.png)

content type Featured highlight
![]()
With Apple Intelligence, we're integrating powerful generative AI right into the apps and experiences people use every day, all while protecting their privacy. At the 2025 Worldwide Developers Conference we introduced a new generation of language foundation models specifically developed to enhance the Apple Intelligence features in our latest software releases. We also introduced the new Foundation Models framework, which gives app developers direct access to the on-device foundation language model at the core of Apple Intelligence.
We crafted these generative models to power the wide range of intelligent features integrated across our platforms. The models have improved tool-use and reasoning capabilities, understand image and text inputs, are faster and more efficient, and are designed to support 15 languages. Our latest foundation models are optimized to run efficiently on Apple silicon, and include a compact, approximately 3-billion-parameter model, alongside a mixture-of-experts server-based model with a novel architecture tailored for Private Cloud Compute. These two foundation models are part of a larger family of generative models created by Apple to support our users.
In this overview, we detail the architectures of the models we designed, the data we used for training, the training recipes we employed, the techniques we used to optimize inference, and our evaluation results when compared to comparable models. Throughout, we highlight how we achieved an expansion of capabilities and quality improvements while increasing speed and efficiency on-device and on Private Cloud Compute. Finally, in our continued commitment to uphold our core values, we illustrate how Responsible AI principles are integrated throughout the entire model development process.
Model Architectures
We developed both the on-device and server models to meet a wide range of performance and deployment requirements. The on-device model is optimized for efficiency and tailored for Apple silicon, enabling low-latency inference with minimal resource usage, while the server model is designed to deliver high accuracy and scalability for more complex tasks. Together, they form a complementary suite of solutions adaptable to diverse applications.
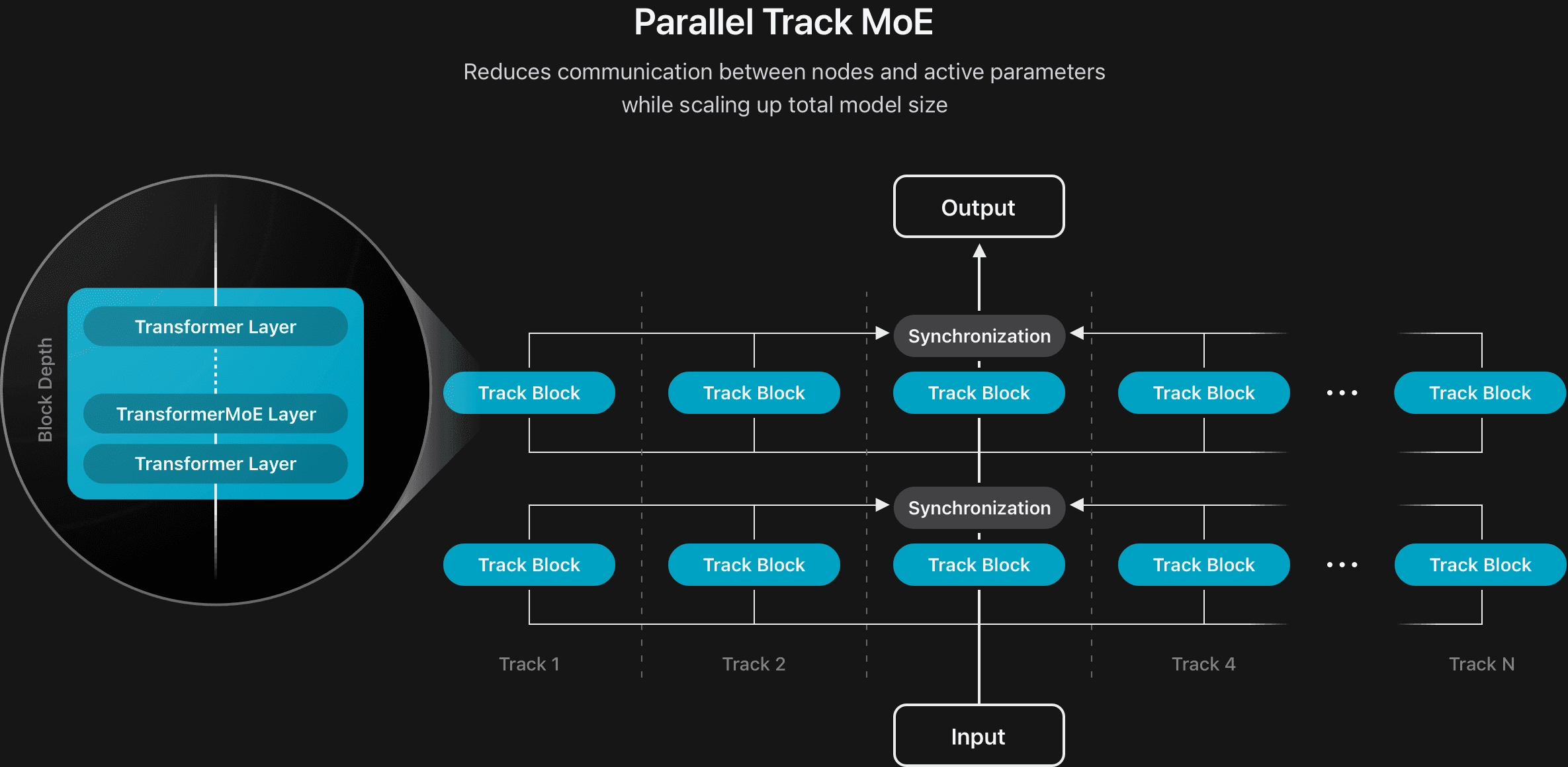
We've improved the efficiency of both models by developing new model architectures. For the on-device model, we divided the full model into two blocks with a 5:3 depth ratio. All of the key-value (KV) caches of block 2 are directly shared with those generated by the final layer of block 1, reducing the KV cache memory usage by 37.5% and significantly improving the time-to-first-token. We also developed a new architecture for the server model by introducing a parallel track mixture-of-experts (PT-MoE) design (see Figure 2). This model consists of multiple smaller transformers, referred to as tracks, that process tokens independently, with synchronization applied only at the input and output boundaries of each track block. Each track block additionally has its own set of MoE layers. Combined with the track-level parallelism enabled by track independence, this design significantly reduced synchronization overhead and allowed the model to scale efficiently while maintaining low latency without compromising quality.
To support longer context inputs, we designed an interleaved attention architecture combining the sliding-window local attention layers with rotational positional embeddings (RoPE) and a global attention layer without positional embeddings (NoPE). This setup improves length generalization, reduces KV cache size, and maintains model quality during long-context inference.
And to enable visual capabilities, we developed a vision encoder trained on large-scale image data. It consists of a vision backbone for extracting rich features and a vision-language adapter to align the features with the LLM’s token representations. We used the standard Vision Transformer (ViT-g) with 1B parameters for the server model and the more efficient ViTDet-L backbone with 300M parameters for on-device deployment. To further effectively capture and integrate both local details and broader global context, we added a novel Register-Window (RW) mechanism to the standard ViTDet, so that both the global context and the local details can be effectively captured.
Training Data
We believe in training our models using diverse and high-quality data. This includes data that we've licensed from publishers, curated from publicly available or open-sourced datasets, and publicly available information crawled by our web-crawler, Applebot. We do not use our users’ private personal data or user interactions when training our foundation models. Additionally, we take steps to apply filters to remove certain categories of personally identifiable information and to exclude profanity and unsafe material.
Further, we continue to follow best practices for ethical web crawling, including following widely-adopted robots.txt protocols to allow web publishers to opt out of their content being used to train Apple’s generative foundation models. Web publishers have fine-grained controls over which pages Applebot can see and how they are used while still appearing in search results within Siri and Spotlight.
Text Data
While respecting the opt-outs noted above, we continued to source a significant portion of the pre-training data for our models from web content crawled by Applebot, spanning hundreds of billions of pages and covering an extensive range of languages, locales, and topics. Given the noisy nature of the web, Applebot employs advanced crawling strategies to prioritize high-quality and diverse content. In particular, we focused on capturing high-fidelity HTML pages, which enrich the dataset with both text and structured metadata for aligning media with the surrounding text content. To improve relevance and quality, the system leveraged multiple signals, including domain-level language identification, topic distribution analysis, and URL path pattern heuristics.
We took special care to accurately extract the content from documents and modern websites. We enhanced our document collection with headless rendering, enabling full-page loading, dynamic content interaction, and JavaScript execution, which are critical for extracting data from web architectures. For websites that depend on dynamic content and user interactions, we enabled complete page loading and interaction simulation to reliably extract meaningful information from complex pages. We also incorporated large language models (LLMs) into our extraction pipeline, particularly for domain-specific documents, as they often outperformed traditional rule-based methods.
In addition to advanced crawling strategies, we significantly expanded the scale and diversity of our training data, and incorporated a larger volume of high-quality general-domain, mathematical, and programming content. We also extended our multilingual support to new languages that will be available later this year.
We believe that high-quality filtering plays a critical role in overall model performance. We’ve refined our data filtering pipeline by reducing our reliance on overly aggressive heuristic rules and incorporating more model-based filtering techniques. By introducing model-informed signals, we were able to retain more informative content, resulting in a larger and higher-quality pre-training dataset.
Image Data
To enhance our models and enable visual understanding capabilities for Apple Intelligence features, we introduced image data into the pre-training pipeline, leveraging high-quality licensed data along with publicly available image data.
Using our web crawling strategy, we sourced pairs of images with corresponding alt-texts. In addition to filtering for legal compliance, we filtered for data quality, including image-text alignment. After de-duplication, this process yielded over 10B high-quality image-text pairs. In addition, we created image-text interleaved data by preserving images in their originally observed text context from crawled documents. After filtering for quality and legal compliance, this resulted in 175M interleaved image-text documents, containing over 550M images. Since web-crawled image-text pairs are generally short and often don't comprehensively describe visual details in images, we used synthetic image captioning data to provide richer descriptions. We developed an in-house image captioning model capable of providing high-quality captions at different levels of detail, ranging from key words to a paragraph-level comprehensive description, generating over 5B image-caption pairs that we used across the pre-training stages.
To improve our models' text-rich visual understanding capabilities, we curated various sets of text-rich data, including PDFs, documents, manuscripts, infographics, tables, and charts via licensed data, web crawling, and in-house synthesis. We then extracted the texts and generated both transcriptions and question-answer pairs from the image data.
We curated a variety of types of image-text data:
- High-quality caption data and grounded captions: We employed Contrastive Language-Image Pre-training (CLIP) models and Optical Character Recognition (OCR) tools as filters to obtain high-quality images from the aforementioned synthetic image caption data. Then, we utilized an in-house grounding model to localize the nouns in the captions and append the coordinates after the nouns to form grounded captions.
- Tables, charts, and plots: For charts and plots, we first prompted an internal LLM to generate synthetic data fields and corresponding values, then asked the LLM to write code that can generate various types of charts and plots based on the previously-synthesized data samples. Lastly, we fed the charts, plots, and data samples into a teacher model to generate QAs for model training. For tables, we parsed the tables from publicly available websites and converted them into markdown, then used both the image-markdown pairs and image-synthetic QAs generated by a teacher model for model training.
Pre-Training
Our pre-training recipe has evolved to scale Apple Intelligence capabilities to support more languages as well as a wider array of features, including those that require image understanding.
Pre-training was conducted in multiple stages, where the first and most compute-intensive stage targeted the text modality only. We trained the on-device model using a distillation loss, but instead of employing a large dense model as the teacher and pre-training it from scratch, we sparse-upcycled a 64-expert, every-2-layer mixture-of-experts (MoE) from a pre-trained ~3B model using a small amount of our highest-quality text data. This reduced the cost of training the teacher model by 90%. However, we trained the sparse server model from scratch on 14T text tokens.
In order to better support new languages during this stage, we extended the text tokenizer from a vocabulary size of 100k to 150k, achieving representation quality for many additional languages with just 25% more tokens. And to enable visual perception, we trained both the on-device and server visual encoders using a CLIP-style contrastive loss to align 6B image-text pairs, resulting in an encoder with good visual grounding.
In the second stage of pre-training, we trained the visual encoders jointly with a vision-language adaption module using a small model decoder to align image features with the model's representation space using high-quality text data, interleaved image-text data, and domain-specific image-text data. We then utilized these visual encoders and pre-trained models to improve code, math, multilingual, long-context understanding, and to incorporate image understanding through multiple continued pre-training stages.
In the stages of continued pre-training, we adapted the dataset mixture ratios, while incorporating synthetic data verified for correctness to improve code, math, and multilingual capabilities. We then incorporated visual understanding through multimodal adaptation without damaging the text capabilities of the models. We trained a vision-language adaptation module from scratch during this stage to connect the visual encoder to both models. In the final continued pre-training stage, we trained the model to handle significantly longer context lengths using sequences up to 65K tokens, sampled from naturally occurring long-form data, synthetic long-form data designed to target specific capabilities, and mixed data from previous rounds of pre-training.
Post-Training
Similar to our approach for pre-training, we evolved our post-training process to support language expansion and visual understanding.
We scaled our Supervised Fine-Tuning (SFT) by combining human-written demonstrations and synthetic data, with an emphasis on core vision capabilities. This included general knowledge, reasoning, text-rich image understanding, text and visual grounding, and multi-image reasoning. We further bootstrapped the diversity of vision SFT data by retrieving additional images and synthesizing their corresponding prompts and responses.
We utilized this SFT stage to further enable tool-use and multilingual support. We designed a process-supervision annotation method, where annotators issued a query to a tool-use agent platform, returning the platform's entire trajectory, including the tool invocation details, corresponding execution responses, and the final response. This allowed the annotator to inspect the model's predictions and correct errors, yielding a tree-structured dataset to use for teaching. To expand to more languages, we matched the output language to the input language by default, but we also enabled the option to use different languages for prompts and responses by creating a diverse dataset with mixed languages.
We applied Reinforcement Learning from Human Feedback (RLHF) after the SFT stage for both the on-device model and the server model. Meanwhile, we proposed a novel prompt selection algorithm based on reward variance of the models' multiple generations to curate the prompt dataset for RLHF training. Our evaluations showed significant gains with RLHF for both human and auto benchmarks. And, while we introduced multilingual data in both the SFT and RLHF stages, we found that RLHF provided significant lift over SFT, leading to a 16:9 win/loss rate in human evaluations.
To continue to improve our models’ quality on multilingual performance, we used the Instruction Following eval (IFEval) and Alpaca Evals with GPT-4o as a judge. We collected 1000 prompts in each supported language written by native speakers. With careful prompt tuning, we achieved good alignment between auto evals and human evals, enabling faster iteration.
Optimizations
Over the past year, we have expanded Apple Intelligence capabilities and made quality improvements while increasing inference efficiency and reducing power consumption of our on-device and server models.
We compressed the on-device model to 2 bits per weight (bpw) using Quantization-Aware-Training (QAT) with a novel combination of learnable weight clipping and weight initialization. The server model was compressed using a block-based texture compression method known as Adaptive Scalable Texture Compression (ASTC), which while originally developed for graphics pipelines, we’ve found to be effective for model compression as well. ASTC decompression was implemented with a dedicated hardware component in Apple GPUs that allows the weights to be decoded without introducing additional compute overhead.
For both models, we quantized the embedding table to 4 bits per weight—using joint training with the base weights using QAT for the on-device model, and post-training quantization for the server model. The KV cache was quantized to 8 bits per weight. We then trained low-rank adapters using additional data in order to recover the quality lost due to these compression steps. With these techniques, we observe some slight quality regressions and even minor improvements, e.g. a ~4.6% regression on MGSM and a 1.5% improvement on MMLU for the on-device model, and a 2.7% MGSM and 2.3% MMLU regression for the server model.
| Decoder Weights | 2-bpw via QAT | 3.56-bpw via ASTC |
| Embedding | 4-bit via QAT | 4-bit post training |
| KV Cache | 8-bit | 8-bit |
| Adapter recovery | Yes | Yes |
Foundation Models Framework
The new Foundation Models framework gives access to developers to start creating their own reliable, production-quality generative AI features with the ~3B parameter on-device language model. The ~3B language foundation model at the core of Apple Intelligence excels at a diverse range of text tasks, like summarization, entity extraction, text understanding, refinement, short dialog, generating creative content, and more. It is not designed to be a chatbot for general world knowledge. We encourage app developers to use this framework to build helpful features tailored to their apps.
The highlight of our framework is an intuitive Swift approach to constrained decoding called guided generation. With guided generation, developers work directly with rich Swift data structures by adding a @Generable macro annotation to Swift structs or enums. This works because of vertical integration with the model, the operating system, and the Swift programming language. It begins with the Swift compiler macros, which translate developer-defined types into a standardized output format specification. When prompting the model, the framework injects the response format into the prompt, and the model is able to understand and adhere to it because of post-training on a special dataset designed with the guided generation specification. Next, an OS daemon employs highly optimized, complementary implementations of constrained decoding and speculative decoding to boost inference speed while providing strong guarantees that the model's output conforms to the expected format. Based on these guarantees, the framework is able to reliably create instances of Swift types from the model output. This streamlines the developer experience by letting app developers write much simpler code, backed by the Swift type system.
Tool calling offers developers the power to customize the ~3B model's abilities by creating tools that provide the model with specific kinds of information sources or services.
The framework's approach to tool calling builds on guided generation. The developer provides an implementation of the simple Tool Swift protocol, and the framework automatically and optimally handles the potentially complex call graphs of parallel and serial tool calls. Model post-training on tool-use data improved the model's reliability for this framework feature.
We've carefully designed the framework to help app developers get the most of the on-device model. For specialized use cases that require teaching the ~3B model entirely new skills, we also provide a Python toolkit for training rank 32 adapters. Adapters produced by the toolkit are fully compatible with the Foundation Models framework. However, adapters must be retrained with each new version of the base model, so deploying one should be considered for advanced use cases after thoroughly exploring the capabilities of the base model.
Evaluation
We conducted quality evaluations of our on-device and server-based models offline using human graders. We evaluate along standard fundamental language and reasoning capabilities, including Analytical Reasoning, Brainstorming, Chat, Classification, Closed Question and Answering, Coding, Creative Writing, Extraction, Mathematical Reasoning, Open Question and Answering, Rewriting, Summarization, and Tool-use.
As we expanded our model support to additional languages and locales, we expanded our evaluation task set to be locale-specific. Human graders assessed the model's ability to produce a response that was native-sounding to a user in that locale. For example, a model responding to an English sports question from a user in Great Britain is expected to know "football" is a more locally appropriate term than "soccer". Graders could flag the model's response for a number of issues, including unlocalized terms or unnatural phrases. Locale-specific evaluations used similar categories as the English US locale, except they excluded technical domains like math and coding which are mostly inherently locale agnostic.
We found that our on-device model performs favorably against the slightly larger Qwen-2.5-3B across all languages and is competitive against the larger Qwen-3-4B and Gemma-3-4B in English. Our server-based model performs favorably against Llama-4-Scout, whose total size and active number of parameters are comparable to our server model, but is behind larger models such as Qwen-3-235B and the proprietary GPT-4o.
Human Evaluation of Text Responses
With our model support expanding to the image modality, an evaluation set of Image-Question pairs was used to assess Image Understanding capabilities. This evaluation set contained similar categories as the text evaluation set, along with image-specific categories like Infographics, which challenge the model to reason about text-rich images. We compared the on-device model to vision models of similar size, namely InternVL-2.5-4B, Qwen-2.5-VL-3B-Instruct, and Gemma-3-4B, and our server model to Llama-4-Scout, Qwen-2.5-VL-32B, and GPT–4o. We found that Apple’s on-device model performs favorably against the larger InternVL and Qwen and competitively against Gemma, and our server model outperforms Qwen-2.5-VL, at less than half the inference FLOPS, but is behind Llama-4-Scout and GPT–4o.
Human Evaluation of Image Responses
In addition to evaluating the base model for generalist capabilities, feature-specific evaluation on adaptors is also performed. For example, consider the adaptor-based Visual Intelligence feature that creates a calendar event from an image of a flyer. An evaluation set of flyers was collected across a broad range of environmental settings, camera angles, and other challenging scenarios. This was used to assess the model's ability to accurately extract information from the flyer, including the date and location, to properly create the calendar event.
Responsible AI
Apple Intelligence is designed with our core values at every step and built on a foundation of industry-leading privacy protection. Additionally, we have created our Responsible AI principles to guide how we develop AI tools, as well as the models that underpin them. These principles are reflected at every stage of the architecture that enables Apple Intelligence and connects features and tools with specialized models:
- Empower users with intelligent tools: We identify areas where AI can be used responsibly to create tools for addressing specific user needs. We respect how our users choose to use these tools to accomplish their goals.
- Represent our users: We build deeply personal products with the goal of representing users around the globe authentically. We work continuously to avoid perpetuating stereotypes and systemic biases across our AI tools and models.
- Design with care: We take precautions at every stage of our process, including design, model training, feature development, and quality evaluation to identify how our AI tools may be misused or lead to potential harm. We will continuously monitor and proactively improve our AI tools with the help of user feedback.
- Protect privacy: We protect our users' privacy with powerful on-device processing and groundbreaking infrastructure like Private Cloud Compute. We do not use our users' private personal data or user interactions when training our foundation models.
These principles guide our work throughout the product development cycle, informing our product design, policies, evaluations, and mitigations. As part of Apple's commitment to responsible AI, we've continued to identify and mitigate the risks inherent to the use of foundation models, such as hallucinations and susceptibility to prompt injections. Our safety taxonomy helps us identify sensitive content that should be handled with care.
To evaluate the safety of Apple Intelligence, we assessed both the foundation models as well as each feature that uses the models prior to deployment. For foundation models, we combined internal and external human evaluation with auto-grading, and compared our models to external models for benchmarking. We constructed targeted safety evaluation datasets to assess the performance of the foundation models on tasks such as summarization, question-answering, and brainstorming, as it applies to high-risk and sensitive content. For individual features, we designed datasets that focus on user-facing risks to specifically identify unwanted or unintended outcomes, as well as to test any impacts that quality issues may cause when applied to sensitive app-specific content. For example, we took care in designing the new Foundation Models framework and supporting resources to help improve generative AI safety for apps. The framework enforces a base level of safety with built-in safety guardrails to mitigate harmful model input and output. To help app designers and developers incorporate AI safety that is tailored to their apps, we created educational resources, such as new Generative AI Human Interface Guidelines for Responsible AI principles.
As we expanded our features to new languages, we expanded our safety representation across regions and cultures, and we have continued to make improvements to account for the wide cultural and linguistic diversity of our users. In addition to adhering to local laws and regulations, we leveraged a combination of high-quality external representative data sources, engaged with internal and external legal, language, and cultural experts, as well as reviewed precedents from previous product decisions to ensure that our approach was contextually respectful and relevant. To design our mitigation steps for multilingual use, we began with multilingual post-training alignment at the foundational model level, then extended to feature-specific adapters that integrate safety alignment data. Additionally, we expanded our guardrail models, designed to intercept harmful prompts, with language-specific training data while maintaining a multilingual adapter. We developed customized datasets to mitigate culture-specific risks and biases and stereotypes in model outputs. Similarly, we extended our evaluation datasets across languages and locales with tools such as machine translation and targeted synthetic data generation, all refined by native speakers. Finally, we conducted human red teaming across features to identify risks unique to each locale.
We continuously monitor and proactively improve our features with the help of user feedback. In Image Playground, for example, users can provide feedback on generated images by tapping "thumbs up" or "thumbs down", with the option to add comments. App developers can similarly offer feedback through Feedback Assistant. Feedback from users and developers, along with evaluation data and other metrics, helps us continuously improve Apple Intelligence features and models.
Conclusion
We're excited to make the language foundation models at the core of Apple Intelligence more efficient and more capable, unlocking a wide range of helpful features integrated across our software platforms, and available to our users around the globe across many languages. We are also giving app developers direct access to our on-device language foundation model with a new Foundation Models framework. App developers can take advantage of AI inference that is free of cost and accessible with just a few lines of code, and bring capabilities such as text extraction and summarization to their apps with just a few lines of code. Our latest foundation models are built with our core values at every step, like our commitment to privacy, as well as our Responsible AI approach. We look forward to sharing more details on updates to our language foundation models in a future technical report.
We present foundation language models developed to power Apple Intelligence features, including a ∼3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the…
At the 2024 Worldwide Developers Conference, we introduced Apple Intelligence, a personal intelligence system integrated deeply into iOS 18, iPadOS 18, and macOS Sequoia.
Apple Intelligence is comprised of multiple highly-capable generative models that are specialized for our users’ everyday tasks, and can adapt on the fly for their current activity. The foundation models built into Apple Intelligence have been fine-tuned for user experiences such as writing and refining text, prioritizing and summarizing notifications, creating playful images for conversations with family and friends, and taking in-app actions to simplify interactions across apps.