring next. This approach yielded some very interesting and competitive kernels!
- Google Deepmind’s AlphaEvolve equipped the Gemini model with automated verifiers and then used an evolutionary framework to improve upon the most promising ideas. They were able to optimize low-level GPU instructions (optimize XLA-generated IR), and led to a 32.5% speedup for their JAX/pallas-based FlashAttention kernel implementation!
These early signs could very much suggest that open-ended evolutionary methods could be a viable strategy for producing interesting kernels, especially those that the models haven’t seen before. To enable more research, we are integrating KernelBench with the OpenEvolve framework (open-source AlphaEvolve implementation), which excitingly has already been used for MLX kernel search.
So… could we just hillclimb with RLVR?
Reinforcement learning with verifiable rewards (RLVR) has been a hot topic for all of 2025, with the tremendous success of DeepSeek-R1 on math and coding benchmarks (aka verifiable domains). GPU kernel generation in particular presents verifiable rewards like correctness and speedup, making it a natural environment to apply RL. So could we just throw GRPO at it and hope the reward will climb?
It is not so simple. If trained in a single turn setting, the model is effectively taught to one shot the kernel, which leads it to opt for easy but correct kernels, rather than riskier, but possibly more performant kernels. Kernel writing is an inherently iterative task; we already replicate this routinely at test time, where we give the model multiple turns of feedback (compiler errors, profiling information) to solve the task. But why not teach these dynamics at training time? This is exactly what we did in Kevin in collaboration with Cognition (hence named Kernel Devin). Multi-turn training proved surprisingly effective: Kevin improves upon its base model (QwQ-32B) both in correctness (56% → 82%) and mean speedup of generated kernels: from 0.53x → 1.10x over PyTorch Eager, while outperforming frontier models like OpenAI o4-mini (0.78x).
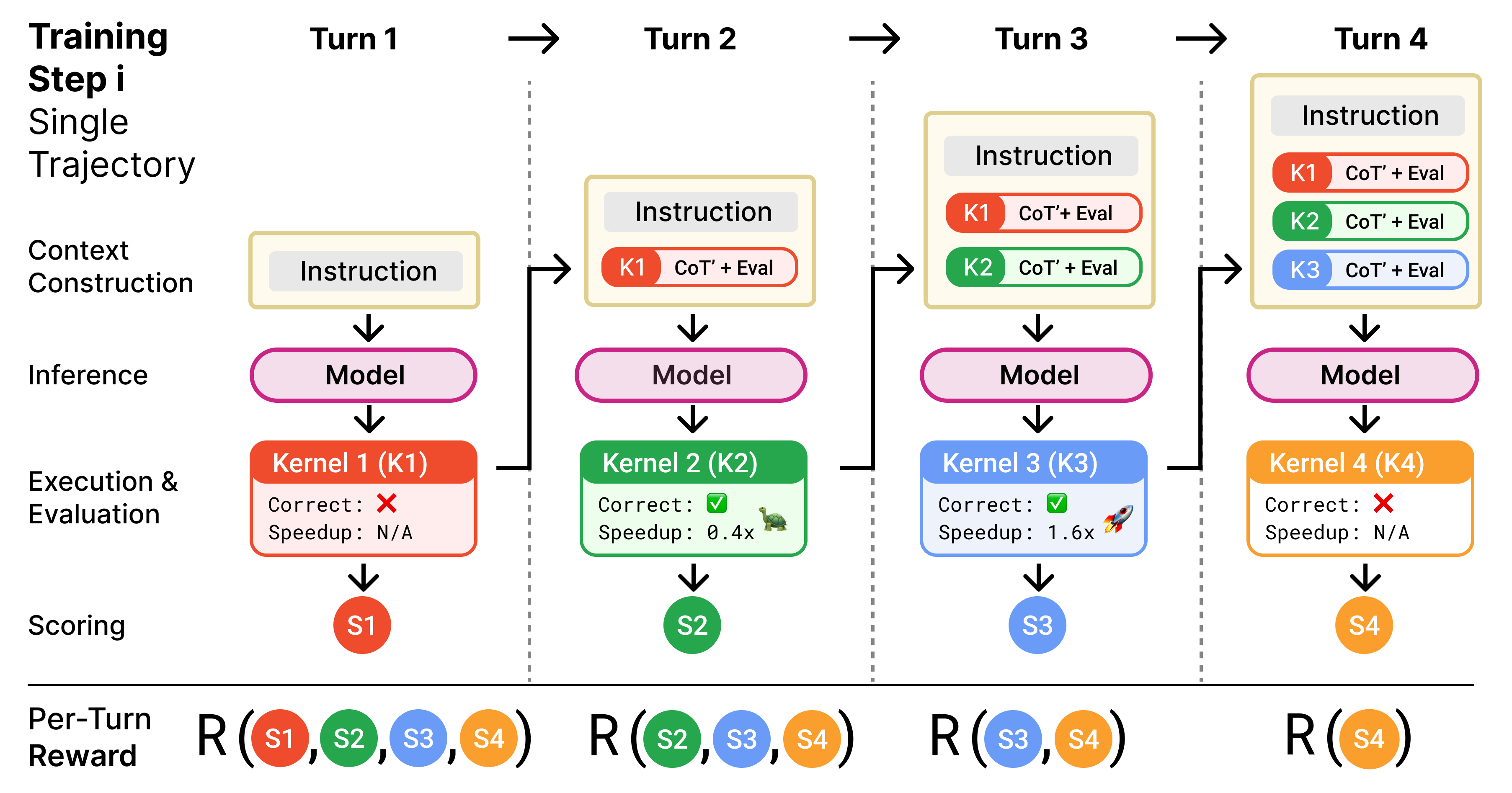
When RL is applied to real-world scenarios, a whole host of issues arise. It suffers from sparse rewards, training collapse, and frequent reward-hacking (if it can hack, it will hack)! To address this, we had to design a flexible multi-turn training recipe that prevents context explosion, enforces training stability, and focuses on sample efficiency. We think kernel engineering is actually a setting to experiment with new RL algorithms! For example, the multi-turn RL we used to train Kevin is extended creatively by the team at Cognition to train models for extremely fast context search.
To enable the community to further RL research and enable KernelBench to contribute to improving model reasoning, we are in the process of integrating KernelBench with open-source RL environment hubs on Prime Intellect, Torch Forge, Atropos, Marin. At the same time, we also wanted to highlight community effort to create more much-needed and diverse RL environments, such as PMPP-eval, which turns CUDA problems from the popular GPU programming textbook into tasks to run RL on!
Future Directions
As we can see, there has been a TON of developments since the initial KernelBench prototype. What started as a fun research project has become a topic that multiple AI research labs (METR, Sakana AI), startups, and major companies like NVIDIA have put attention on and extended work on. In the open source, Project Popcorn (as in popcorn 🍿 are generated kernels!) is a working group with the GPU MODE community, which aims to democratize kernel generation by a kernel-generating LLM from the ground up. It’s also really exciting to see startups like Standard Kernel (started by my labmate Anne!), Mako, Herdora, Gimlet Labs and others are bringing this vision to the real world.
So what’s next? Have we tried everything? How far are we from automating GPU programming? We think that there are still many unanswered directions and questions in this space for the community to explore.
Performance-Oriented Code Optimization
While most current coding and software engineering benchmarks (HumanEval, CodeContests, SWEBench) have solely focused on correctness, KernelBench represents a class of problems that also deeply concerns performance. A correct but slow kernel is not useful, and a blazing fast but incorrect kernel is irrelevant. Balancing the multi-objective optimization for correctness and performance made this task especially challenging, and poses challenges during the multi-turn RL setting where models must learn to trade off between scaling parallel attempts and serial calls.
We believe writing correct code and writing good (fast/memory-efficient) code presents fundamentally very different challenges. It’s great to see work like AlgoTune and SWE-fficiency extend this thinking towards the more general software engineering setting and cite KernelBench as a source of inspiration!
Rethink how we optimize systems
Although KernelBench stemmed from our struggle writing kernels, we think leveraging LLMs for optimization could apply beyond GPU code generation. We are very grateful that KernelBench has been highlighted at various systems conferences, e.g. MLSys (by Soumith Chintala from PyTorch) and MICRO (by Prof. Luis Ceze).
Across system research, there are many opportunities for optimization that require human ingenuity and clever engineering constructions, yet uniquely having the property of the metric being measurable and verifiable. Recent work like Barbarians at the Gate from Berkeley and demonstrations from Google’s AlphaEvolve show they can make a difference in a wider range of real-world problems from data center scheduling to AI training itself.
Interface with the Compiler / Programmer
A question we kept getting over the last year is “why not just use a compiler”? Compilers are incredibly powerful and complex systems, and I had a whole new level of appreciation for them after Prof. Fred Kjostad’s course on domain-specific programming. Our original motivation is that having efficient implementations integrated into the compiler often takes a while after new features are released; leveraging models could help bridge the gap and enable more customization (do note approaches like FlexAttention exist). However, I do think a future might look like a hybrid of models and compiler flow working together, where models guide through the optimization space (currently done by predefined heuristics) and let the compiler handle provably robust transformations they do best.
As much as I want to automate myself, I don’t think kernel engineers will be fully replaced anytime soon. What’s more realistic and useful is reducing the difficulty and speeding up kernel development, like NVIDIA’s multi-agent system that enables agentic NCU chat interface (showcased at GTC). Personally, I am very interested in how human programmers and coding agents can collaborate. To that end, this fall we’re piloting a KernelBench-style competition for Stanford’s CS 149 Parallel Computing taught by Prof. Kayvon Fatahalian, where students are actually encouraged to use AI agents in their kernel writing workflow. Hopefully, we gain some insights on which parts of the kernel optimization process benefit most from AI assistance!
A few thoughts and interesting future approaches
- Although KernelBench started with a focus on CUDA, we are very interested in other DSLs and their potentially different productivity vs. performance tradeoffs, and whether some DSLs could be better representations for models to write code in. However, a key challenge across leveraging DSLs is that they are even more rare in models’ training data than CUDA! To enable research in leveraging low-resource DSLs, we have added Triton and CuTe-DSL support to KernelBench and are actively working on ThunderKittens, CUTLASS, and Tilelang integration.
- One recent approach is to leverage the world model for code generation, pioneered from Meta FAIR’s Code World Model (CWM) paper. Having a world model could help the model build a sense of the generated code’s behavior without execution, as shown by recent work predicting Triton kernel latency. In fact, the CWM mid-training phase even leveraged the synthetic Triton pipeline that we built for KernelBook!
- GPU architectures evolve quickly and distinctly across generations. Unfortunately, even the best LLM-generated submissions to KernelBench struggle to utilize essential hardware units. We’re excited about some ongoing work (more to come soon!) that explores hardware-aware agents that can understand architecture-specific characteristics and make software-level optimizations that exploit the underlying hardware.
As you can see, there is not a single method that would get us to build an automated kernel engineer, yet the various approaches are also what make it exciting! There is also something quite meta and fascinating about this self-improvement loop: improving models to improve generated kernel performance, which hopefully then enables the model to run faster! Of course, we have to be extra careful and rigorous about our approaches, as even discovering something slightly faster than current compiler baselines should raise our suspicions. If any of those ideas excite you, please do reach out, and we would love to hear your thoughts!
Acknowledgement
Perhaps as a PhD student, the best part of this journey is the people I get to work with along the way.
I am incredibly grateful for my lab mates during the KernelBench project like Anne who bootstrapped the project together through many late nights, William and Alex for helping out and leading many parts of the investigation, and Simran and Dan for tirelessly mentoring us. Special thanks to my advisors during the first-year rotation program: especially Prof. Azalia Mirhoseini for believing in us and her immense support, Prof. Christopher Ré (and the whole group) for showing me what doing excellent work looks like, and Prof. Tatsunori Hashimoto for the many impromptu yet incredibly helpful discussions by the water fountain. I am also so grateful to mentor undergrads, particularly the trio (Carlo, Pietro, Ben) with their RL wizardry for Kevin, and Cognition AI’s support for them.
KernelBench and many of the follow-up would not have been possible without many generous collaborators and sponsors. Modal and Prime Intellect enabled us to easily extend KernelBench to a variety of different GPU platforms. The PyTorch / FAIR Code Generation team (Mark, Sahan Paliskara, Zach, Joe Isaacson, Joe Spisak, Hugh, Chris Cummins) has been instrumental in helping us understand how to benchmark and enabling follow-up work like KernelBook and KernelLLM. We are also grateful for the enthusiasm from the GPU Mode community and particularly the competition devs (Matej, Erik, Mark, Ben, Alex) for creating the GPU MODE leaderboard and democratizing GPU kernel data in the open.
Thank you to Arya Tschand, Kesavan Ramakrishnan, Nathan Paek, Ethan Boneh, Pietro Marsella, Michael Zhang, Allen Nie, Vighnesh Iyer, Kilian Haefeli, and Asianometry for reviewing this blog post.
Reference
Relevant Projects & Publications we were on:
- KernelBench: Can LLMs Write Efficient GPU Kernels? Anne Ouyang*, Simon Guo*, Simran Arora, Alex L. Zhang, William Hu, Christopher Ré, Azalia Mirhoseini https://arxiv.org/abs/2502.10517
- KernelLLM: Making Kernel Development more accessible with KernelLLM Zacharias V. Fisches, Sahan Paliskara, Simon Guo, Alex Zhang, Joe Spisak, Chris Cummins, Hugh Leather, Gabriel Synnaeve, Joe Isaacson, Aram Markosyan, Mark Saroufim https://huggingface.co/facebook/KernelLLM
- facebook/KernelLLM collaboration with PyTorch and FAIR [HF]
- Kevin: Multi-Turn RL for Generating CUDA Kernels Carlo Baronio*, Pietro Marsella*, Ben Pan*, Simon Guo, Silas Alberti https://arxiv.org/abs/2507.11948
Talk:
- GPU kernel generation; Talk at HAC: The Hacker-Cup AI Competition @ NeurIPS 2024
- Project Popcorn; Talk at GPU MODE @ NVIDIA GTC 2025
- KernelBench; Best Paper Talk at DL4C: Deep Learning For Code @ ICLR 2025

