.png)


One of the things I’ve geeked out on recently was using AI to assign difficulty and performance bands to a WOD. Not just one but 907 of them (and counting).
I’m building PRzilla.app which allows you to log scores for various WOD’s, track your performance, and see all kinds of cool charts about it: how you’re progressing, what biases and weaknesses there are, movement prioritization.
In order to measure athlete performance, we need to compare it against a set of “objective” levels. For example, it is commonly accepted that Fran can be done within 3 minutes if you’re an elite CrossFit athlete, with the rest of the bands looking like this:
What is a good score for the “Fran” workout?
– Beginner: 7-9 minutes
– Intermediate: 6-7 minutes
– Advanced: 4-6 minutes
– Elite: <3 minutes
Wodwell is likely the biggest database of WOD’s and it shows bands for some of the most common ones but not all of them. I decided to add these bands to PRzilla and add them to all workouts.
But how do we measure all of them?
Ideally, we’d have a dedicated panel of experts going over thousands of WOD’s to figure all of this out. Thankfully, current top-tier AI models are trained on sufficient volume of CrossFit data and have strong-enough reasoning capabilities to do this in much shorter time.
Here’s the thing: absolute scores are bound to be subjective and context-dependent!
Even though Fran times are “commonly accepted“ as <3, 4-6, 6-7, 7-9 there can also be a decent variation among them when adjusted for male vs. female, year/decade measured (CF performance is usually trending upwards), in general population vs. experienced CrossFitters, in CrossFitters vs. specialized athletes (runners/weightlifters/calisthenic warriors), based on country/area or a specific gym (Mayhem vs. your typical box), and many more.
This makes calculations tricky but I think it’s still possible to create a range that resembles an averaged-out, close-enough representation. Our “5k run” results are likely more lax than the ones actual runners would use. But for most workouts, it’s possible to use reasoning to tell that 6 minute Fran is roughly a (top of) intermediate or a (bottom of) advanced.
More importantly, as long as our scoring system is consistent across the board, it’s great for measuring relative performance: either against yourself over time, or against others.
Top tier AI models are already trained on a large enough CrossFit data to be able to determine most of these bands. But we need few extra layers of careful orchestration to create a solid system at large:
SOTA thinking model(s)
I used mostly Gemini 2.5 Pro (sometimes Sonnet 3.7) since those were the best reasoning models at the moment.Prompt and context
Make it act like a CrossFit coach / exercise scientist. “Use your extensive CrossFit knowledge”. Give it extra data to consult and base off of to narrow the scope and context, e.g. Community Cup tiers and measurements.Memory bank and examples
In practice, models are limited by 100-200K context window so we can’t send our entire JSON consisting of millions of tokens. For relative stability across batches, we need to constantly orient our model to return relatively similar calculations. I used a combination of memory bank + specific detailed documentation for this plan/feature + few examples of already existing calculations and reasoning across varied workouts. Reasoning was performed in batches to prevent hallucinations and tackle cost (this was expensive as is).Internal error correction
At the end of calculation, model needs to double-check its own analysis of specific WOD for correctness.External error correction
At the end of each batch of calculations, model takes few random existing scores and compares them to a current calculation; this ensures relative stability across many batches.
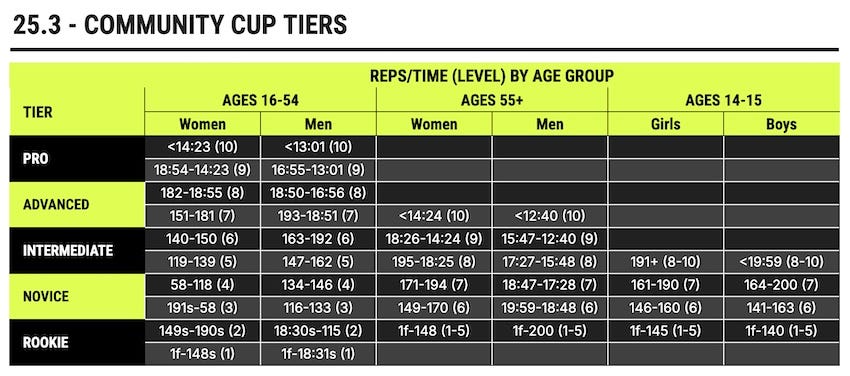
CrossFit popularized percentile-based scores during the Open, and — as part of Community Cup — they recently rolled out a scoring system that consists of 5 levels that map directly to percentiles — Rookie (<21%), Novice (22-43%), Intermediate (44-65%), Advanced (66-87%), and Pro (>88%).
I initially went with wodwell-inspired 4 tiers of Beginner, Intermediate, Advanced, Elite, then realized that there’s not enough granularity. When working on GPP charts, the scale was 1-10 and plotting “Advanced” on it was washing out the result too much. 60% and 80% could both be considered Advanced but to go from one to another might take you few years! Similarly with GPP wheel chart: if your stamina is at 60% and strength is at 80%, you would want to see that reflected on a chart as unevenness.
Here is a raw example of one of the calculations and model’s reasoning. I already had a 4 tier system/data that was generated using similar heuristic; each WOD had a difficulty, difficultyExplanation (the one model derived from its reasoning before), type, and levels.
I then used a model to derive 10 levels by giving it existing framework of how we derived those 4 levels + new system of 10 levels + examples.
Notice how it analyses WOD step by step; it understands that it’s similar to “Helen” and “Eva” since both follow a similar triplet pattern of run, x, pull-ups with this one being closer to “Eva” in terms of volume; it calculates rough times for run and thrusters while accounting for fatigue and number of rounds; adjusts edges of 10-tier to be more than 4-tier one and even considers that because it’s a “hard” WOD, beginner level is to be extended by 7min.
This now allows us to see where our scores stand for any WOD, such as this L7 that falls within 4:00-5:00 for Diane.
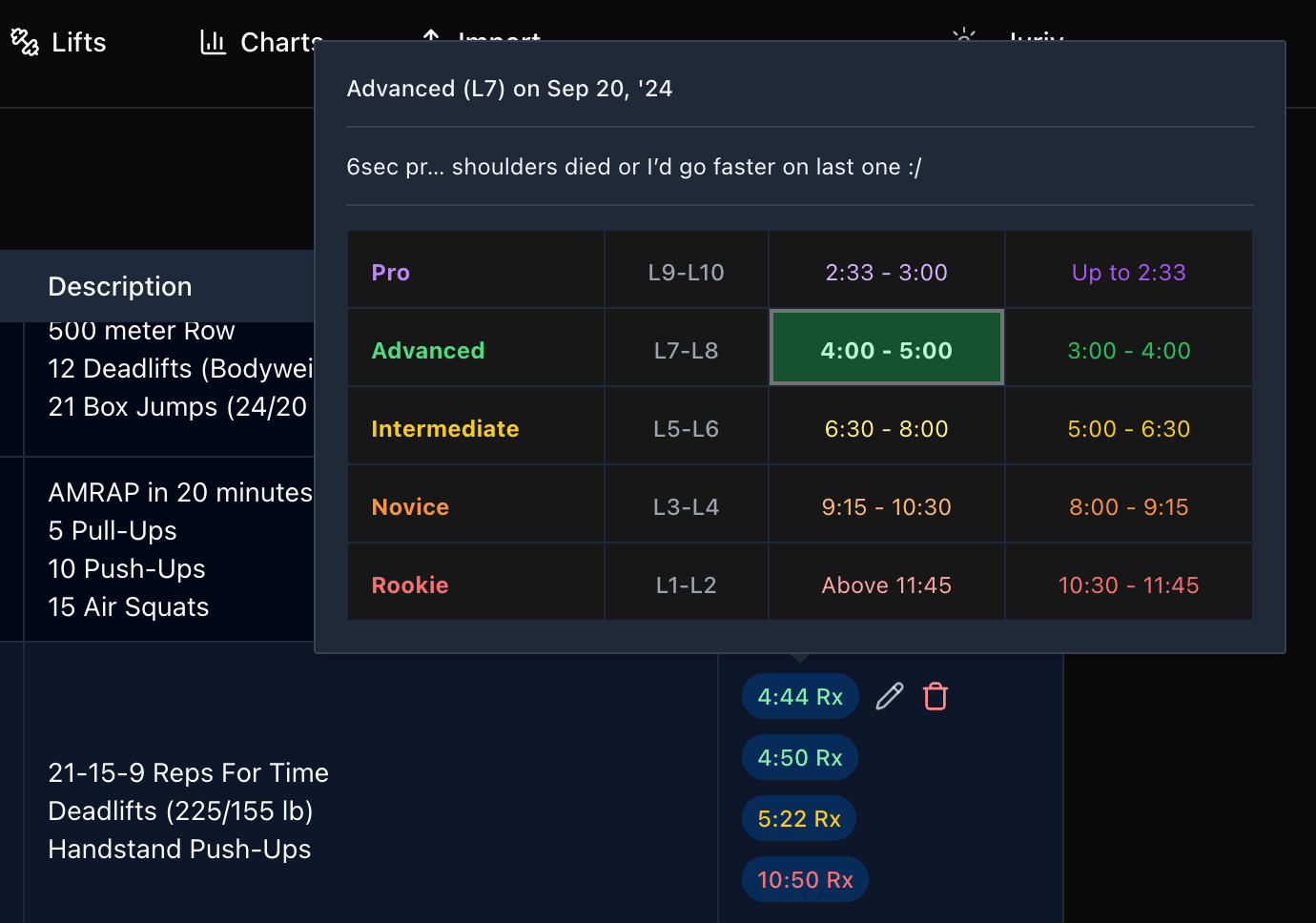
Before doing a workout, you can take a look at the performance guide and have a better idea which time to shoot for to get into a certain percentile.
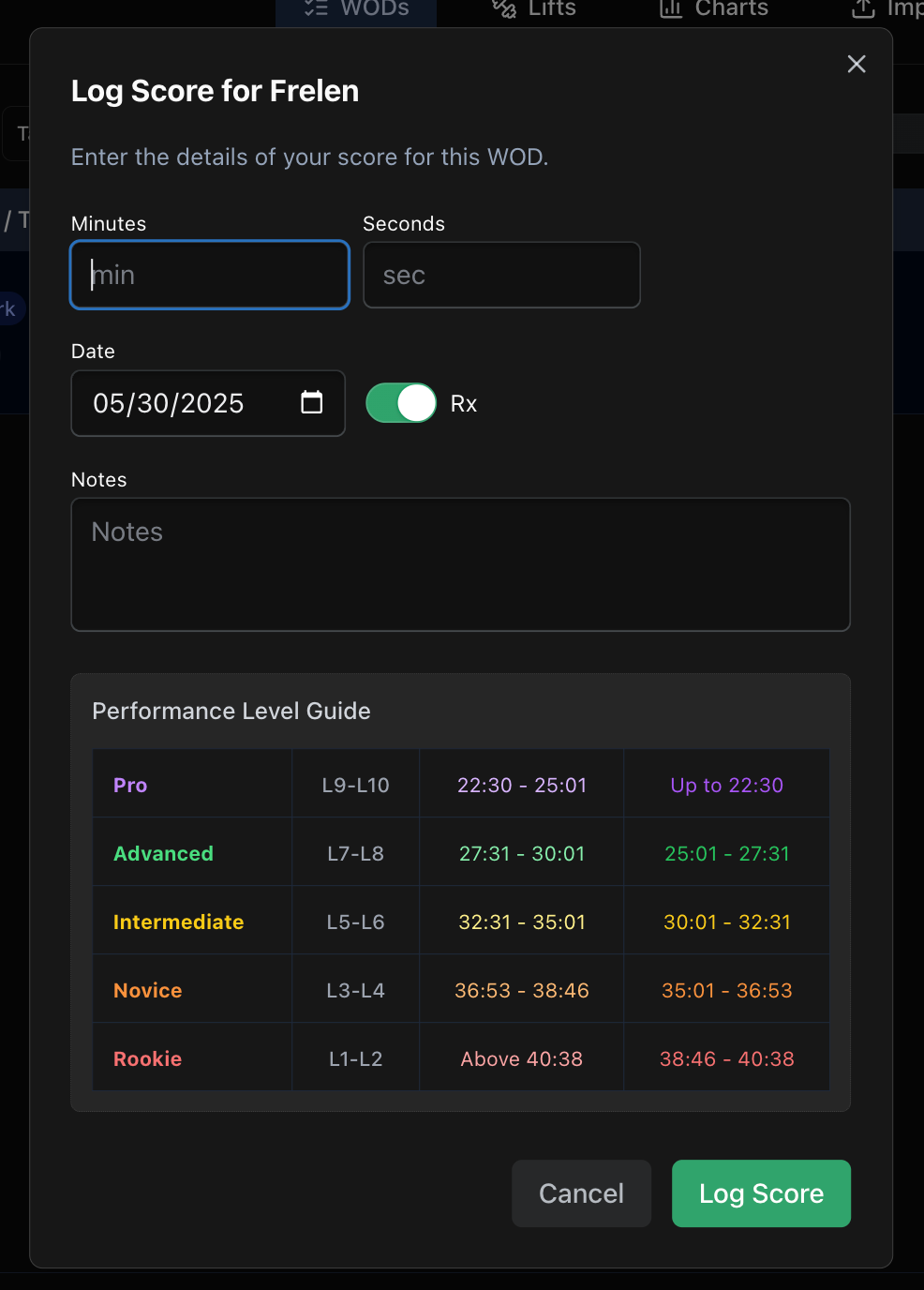
Using similar training and reasoning, I was also able to create difficulty levels for all WOD’s. You’ve already seen “Frelen” categorized as “Hard“ earlier.
Here’s the actual documentation used when orienting AI to work with this data. AI uses this as a framework to understand general structure of a workout, and then adjusts difficulty based on modifiers like volume, skill, and load.
This produces strikingly accurate results. Note AI’s explanation for why difficulty is set certain way:
1k row — Easy, “A standard benchmark test of 1000 meter rowing speed.“
Baseline — Easy, “A classic CrossFit introductory benchmark testing basic rowing and bodyweight movement capacity.”
Annie — Medium, “Girl WOD (Ladder Couplet). Tests double-under skill proficiency and core endurance in a fast-paced descending rep scheme (50-40-30-20-10).”
Wittman — Medium, “Hero WOD (Triplet). 7 rounds combining moderate KB swings, light power cleans, and box jumps. Tests moderate power endurance/conditioning.”
Dork — Hard, “Hero WOD (Triplet). 6 rounds combining DUs, heavy KB swings (70lb), and burpees. Tests conditioning, skill, and endurance over significant volume.”
Kelly — Hard, “Girl WOD (Triplet). 5 rounds: run, high-vol box jumps, high-vol wall balls. Tests high-volume conditioning/endurance.”
Maggie — Very Hard, “Five rounds of high-volume, high-skill gymnastics movements (HSPU, Pull-ups, Pistols). Tests advanced gymnastics capacity and endurance.”
The Seven — Very Hard, “Hero WOD. 7 rounds of 7 reps: HSPU, heavy thrusters (135lb), KTE, heavy DL (245lb), burpees, heavy KB swings (70lb), pull-ups. Extremely demanding strength/skill/volume across 7 movements.“
Atalanta — Extremely Hard, “Long Murph-style chipper with vest, high volume gymnastics.“
2007 Reload — Extremely Hard, “Long row followed by high-skill gymnastics and heavy shoulder-to-overheads demand elite capacity and strength.“
Fun fact: “Extremely Hard“ category did not exist until I introduced Crossfit Games workouts at which point AI proactively came up with it and it made sense as the relative difficulty was objectively increased in those! Only 15 out of 907 are currently categorized as such.
Some of you will certainly scoff at a “1k row” categorized as easy. A simple movement like that can absolutely be made into a grueling test of strength, grit, endurance and stamina. The difficulty in PRzilla is not about how hard something can be made but how demanding it is on skill/strength/endurance. 1k row is easy in a sense that it can be performed by almost any person and can be completed with little effort as prescribed. You can’t say the same about Amanda that will have you do 21 ring muscle-ups together with 21 squat snatches at 135lb — feats that can take you years to master individually, not to mention being able to superset them.
Speaking of extremely hard tests, it was interesting to see how AI estimates something like “Triple unders: max reps” or “Free standing handstand push-ups: max reps”:
This is a "Very Hard" test of max unbroken triple-unders. This is an extremely high-skill movement. Even a single rep is a significant achievement for many.
High-skill jump rope variation requiring exceptional timing, coordination, and wrist speed.
- L1: Cannot complete 0 reps (effectively)
- L2: 0 reps
- L3: 0 reps
- L4: 0 reps
- L5: 1-4 reps
- L6: 5-10 reps
- L7: 11-15 reps
- L8: 16-21 reps
- L9: 22-36 reps
- L10: >=36 reps
Because we maintain relative difficulty, even an intermediate score on such tests are a great achievement. And the model understands that beginners (up until level 5) are unlikely to complete even 1.
Once we know your performance levels on all the WOD’s, it’s easy to plot them over time for a chart like this that shows “fitness level” progression and trend. And here’s something even more fun — because we have WOD’s difficulty, we can adjust your score to be more representative of real life performance (meaning that getting “Intermediate” in a “Very Hard” WOD is closer to getting “Advanced“ in “Hard” one):
adjustedLevel = cap(scoreLevel + difficultyBonus, 0, 10)…where difficultyBonus is something simple like:
Easy: -0.5, Medium: +0.0, Hard: +0.5, Very Hard: +1.0, Extremely Hard: +1.5
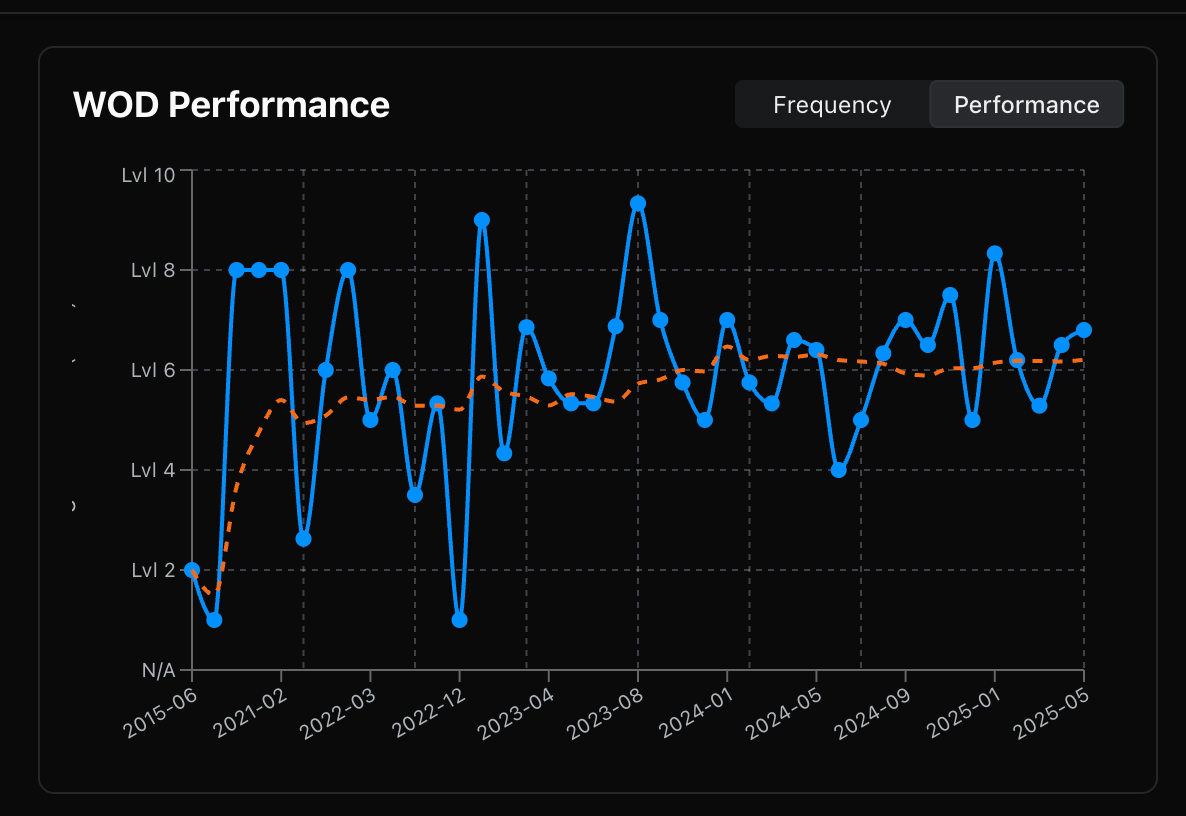
Give these estimates a try — do they feel right? Could anything be improved? I’m planning to refine these in PRzilla for an even deeper understanding of workout stimulus; similar to community cup, we could be better at gender and age group adjustments. There are also gaps right now with certain WODs that have a timecap and so are a hybrid of time (if completed within timecap) and reps/load (if completed at timecap).
In the future, I’m planning to add an option to input any custom WOD and get an estimate of its difficulty and performance levels.



