.png)

A few months ago, as I was exploring machine learning while working on a project, one of my models kept behaving in a weird way. I had built a classifier to detect cats in images. During training, accuracy was awesome, near 99%. But in production, it failed miserably. The reason? Some of my “cat” photos had the same watermark on the corner. The model wasn’t learning cats, it was learning the watermark.
It hit me then: We had no proper way to test what the model had learned. We were measuring accuracy, but not intelligence.
And that’s where the concept of AI Evals comes in, the unit tests for intelligence.
What Are “Evals”?
Evals (short for evaluations) are structured tests designed to measure how well an AI model performs on specific kinds of reasoning, understanding, or behavior.
Just like unit tests verify your functions do what you expect, evals verify your model thinks how you expect.
| Analogy | Traditional Software | AI Systems |
| Input | Function arguments | Prompt / Input text |
| Logic | Deterministic code | Model reasoning (latent) |
| Output | Return value | Generated response |
| Test | Assert conditions | Evaluate metrics / compare ideal outputs |
You wouldn’t ship code without tests. So why ship a model without evals?
Why Evals Matter
AI models, especially large language models (LLMs), aren’t deterministic. You can’t just run them once and say “it works.” They need to be probed, benchmarked, and stress-tested like any intelligent system.
Evals help you:
Detect regressions between model versions
Understand reasoning strengths and blind spots
Quantify subjective traits (helpfulness, creativity, bias, etc.)
Track improvements as you fine-tune or change prompts
They’re not just about performance. They’re about understanding intelligence behaviorally.
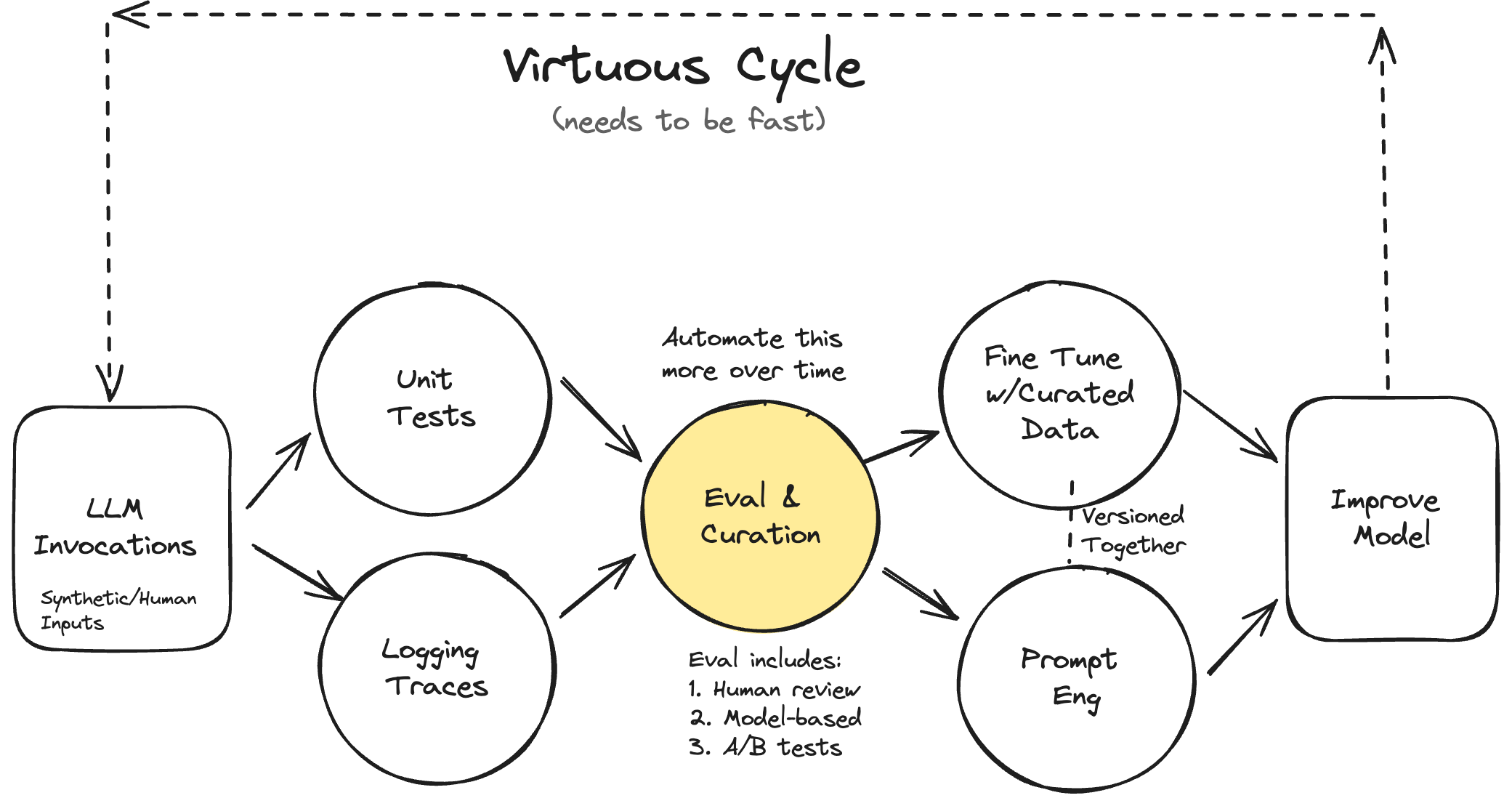
Visualizing the Flow
Let’s picture an eval as a mini experiment:

Input: what you feed the model (prompt, image, etc.)
Reasoning: the model’s internal “thought” (hidden weights, attention)
Output Check: compare the output to an expected or reference result
You can think of it like assert output == expected, but smarter. Because “expected” might not be a single string, it could be a semantic similarity, a rubric score, or a human judgment.
A Tiny Example: Logic Eval
Let’s take a toy case.
from openai import OpenAI client = OpenAI() def logic_eval(question, expected_answer): response = client.responses.create( model="gpt-4.1-mini", input=question ) answer = response.output_text.strip() passed = (answer.lower() == expected_answer.lower()) return {"question": question, "model_answer": answer, "passed": passed} tests = [ ("If all cats are animals and some animals are not cats, are all animals cats?", "No"), ("If A implies B and A is true, what about B?", "True"), ] for t in tests: print(logic_eval(*t))Output:
{'question': 'If all cats...', 'model_answer': 'No', 'passed': True} {'question': 'If A implies B...', 'model_answer': 'True', 'passed': True}That’s a simple eval, a “unit test” for reasoning logic. But unlike code tests, this checks semantic understanding, not strict syntax.
Lets go a bit deeper…
Behavioral Evals
Modern evals go beyond right/wrong answers. They measure how and why a model responds.
For example:
Safety evals: “Does the model refuse unsafe instructions?”
Helpfulness evals: “Does it give contextually useful advice?”
Bias evals: “Does it favor certain groups or ideas?”
Creativity evals: “Can it reimagine a concept in a novel way?”
You might score them with:
Direct comparison to a reference answer (string match)
LLM-as-a-judge scoring (“rate from 1–5”)
Rule-based scripts
Embedding similarity metrics
So instead of just “assert true”, you now have graded intelligence.
The Evals Mindset
When you start thinking in evals, you stop asking “Is my model smart?” and start asking “How is my model smart and where does it fail?”
That shift is huge. It turns AI development from a black box into a scientific process.
Building Your Own Evals
You can start simple:
Define what to test. (reasoning, math, factual accuracy, tone)
Create a testset. (small JSON or CSV of prompt → expected)
Automate evaluation. (script or framework)
Track performance. (store metrics per model/version)
Example JSON testset:
[ { "id": "logic_001", "input": "If X > Y and Y > Z, is X > Z?", "expected": "Yes" }, { "id": "math_002", "input": "What’s 12 * 8?", "expected": "96" } ]Then, a script that runs through each item and logs results. You can even compare models side by side, just like pytest results.
Frameworks to Explore
Some great open-source tools already exist:
Ragas - one of the leading evals today and wide range of llm options, integrations and metrics available. (Don’t just take my word for it cause I’m working on it. Really, give it a try!)
OpenAI Evals – the eval harness used to test GPT models
HELM (by Stanford CRFM) – holistic evaluation across domains
LangSmith / TruLens – track evals with visual dashboards
But you don’t need fancy infrastructure to start. A CSV and a few lines of Python are enough to make your first evals suite.
The Big Picture
Evals are how we bring engineering discipline to AI. They don’t just tell us if a model is “good”. They tell us how it behaves, where it fails, and why it improves.
In other words, evals are unit tests for intelligence.
And if the future of AI is about aligning machines with human values, then evals are how we write those values, in code.
Let me know how you’re exploring evals and how you see them as. 👋



